 |
Главная |


Назначение и структура хранилища данных
|
из
5.00
|
Хранилище данных (Data Warehouse) — предметно-ориентированная информационная база данных, специально разработанная и предназначенная для подготовки отчётов и бизнес-анализа с целью поддержки принятия решений в организации [22, 23, 24, 25].
К хранимым данным предъявляются следующие основные требования.
Интегрированность. Данные объединены так, чтобы они удовлетворяли всем требованиям предприятия в целом, а не единственной функции бизнеса.
Некорректируемость. Данные в хранилище данных не создаются: то есть поступают из внешних источников, не корректируются и не удаляются.
Зависимость от времени. Данные в хранилище точны и корректны только в том случае, когда они привязаны к некоторому промежутку или моменту времени.
Основным источниками данных для хранилищ является базы данных, содержащие первичную информацию о деятельности предприятия. Поскольку сами хранилища используются независимо от процедур их формирования, то принципиально допустимы любые источники, лишь бы получаемая из них информация была согласована на момент создания или коррекции хранилища.
Сами хранилища могут быть организованы в виде набора нормализованных или ненормализованных таблиц.
Ядро хранилища данных образует таблица фактов, представляющая OLAP-куб, измерения куба описываются таблицами измерений. Наиболее естественным представлением является такое, при котором каждому измерению, используемому при анализе, соответствует своя таблица измерений. Таблицы измерений при такой организации, как правило, не нормализованы.
Схема такого построения представлена на рис. 12.1 и носит название «звезда».

Рис. 12.1. Схема звезда
Любое хранилище данных может быть представлено такой схемой. В то же время отдельные измерения могут быть зависимыми, так город входит в страну и так далее. В этом смысле включение страны в список измерений влечет за собой рост размерности куба. Формально массив мер куба содержит Nm= n1* n2*…* nm элементов. Добавление нового m+1 измерения с nm+1 значением порождает новый куб с Nm+1 = Nm* nm+1 элементами. При наличии десятка или более измерений количество элементов куба становится катастрофически большим, поэтому для представления куба используют различные методы сжатия, основанные на хранении только ненулевых элементов, но и в этом случае добавление новых измерений сопряжено с нежелательным ростом объемов хранимой информации. В этом случае для части измерений возникают консолидирующие таблицы измерений.
Альтернативой хранения измерений, как независимых, можно строить нормализованную (или частично нормализованную) систему таблиц измерений.
Схема такого построения представлена на рис. 12.2 и носит название «снежинка». Нормализация таблиц измерений обычно приводит хранилище именно к такой схеме. В схеме «снежинка» обеспечивается более компактное хранение данных, но операции с хранилищем оказываются более сложными.
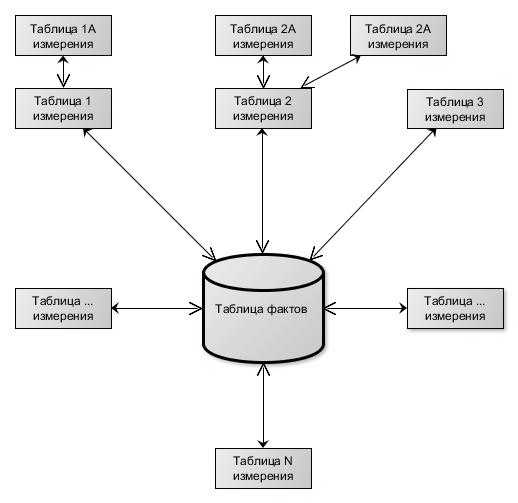
Рис. 12.2. Схема снежинка
Рассмотрим основные операции с OLAP-кубом.
Операция консолидации состоит в агрегировании по каким-либо измерениям, как это ранее рассматривалось.
Операция детализации состоит во вводе новых измерений детализирующих информацию. Такой ввод новых измерений предполагает, что ранее эти данные были включены в главное хранилище.
Схема операций консолидации и детализации представлена на рис. 12.3.

Рис 12.3. Операции консолидации и детализации
Операция вращения состоит в изменения порядка измерений куба и, возможно изменения упорядочения значений по измерениям. Схема операции вращения представлена на рис. 12.4.

Рис 12.4. Операция вращения
Операция среза состоит в выделении из куба по каким-либо измерениям отдельных значений или множеств значений для формирования нового куба. Схема операции среза представлена на рис. 12.5.

Рис 12.5. Операция среза
При создании хранилища можно рекомендовать использование правил Кодда [26]. К базовым правилам относятся следующие 12.
1. Многомерность - OLAP-система на концептуальном уровне должна представлять данные в виде многомерной модели, что упрощает процессы анализа и восприятия информации.
2. Прозрачность - OLAP-система должна скрывать от пользователя реальную реализацию многомерной модели, способ организации, источники, средства обработки и хранения.
3. Доступность OLAP-система должна предоставлять пользователю единую, согласованную и целостную модель данных, обеспечивая доступ к данным независимо от того, как и где они хранятся.
4. Постоянная производительность при разработке отчетов - производительность OLAP-систем не должна значительно уменьшаться при увеличении количества измерений, но которым выполняется анализ.
5. Клиент-серверная архитектура - OLAP-система должна быть способна работать в среде «клиент-сервер», так как большинство данных, которые сегодня требуется подвергать оперативной аналитической обработке, хранятся распределенно. Главной идеей здесь является то, что серверный компонент инструмента OLAP должен быть достаточно интеллектуальным и позволять строить общую концептуальную схему на основе обобщения и консолидации различных логических и физических схем корпоративных БД для обеспечения эффекта прозрачности.
6. Равноправие измерений - OLAP-система должна поддерживать многомерную модель, в которой все измерения равноправны. При необходимости дополнительные характеристики могут быть предоставлены отдельным измерениям, но такая возможность должна быть предоставлена любому измерению.
7. Динамическое управление разреженными матрицами - OLAP-система должна обеспечивать оптимальную обработку разреженных матриц. Скорость доступа должна сохраняться вне зависимости от расположения ячеек данных и быть постоянной величиной для моделей, имеющих разное число измерений и различную степень разреженности данных.
8. Поддержка многопользовательского режима - OLAP-система должна предоставлять возможность работать нескольким пользователям совместно с одной аналитической моделью или создавать для них различные модели из единых данных, при этом возможны как чтение, так и запись данных, поэтому система должна обеспечивать их целостность и безопасность.
9. Неограниченные перекрестные операции - OLAP-система должна обеспечивать сохранение функциональных отношений, описанных с помощью определенного формального языка между ячейками гиперкубов при выполнении любых операций среза, вращения, консолидации или детализации. Система должна самостоятельно (автоматически) выполнять преобразование установленных отношений, не требуя от пользователя их переопределения.
10. Интуитивная манипуляция данными - OLAP-система должна предоставлять способ выполнения операций среза, вращения, консолидации и детализации над гиперкубом без необходимости пользователю совершать множество действий с интерфейсом. Измерения, определенные в аналитической модели, должны содержать всю необходимую информацию для выполнения вышеуказанных операций.
11. Гибкие возможности получении отчетов - OLAP-система должна поддерживать различные способы визуализации данных, т. е. отчеты должны представляться в любой возможной ориентации. Средства формирования отчетов должны представлять синтезируемые данные или информацию, следующую из модели данных в ее любой возможной ориентации. Это означает, что строки, столбцы или страницы должны показывать одновременно от 0 до N измерений, где N - число измерений всей аналитической модели. Кроме того, каждое измерение содержимого, показанное в одной записи, колонке или странице должно позволять показывать любое подмножество элементов (значений), содержащихся в измерении, в любом порядке.
12. Неограниченная размерность и число уровней агрегации - исследование о возможном числе необходимых измерений, требующихся в аналитической модели, показало, что одновременно может использоваться до 19 измерений, Отсюда вытекает настоятельная рекомендация, чтобы аналитический инструмент мог одновременно предоставить хотя бы 15, а предпочтительно - 20 измерений. Более того, каждое из общих измерений не должно быть ограничено по числу определяемых пользователем-аналитиком уровней агрегации и путей консолидации.
К дополнительным правилам относятся следующие 6.
13. Пакетное извлечение против интерпретации - OLAP-система должна в равной степени эффективно обеспечивать доступ как к собственным, так и к внешним данным.
14. Поддержки всех моделей OLAP-анализа - OLAP-система должна поддерживать все четыре модели анализа данных, определенные Коддом: категориальную, толковательную, умозрительную и стереотипную.
15. Обработка ненормализованных данных - OLAP-система должна быть интегрирована с ненормализованными источниками данных. Модификации данных, выполненные в среде OLAP, не должны приводить к изменениям данных, хранимых в исходных внешних системах.
16. Сохранение результатов OLAP: хранение их отдельно от исходных данных - OLAP-система, работающая в режиме чтения – записи, после модификации исходных данных должна результаты сохранять отдельно. Иными словами, обеспечивается безопасность исходных данных.
17. Исключение отсутствующих значений - OLAP-система, представляя данные пользователю, должна отбрасывать все отсутствующие значения. Другими словами, отсутствующие значения должны отличаться от нулевых значений.
18. Обработки отсутствующих значений – OLAP-система должна игнорировать все отсутствующие значения без учета их источника. Эта особенность связана с 17-м правилом.
Кроме того, Кодд разбил все 18 правил на следующие четыре группы, назвав
их особенностями. Эти группы получили названия B (base), S (special), R (report) и R.(dimension)
Основные особенности (В) включают следующие правила:
многомерное концептуальное представление данных (правило 1);
интуитивное манипулирование данными (правило 10);
доступность (правило 3);
пакетное извлечение против интерпретации (правило 13);
поддержка всех моделей OLAP - анализа (правило 14);
архитектура ”клиент-сервер“ (правило 5);
прозрачность (правило 2);
многопользовательская поддержка (правило 8)‚
Специальные особенности (S):
обработка ненормализованных данных (правило 15);
сохранение результатов OLAP: хранение их отдельно от исходных данных (правило 16);
исключение отсутствующих значений (правило 17);
обработка отсутствующих значений (правило 18).
Особенности представления отчетов (R):
гибкость формирования отчетов (правило 11);
стандартная производительность отчетов (правило 4);
автоматическая настройка физического уровня (измененное оригинальное правило 7);
Управление измерениями (D):
универсальность измерений (правило 6);
неограниченное число измерений и уровней агрегации (правило 12);
неограниченные операции между размерностями (правило 9).
Отметим, что часть перечисленных правил слабо формализована и носит больше рекомендательный характер. Различные системы реализуют в той или иной мере лишь часть правил и ориентируются на конкретную область применения.
Рассмотрим проблемы, возникающие при организации данных в хранилище.
Хранение данных в виде многомерного массива с Nc= n1* n2 …* nm элементами позволяет непосредственно адресоваться к каждому его элементу по индексам, обеспечивая одинаково быстрый доступ к любым данным, что удобно для их отображения и анализа. Для выполнения операций над OLAP-кубом типа консолидации требуется просмотр всех хранимых данных, что может быть эффективным только тогда, когда он является мало разряженным, то есть общее количество ненулевых элементов массива N близко к Nc. Для разряженных массивов N<<Nc время таких операций Tс= O(Nc), не говоря уже о затратах памяти на хранение данных, становится недопустимо большим.
Хранение данных в виде плоской таблицы содержащей значения измерений (индексов) и характеристик (мер) требует просмотра, множества строк таблицы для нахождения нужного элемента, что дольше, чем в многомерном массиве. Для выполнения операций над таблицей типа консолидации требуется просмотр всех ее строк, и время обработки оказывается Tt= O(N). Если соответствующий OLAP-куб разряжен (N<<Nc), то Tt << Tc.
В зависимости от назначения и особенностей данных применяются разные способы их хранения.
MOLAP (Multidimensional OLAP) - исходные и агрегатные данные хранятся в многомерной базе данных.
ROLAP (Relational OLAP) - исходные данные остаются в той же реляционной базе данных, где они изначально и находились. Агрегатные же данные помещают в специально созданные для их хранения служебные таблицы в той же базе данных.
HOLAP (Hybrid OLAP) - исходные данные остаются в той же реляционной базе данных, где они изначально находились, а агрегатные данные хранятся в многомерной базе данных.
Некоторые OLAP-средства поддерживают хранение данных только в реляционных структурах, некоторые - только в многомерных. Однако большинство современных серверных OLAP-средств поддерживают все три способа хранения данных. Выбор способа хранения зависит от объема и структуры исходных данных, требований к скорости выполнения запросов и частоты обновления OLAP-кубов.
Отметим также, что подавляющее большинство современных OLAP-средств не хранит «пустых» значений (примером «пустого» значения может быть отсутствие продаж сезонного товара вне сезона).
|
из
5.00
|
Обсуждение в статье: Назначение и структура хранилища данных |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы