 |
Главная |


Этап 3. Загрузка и обработка данных
|
из
5.00
|
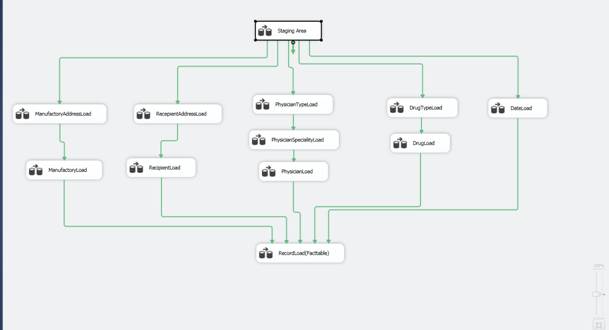
Процесс загрузки
Первый этап – загрузка данных в буферную область (скриншоты файла буферной области представлены в предыдущем пункте). В данной этапе мы берем два файла (формата xlsи csv), в которых все данные находятся на одном листе(в одной ячейке в случае csv). Данные из этих файлов после преобразования типов столбцов(для соответствия с типами данных в базе данных) объединяются оператором union. После этого полученные данные распределяются по листам файла буферной области для более удобной работы с ними в дальнейшем. В итоге получаем таблицу со всеми данными, разделенными по листам в соответствии с таблицами базы данных.

Второй этап – загрузка измерений базы данных. Она происходит последовательно с тем как идут связи таблиц в базе данных. Например, загрузка измерений, связанных с Врачом (Physician) происходит так: сначала загружается последняя в иерархии таблица PhysicianType, затем после успешной ее загрузки загружается таблица PhysicianSpecialty, в которой присутствует внешний ключ Type_ID, связанный с предыдущей таблицей, и в конце сама таблица Physician. В таблицах, которые не связаны напрямую с фактами, используется простая инкрементная загрузка: делается сравнение полученных из excelданных с имеющимися в базе данных по первичному ключу, если записи с таким ключом нет – строка добавляется, если есть – происходит ее обновление. В тех же таблицах которые напрямую связаны с фактами, инкрементная загрузка реализована несколько иначе: старые данные не удаляются, а имеют дату, когда они впервые стали актуальными (DateStart), если же уже существующая строка меняется в источнике, то она добавляется как новая, а старая получает дату окончания актуальности (DateFinish).


Третий этап – загрузка фактов. После загрузки всех измерений происходит загрузка фактов. Для этого опять же берутся данные из источника, после чего с помощью нескольких уточняющих запросов идет их сопоставление с имеющимися данными в измерениях, для того чтобы избежать конфликтов данных. В случае возникновения ошибок, данные ошибок записываются в текстовый файл, для каждого измерения в свой отдельный. При загрузке фактов также реализована инкрементная загрузка без сохранения предыдущих версий.
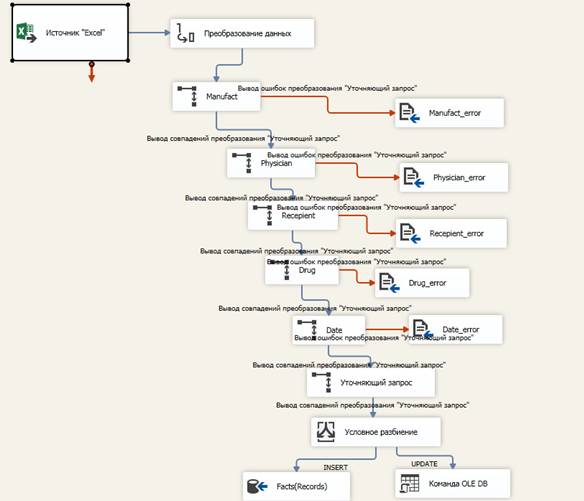
Начальная загрузка происходит из представленных файлов, инкрементная – повторной загрузкой тех же источников. После повторной загрузки мы видим, что ошибок загрузки не появилось и все данные были верно отсортированы в поток обновление (UPDATE).
Начальная загрузка

Все данные переходят в INSERT, так как база данных пуста(Начальная загрузка)


Успешная инкрементная загрузка
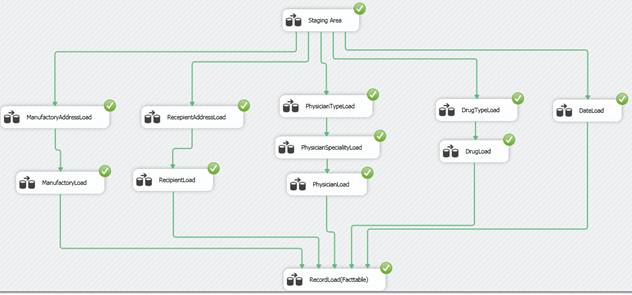 Как видим, так как эти данные уже присутствуют в базе, все строки перешли в поток UPDATE. Ошибок повторной загрузки нет, данные не конфликтуют
Как видим, так как эти данные уже присутствуют в базе, все строки перешли в поток UPDATE. Ошибок повторной загрузки нет, данные не конфликтуют 

|
из
5.00
|
Обсуждение в статье: Этап 3. Загрузка и обработка данных |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы