 |
Главная |


Реляционная модель данных
|
из
5.00
|
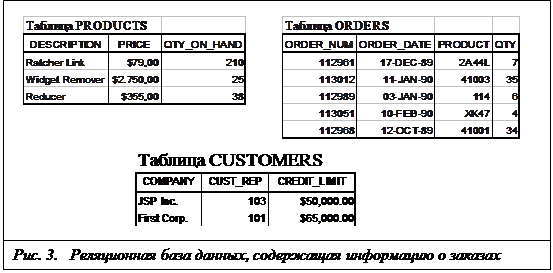
Недостатки иерархической и сетевой моделей привели к появлению новой, реляционной модели данных, созданной Коддом в 1970 году и вызвавшей всеобщий интерес. Реляционная модель была попыткой упростить структуру базы данных. В ней отсутствовали явные указатели на предков и потомков, а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы. На рис. 3. показана реляционная версия сетевой базы данных, содержащей информацию о заказах и приведенной на рис. 2.
К сожалению, практическое определение понятия "реляционная база данных" оказалось гораздо более расплывчатым, чем точное математическое определение, данное этому термину Коддом в 1970 году. В первых реляционных СУБД не были реализованы некоторые из ключевых частей модели Кодда, и этот пробел был восполнен только впоследствии. По мере роста популярности реляционной концепции реляционными стали называться многие базы данных, которые на деле таковыми не являлись.
В ответ на неправильное использование термина "реляционный" Кодд в 1985 году написал статью, где сформулировал 12 правил, которым должна удовлетворять любая база данных, претендующая на звание реляционной. С тех пор двенадцать правил Кодда считаются определением реляционной СУБД. Однако можно сформулировать и более простое определение:
Реляционной называется база данных, в которой все данные, доступные пользователю, организованны в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами.
Приведенное определение не оставляет места встроенным указателям, имеющимся в иерархических и сетевых СУБД. Несмотря на это, реляционная СУБД также способна реализовать отношения предок/потомок, однако эти отношения представлены исключительно значениями данных, содержащихся в таблицах.
Поскольку в программной реализации дипломной работы избран реляционный подход, как наиболее подходящий, опишем его более подробно.[3, 7, 8, 12].
Таблицы
Таблицы – фундаментальные объекты реляционной базы данных, в которых хранится основная часть данных приложения. Отдельная таблица чаще всего хранит информацию по конкретной теме (например, сведения о служащих компании или адреса заказчиков). Информация в таблице организуется в строки (записи) и столбцы (поля). Таблице присущи два компонента: структура таблицы и данные таблицы.
Структура таблицы (также называется определением таблицы) специфицируется при создании таблицы. Структура таблицы должна быть спроектирована и создана перед вводом в таблицу каких-либо данных. Она определяет, какие данные таблица будет хранить, а также правила, ассоциированные с вводом, изменением или удалением данных (бизнес-правила, или ограничения).
Структура таблицы включает следующую информацию:
· Имя таблицы - Имя, по которому к таблице можно обратиться в свойствах, методах и операторах SQL.
· Столбцы таблицы - Категории информации, сохраненной в таблице. Каждый столбец имеет имя и тип данного.
· Табличные и столбцовые ограничения - Ограничения целостности, определенные на уровне таблицы или на уровне столбца.[3, 7, 8, 12].
 |
Более наглядно структуру таблицы иллюстрирует рис 4., на котором изображена таблица STUDENTS. Каждая горизонтальная строка этой таблицы представляет отдельную физическую сущность - одного студента. Все данные, содержащиеся в конкретной строке таблицы, относятся к студенту, который описывается этой строкой.
Каждый вертикальный столбец таблицы STUDENTS представляет один элемент данных для каждого из студентов. Например, в столбце GROUP содержатся номера групп, в которых расположены студенты. В столбце DATE содержатся даты рождения каждого студента.
Данные таблицы – информация, которая сохранена в таблице. Все данные таблицы хранятся в строках, каждая из которых содержит порции информации в столбцах, определенных в структуре таблицы. Данные – та часть таблицы, к которой обычно должны иметь доступ пользователи приложения (например, данные таблицы могут выводиться в элементах управления, размещенных в формах и отчетах).
На пересечении каждой строки с каждым столбцом таблицы содержится в точности одно значение данных. Например, во второй строке в столбце FAMILY содержится значение "ИВАНОВ". В столбце PODGRP той же строки содержится значение 1, которое является номером подгруппы, в которой находится данный студент.
Все значения, содержащиеся в одном и том же столбце, являются данными одного типа. Например, в столбце FAMILY содержатся только слова, в столбце DATE содержатся даты, а в столбце NUMBER содержатся целые числа, представляющие идентификаторы студентов. Множество значений, которые могут содержаться в столбце, называется доменом этого столбца. Доменом столбца FAMILY является множество фамилий студентов. Доменом столбца DATE является любая дата.
У каждого столбца в таблице есть своё имя, которое обычно служит заголовком столбца. Все столбцы в одной таблице должны иметь уникальные имена, однако разрешается присваивать одинаковые имена столбцам, расположенным в различных таблицах. На практике такие имена столбцов, как NUMBER, FAMILY, NAME, GROUP, DATE, PODGRP, часто встречаются в различных таблицах одной базы данных.
Столбцы таблицы упорядочены слева направо, и их порядок определяется при создании таблицы. В любой таблице всегда есть как минимум один столбец. В стандарте ANSI/ISO не указывается максимально допустимое число столбцов в таблице, однако почти во всех коммерческих СУБД этот предел существует и обычно составляет примерно 255 столбцов.
В отличие от столбцов, строки таблицы не имеют определённого порядка. Это значит, что если последовательно выполнить два одинаковых запроса для отображения содержимого таблицы, нет гарантии, что оба раза строки будут перечислены в одном и том же порядке.
В таблице может содержаться любое количество строк. Вполне допустимо существование таблицы с нулевым количеством строк. Такая таблица называется пустой. Пустая таблица сохраняет структуру, определённую её столбцами, просто в ней не содержится данные. Стандарт ANSI/ISO не накладывает ограничений на количество строк в таблице, и во многих СУБД размер таблиц ограничен лишь свободным дисковым пространством компьютера. В других СУБД имеется максимальный предел, однако он весьма высок - около двух миллиардов строк, а иногда и больше.[12].
Ключевые поля
Мощь реляционных баз данных заключается в том, что с их помощью можно быстро найти и связать данные из разных таблиц при помощи запросов; форм и отчетов. Для этого каждая таблица должна содержать одно или несколько полей, однозначно идентифицирующих каждую запись в таблице. Эти поля называются ключевыми полями таблицы. Ключевые поля ещё также называют первичным ключом. Можно выделить три типа ключевых полей: счетчик, простой ключ и составной ключ.
Поскольку строки в реляционной таблице не упорядочены, нельзя выбрать строку по ее номеру в таблице. В таблице нет "первой", "последней" или "тринадцатой" строки. Тогда каким же образом можно указать в таблице конкретную строку, например строку для студента с фамилией Иванов?
Ключевое поле можно задать таким образом, чтобы при добавлении каждой записи в таблицу в это поле автоматически вносилось порядковое число, т.е. организовать счётчик. Это наиболее простой способ создания ключевых полей.
Если поле содержит уникальные значения, такие как коды или инвентарные номера, то это поле можно определить как простой ключ. Если выбранное поле содержит повторяющиеся или пустые значения, то оно не будет определено как ключевое. Для определения записей, содержащих повторяющиеся данные, можно выполнить запрос на поиск повторяющихся записей. Если устранить повторы путем изменения значений невозможно, то следует либо добавить в таблицу поле счетчика и сделать его ключевым, либо определить составной ключ.[3, 7, 8, 12].
На первый взгляд, первичным ключом таблицы STUDENTS могут служить и столбец FAMILY. Однако в жизни довольно часто встречаются однофамильцы, следовательно, столбец FAMILY больше не может выполнять роль ключа. На практике в качестве первичных ключей таблиц обычно следует выбирать идентификаторы, такие как идентификатор студента NUMBER в таблице STUDENTS.
 |
Таблица ORDERS, фрагмент которой показан на рис. 5., является примером таблицы, в которой первичный ключ представляет собой комбинацию столбцов. Такой первичный ключ называется составным ключом.
Он применяется в случаях, когда невозможно гарантировать уникальность значений каждого отдельного поля. Чаще всего такая ситуация возникает для таблицы, используемой для связывания двух таблиц в отношении "многие-ко-многим".
Столбец NSTUD содержит идентификаторы студентов, перечисленных в таблице, а столбец NORDER содержит номера, приказам. Может показаться, что столбец NORDER мог бы и один выполнять роль первичного ключа, однако ничто не мешает одному студенту несколько раз попасть под отчисление и затем восстановиться на факультете. Таким образом, в качестве первичного ключа таблицы ORDERS необходимо использовать комбинацию столбцов NSTUD и NORDER. Для каждого из студентов, содержащихся в таблице, комбинация значений в этих столбцах будет уникальной.
Первичный ключ для каждой строки таблицы является уникальным, поэтому в таблице с первичным ключом нет двух совершенно одинаковых строк. Таблица, в которой все строки отличаются друг от друга, в математических терминах называется отношением. Именно этому термину реляционные базы данных и обязаны своим названием, поскольку в их основе лежат отношения (таблицы с отличающимися друг от друга строками).
Хотя первичные ключи являются важной частью реляционной модели данных, в первых реляционных СУБД (System/R, DB2, Oracle и других) не была обеспечена явным образом их поддержка. Как правило, проектировщики базы данных сами следили за тем, чтобы у всех таблиц были первичные ключи, однако в самих СУБД не было возможности определить для таблицы первичный ключ. И только в СУБД DB2 Version 2, появившейся в апреле 1988 года, компания IBM реализовала поддержку первичных ключей. После этого подобная поддержка была добавлена в стандарт ANSI/ISO.[3, 7, 8, 12].
Индексы
Индексы – объекты базы данных, которые обеспечивают быстрый доступ к отдельным строкам в таблице. Индекс создается с целью повышения производительности операций запросов и сортировки данных таблицы. Индексы также используются для поддержания в таблицах некоторых типов ключевых ограничений; эти индексы часто создаются автоматически при определении ограничения.
Индекс – независимый объект, логически отдельный от таблицы; создание или удаление индекса никак не воздействует на определение или данные индексированной таблицы. Он хранит высоко оптимизированные версии всех значений одного или больше столбцов таблицы. Когда значение запрашивается из индексированного столбца, процессор (ядро) базы данных использует индекс для быстрого нахождения требуемого значения. Индексы должны постоянно поддерживаться, чтобы отражать последние изменения индексированных столбцов таблицы. Процедуры обновления индекса при вставке, модификации или удалении значения в индексированный столбец автоматически выполняются процессором базы данных. Хотя эти операции не требуют никаких действий со стороны пользователя, они, однако, снижают эффективность некоторых операций манипулирования данными (кроме запросов на выборку). Однако уменьшение производительности, ассоциированное с поддержанием индекса, в большинстве случаев с лихвой компенсируется преимуществами повышения быстродействия доступа к данным, которое обеспечивает индекс. Индексы обеспечивают наибольшие выгоды для относительно статичных таблиц, по которым часто выполняются запросы.
Создать индексы, как и ключи, можно по одному или нескольким полям. Составные индексы позволяют при отборе данных группировать записи, в которых первые поля могут иметь одинаковые значения. Индексировать поля требуется для выполнения частых поисков, сортировок или объединений с полями из других таблиц в запросах. Ключевые поля таблицы индексируются автоматически. Нельзя индексировать поля с типом данных поле МЕМО, гиперссылка или объект OLE. Для остальных полей индексирование используется, если поле имеет текстовый, числовой, денежный тип или тип даты/времени и требуется осуществлять поиск и сортировку значений в поле. Если предполагается, что будет часто выполняться сортировка или поиск одновременно по двум и более полям, можно создать составной индекс. Например, если для одного и того же запроса часто устанавливается критерий для полей Имя и Фамилия, то для этих двух полей имеет смысл создать составной индекс. При сортировке таблицы по составному индексу сначала осуществляется сортировка по первому полю, определенному для данного индекса. Если в первом поле содержатся записи с повторяющимися значениями, то сортировка осуществляется по второму полю и т. д.[3, 7, 8, 12].
|
из
5.00
|
Обсуждение в статье: Реляционная модель данных |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы