 |
Главная |


Исходные данные и результаты. Массовость алгоритма
|
из
5.00
|
Итак, мы в «джунглях». Но чтобы в них ориентироваться, нужно понять, что такое алгоритм. Приведенные выше примеры уже позволяют осуществить некоторый анализ; еще ряд примеров содержит глава 2, в которую можно «подглядывать».
Сразу бросается в глаза, что каждый алгоритм предполагает наличие некоторых исходных данных и приводит к получению определенного искомого результата. Например, в § 1 для алгоритма приготовления детской пищи исходными данными являются порции кефира (50 г), крупяного отвара (45 г) и сахарного песка (5 г), а результатом — соответствующее количество детской пищи (очевидно, 100 г). Для медицинского рецепта (алгоритма) исходным данным является медикамент арпенал, используемый для лечения язвы желудка, а результатом—-коробочка с двадцатью таблетками и надписью «по 1 таблетке 3 раза в день». Для алгоритма сложения исходным данным является пара слагаемых (чисел), а результатом—сумма (опять число).
Создается впечатление, что каждый алгоритм — это правило, указывающее действия, в результате цепочки которых от исходных данных мы приходим к искомому результату. Такая цепочка действий называется алгоритмическим процессом, а каждое действие — его шагом.
Можно подумать, что каждый алгоритм задает вполне определенный процесс. К сожалению, не совсем так. Только для самых простых алгоритмов можно говорить об определенных алгоритмических процессах. Для более сложных алгоритмов (мы это увидим на стр. 20) указать определенный процесс нельзя. Но для тех алгоритмов, о которых мы уже говорили, существование такого процесса не вызывает сомнения. Поэтому пока мы говорим о наиболее простых алгоритмах; будем считать, что каждый из них задает вполне определенный алгоритмический процесс.
Но вернемся к анализу тех предметов, которые могут быть исходными данными и результатами. Очевидно, для каждого алгоритма можно брать различные варианты исходных данных. Это видно из того, что, например, для алгоритма приготовления детской пищи можно слова «граммы» при описании исходных данных понимать как «весовые части». Качество получаемой пищи при этом не изменится. Может измениться только ее количество. Для рецепта приготовления лимонного желе, очевидно, так и сделано. Многие алгоритмы остаются в силе для различных вариантов исходных данных. Алгоритм сложения можно применить к парам любых положительных чисел. Алгоритм дополнительного кормления щенят годится не только, например, для Рексика и Бобика, но и для других щенят.
Замеченное нами свойство алгоритмов, перечисленных в § 1 (их применимость к большому числу вариантов исходных данных), называют их массовостью. Долгое время считали, что пригодность алгоритмов для многих частных случаев является настолько существенной и важной их чертой, что должна войти в научное определение алгоритма. Это исключало[6] многие правила из компетенции науки (из-за их «недостаточной» массовости) и затрудняло[7] как научные исследования, так и применение их результатов на практике (а вдруг перед нами именно ненаучный случай?), что представляет собой серьезные неудобства.
А между тем ценность представляют и правила (алгоритмы), применимые даже только к одному-единственному варианту исходного данного. К их числу относятся алгоритмы пользования различными автоматами (например, автоматом, продающим газеты, или телефоном-автоматом, если они рассчитаны на одну определенную монету), алгоритмы следования по маршруту, начинающемуся в определенном пункте и ведущему в заданное место, и многие другие. Ценность подобных алгоритмов настолько широко известна, что они положены в основу сюжетов многих литературных произведений (вспомним рассказы о кладоискателях).
Расплывчатость термина «массовость» подтверждается известным парадоксом Эвбулида, который иногда называют парадоксом кучи. Сущность его можно передать, задавая себе ряд вопросов и тут же отвечая на них. Один камень — это куча? Нет. А два камня? Тоже нет. А три? В конце концов мы либо придем к выводу, что куч не существует, либо вынуждены будем признать, что есть такое число камней, увеличение которого на единицу приводит к получению кучи. И то и другое противоречит фактам и является следствием расплывчатости понятия кучи. И все же просто «отмахнуться» от свойства массовости нельзя. Нужно несколько изменить его трактовку, с тем чтобы устранить указанные выше неудобства.
Какой же смысл следует вкладывать в термин «массовость»? А вот какой. Нужно считать, что для каждого алгоритма существует некоторый класс объектов, шаги этого процесса бывают достаточно простыми, а их число не очень большим. Практически число совершенных шагов связано с количеством затраченного на их выполнение времени, а может быть (да и наверное так!), с расходом ряда других ресурсов.
Следует ли при изучении алгоритмов задать для числа шагов какую-нибудь раз и навсегда выбранную границу? Если допустить алгоритмы, выполнение которых требует, например, ста шагов, то почему не допустить и такие, которые потребуют ста одного шага, ста двух шагов и т. д.? Тем более, что развитие науки и техники делает нас богаче ресурсами и позволяет сегодня выполнять различные действия быстрее, чем это было возможно вчера.
Отвлекаясь от реальной ограниченности времени и ресурсов, которыми мы располагаем, будем требовать лишь того, чтобы алгоритмический процесс оканчивался после конечного числа шагов и чтобы на каждом шаге не было препятствий для его выполнения. В этом случае и будем считать, что алгоритм применим к исходному данному.
Так как требование завершения алгоритмического процесса за конечное число шагов не учитывает реальных возможностей, связанных с затратами времени и расходованием ресурсов, то говорят, что при этом алгоритм потенциально (а не реально) выполним.
Неприменимость алгоритма к допустимому исходному данному будет заключаться в том, что алгоритмический процесс либо никогда не оканчивается (при этом говорят, что процесс бесконечен), либо его выполнение во время одного из шагов наталкивается на препятствие (при этом . говорят, что он безрезультатно обрывается).
Проиллюстрируем оба эти случая. Приведем пример бесконечного алгоритмического процесса. Всем известен алгоритм деления десятичных дробей. Числа 4,2 и 3 являются для него допустимыми исходными данными. При этом получается следующий процесс:

Искомый результат равен 1,4. Но совсем иная картина получится для чисел 20 и 3, которые тоже представляют собой допустимые исходные данные. Для них получится такой процесс:
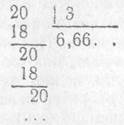
Сколько бы ни продолжался процесс, он не заканчивается и не встречает препятствий. Оказывается, что нельзя получить для исходных данных 20 и 3 искомого результата. Если же оборвать процесс по произволу, то его результат будет только приближением к частному, но не частным. Кстати, алгоритм, предусматривающий обрыв процесса на каком-то шаге, уже не будет тем алгоритмом, который мы рассматриваем.
Теперь приведем пример безрезультатно обрывающегося процесса. Представьте себе, что алгоритм состоит из нескольких более простых предписаний, обычно называемых пунктами.
1. Исходное данное умножить на 2. Перейти к выполнению п. 2.
2. К полученному числу прибавить единицу. Определить остаток у от деления этой суммы на 3. Перейти к выполнению п. 3.
3. Разделить исходное данное на у. Частное является искомым результатом. Конец.
Пусть целые неотрицательные числа (так называемые натуральные) будут допустимыми исходными данными для этого алгоритма.
Для числа 6 алгоритмический процесс будет протекать так.
Первый шаг: 6-2=12; переходим к п. 2.
Второй шаг: 12+1 = 13; у=1; переходим к п. 3.
Третий шаг: 6 : 1=6. Конец.
Искомый результат равен 6. Иначе будет протекать алгоритмический процесс для исходного данного 7.
Первый шаг: 7-2=14; переходим к п. 2.
Второй шаг: 14+1 = 15; у=0; переходим к п. 3.
Третий шаг: 7:0 — деление невозможно. Процесс натолкнулся на препятствие и безрезультатно оборвался.
Подчеркнем еще раз, что на практике всегда требуется реальная выполнимость алгоритма, мы же требуем лишь потенциальной выполнимости. Это связано с определенной абстракцией.
Понятность алгоритма
Анализируя интуитивное понятие алгоритма, мы замечаем еще одну особенность. Предполагается, что исполнитель правила всегда знает, как его выполнять. Говорят, что алгоритм понятен для исполнителя. В первых книгах по теории алгоритмов говорится даже об их общепонятности. С таким утверждением согласиться нельзя. Даже свойство понятности не так просто, как кажется на первый взгляд.
Представим себе, что нами получен некоторый письменный текст. Можно ли утверждать, что он понятен и в каких случаях? Если алфавит, буквы которого использованы в тексте, нам незнаком, то ответ будет один: текст непонятен. Но если все буквы принадлежат знакомому алфавиту, может оказаться, что составляющие его слова нам незнакомы. В этом случае текст тоже непонятен. А если все слова знакомы? Тогда возникает вопрос о способе их соединения в предложения. Если он противоречит грамматическим правилам, опять текст непонятен. А если все грамматические правила соблюдены? В этом случае неизвестно, понятен текст или нет. Ведь может оказаться, что он является кодом какого-то другого текста и его скрытый истинный смысл не совпадает с его непосредственным смыслом. Если о тексте (кроме него самого) ничего не известно, то назвать его понятным нельзя. Если известно, что текст представляет собой алгоритм, то неопределенность его уменьшается, но незначительно. Полная ясность будет лишь тогда, когда будет известно, что надо делать для того, чтобы этот алгоритм выполнить.
Свойство понятности можно, таким образом, истолковать как наличие алгоритма, определяющего процесс выполнения алгоритма, заданного в виде текста. Такое объяснение «понятности» позволяет предположить, что не только люди, но и животные и некоторые машины могут быть исполнителями алгоритмов.
Итак, каждому исполнителю известен алгоритм, которым нужно руководствоваться для выполнения других алгоритмов, адресованных исполнителям его класса. Исполнитель может этот алгоритм знать, например, если он человек, или может быть так дрессирован, чтобы его выполнять, если он животное, или может быть так устроен, чтобы его выполнять, если он машина.
В дальнейшем (гл. 9, § 4) читатель узнает, что про некоторые машины (ЭВМ) по отношению к некоторым алгоритмам выполнения алгоритмов (операционным системам) так и напрашивается антропоморфическое выражение «она' его знает». И все же даже у этих машин механизм понимания алгоритмов не тот, что у людей.
Может показаться, что, разъясняя понятие алгоритма, мы апеллировали к этому же понятию и допустили некорректное рассуждение, называемое порочным кругом. В данном случае это не так (см. § 5).
|
из
5.00
|
Обсуждение в статье: Исходные данные и результаты. Массовость алгоритма |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы