 |
Главная |


Теоретические основы построения и анализа уравнения парной регрессии
|
из
5.00
|
Эконометрическое исследование начинается с теории, устанавливающей связь между явлениями. Из всего круга факторов, влияющих на результативный признак, выделяются наиболее существенные факторы. После того, как было выявлено наличие взаимосвязи между изучаемыми признаками, определяется точный вид этой зависимости с помощью регрессионного анализа.
Регрессионный анализ заключается в определении аналитического выражения (в определении функции), в котором изменение одной величины (результативного признака) обусловлено влиянием независимой величины (факторного признака). Количественно оценить данную взаимосвязь можно с помощью построения уравнения регрессии или регрессионной функции.
Базисной регрессионной моделью является модель парной (однофакторной) регрессии. Парная регрессия – уравнение связи двух переменных у и х, записываемое в виде формулы (1.1).
y = f (x) (1.1)
где y – зависимая переменная (результативный признак);
x – независимая, объясняющая переменная (факторный признак).
В зависимости от характера изменения у с изменением х различают линейные и нелинейные регрессии
Аналитическая форма зависимости между изучаемой парой признаков (регрессионная функция) определяется с помощью следующих методов:
1. На основе теоретического и логического анализа природы изучаемых явлений, их социально-экономической сущности. Например, если изучается зависимость между доходами населения и размером вкладов населения в банки, то очевидно, что связь прямая.
2. Графический метод, когда характер связи оценивается визуально.
Эту зависимость можно наглядно увидеть, если построить график, отложив на оси абсцисс значения признака х, а на оси ординат – значения признака у. Нанеся на график точки, соответствующие значениям х и у, получим корреляционное поле:
а) если точки беспорядочно разбросаны по всему полю – это говорит об отсутствии зависимости между этими признаками;
б) если точки концентрируются вокруг оси, идущей от нижнего левого угла в верхний правый – то имеется прямая зависимость между признаками;
в) если точки концентрируются вокруг оси, идущей от верхнего левого угла в нижний правый – то обратная зависимость между признаками.
Построение уравнения регрессии сводится к оценке ее параметров. Эти оценки параметров могут быть найдены различными способами. Одним их них является метод наименьших квадратов (МНК). Суть метода состоит в следующем. Каждому значению x соответствует эмпирическое (наблюдаемое) значение y. Построив уравнение регрессии, например уравнение прямой линии, каждому значению x будет соответствовать теоретическое (расчетное) значение yx. Наблюдаемые значения y не лежат в точности на линии регрессии, т.е. не совпадают с yx. Разность между фактическим и расчетным значениями зависимой переменной называется остатком (см. формула (1.2)):
E = y - yx (1.2)
МНК позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака у от теоретических yx, т.е. сумма квадратов остатков, минимальна (см. формула (1.3)):
 (1.3)
(1.3)
Для линейных уравнений и нелинейных, приводимых к линейным, решается следующая система относительно а и b по формулам (1.4):
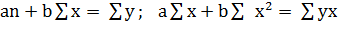 (1.4)
(1.4)
где n – численность выборки.
Решив систему уравнений, получаются значения а и b, что позволяет записать уравнение регрессии (регрессионное уравнение) по формуле (1.5):
 (1.5)
(1.5)
где x – объясняющая (независимая) переменная;
yx – объясняемая (зависимая) переменная;
Параметр b при х имеет большое практическое значение и носит название коэффициента регрессии. Коэффициент регрессии показывает, на сколько единиц в среднем изменяется величина у при изменении факторного признака х на 1 единицу своего измерения. Знак параметра b в уравнении парной регрессии указывает на направление связи:
· если b > 0, то связь между изучаемыми показателями прямая, т.е. с увеличением факторного признаках увеличивается и результативный признак у, и наоборот;
· если b < 0, то связь между изучаемыми показателями обратная, т.е. с увеличением факторного признаках результативный признак у уменьшается, и наоборот.
Значение параметра а в уравнении парной регрессии в ряде случаев можно трактовать как начальное значение результативного признака у. Такая трактовка параметра а возможна только в том случае, если значение х = 0 имеет смысл.
Параметры a и b находятся по формуле (1.6):
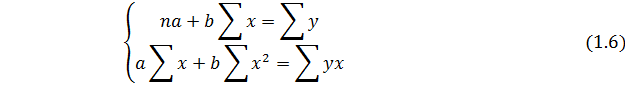
где n – кол-во наблюдений;
 – сумма значений факторного признака;
– сумма значений факторного признака;
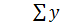 – сумма значений результативного признака;
– сумма значений результативного признака;
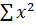 – сумма квадратов значений факторного признака;
– сумма квадратов значений факторного признака;
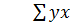 – сумма произведений факторного и результативного признака.
– сумма произведений факторного и результативного признака.
Коэффициент b при факторной переменной x имеет следующую интерпретацию: он показывает, на сколько изменится в среднем величина y при изменении фактора x на 1 единицу измерения. Коэффициент a имеет следующую интерпретацию: он показывает, сколько составит значение y при нулевом влияние фактора x.
Чтобы построенную модель можно было использовать для дальнейших экономических расчетов, проверки качества построенной модели недостаточно. Необходимо также проверить значимость (существенность) полученных с помощью метода наименьших квадратов оценок уравнения регрессии и показателя тесноты связи, т.е. необходимо проверить их на соответствие истинным параметрам взаимосвязи.
Это связано с тем, что исчисленные по ограниченной совокупности показатели сохраняют элемент случайности, свойственный индивидуальным значениям признака. Поэтому они являются лишь оценками определенной статистической закономерности. Необходима оценка степени точности и значимости (надежности, существенности) параметров регрессии. Под значимостью понимают вероятность того, что значение проверяемого параметра не равно нулю, не включает в себя величины противоположных знаков.
Оценка значимости парного уравнения регрессии сводится к проверке гипотез о значимости уравнения регрессии в целом и отдельных его параметров (a, b), парного коэффициента детерминации или индекса корреляции. В этом случае могут быть выдвинуты следующие основные гипотезы H0:
1) a = 0; b = 0 – коэффициенты регрессии являются незначимыми и уравнение регрессии также является незначимым;
2) 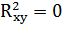 – парный коэффициент детерминации незначим и уравнение регрессии также является незначимым.
– парный коэффициент детерминации незначим и уравнение регрессии также является незначимым.
Альтернативной (или обратной) выступают следующие гипотезы:
1) a ≠ 0; b ≠ 0 – коэффициенты регрессии значимо отличаются от нуля, и построенное уравнение регрессии является значимым;
2) 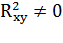 – парный коэффициент детерминации значимо отличаются от нуля и построенное уравнение регрессии является значимым.
– парный коэффициент детерминации значимо отличаются от нуля и построенное уравнение регрессии является значимым.
Тесноту связи изучаемых явлений оценивает линейный коэффициент парной корреляции, принимающий значений (–1 ≤ rxy ≤ 1). Схема расчёта данного показателя представлена в формуле (1.7):
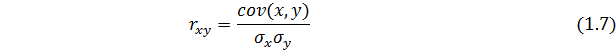
где 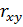 – линейный коэффициент парной корреляции;
– линейный коэффициент парной корреляции;
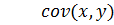 – выборочная ковариация двух переменных x, y;
– выборочная ковариация двух переменных x, y;
 – стандартные отклонения случайных величин x, y.
– стандартные отклонения случайных величин x, y.
Коэффициент детерминации r2xy (для линейной регрессии) или индекс детерминации R2= ρ2xy (для нелинейной регрессии) характеризует долю дисперсии, объясняемую регрессией, в общей дисперсии результативного признака у. Коэффициент детерминации – квадрат коэффициента или индекса корреляции. Для оценки качества построенной модели регрессии можно использовать показатель (коэффициент, индекс) детерминации R2 либо среднюю ошибку аппроксимации. Чем выше показатель детерминации или чем ниже средняя ошибка аппроксимации, тем лучше модель описывает исходные данные. Средняя ошибка аппроксимации представляет из себя среднее относительное отклонение расчетных значений от фактических, схема расчета данного показателя представлена в формуле (1.8):

Где 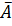 – средняя ошибка аппроксимации;
– средняя ошибка аппроксимации;
y – фактическое значение результативного признака;
 – теоретическое (расчетное) значение результативного признака;
– теоретическое (расчетное) значение результативного признака;
n – кол-во наблюдений;
Построенное уравнение регрессии считается удовлетворительным, если значение A не превышает 10–12 %.
Оценка значимости всего уравнения регрессии в целом осуществляется с помощью F-критерия Фишера.
F-критерий Фишера заключатся в проверки гипотезы H0 о статистической незначимости уравнения регрессии. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера. Схема расчета Fфакт представлена в формуле (1.9):

где  – фактическое значение критерия Фишера;
– фактическое значение критерия Фишера;
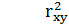 – коэффициент детерминации для линейной регрессии;
– коэффициент детерминации для линейной регрессии;
n – кол-во наблюдений;
m – число параметров при переменных, для линейной регрессии m=1.
Для нелинейно регрессии вместо 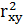 используется R2.
используется R2.
Гипотеза проверяется следующим образом:
1) если фактическое (наблюдаемое) значение F-критерия больше критического (табличного) значения данного критерия Fнабл < Fкр , то с вероятностью 1-а основная гипотеза о незначимости уравнения регрессии или парного коэффициента детерминации отвергается, и уравнение регрессии признается значимым;
2) если фактическое (наблюдаемое) значение F-критерия меньше критического значения данного критерия, Fнабл > Fкр то с вероятностью (1-a) основная гипотеза о незначимости уравнения регрессии или парного коэффициента детерминации принимается, и построенное уравнение регрессии признается незначимым. Критическое значение F-критерия находится по соответствующим таблицам в зависимости от уровня значимости a и числа степеней свободы k1, k2.
Для оценки статистической значимости коэффициентов линейной регрессии и линейного коэффициента парной корреляции rxy применяется t-критерий Стьюдента и рассчитываются доверительные интервалы каждого из показателей. Согласно t-критерию, выдвигается гипотеза Н0 о случайной природе показателей, т. е. о незначимом их отличии от нуля. Далее рассчитываются фактические значения критерия tфакт для оцениваемых коэффициентов регрессии и коэффициента корреляции rxy путем сопоставления их значений с величиной стандартной ошибки. В формулах (1.10), (1.11) и (1.12) представлены схема расчета для t – фактического для коэффициентов a, b и коэффициента корреляции соответственно [3]:

где 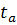 – t-расчетное для коэффициента а;
– t-расчетное для коэффициента а;
а – значение параметра a;
 – стандартная ошибка параметра а.
– стандартная ошибка параметра а.
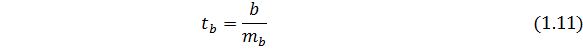
где  – t-расчетное для коэффициента b;
– t-расчетное для коэффициента b;
b – значение параметра b;
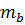 – стандартная ошибка параметра b.
– стандартная ошибка параметра b.
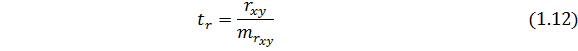
где 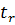 – t-расчетное для коэффициента ;
– t-расчетное для коэффициента ;
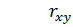 – значение параметра ;
– значение параметра ;
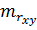 – стандартная ошибка параметра .
– стандартная ошибка параметра .
Сравнивая фактическое и критическое (табличное) значения t-статистики tтабл и tфакт принимают или отвергают гипотезу Н0. tтабл – максимально возможное значение критерия под влиянием случайных факторов при данной степени свободы k = n–2 и уровне значимости α.
Если tтабл < tфакт, то Н0 отклоняется, т. е. a, b и rxy не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора х. Если tтабл > tфакт, то гипотеза Н0 не отклоняется и признается случайная природа формирования а, b или rxy[2].
|
из
5.00
|
Обсуждение в статье: Теоретические основы построения и анализа уравнения парной регрессии |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы