 |
Главная |


Обеспечивающей появление огня
|
из
5.00
|
| Элемент | Степень необходимости |
| Искра (источник огня) | +98% |
| Горючее вещество | +100% |
| Кислород | +100% |
| Особый температурный режим | +50% |
| Вода | –90% |
| Углекислый газ | –60% |
| Человек | +10% |
| Дрова | +50% |
Степень необходимости, которую мы поставили в данной таблице, естественно, весьма условна, поскольку специализированного научного исследования по этому вопросу мы не проводили. Тем не менее, мы можем четко отследить, какие из этих элементов являются значимыми, а какие нет. Следует отметить, что в психологии коэффициент значимости при факторном анализе составляет |0,7|, то есть 70 %. Иными словами, значимыми являются показатели (с -1,0 по -0,7) и (с +0,7 по +1,0).
Графически, это выглядит следующим образом:
 |
-1 0 +1
| Зона значимых различий | Зона неопределенности | Зона значимых различий |
Рис. 1. Схематичное отображение зон значимых различий и зоны неопределенности.
Теперь представим себе, как мы можем ответить на вопрос, что такое огонь? Мы можем четко сказать, что огонь – это наличие одних элементов и отсутствие других. Иными словами, ключом к методике, направленной на определение того, есть «огонь» или его нет, является перечень элементов, выделенных факторным анализом как «значимые», то есть >|0,7|. Таким образом, факторный анализ позволяет выделить значимые признаки путем математической обработки, а понять, что мы получили в итоге (в нашем случае «огонь») – задача исследователя. В психологии наиболее часто встречается ситуация, когда имеется перечень признаков, и путем их анализа мы должны определить, как можно обозначить то психологическое явление, которое характеризуется наличием или отсутствием этих признаков.
Теперь перенесем этот принцип на процесс разработки методики. Если мы говорим, что методика – это инструментарий, исследующий некое психологическое явление, которое может быть определено как «фактор», то вопросы, входящие в ее состав, должны быть значимыми признаками (элементами) исследуемого фактора. Таким образом, при помощи факторного анализа, мы должны осуществить проверку каждого вопроса на предмет определения его важности для методики в целом.
Факторный анализ позволяет понять, какой ответ на вопрос, положительный или отрицательный, следует считать признаком выраженности, в нашем случае – тревожности. Казалось бы, к чему такие сложности? Зачем осуществлять факторный анализ? Мы и сами могли бы это определить. Но не все так просто. Приведем пример из практики автора.
Занимаясь созданием методики, позволяющей определить, является ли ребенок жертвой насилия, одним из вопросов, которые мы включили в нее, был следующий: «Ты хотел бы что-нибудь изменить в своей жизни?». Мы полагали, что дети – жертвы насилия, безусловно, желали бы, чтобы их жизнь сложилась иначе. Потому ожидалось, что такие дети будут положительно отвечать на этот вопрос более часто по сравнению с детьми, не подвергавшимися насилию.
Однако результаты факторного анализа продемонстрировал противоположное. Дети, ставшие жертвой насилия, отвечали на этот вопрос практически во всех случаях отрицательно. В то время как дети, которые насилию не подвергались, – отвечали наоборот, положительно. Оказалось, что был неучтен тот факт, что дети, попавшие в сложную ситуацию, очень боятся любых перемен, которые, по их мнению, не приведут ни к чему хорошему. Дети, которые насилию не подвергались, не испытывают опасения перед переменами, а потому к ним готовы и желают их в соответствии со своими идеалами и мечтами.
Эти нюансы помогает выявить факторный анализ. Кроме того, факторный анализ позволяет определить, какие задания методики являются значимыми, а какие – несущественными (показатель факторного веса), и, соответственно, какие вопросы следует оставить обязательно, а какие можно удалить. Именно по результатам факторного анализа можно сократить объем первоначального варианта методики до планируемого ранее объема и привести ее в состояние, обеспечивающее внутреннюю согласованность.
Идеальная методика – это методика, которая по результатам факторного анализа выделяет лишь один исследуемый фактор, а все вопросы, входящие в ее состав, являются значимыми.
Факторный анализ в процессе создания реальной методики выполняется по определенному алгоритму, а не «просто посмотрели, подумали и сказали». Проще всего его осуществить при помощи компьютерных программ. На примере одной из них далее будет продемонстрировано, как это может быть сделано.
Приведем пример расчета факторного анализа, выполненного в программе STATISTICA 5.77[16].
Для начала составляем таблицу, в которую заносим: в столбцы – номера вопросов, а в строки – ответы испытуемых, которые принимали участие в процессе апробации методики.
Она будет выглядеть следующим образом:
Таблица 4
Сводная таблица ответов на вопросы
первоначального варианта методики
| Вопрос 1 | Вопрос 2 | Вопрос 3 | и т.д. | |
| Испытуемый 1 | ||||
| Испытуемый 2 | ||||
| Испытуемый 3 | ||||
| Испытуемый 4 | ||||
| и т.д. |
Ответы испытуемых лучше фиксировать в числовом формате. К примеру, 1 – ДА, 0 – НЕТ. При этом необходимо учитывать, что при наличии промежуточного варианта, его необходимо обозначать промежуточным числом. Например: 0 – НЕТ; 1 – НЕ ЗНАЮ; 2 – ДА.
Такую таблицу лучше составить в программе типа MS Excel, входящей в пакет MS Office, так как она может понадобиться нам и для других целей.
Далее, запускаем программу STATISTICA. При этом открывается окно программы (см. Приложение 1, рис. 2).
Программа предлагает нам создать новый документ с именем NEW.STA размером 10х10. Наша задача присвоить файлу новое имя, к примеру – Metodica.STA. Следует учесть, что данная версия программы имеет некоторые ограничения. В частности, не допускается использование русского шрифта, а длина имени файла не должна превышать 8 символов. Переименовать файл (присвоить ему новое имя), можно при помощи команды File => Save as…или путем нажатия клавишиF12 (см. Приложение 1, рис. 3, 4).
Далее, после того, как было присвоено имя нашему файлу, необходимо привести стандартную таблицу 10х10 в тот формат, который нам необходим. К примеру, если в пробном варианте нашей методики было 30 вопросов и мы в процессе ее апробации привлекли 35 человек, то нам необходима таблица 30х35. Для этого на панели инструментов программы присутствуют кнопки Vars, что означает варианты, в нашем случае – столбцы и Cases, что означает случаи или наблюдения, в нашем случае – строки. При нажатии на эти кнопки появляется выпадающее меню, в котором нам необходимо выбрать функцию Add… (добавить)[17] (см. Приложение 1, рис 5).
В появившемся окне мы видим следующие поля: Number of variables to add:, что можно перевести как «количество добавляемых столбцов (вариантов)» и Insert after variable:, что переводится как «вставить после столбца (варианта)». Соответственно, мы записываем 20 вариантов (30 – 10 = 20), после десятого столбца (VAR10).
Аналогичным образом добавляем строки. В итоге мы получаем таблицу с именем Metodica.STA, имеющую формат 30х35 (см. Приложение 1, рис. 6).
Итак, все готово для внесения данных, т.е. заполнения таблицы. Проще всего ее заполнить посредством переноса из программы MS Excel через «буфер обмена».
Если Вам сложно понять, о чем идет речь, просто внесите свои данные в таблицу внутри программы STATISTICA. В результате мы должны получить полностью заполненную таблицу, отражающую все ответы испытуемых на вопросы пробного варианта нашей методики. Для демонстрации мы используем свои данные (см. Приложение 1, рис. 7).
Мы использовали следующий принцип «кодирования» ответов испытуемых: 1 – ответ «НЕТ», 2 – ответ «ДА».
Теперь можно приступать непосредственно к факторному анализу. Для этого необходимо нажать кнопку STATISTICA Module Switcher, которая расположена на панели инструментов самой первой (рис. 8).

рис. 8
Далее в появившемся окне следует выбрать функцию Factor Analуsis и нажать кнопку Switch To (см. Приложение 1, рис. 9), после чего запустится модуль факторного анализа (см. Приложение 1, рис. 10).
Задачей последующих наших действий является определение параметров факторного анализа.
Первое, что нам необходимо определить – это количество исследуемых признаков (вариантов). В нашем случае, естественно, нас интересуют они все, т.е. 30 вариантов (столбцов). Для этого нам необходимо нажать кнопку Variables (см. Приложение 1, рис. 10), а в появившемся окне – выбрать (выделить мышкой или набрать цифрами) все варианты. Также, можно использовать кнопку Select All (см. Приложение 1, рис. 11).
В следующем окне «Define Method of Factor Extraction»(см. Приложение 1, рис. 12), которое появится после нажатия кнопки ОК, нас интересует параметр Maximum no. Of Factors, который задает количество факторов, расчет которых будут осуществляться.
«По умолчанию» в программе стоит «искать 2 фактора». Мы можем либо увеличить их количество, либо уменьшить. Если мы, к примеру, выберем 20 факторов, то вероятнее всего программа не обнаружит 20, просто потому, что их там нет. Их может быть, скажем, 5, 7 или любое другое разумное количество. Данная опция нам интересна тем, что когда мы создавали текст опросника, то полагалось, что все задания направлены на исследование лишь одного фактора, а именно, школьной тревожности в ситуации проверки знаний. На самом же деле мы можем обнаружить, что методика исследует несколько факторов. И это уже нам решать, анализировать или нет по содержанию вопросов, что же именно исследует методика помимо школьной тревожности в ситуации проверки знаний.
Первый выделенный программой STATISTICA фактор, как правило является «нашим», а остальные – второстепенные. В то же время, такое заявление является достаточно условным, так как вполне возможны ситуации, когда «основным» фактором может являться какой-то другой, к примеру, он мог бы быть «школьной тревожностью в ситуации проверки знаний в условиях школы» и не включать вопросы, имеющие отношение к проверке знаний дома, родителями. Это, в свою очередь, может дать повод для размышления, не стоит ли развести эти ситуации, так как они, может быть, не так уж и схожи. Иными словами, факторный анализ может продемонстрировать нам то, что исследуемые вопросы методики исследуют не просто школьную тревожность, а какой-то один, чрезвычайно узкий ее аспект или несколько.
Какой вывод можно сделать, если выделяется не один, а несколько факторов? Скорее всего, для исследования проявления «школьной тревожности в ситуации проверки знаний» нами составлены не совсем корректные вопросы. В этом случае, желательно проанализировать содержание опросника и, возможно, пересмотреть его. Соответственно, необходимо провести апробацию пробного варианта повторно.
Итак, продолжим описание работы с программой. Оставляем количество искомых факторов – 2 и нажимаем ОК (см. Приложение 1, рис. 12).
В следующем появившемся окне Factor Analysis Result (см. Приложение 1, рис. 13) нам предлагается структурировать полученные результаты, для чего необходимо нажать кнопку Factor rotation, а в появившемся меню выбрать функцию Varimax normalized (см. Приложение 1, рис. 14).
После нажатия кнопки Varimax normalized (рис. 14) мы получим результаты факторного анализа (см. Приложение 1, рис. 15).
Красным цветом программа выделяет значимые признаки (в нашем случае это вопросы методики, имеющие значимый факторный вес (превышающий |0,7|)), и указывает «полюс» вопроса, позволяющий составить ключ методики. Иными словами, мы можем определить, за какие (положительные или отрицательные) ответы на вопрос следует начислять баллы.
В нашем примере программа выявила наличие двух факторов (хотя их могло быть и больше). Это означает, что данные вопросы методики исследовали не только школьную тревожность в ситуации проверки знаний, но и что-то еще.
Кроме того, полученные результаты позволяют определить факторный вес вопросов, о котором мы уже говорили ранее.
Однако это не означает, что при создании методики необходимо оставить «значимые» (по результатам факторного анализа) вопросы и удалить «второстепенные». Мы уже отмечали ранее, что существует такой фактор, как влияние содержания предыдущих вопросов на восприятие последующих. Это, в свою очередь, означает, что, убрав из методики какие-то менее значимые вопросы, мы изменим восприятие других, и, возможно, оставшиеся вопросы уже не будут иметь такой значительный факторный вес.
Несмотря на сказанное, на следующем этапе создания методики нам все же придется удалить часть вопросов, а именно те из них, факторный вес которых стремится к нулю. В своей практике мы удаляем вопросы, факторный вес которых менее |0,05|. В данном случае, определяя такой порог, мы исходили из одного из принятых в психологии правил, что уровень статистической значимости большинства экспериментальных исследований составляет 5 % (p=0,05).
После этого необходимо повторно осуществить апробацию методики с ее проверкой при помощи факторного анализа. Если результаты, полученные во втором случае, будут незначительно (не более чем на 15 %) отличаться от результатов первого факторного анализа, можно считать, что мы обеспечили внутреннюю согласованность методики. Иногда, такой способ (повторный факторный анализ) применяется для оценки надежности методики. Однако следует отметить, что это – не самый удачный вариант оценки надежности. Он может применяться лишь в случаях, когда мы не используем метод «парных методик» («параллельных форм»), при котором разрабатываются два взаимозаменяемых варианта одной методики, или мы не в состоянии привлечь испытуемых для повторного тестирования. Последний аргумент, с нашей точки зрения, является несостоятельным, так как сложно представить себе ситуацию, когда психолог не может по объективным причинам найти достаточное количество испытуемых, которые согласились бы дважды пройти один тест с интервалом в 2–3 недели. В целом же, оценку надежности методики следует выделять в отдельный этап, о котором мы поговорим позже.
Следует отметить, что помимо данного варианта определения факторного веса вопросов (при помощи целостного факторного анализа в компьютерной программе), можно вычислить его вручную, для чего используется Коэффициент Вальда: К=10* 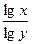 , где: x – количество ответов (отдельно положительных и отрицательных), а y – количество испытуемых, участвовавших в апробации, то есть общее количество ответов на данный вопрос.
, где: x – количество ответов (отдельно положительных и отрицательных), а y – количество испытуемых, участвовавших в апробации, то есть общее количество ответов на данный вопрос.
Или, можно использовать коэффициент приведения моментов Пирсона:

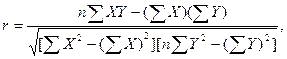
где: r – коэффициент приведения моментов Пирсона; X – результат по каждому заданию; Y – балл (результат) по всему тесту; n – количество попарных произведений.
Помимо этого существует еще целый ряд методов оценки факторного веса вопросов. К примеру, Г. Айзенк использовал при создании своих методик совершенно особый метод. Но его подход представляется автору слишком громоздким, так как предполагает, что для процесса апробации необходимо привлечение испытуемых в количестве из расчета 50 человек на один вопрос методики. Тем не менее, такие способы существуют, и при желании читатель может ознакомиться с ними в специальной литературе.
Завершая описание данного этапа, следует отметить, что при всей его сложности наиболее простым и оперативным является компьютерный вариант факторного анализа. Обычно после освоения программы он занимает не более 5-и минут.
Этап 8.Проверка валидности.
Существует несколько экспериментальных планов, которые могут быть использованы для проверки валидности. В рамках данного пособия будет рассмотрен лишь один из них.
Следует пояснить, почему необходимо привлекать методы экспериментальной психологии. Целью экспериментального исследования в данном случае является выявление причинно-следственной связи между исследуемым психологическим явлением и результатами тестирования. Мы получаем ответ на вопрос, отражается ли изменение выраженности исследуемого признака на результатах, полученных при помощи создаваемой нами методики.
Наиболее простым и в то же время достаточно надежным является экспериментальный план ex-post-facto. Данный план относится к классу квазиэкспериментальных и используется в случаях, когда мы не в состоянии обеспечить необходимое изменение в исследуемом качестве по этическим причинам (более подробно этот вопрос рассмотрен в части, посвященной различным аспектам экспериментальной психологии).
Одной из наиболее существенных проблем, возникающих в ходе использования данного экспериментально плана, является проблема рандомизации[18] экспериментальной и контрольной выборок. Основной вопрос, который возникает в данном случае – каким должен быть объем выборки? Сколько человек достаточно для получения статистически значимых результатов? Казалось бы, «чем больше, тем лучше». Однако, когда человек подвергается значительному психоэмоциональному воздействию факторов стрессогенного характера, у него может наблюдаться как усиление, так и ослабление отдельных черт, суммация которых у всех испытуемых в результате даст нам средние показатели, которые будут, в целом, незначительно отличаться от контрольной группы. Если же экспериментальная группа будет незначительной, то возникает проблема внешней валидности, т.е. ставится под сомнение сама возможность переноса полученных данных на генеральную совокупность. Одновременно, «нейтрализация» побочных факторов (темперамент, уровень образования, социальный статус и т.д.) тем более успешна, чем больший объем выборки мы используем. Одним из способов решения данного вопроса является осуществление параллельного исследования с привлечением нескольких экспериментальных и контрольных групп с последующим перекрестным сопоставлением результатов. Оптимальное количество испытуемых ввиду указанных выше моментов может варьироваться в пределах от 15-20 до 50-70 человек в одной группе в зависимости от специфики исследуемой проблемы.
В нашем случае для осуществления оценки валидности методики, исследующей тревожность школьника в ситуации проверки знаний, нам необходимы две экспериментальных и две контрольных группы по 20 человек в каждой. Почему именно 20? Вопрос справедливый. В данном случае мы исходили из того, что количество вопросов, которые войдут в методику, составляет 20. Но это вовсе не означает, что эти показатели должны быть равны. Испытуемых могло быть и больше, и меньше. Все определяется возможностью привлечения испытуемых к исследованию и особенностями самой проблемы, для диагностики которой разрабатывается методика.
Осуществляя комплектацию экспериментальных групп, необходимо исходить из того, что основным показателем включения человека в группу является наличие у него выраженной школьной тревожности, о которой нам известно заранее (из других источников). Контрольная группа комплектуется в соответствии с половозрастным составом эксперимен-тальной, то есть методом попарного выравнивания.
В результате мы получаем четыре группы по 20 человек, в двух из которых – дети, имеющие выраженные признаки школьной тревожности в ситуации проверки знаний. В контрольную группу входят школьники, соответствующие экспериментальной по половозрастным характеристикам, но о наличии или отсутствии у них школьной тревожности у нас информации нет.
Может возникнуть закономерный вопрос: «Почему так важно, чтобы в контрольную группу входили «случайные дети»? Почему бы не отобрать для сравнения детей, у которых школьная тревожность минимальна? Дело в том, что низкая выраженность одного психологического признака может сопровождаться изменением другого, к примеру, самооценки. Если между ними существует тесная взаимосвязь, то может быть не совсем ясно, исследует методика именно школьную тревожность в ситуации проверки знаний или, к примеру, школьную самооценочную тревожность. Именно поэтому нам необходима контрольная группа, в которую вполне могут входить как школьники с высоким показателем тревожности в ситуации проверки знаний, так и школьники с низкой тревожностью. Элемент случайности в экспериментальном исследовании, как ни парадоксально это звучит, помогает нам установить закономерность, поскольку и другие признаки, как в нашем примере о школьной самооценочной тревожности, будут иметь среднюю, а не крайнюю выраженность. Иначе говоря, кривая распределения как исследуемого нами признака, так и других, в целом, в контрольной группе будет стремиться к виду «нормального распределения»[19]. А это, в свою очередь, является признаком адекватной рандомизации контрольной группы.
Далее, мы осуществляем тестирование всех испытуемых и сравниваем полученные данные при помощи методов математической статистики. Могут быть использованы различные непараметрические критерии, к примеру: U критерий Манна–Уитни, j-критерий Фишера, Q-критерий Розенбаума и т.д. Поскольку данный вопрос достаточно подробно описан в соответствующей литературе[20], нет смысла останавливаться на нем подробно.
Таким образом, целью данного этапа является выявление статистически значимых различий между контрольными и экспериментальными группами.
Этап 9. Верификация методики.
Следующим этапом создания новой методики, который так же, как и предыдущий позволяет оценить ее валидность, является этап верификации. Верификация – особый метод проверки валидности, осуществляемый путем сравнения результатов тестирования испытуемых, осуществленного при помощи различных методик, исследующих одно и то же психологическое явление. Иными словами, необходимо сравнить данные, полученные при помощи нашей методики с данными, полученными при помощи методики, валидность которой известна. Цель – установление наличия значимой положительной корреляции между методиками.
Может возникнуть вопрос, для чего нам дважды проверять валидность методики? Существует следующее требование (выдвигаемое в рамках данного алгоритма создания психодиагностических методик): лишь только в том случае, когда два принципиально различных метода оценки валидности дают схожие результаты, можно быть твердо уверенным в том, что методика действительно является валидной.
В нашем случае мы могли бы использовать, скажем, опросник Филлипса, исследующий школьную тревожность. Одной из шкал этой методики является шкала «страх в ситуации проверки знаний». Как известно, понятия «тревожность» и «страх» являются достаточно близкими, и, поэтому, если наша методика действительно исследует именно школьную тревожность в ситуации проверки знаний, она должна прямо коррелировать с указанной шкалой из методики Филлипса.
Соответственно, мы вновь должны привлечь группу испытуемых. В этом случае нам совершенно неважно, имеют ли они тревожность или нет. Мы ищем корреляции, т.е. взаимосвязь, а не различия. Именно поэтому единственное, что нас интересует, это количество испытуемых и их соответствие возрастной группе, для работы с которой предназначена наша методика.
На проблеме «соответствие возрастной группе» можно не останавливаться, поскольку такое требование является очевидным. Что же касается объема выборки – то чем он выше, тем лучше. Корреляционный анализ может быть осуществлен уже на выборке из трех человек[21]. Однако при такой выборке высока вероятность получения случайных результатов. С нашей точки зрения, минимальный объем выборки должен составлять не менее 15-20 человек. Этот показатель был определен исходя из опыта автора.
Суть данного этапа исследования заключается в следующем. Мы тестируем испытуемых при помощи двух методик (разрабатываемой и «контрольной» в роли которой выступает «Опросник школьной тревожности Филлипса») и при помощи метода линейной корреляции Пирсона[22] оцениваем наличие значимых корреляций между нашей методикой и соответствующей шкалой из методики Филлипса.
Как было отмечено ранее, такого рода расчеты проще всего осуществлять при помощи компьютерных программ, Приведем пример построения корреляционной матрицы при помощи программы STATISTICA 5.77.
Создаем файл Veryfic.STA аналогично, как это показано на рис. 1–5 (см. Приложение 1) с размером Х*У, где Х – количество исследуемых признаков, У – количество участвовавших в работе над данным этапом испытуемых. В нашем случае – 9*20, где 9 = «один признак новой методики» + «восемь шкал методики Филипса». Число «20» означает, что данное количество испытуемых привлекалось к работе над этапом верификации (см. Приложение 1, рис. 16).
Баллы по интересующим нас шкалам были занесены в таблицу: столбец 1 – данные, полученные по нашей методике, столбец 6 – шкала «Страх ситуации проверки знаний» методики Филлипса.
Далее, выбираем Analysis => Correlation matrices и открываем окно Pearson Product-Moment Correlation (см. Приложение 1, рис. 17).
Далее, нажимаем кнопку Correlations и получаем корреляционную матрицу (см. Приложение 1, рис. 18).
Красным цветом выделены значимые корреляции. В нашем случае мы получили значимую корреляцию на уровне 0,66 между нашей методикой и шкалой «Страх ситуации проверки знаний» опросника школьной тревожности Филлипса, что и требовалось. Это позволяет нам сделать вывод о том, что наш опросник является валидным.
Этап 10. Стандартизация метода обработки результатов.
Следующим этапом создания новой методики является этап стандартизации. Необходимо разработать систему перевода сырых баллов в стандартные. Это могут быть «стены» (стандартная десятка), «станайны» (стандартная девятка), «Т-баллы» и многие другие. Принципиальной разницы в том, какой метод стандартизации будет выбран, нет. Более подробно этот вопрос рассмотрен в специальной литературе[23], и поэтому рассматривать его в рамках данной работы нет необходимости.
Этап 11. Стандартизация метода интерпретации результатов.
Предпоследним этапом создания методики является составление стандартизованной интерпретации результатов тестирования в зависимости от суммы набранных баллов. Мы не станем описывать данный этап подробно, поскольку особых трудностей он, как правило, не вызывает. Необходимо обратить внимание на то, что следует описывать не только крайне выраженные показатели (баллы, набранные по шкале), но и средние, и пороговые. Это значительно облегчит работу психологов с методикой.
Этап 12. Стандартизация процедуры тестирования.
И, наконец, последним этапом является разработка и унификация процедуры тестирования. Здесь, в отличие от предыдущих этапов, требуется привлечение как минимум еще одного психолога. Это необходимо для того, чтобы оценить возможность влияния фактора «психолог» на результаты тестирования. Проще говоря, необходимо оценить, не является ли личность психолога решающим фактором, определяющим результаты тестирования. Мы должны осуществить то, что в экспериментальной психологии называется проверкой внешней валидности. Соответственно, привлечением второго психолога мы проверяем, могут ли методикой пользоваться в своей работе и другие психологи.
|
из
5.00
|
Обсуждение в статье: Обеспечивающей появление огня |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы