 |
Главная |


Описание и ввод грамматики
|
из
5.00
|
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАСЛЯЦИИ
АТРИБУТНЫЕ ТРАНСЛИРУЮЩИЕ ГРАММАТИКИ
Методические указания
К выполнению лабораторной работы №2
Для студентов очной формы обучения специальности 230105 «Программное обеспечение вычислительной техники
И автоматизированных систем»
Брянск 2010
УКД 629.42.02/.06(07)+621.313.2(07)
Теории языков программирования и методы трансляции. Атрибутные транслирующие грамматики: методические указания к выполнению лабораторной работы №2 для студентов очной формы обучения специальности 230105 «Программное обеспечение вычислительной техники и автоматизированных систем». – Брянск: БГТУ, 2010. – 16 с.
Разработали:
А.Н.Горбунов
доцент, канд. техн. наук,
Я.И.Сиваков
старший преподаватель
Рекомендовано кафедрой «Информатика и программное обеспечение» БГТУ (протокол № от __.__.2010 г.)
ЦЕЛЬ РАБОТЫ
Целью работы является получение практических навыков по составлению правил атрибутной транслирующей грамматики и проверка их правильности путем моделирования.
Продолжительность работы – 6 часов.
Основные понятия и термины
Транслирующие грамматикипозволяют задавать соответствия между цепочками входного и выходного языков, называемые переводом. Эти соответствия отражают структурные или синтаксические свойства входных и выходных цепочек, однако при попытках их использования для описания контекстно-зависимых условий или смысла конструкций – семантики языков программирования возникают значительные трудности. Поэтому для задания семантики применяются различные приемы: W -грамматики, венский метаязык, аксиоматический и денотационный методы, а также атрибутные транслирующие грамматики.
Существует два вида записи для связанных с продукциями семантических правил — синтаксически управляемые определения и схемы трансляции. Синтаксически управляемые определения представляют собой высокоуровневые спецификации трансляции, скрывающие множество деталей реализации и освобождающие пользователя от явного указания порядка выполнения трансляции. Схемы трансляции указывают порядок, в котором выполняются семантические правила; так что эти схемы показывают определенную часть деталей реализации. Выполнение семантических правил может генерировать код, сохранять информацию в таблице символов, выводить сообщения об ошибках или выполнять какие-либо другие действия.
Синтаксически управляемое определение представляет собой обобщение контекстно-свободной грамматики, в которой каждый грамматический символ имеет связанное множество атрибутов, разделенное на два подмножества, — синтезируемые и наследуемые атрибуты этого грамматического символа. Если рассматривать узел грамматического символа в дереве разбора как запись с полями для хранения информации, то атрибут соответствует имени поля.
Атрибутные транслирующие грамматики (АТ-грамматики) отличаются от транслирующих грамматик тем, что символам грамматики приписываются атрибуты, отражающие семантическую информацию, а правилам грамматики сопоставляются правила вычисления значений атрибутов. Атрибут может представлять собой все, что угодно, — строку, число, тип, адрес памяти и т.д. Значение атрибута в узле дерева разбора определяется семантическими правилами, связанными с используемой в данном узле продукцией. Значение синтезируемого атрибута в узле вычисляется по значениям атрибутов в дочерних по отношению к данному узлах; значения наследуемых атрибутов определяются значениями атрибутов соседних (т.е. узлов, дочерних по отношению к родительскому узлу данного узла) и родительского узлов.
Семантические правила определяют зависимости между атрибутами, которые представляются графом зависимости, определяющим порядок выполнения семантических правил, что в свою очередь дает значения атрибутов в узлах дерева разбора входной строки. Семантические правила могут иметь и побочные действия, например вывод значения или изменение глобальной переменной. Дерево разбора, показывающее значения атрибутов в каждом узле, называется аннотированным, а процесс вычисления значений атрибутов в узлах дерева — аннотированиемдерева разбора.
2.1 Синтезируемые атрибуты.
В синтаксически управляемом определении каждая продукция грамматики А → а имеет связанное с ней множество семантических правил вида b := f (c1, c2, …, ск), где f — функция, с1, с2, ..., ск — атрибуты грамматических символов продукции, а b — синтезируемый атрибут символа А или наследуемый атрибут одного из грамматических символов правой части продукции.
В любом случае атрибут b зависит от атрибутов с1 с2, ..., ск. Таким образом, атрибутная грамматикаявляется синтаксически управляемым определением, в котором функции в семантических правилах не имеют побочных эффектов. Функции в семантических правилах зачастую записываются как выражения. Может быть так, что единственная цель семантического правила в синтаксически управляемом определении состоит именно в создании побочного эффекта. Такие семантические правила записываются как вызовы процедур или фрагменты программ. Их можно рассматривать как правила, определяющие значения фиктивных синтезируемых атрибутов нетерминала в левой части связанной продукции; фиктивный атрибут и знак присвоения : = при этом не указываются.
В качестве примера рассмотрим синтаксически управляемое определение программы простого калькулятора. Это определение связывает с каждым из нетерминалов Е, Т и F целочисленный синтезируемый атрибут val. Для каждой Е-, Т- и F -продукции семантическое правило вычисляет значение атрибута val нетерминала из левой части продукции по значениям атрибутов нетерминалов правой части.
Продукция Семантические правила
L→En print(E.val)
E→E1+ Т E.val := E1.val + T.val
Е→Т E.val := T.val
T→T1*F T.val :=T1.val * F.val
T→F T.val := F.val
F→ (E) F.val := E.val
F→ digit F.val := digit.lexval
Лексема digit имеет синтезируемый атрибут lexval, значение которого предоставляется лексическим анализатором. Правило, связанное с продукцией L → Еn для стартового нетерминала L, представляет собой процедуру вывода значения арифметического выражения, порождаемого E (это правило можно рассматривать как определяющее фиктивный атрибут для нетерминала L).
В синтаксически управляемом определении предполагается, что терминалы могут иметь только синтезируемые атрибуты, поскольку определение не дает никаких семантических правил для терминалов (обычно значения атрибутов терминалов предоставляются лексическим анализатором). Кроме того, если иное не оговорено особо, стартовый символ не имеет наследуемых атрибутов.
Синтаксически управляемое определение, использующее только синтезируемые атрибуты, называется S-атрибутным определением. S-атрибутное определение в рассматриваемом примере описывает калькулятор, считывающий арифметическое выражение из цифр, скобок, операторов + и *, за которым следует символ новой строки n, и выводит значение выражения. Например, получив выражение 3*5+4, за которым следует символ новой строки, программа выводит значение 19. На рис. 2.1 показано аннотированное дерево разбора для входной строки 3*5+4n. Выход программы, печатаемый в корне дерева, представляет собой значение E.val в первом дочернем узле корня дерева.
L
 |  | ||
n
E.val=19
 |  |  | |||
+
E.val:= 15 T.val=4
 T.val =15 F.val = 4
T.val =15 F.val = 4




* digit./ewa/ = 4
T.val = 3 F.val=5
F.val=3 digit.lexval=5

digit.lexval= 3
Рис. 2.1. Аннотированное дерево разбора для 3*5+4n.
Рассмотрим узел продукции T→T*F. Значение атрибута T.val в этом узле определяется следующим образом:
Продукция Семантическое правило
Т→Т1 * F T.val := T1.val * F.val
При использовании этого семантического правила в данном узле T1.val имеет значение 3, полученное от левого наследника, a F.val — значение 5, полученное от правого наследника. Следовательно, в этом узле T.val составляет 15.
Правило, связанное с продукцией для стартового нетерминала L → Еn, выводит значение выражения, порожденного Е.
2.2. Наследуемые атрибуты.
Наследуемые атрибуты представляют собой атрибуты, значения которых в узле дерева разбора определяются атрибутами родительского и/или дочерних по отношению к родительскому узлов. Наследуемые атрибуты удобны для выражения зависимости конструкций языка программирования от контекста, в котором они появляются. Например, мы можем использовать наследуемые атрибуты для отслеживания, появляется ли идентификатор слева или справа от знака присвоения, чтобы определить, потребуется ли адрес или значение данного идентификатора. Хотя всегда можно переписать синтаксически управляемое определение таким образом, чтобы использовать только синтезируемые атрибуты, зачастую более естественно воспользоваться синтаксически управляемым определением с наследуемыми атрибутами.
Рассмотрим пример, в котором наследуемый атрибут распространяет информацию о типе на различные идентификаторы в объявлении.
Пусть объявление, порождаемое нетерминалом D в синтаксически управляемом определении, приведенном ниже, состоит из ключевых слов intили real,за которыми следует список идентификаторов. Нетерминал Т имеет синтезируемый атрибут type, значение которого определяется ключевым словом объявления. Семантическое правило L.in := Т.type, связанное с продукцией D → ТL, определяет наследуемый атрибут L.in как тип объявления. Затем приведенные правила распространяют этот тип вниз по дереву разбора с использованием атрибута L.in. Правила, связанные с продукциями для L, вызывают процедуру addtype для добавления типа каждого идентификатора к его записи в таблице символов (определяемой атрибутом entry).
Продукция Семантические правила
D → TL L.in:= Т.type
T → int Т.type:= integer
T → reaI T.type := real
L → L1, id L1.in := L.in
addtype(id. entry, L.in)
L → id addtype(id.entry, L.in)
На рис. 2.2 приведено аннотированное дерево разбора для предложения real id1, id2, id3.

 D
D
T.type = real L.in = real
| |  |  |  | ||||
real
L.in = real , id3
 |  |  | |||
 L.in = real , id2
L.in = real , id2
id1
Рис. 2.2 Дерево разбора с наследуемыми атрибутами in в каждом узле, помеченном L.
Описание и ввод грамматики
В комплект программы входит текстовый редактор, с помощью которого можно вводить грамматику. Для входа в редактор перейдите в папку программы и запустите файл SAG à ScilicetEditor à ScilicetEditor.exe. Этот редактор настроен на автоматический запуск анализатора SAG. Так же он подсвечивает синтаксис вводимых конструкций.
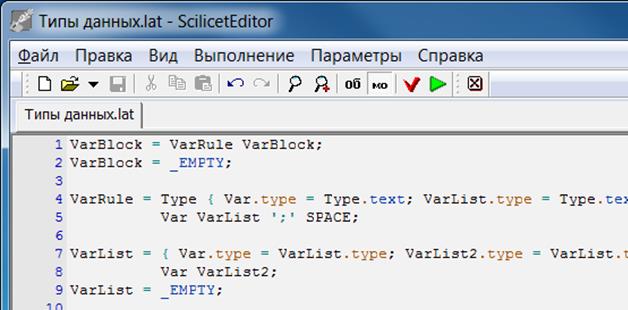
Рис. 1. Окно текстового редактора для ввода грамматики
Грамматика описывается при помощи нотации Бакуса-Наура. Терминальные символы заключаются в кавычки. Терминальные и нетерминальные символы могут состоять из нескольких литер. Внутри многолитерных символов не должны встречаться специальные символы, в том числе и пробелы. Правила грамматики записывается в виде
нетерминальный_символ = цепочка
Каждое определение нетерминального символа должно заканчиваться знаком точки с запятой (;).
Между символами =, а также между нетерминальными символами допускается любое число пробелов. Описание грамматики должно начинаться с правила, определяющего начальный символ (аксиому) грамматики. В тексте описания грамматики можно использовать комментарии. Комментарий начинается с двух слешей (//) и продолжается до конца строки.
В терминальных символах можно использовать следующие обозначения:
\r – перевод каретки (символ с кодом 10);
\n – возврат каретки (символ с кодом 13);
\t – знак табуляции;
\\ – знак обратного слеша;
\’ – одинарная кавычка;
\” – двойная кавычка.
Атрибутные правила записываются внутри фигурных скобок и разделяются точками с запятой (;). Внутри атрибутных правил обращения к атрибутам записываются в виде
нетерминальный_символ . название_атрибута
Сами атрибутные правила должны выглядеть так:
атрибут = выражение_с_атрибутами
В выражениях допустимо использовать математические операции «+», «–» , «*» , «/» и операцию объединения строк «&». Кроме того, ко всем успешно разобранным нетерминальным символам сразу после их разбора анализатор добавляет атрибут text, в который помещает ту часть исходной цепочки, которая соответствует рассматриваемому нетерминальному символу. Этот атрибут в дереве разбора скрыт (какая часть цепочки соответствуем нетерминальному символу легко узнать, выполнив щелчок левой кнопкой мыши по узлу дерева).
К названиям нетерминальных символов допустимо приписывать числовой суффикс для различения этих символов в атрибутных правилах. Это требуется, если один и тот же нетерминальный символ встречается в правиле более одного раза и есть атрибутное правило, ссылающееся на него (см. листинг 1, правило 4).
Пустые цепочки следует задавать предопределённым нетерминальным символом _EMPTY. Для упрощения задания непустых буквенно-цифровых последовательностей можно применять встроенный нетерминальный символ _TEXT.
Рассмотрим пример грамматики для распознавания объявлений переменных в стиле языка Си с сохранением типов данных для каждой переменной. Пример такой грамматики показан в листинге 1.
Листинг 1. Пример грамматики.
[1] VarBlock = VarRule VarBlock;
[2] VarBlock = _EMPTY;
[3] VarRule = Type
{ Var.type = Type.text;
VarList.type = Type.text }
' ' Var VarList ';' SPACE;
[4] VarList = { Var.type = VarList.type;
VarList2.type = VarList.type }
',' SPACE Var VarList2;
[5] VarList = _EMPTY;
[6] Type = _TEXT;
[7] Var = _TEXT;
[8] Number = _TEXT;
[9] SPACE = ' ';
[10] SPACE = '\n';
[11] SPACE = _EMPTY;
После того как грамматика набрана, она должна быть сохранена. Имя файла выбирается произвольно, расширение должно быть lat.
Проверка и трансляция
Набранной грамматики
|
из
5.00
|
Обсуждение в статье: Описание и ввод грамматики |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы