 |
Главная |


Кластеризация методом K – средних – K – means clustering
|
из
5.00
|
Этот метод кластеризации существенно отличается от иерархических агломеративных методов. Он применяется, если пользователь уже имеет представление относительно числа кластеров, на которые необходимо разбить наблюдения. Тогда метод k – средних строит ровно k различных кластеров, расположенных на возможно больших расстояниях друг от друга.
Рассмотрим работу метода k-средних на данных нашего примера. Щелкнем по строке – K – means clustering (Кластеризация методом k-средних) стартовой панели модуля Cluster analysis (Кластерный анализ) . На экране появится окно настройки параметров кластеризации.

С помощью кнопки Variables (Переменные) выберем показатели, по которым будет происходить кластеризация. В строке Объекты укажем объекты для классификации Cases [rows] (Наблюдения [строки]). Поле Number of clusters (Число кластеров) позволяет ввести желаемое число кластеров, которое должно быть больше 1 и меньше чем количество объектов. Метод k-средних является итерационной процедурой, в результате которой на каждой итерации объекты перемещаются в различные кластеры. Поле Number of iterations (Число итераций) предназначено для указания их максимального числа. Важным моментом при настройке параметров является выбор Initial cluster centers (Начальных центров кластеров), так как конечные результаты зависят от начальной конфигурации.
Опция Choose observations to maximize initial between-cluster distances (Выбрать набл, максимиз. начальные расстояния между кластерами) выбирает первые k в соответствии с количеством кластеров, наблюдений, которые служат центрами кластеров. Последующие наблюдения заменяют ранее выбранные центры в том случае, если наименьшее расстояние до любого из них больше, чем наименьшее расстояние между кластерами. В результате этой процедуры начальные расстояния между кластерами максимизируются. Если выбрана опция Sort distances and take observations at constant intervals (Сортировать расстояния и выбрать наблюдения на постоянных интервалах), то сначала сортируются расстояния между всеми объектами, а затем в качестве начальных центров кластеров выбираются наблюдения на постоянных интервалах.
Choose the first N (Number of cluster) (Выбрать первые N [количество кластеров] наблюдений). Эта опция берет первые N (количество кластеров) наблюдений в качестве начальных центров кластеров. Для нашего примера сделаем установку - Sort distances and take observations at constant intervals (Сортировать расстояния и выбрать наблюдения на постоянных интервалах).
Опция MD deletion (Удаление ПД) устанавливает режим работы с теми наблюдениями (или переменными, если установлен режим Variables (columns)) в строке Объекты, в которых пропущены данные. По умолчанию установлен режим «Построчное». Тогда наблюдения просто исключаются из рассмотрения. Если установить режим Mean subsitution (Заменять на среднее), то вместо пропущенного числа будет использовано среднее по этой переменной (или наблюдению). Если установлена опция Batch processing and reporting (Пакетная обработка и печать), тогда система STATISTICA автоматически осуществит полный анализ и представит результаты в соответствии с установками.
После соответствующего выбора нажмем кнопку OK. STATISTICA произведет вычисления и появится новое окно:
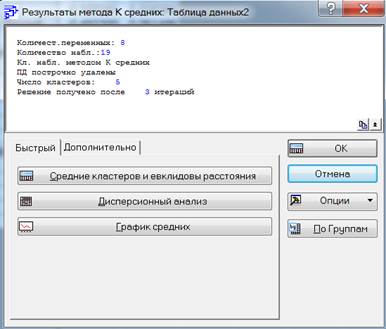
Вывод результатов и их анализ Появившееся окно с результатами классификации условно разделено на две части. В верхней части содержатся значения параметров, по которым проводится анализ, а в нижней – кнопки для вывода результатов.
В верхней части окна (в том же порядке, как они идут на экране):
· Количество переменных - 8;
· Количество наблюдений - 19;
· Классификация наблюдений (или переменных, зависит от установки в предыдущем окне в строке Cluster) методом K - средних;
· Наблюдения с пропущенными данными удаляются или изменяются средними значениями. Зависит от установки в предыдущем окне в строке Удаление ПД.
· Количество кластеров - 5;
· Решение получено после: 3 итераций.
В нижней части окна расположены кнопки для вывода различной информации по кластерам. Analysis of Variance (Дисперсионный анализ). После нажатия появляется таблица, в которой приведена межгрупповая и внутригрупповая дисперсии. Где строки - переменные (наблюдения), столбцы - показатели для каждой переменной: дисперсия между кластерами, число степеней свободы для межклассовой дисперсии, дисперсия внутри кластеров, число степеней свободы для внутриклассовой дисперсии, F - критерий, для проверки гипотезы о неравенстве дисперсий. Проверка данной гипотезы похожа на проверку гипотезы в дисперсионном анализе, когда делается предположение о том, что уровни фактора не влияют на результат.

Итак, значение р<0.05, что говорит о значимом различии.
Cluster Means & Euclidean Distances (средние значения в кластерах и евклидово расстояние). Выводятся две таблицы. В первой указаны средние величины класса по всем переменным (наблюдениям). По вертикали указаны номера классов, а по горизонтали переменные (наблюдения).

Во второй таблице приведены расстояния между классами. И по вертикали и по горизонтали указаны номера кластеров. Таким образом, при пересечении строк и столбцов указаны расстояния между соответствующими классами. Причем выше диагонали (на которой стоят нули) указаны квадраты, а ниже просто евклидово расстояние.

Щелкнув по кнопке Graph of means (График средних), можно получить графическое изображение информации содержащейся в таблице, выводимой при нажатии на кнопку Analysis of Variance (Дисперсионный анализ). На графике показаны средние значения переменных для каждого кластера.

По горизонтали отложены участвующие в классификации переменные, а по вертикали - средние значения переменных в разрезе получаемых кластеров.
Descriptive Statistics for each cluster (Статистика для каждого кластера). После нажатия этой кнопки выводятся окна, количество которых равно количеству кластеров. В каждом таком окне в строках указаны переменные (наблюдения), а по горизонтали их характеристики, рассчитанные для данного класса: среднее, несмещенное среднеквадратическое отклонение, несмещенная дисперсия.
Members for each cluster & distances (Элементы кластеров и расстояния). Выводится столько окон, сколько задано классов. В каждом окне указывается общее число элементов, отнесенных к этому кластеру, в верхней строке указан номер наблюдения (переменной), отнесенной к данному классу и евклидово расстояние от центра класса до этого наблюдения (переменной). Центр класса - средние величины по всем переменным (наблюдениям) для этого класса.
|
из
5.00
|
Обсуждение в статье: Кластеризация методом K – средних – K – means clustering |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы