 |
Главная |


Таблицы экспериментальных данных и их предварительная обработка
|
из
5.00
|
СИСТЕМНЫЙ АНАЛИЗ
Выполнила: студентка группы БЖ-91 Тюнина А. С.
Проверила: Решетникова В.П.
Курск - 2012
Содержание
Кафедра охраны труда и окружающей среды.............................................. 1
Введение........................................................................................................... 5
1. Теоретическая часть................................................................................... 6
1.1 Понятие класса.......................................................................................... 6
1.2 Таблицы экспериментальных данных и их предварительная обработка 6
1.3 Выбор решающего правила................................................................... 11
2. Расчетная часть.......................................................................................... 15
2.1 Заполнение пропусков в ТЭД................................................................. 16
2.2 Удаление артефактов............................................................................... 19
2.3 Оценка структуры классов...................................................................... 25
2.4 Выбор решающего правила................................................................... 29
Заключение.................................................................................................... 32
Задание на курсовой проект
Вариант 11
1. Заполнить пропуски в ТЭД
2. Удалить артефакты
3. По одномерным гистограммам оценить структуру классов
4. Выбрать тип решающего правила
5. Найти численные значения параметров решающего правила
6. Используя данные ТЭД в качестве контрольной найти значение вероятности правильной классификации полученной модели
| Х1 | Х2 | Х3 | Х4 | Х5 | Номер класса | |
Введение
Распознавание образов представляет собой задачу преобразования входной информации в выходную, являющуюся заключением о том, к какому классу принадлежит распознаваемый образ.
Задача классификации представляет собой задачу разбиения пространства признаков на области по одной для каждого класса. Разбиение необходимо производить так, чтобы не было ошибочных решений.
Целью данного курсового проекта является обработка таблицы экспериментальных данных, и нахождение для нее решающего правила.
Теоретическая часть
Понятие класса
Одним из основных понятий теории распознавания образов, относящимся к множеству объектов, явлений или ситуаций, которым присущи некоторые общие свойства, позволяющие объединить их как сходные, но в то же время отличать их от различных объектов. Для обозначения этого понятия используют термин "образ", а более употребительным является термин "класс".
Пусть Qj - класс. Он принадлежит множеству классов Q, т.е. Q = {Qj}. Индекс j позволяет отличить один класс от другого.
Распознаванием называется процедура отнесения конкретного объекта, явления или ситуации к одному из классов Oj из общей совокупности Q.
Таблицы экспериментальных данных и их предварительная обработка
Типичная форма при сборе экспериментальных данных - таблица "объект-признак", в которую заносятся значения признаков (свойств), характеризующие каждый исследуемый объект. Примерами признаков могут быть наличие или отсутствие симптома, "вес", "температура", "давление", "частота сердечных сокращений" и т.д. Под объектами могут рассматриваться любые проявления реального мира люди, нозологические формы, животные, изделия и пр. Таблицу такого вида принято называть таблицей экспериментальных данных (ТЭД).
При проведении реальных вычислительных экспериментов нельзя исключить возможность получения "артефактных" данных в ТЭД, например, в случае возникновения ошибок при регистрации соответствующих показателей. Для поиска в ТЭД искаженных данных можно использовать построение и визуальный анализ гистограмм распределений признаков. При этом ошибочным может считаться тот показатель, который не вписывается в общую картину закона распределения соответствующих признаков. Например, если признаки получены по нормальному (Гауссовскому) распределению, то за истинные данные можно принять интервал ±2d (где d - стандартное отклонение). В этом случае все результаты за пределом данного интервала могут быть исключены из ТЭД. В то же время при исключении ошибочных данных, а также в ряде других случаев (данные невозможно было собрать или они утеряны) в ТЭД возникают пропуски, которые необходимо заполнить. Для заполнения пропусков можно использовать метод "максимального подобия". Суть метода состоит в том, что для восстановления утраченных данных в строках таблицы производится последовательный просмотр всех строк ТЭД с поиском той строки, которая не имеет пропусков и максимально похожа на восстанавливаемую строку с пропусками. При нахождении строки ТЭД удовлетворяющей указанным требованиям в строку с пропущенными данными копируются ячейки из найденной строки. Для нахождения строки с максимальным подобием можно использовать метод наименьших квадратов, в этом случае каждой строке ТЭД ставится в соответствие сумма квадратов отклонений (СКО) элементов заполняемой строки с соответствующими элементами всех строк ТЭД.
 (1.1)
(1.1)
где i - номер столбца,
j - номер строки,
m - номер строки с пропущенными ячейками.
При этом в качестве наиболее "похожей" строки выбирается строка ТЭД с наименьшим показателем СКО.
Каждый реальный объект имеет бесконечное число различных свойств, отражающих его различные стороны. Естественно, что в каждом конкретном исследовании существенными являются не все свойства, а их ограниченный набор, определяющий наиболее важные признаки. Таким образом, после формирования исходной ТЭД необходимо решить задачу анализа информативности признаков таблицы. Другими словами необходимо из имеющихся признаков отобрать некоторое их количество, которое бы описывало структуру данных так же, как и вся совокупность. Вторая задача (после удаления артефактов и заполнения пропусков) решаемая на этапе предварительного анализа данных сводится к оценке степени корреляции между столбцами ТЭД с целью исключения наиболее коррелированных между собой, а также селекции наименее информативных признаков. Для решения данной задачи используются различные методы:
1. Селекция признаков по относительному дисперсионному разбросу (внутриклассовой вариации).
2. По парной корреляции, путем построения векторов парной корреляции признаков R[k,i], k=l..n; i=l..n, где n – количество признаков, и R[k,i] – ранжированное с точностью до 0,1 абсолютное значение коэффициента парной корреляционной связи между признаками k и i. Селекция производится с выбором факторов, у которых значение парной корреляции составляет значение меньше порогового Rпop. Уравнение для коэффициента корреляции имеет следующий вид:
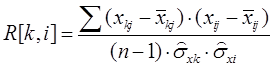 (1.2)
(1.2)
 (1.3)
(1.3)
 (1.4)
(1.4)
Использование первых двух методов обычно производится в качестве предварительного анализа. Так, использование селекции признаков по относительному дисперсионному разбросу позволяет выявить представительность отдельных признаков как внутри класса, так и вне его, построение векторов парной корреляции – оценить величины линейных зависимостей между исходными признаками. Однако первый метод не позволяет оценить величины линейной зависимости между сходными классификационными переменными, а также оставляет в генерируемой совокупности признаки, положительно не влияющие на вероятность правильной классификации в конечном итоге. Использование второго метода позволяет выявить существующие линейные зависимости между исходными классификационными переменными, однако данный метод не обладает возможностью оценки информативности отдельного признака. Раздельное применение данных методик в качестве критерия отбора иногда приводит к получению противоречивых результатов, а в то время как и совместно взятые, в рамках одного метода, не лишены определенных недостатков.
3. По информационному показателю силы влияния (ИПВ). Данный критерий отсева основывается на свойствах информационной энтропии и заключается в следующем: для каждого признака хi (i=1..n, где n – общее количество признаков) строится гистограмма его значений, по которой оценивается общая энтропия Эi:
 (1.5)
(1.5)
где P(i) - вероятность нахождения значения признака в заданном интервале.
Поступая аналогичным образом в каждом классе, получаем внутриклассовые энтропии Эк (к=1..m, где m - общее количество классов). Тогда показатель неэнтропии будет найден из следующего выражения:
 (1.6)
(1.6)
где N – общее количество объектов во всех классах, k – количество классов, ni – количество объектов в i-ом класса (i=l..k), Эki – внутриклассовая энтропия.
Отсюда имеем показатель информативной силы влияния (ИПВi):
 (1.7)
(1.7)
на основании которого выбирается оптимальный набор признаков, с максимальными значениями показателя ИПBi.
4. Метод отбора переменных на основании величины отношения внутренне обобщенной дисперсии к общей обобщенной дисперсии для отбираемых переменных. При использовании данного метода внутренняя обобщенная дисперсия вычисляется как определитель внутригрупповой матрицы перекрестных произведений W(x) для переменных x=(xl,x2,...,xp), и аналогично, общая обобщенная дисперсия есть определитель общей матрицы перекрестных произведений Т(х) для этих переменных. Отношение
l(x)=detW(x)/detT(x) (1.8)
называется l – статистикой Уилкса. Оно принимает значения между нулем и единицей. Большие значения указывают на слабое разделение между группами, в то время как малые значения – на хорошее разделение между группами (по крайней мере между некоторыми из них). Мультипликативное приращение
l(ux)= l((x,u)/l(x)) (1.9)
в l(x), получаемое при добавлении переменной и к множеству x=(xl,x2,...,xp), называется частной статистикой. Соответствующая F-статистика есть
 (1.10)
(1.10)
где n – общее число наблюдений,
q – число групп,
р – число переменных в текущем анализе. Используется для проверки значимости изменений в l(х) в результате добавления u. Рассматриваемое в данной работе значение F-статистики было использовано нами как одно из средств для отбора переменных. При этом F-статистика может рассматриваться как F-статистика включения (при включении переменной и в множество x=(xl,x2,...,xp), так и как F-статистика исключения (при исключении переменной и из множества x=(x1,x2,...,xp,u)). При этом вводится ряд правил на запрещение включения и исключение переменных:
1. Переменная не исключается, если значение ее F-статистики исключения больше или равно установленному порогу.
2. Переменная не включается, если значение ее F-статистики включения ниже установленного порога.
3. Переменная не включается, если значение ее толерантности ниже установленного порога (в данном случае толерантность для включения классификационной переменной равна единице, а вычетом квадрата ее внутригрупповой корреляции с текущими включенными переменными).
Для реализации вышеизложенных правил используется следующий пошаговый алгоритм:
1. Исключается переменная с наименьшим значением F-статистики исключения, если это значение больше или равно пороговому значению F-статистики исключения.
2. Если исключение невозможно, то находится переменная с наибольшим значением F-статистики включения среди всех переменных, толерантность которых больше или равна порогу толерантности. Эта переменная включается, если значение ее F-статистики включения ниже порога для F-статистики включения.
3. Если включение или исключение переменной невозможно, то пошаговая процедура заканчивается, в противном случае, производится переход на п. 1.
|
из
5.00
|
Обсуждение в статье: Таблицы экспериментальных данных и их предварительная обработка |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы