 |
Главная |


Формула, которая нас объединяет
|
из
5.00
|
В 1999 году руководитель исследования Фредрик Лильерос и его коллеги-математики из Стокгольмского университета представили полученную ими статистику в виде графика и обнаружили поразительно простую зависимость. Почти все 2810 ответов расположились на практически идеальной кривой, как показано на рисунке ниже, продемонстрировав тем самым очевидную закономерность в распределении участников по количеству партнеров.
У подавляющего большинства опрошенных число сексуальных партнеров совсем невелико – вот почему левая часть кривой поднимается высоко вверх. Но среди респондентов было также некоторое количество людей, которые назвали необычно высокое число “побед”, поэтому правая часть кривой плавно приближается к нулевым значениям, но никогда их не достигает. Если шведский опрос репрезентативно представляет население в целом, то такой вид кривой говорит о том, что всегда есть шанс найти кого-то, у кого было сколь угодно большое число сексуальных партнеров. Понятно, что в мире не так уж много людей, у которых было, скажем, десять тысяч или даже “всего” тысяча партнеров, однако график предсказывает, что хотя бы один такой всегда может найтись.
Все это легко сворачивается в одну-единственную формулу, которая позволит предсказать, с каким количеством партнеров переспал каждый из нас. Для произвольно выбранного жителя Земли вероятность иметь больше, чем x партнеров, составляет x –α.
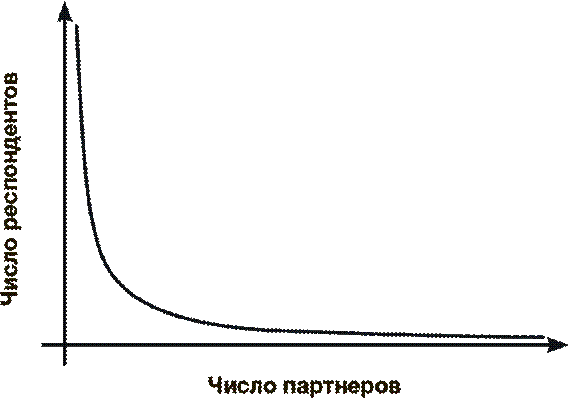

Параметр α рассчитывается по данным опросов. Например, исследователи определили, что для шведской женщины величина α составляет 2,1. Если это значение экстраполировать на весь мир, то вероятность того, что у кого-то было более сотни партнеров, составит 0,006 % – иными словами, это будет всего один человек из 15 800. Вероятность резко уменьшается с увеличением числа предполагаемых партнеров, тем не менее шанс найти кого-то, у кого было более тысячи партнеров, составляет 0,00005 %, то есть это один из двух миллионов человек.
Прежде чем меня окончательно захлестнет волна восторга перед элегантностью математики, стоит остановиться на секунду, чтобы осознать всю важность этих открытий. Пусть мы обладаем свободной волей, пусть наши сексуальные контакты обусловлены довольно сложной совокупностью объективных обстоятельств – и все же, если говорить обо всем человечестве в целом, оказывается, что все наши действия описываются поразительно простой формулой.
Эта формула говорит, что число наших сексуальных партнеров – не совсем случайная величина. Кроме того, эта величина не подчиняется закону нормального распределения – колоколообразной кривой, которая обычно описывает распределение любых средних параметров человека: роста, IQ и так далее. Совсем наоборот: из формулы следует, что число наших сексуальных партнеров описывается так называемой “степенной зависимостью”.
Когда речь идет о росте, почти все мы попадаем в относительно узкий интервал от 150 до 190 см. Конечно, бывают некоторые резкие отклонения, но в целом разница между низкими и высокими людьми не так уж велика. В то же время степенная зависимость охватывает гораздо больший интервал. Если бы число сексуальных партнеров подчинялось тому же самому закону, что и распределение по росту, то вероятность существования героя-любовника, у которого было свыше тысячи партнеров, была бы равна вероятности встретить человека ростом с Эйфелеву башню.
Отчасти вдохновленные этим исследованием, ученые в последние десять лет начали искать – и находить – зависимости, описываемые степенным законом, в самых разных необычных областях. Так, например, картина, аналогичная распределению сексуальных контактов, обнаруживается также в системе перекрестных ссылок между сайтами в интернете, в том, как построены социальные сети в Twitter и Facebook , в том, как расположены слова в предложениях и даже в том, насколько часто и в каких количествах используются в рецептах различные ингредиенты. Все эти разнообразные явления описываются простой формулой x −α.
Причина этого станет понятнее, если мы вернемся к рассмотрению связей в сети. Количество этих связей и отражается в распределении. Степенное распределение создается связями в сети строго определенной формы, известной в математике как безмасштабная сеть[8].
Пример того, как выглядит безмасштабная сеть, представлен на рисунке:

У большинства людей приблизительно одинаковое число связей, однако есть некоторые – темный кружок в середине – у которых связей гораздо больше. Таких людей можно считать “хабами” (узлами) сети, и именно “хабы” делают это распределение похожим на ряд других степенных распределений, на первый взгляд не имеющих ничего общего. Певица Кэти Перри, у которой 57 миллионов фолловеров (по состоянию на сентябрь 2014 года), – крупнейший “хаб” сети Twitter , “Википедия” – крупнейший узел Всемирной паутины, а обычный лук – узел сети рецептов и кулинарных ингредиентов.
Во всех этих случаях узлы развиваются согласно правилу “деньги к деньгам”. Чем больше фолловеров у Кэти Перри, тем больше шансов, что новые поклонники пополнят их ряды.
Аналогично обстоит дело и с сетью сексуальных контактов: чем больше побед одерживают “люди-хабы”, тем выше вероятность, что они сумеют затащить в постель еще большее количество партнеров. Именно “хабы” являются причиной того, что заболевания, передающиеся половым путем, распространяются так быстро и их так трудно контролировать. Если “узел” не принимает соответствующих мер предосторожности, то он сам становится первым кандидатом на заражение, а также, скорее всего, передаст инфекцию дальше по сети. Если вы представите себе, как вирус распространяется по безмасштабной сети, то поймете, какую драматическую роль могут играть “узлы”.
Под колпаком
“Люди-хабы”, подвергающие риску и себя, и своих партнеров, – главные разносчики половых инфекций, однако существует математический прием, позволяющий использовать их самих и структуру сети, чтобы попытаться остановить распространение болезни.
Идея станет понятна, если мы представим себе упрощенную сеть:

Допустим, у нас есть четыре юные принцессы: Золушка, Белоснежка, Русалочка и Спящая красавица. Все они предаются любви с одним и тем же весьма сексуальным Прекрасным принцем и соответственно образуют сеть сексуальных контактов. При этом между дамами никаких сексуальных контактов нет (мы не будем учитывать то, что пишут на некоторых весьма смелых диснеевских фансайтах, и я настоятельно советую вам не посещать такие места, если вы хотите сохранить в чистоте свои невинные детские воспоминания).
Теперь представим, что среди членов группы завелась какая-то неприятная инфекция. Если вакцинация или просвещение каждого члена группы обойдется слишком дорого, мы можем сосредоточиться только на “узле”, как ключевом элементе сети.
Однако, не видя скрытых связей внутри сети, мы сможем понять, что этот человек – Прекрасный принц, только когда опросим всех участников, сколько у каждого из них сексуальных партнеров. Таким образом, задача состоит в том, чтобы, не зная всех участников сети, с наибольшей вероятностью выявить скрытый “узел”.
Если мы выберем кого-то наугад, то шансы, что мы сразу угадаем “хаб”, составляют один к пяти. Но представьте, что вместо этого мы выберем первого попавшегося участника, скажем, Русалочку, и попросим ее помочь нам сделать прививку своему партнеру. Русалочка приведет нас к Прекрасному принцу. Точно так же, если мы случайным образом выберем Золушку и обратимся с той же просьбой, она тоже выведет нас на Принца. Так же поступят Спящая красавица и Белоснежка.
Иными словами, добавив к нашему алгоритму один простой шаг, мы увеличим наши шансы обнаружить “узел” сразу в четыре раза: до четырех шансов из пяти. Гораздо лучше, не так ли?
То же самое относится и к гораздо более обширным сетям. Представьте, что, мы, не имея доступа к статистике Twitter , попытаемся отыскать Кэти Перри – самый большой “хаб” этой социальной сети (на момент написания данной главы).
Если мы возьмем наугад одного из 500 миллионов пользователей Twitter , то наш шанс найти Кэти составит один на 500 миллионов.
Если мы столь же случайным образом выберем пользователя и попросим его назвать нам самого популярного человека, на которого он подписан, то таких может набраться уже 57 миллионов. Внезапно наши шансы найти Кэти подскакивают до 10 % и выше, что очень впечатляет, особенно учитывая, насколько прост алгоритм.
Подобная методика используется для прогнозирования и остановки эпидемий, избавляя медиков от необходимости проводить сложное и дорогое выявление всей сети заболевших. А кроме того, такие расчеты, как мне кажется, рассказывают нам что-то очень важное о том, как просто устроена обширная сеть, которая соединяет всех нас.
Так что в следующий раз, занося новый трофей в свой донжуанский список, подумайте об огромной разветвленной сети, частью которой вы становитесь. Математики не в состоянии помочь вам повысить качество секса, но мы пытаемся – и нам это удается – сократить число инфекционных заболеваний, которые вы можете подхватить.
И разве это само по себе уже не секси?
|
из
5.00
|
Обсуждение в статье: Формула, которая нас объединяет |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы