 |
Главная |


Поиск закономерностей для качественных данных. Анализ «хи-квадрат»
|
из
5.00
|
Критерий хи-квадрат используют для проверки гипотез о качественных данных, представленных не числами, а категориями. Здесь принято оперировать подсчетом частоты (поскольку ранжирование или арифметические действия выполнять невозможно).
Критерий (тест) «хи-квадрат» основан на частотах, которые представляют собой количество объектов выборки, попадающих в ту или иную категорию. Суть показателя хи-квадрат (χ2): он измеряет разницу между наблюдаемыми (экспериментальными) частотами fЭ и ожидаемыми (теоретическими) частотами fТ. Конкретно он рассчитывается как сумма квадратов разности этих частот, выраженная в долях частоты теоретической. Это утверждение можно записать следующим образом:
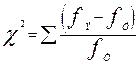
Использование этого статистического подхода рассмотрим на следующем примере.
Мы решили провести маркетинговое исследование, чтобы уяснить, какую марку минеральной воды предпочитают мужчины и женщины. Для каждой покупки фиксировались две качественные переменные – марка воды и пол покупателя. В качестве продаваемой воды фигурировали «Нарзан», «Ессентуки» и «Тагарская».
Полученные данные статистического опроса представлены в табличной форме (табл.4), в которой для каждого вида минеральной воды указано количество совершаемых покупок тем или иным покупателем.
Необходимо дать заключение по итогам статистической проверки по критерию «хи-квадрат», т.е. сформулировать вывод и пояснить результат с практической точки зрения – определить, какую рыночную стратегию необходимо принять, т.е., на какого покупателя и на какую марку минеральной воды необходимо ориентироваться.
Таблица 4.– Экспериментальные данные о результатах опроса
посетителей аптеки
| Марка воды | Частота предпочтений | Итого | |
| Мужчины | Женщины | ||
| Нарзан | |||
| Ессентуки | |||
| Тагарская | |||
| Итого |
Чисто визуально трудно ответить, есть ли взаимосвязь между этими признаками: разными категориями покупателей и марками минеральной воды. Поэтому необходимо дать анализ распределения частот в таблице по строкам и графам.
При этом исходят из следующего положения. Если признак, положенный в основу группировки по строкам (марка минеральной воды), не зависит от признака, положенного в основу группировки по столбцам (пол покупателя), то в каждой строке (столбце) распределение частот должно быть пропорционально распределению их в итоговой строке (столбце). Такое распределение можно рассматривать как теоретическое (ожидаемое), частоты которого рассчитаны в предположении отсутствия связи между изучаемыми совокупностями.
Рассчитаем ожидаемые частоты внутри таблицы пропорционально распределению частот в итоговой строке.
Так, «Нарзан» как одна из марок минеральной воды в зависимости от поведения посетителей аптеки по частоте попадания в категории «Мужчины» и «Женщины» имеет следующие показатели:
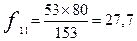 ;
; 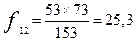
Для второй строки, т.е. для воды «Ессентуки», эти показатели имеют следующие значения:
 ;
; 
Для третей строки – категория «Тагарская»:
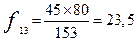 ;
; 
Полученные результаты поместим в таблицу 5.
Таблица 5. – Теоретические данные о результатах опроса
посетителей аптеки
| Марка воды | Частота предпочтений | Итого | |
| Мужчины | Женщины | ||
| Нарзан | 27,7 | 25,3 | |
| Ессентуки | 28,8 | 26,2 | |
| Тагарская | 23,5 | 21,5 | |
| Итого |
|
из
5.00
|
Обсуждение в статье: Поиск закономерностей для качественных данных. Анализ «хи-квадрат» |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы