 |
Главная |


Каков тип результата при вычислении выражения?
|
из
5.00
|
- Если все аргументы одного типа, то и результат будет того же типа.
- Если аргументы имеют разные типы, то происходит преобразование типов: более короткие типы преобразовываются в более длинные.
16. Понятие структурного программирования. Основные конструкции структурного программирования. Оператор if и его программирование. Оператор switch и его программирование. Примеры.
СТРУКТУРНОЕ ПРОГРАММИРОВАНИЕ — методология разработки программ, в основе которой лежит представление программы в виде иерархической структуры блоков.
БАЗОВЫЕ КОНСТРУКЦИИ:
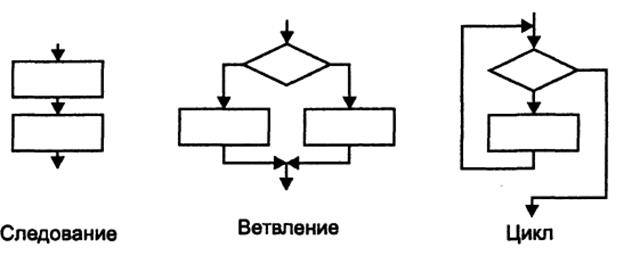
ОПЕРАТОР if служит для того, чтобы выполнить какую-либо операцию в том случае, когда условие является верным. Условная конструкция в С++ всегда записывается в круглых скобках после оператора if.
if (<условие>) <оператор1>;
else <оператор2>;
ПРИМЕР:
if (num < 10) cout << "Это число меньше 10." << endl;
else cout << "Это число больше либо равно 10." << endl;
Конструкция switch-case — это удобная замена длинной if-else конструкции, которая сравнивает переменную с несколькими константными значениями, например int или char.
СИНТАКСИС:
switch ( <переменная> ) {
case значение1:
Выполнить если <переменная> == значение1
break;
case значение2:
Выполнить если <переменная> == значение2
break;
...
default:
выполнить, если ни один вариант не подошел
break;
}
ПРИМЕР:
int a=1;
switch(a)
{
case 1:
a++;
case 2:
a++;
case 3:
a++;
}
cout<<"a= "<<a;
Данная программа выведет a = 4.
17. Оператор цикла while. Оператор цикла do… while. Оператор цикла
for… . Операторы break и continue. Примеры использования.
Данный цикл будет выполняться, пока условие, указанное в круглых скобках является истиной. While удобно применять тогда, когда количество итераций цикла заведомо неизвестно.
СИНТАКСИС:
while (Условие) { Тело цикла; }
ПРИМЕР:
int i = 0, sum = 0;
while (i < 1000) { i++; sum += i; }
cout << "Сумма чисел от 1 до 1000 = " << sum << endl;
Цикл do while очень похож на цикл while. Единственное их различие в том, что при выполнении цикла do while один проход цикла будет выполнен независимо от условия.
СИНТАКСИС:
do {Тело цикла;} while (Условие};
Решение задачи на поиск суммы чисел от 1 до 1000, с применением цикла do while:
int i = 0, sum = 0;
do { i++; sum += i; } while (i < 1000);
cout << "Сумма чисел от 1 до 1000 = " << sum << endl;
Если мы знаем точное количество действий (итераций) цикла, то можем использовать цикл for.
СИНТАКСИС:
for (инициализации; условия; модификации)
{<Тело цикла>;}
ПРИМЕР:
for ( int x = 0; x < 10; x++ ) {
//вывод x и переход на новую строку
cout<< x <<endl;
}
Оператор continue обеспечивает передачу управления управляющему выражению наименьшего внешнего цикла do, for или while.
int count = 0;
do // начало цикла do while
{
continue;
count++;
}
while ( count < 10 )
Оператор break заканчивает выполнение ближайшего внешнего цикла или условного оператора, в котором он отображается. Управление передается оператору, который расположен после оператора, при его наличии.
for (int count = 0; count <= 10; count++) // начало цикла for
{
if ( count == 6)
break; // выход из цикла for
cout << "2^" << count << " = " << pow(2.0,count) << endl; // печать степени двойки }
18. Понятие сложности алгоритма. Временная и емкостная сложность. Определение порядка сложности. Полиномиальная и экспоненциальная сложность. Примеры.
Для анализа и/или сравнения алгоритмов между собой необходимо ввести некий критерий качества. Основным критерием качества является сложность.
Временная сложность алгоритма – функция зависимости объёма работы, выполняемой некоторым алгоритмом, от размера входных данных.
ПРИМЕР:
«Пропылесосить ковер» требует время, линейно зависящее от его площади, то есть на ковер, площадь которого больше в два раза, уйдет в два раза больше времени. Соответственно, при увеличении размера ковра в сто тысяч раз, объем работы увеличивается строго пропорционально в сто тысяч раз, и т. п.
Емкостная сложность - это функция, выражающая зависимость требуемой памяти от размера входных данных.
ПРИМЕР:
Дан массив и требуется вывести его в отсортированном порядке. Если на вход будет подаваться сто чисел, то понадобится массив из 100 ячеек. Миллион чисел – миллион ячеек. Зависимость необходимой памяти от размера входных данных линейная.
Порядок сложности алгоритма – O (…) (читается «О большое от ...) – это функция, доминирующая над точным выражением временной сложности (верхняя граница для максимального числа основных операций).
Экспоненциальная сложность или экспоненциальное время — в теории сложности алгоритмов, время решения задачи, ограниченное экспонентой от размерности задачи. Другими словами, если размерность задачи возрастает линейно, время её решения возрастает экспоненциально.
В теории алгоритмов классом P (от англ. polynomial) называют множество задач, для которых существуют «быстрые» алгоритмы решения (время работы которых полиномиально зависит от размера входных данных). Класс P включён в более широкие классы сложности алгоритмов.
19. Выделение цифр натурального числа Алгоритмы построения «перевертыша» числа и определения, является ли число палиндромом. Алгоритмы определения НОД, НОК.
Цифры натурального числа можно выделить с помощью операции «%».
Алгоритм построения перевёртыша:
…
cin >> n;
Z = 0;
while (n)
{ z = z * 10 + n % 10;
n / = 10;
}
…
Алгоритм определения, является ли число палиндромом
int n = 0;
while(number)
{
n = 10*n + number%10;
number /= 10;
}
if (number ==n)
cout << number << " Это палиндром" << endl;
else
cout << "Это не палиндром " << endl;
Идея алгоритма определения НОД основана на следующей формуле:
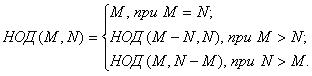
1) Если числа равны, то взять любое из них в качестве ответа, в противном случае продолжить выполнение алгоритма.
2) Заменить большее число разностью большего и меньшего из чисел;
3) Вернуться к выполнению п.1.
Рассмотрим этот алгоритм на примере М=32, N=24:
| M | 32 | 8 | 8 | 8 |
| N | 24 | 24 | 16 | 8 |
Получили: НОД(32, 24) = НОД(8, 24) = НОД(8, 16) = НОД(8, 8) = 8, что верно.
Программа нахождения НОД с использованием вычитания:
#include <iostream>
using namespace std;
void main()
{
int N,M;
cin>>N>>M;
/* НОД(M,N)=НОД(M-N,N), если M>N; НОД(M,N)=НОД(N,N-M), если M<N; НОД(M,M)=M */
while (M!=N)
if (M>N) M-=N;
else N-=M;
cout<< M<<"\n" ;
}
Идея алгоритма определения НОК
НОК (a, b)=a·b: НОД (a, b).
20. Эффективные алгоритмы проверки простоты числа и подсчета количества делителей натурального числа. Разложение числа на простые сомножители.
Самый простой путь решения этой задачи – проверить, имеет ли данное число N (N>=2) делители в интервале [2;  ].
].
Здесь используется свойство: наименьшее число, на которое делится натуральное число N, не превышает целой части квадратного корня из числа N. Если делители есть, число N – составное, если – нет, то – простое. При реализации алгоритма разумно делать проверку на четность введенного числа, поскольку все четные числа делятся на 2 и являются составными числами, то, очевидно, что нет необходимости искать делители для этих чисел. Из четных чисел только число 2 является простым.
#include <iostream>
#include “windows.h”
using namespace std;
void main()
{
SetConsoleCP(1251);
SetConsoleOutputCP(1251);
int N,i;
cout<< "Введите натуральное число: ";
cin>>N;
if (N==2)cout<< "Число 2 - простое\n";
else
if (N%2 ==0) cout<< "Число " << N << " - составное\n";
else
{
i=1;
do
i+=1;
while (i * i < N && N % i != 0);
if (i * i < N) cout<< "Число "<<N<<" - составное \n";
else cout<< "Число "<<N<<" - простое\n";
}
}
21. Эффективный алгоритм вычисления аn, где n – натуральное число. Итеративная и рекурсивная реализация.
Алгоритм быстрого возведения в степень сводится к мультипликативному аналогу схемы Горнера:
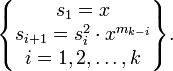
double power(double x, long n)
{
double result = 1.0;
while (n != 0)
{
if (n % 2 != 0)
{
result *= x;
n -= 1;
}
x *= x;
n /= 2;
}
return result;
}
long int pow(long int x, unsigned int n)
{
if (n==0)
return 1;
else if (n==1)
return x;
else if (n % 2 == 0 )
return pow( x * x, n/2);
else
return pow( x * x, n /2)*x;
}
22. Текстовые файлы. Способы работы с ними в С++. Примеры. Сравнение с файлами произвольного доступа.
В программах на C++ при работе с текстовыми файлами необходимо подключать библиотеки iostream и fstream.
Для того чтобы записывать данные в текстовый файл, необходимо:
- описать переменную типа ofstream.
- открыть файл с помощью функции open.
- вывести информацию в файл.
- обязательно закрыть файл.
Для считывания данных из текстового файла, необходимо:
1. описать переменную типа ifstream.
2. открыть файл с помощью функции open.
3. считать информацию из файла, при считывании каждой порции данных необходимо проверять, достигнут ли конец файла.
4. закрыть файл.
Пример 1
#include <iostream>
#include <fstream>
using namespace std;
void main()
{
int a,b;
ofstream f;
f.open("a.txt",ios::out);
cin >>a>>b;
f<<a<<b;
f.close();
}
Пример 2
void main()
{
int a,b;
ifstream f;
f.open("a.txt",ios::in);
f >>a>>b;
cout<<a<<b;
f.close();
}
Последовательные файлы выигрывают у файлов с произвольным доступом по компактности, но проигрывают по скорости доступа.Файлы с последовательным доступом – это в основном текстовые файлы, которые можно открывать с помощью текстового редактора. Текстовый файл может содержать коды символов, признак перевода строки vbCrLf, признак табуляции vbTab и признак конца файла. Здесь записи – это строки переменной длины, отделенные друг от друга символом перевода строки. Такие файлы обычно создаются приложениями для обработки и хранения текстовой информации (но не числовой). Файлы с последовательным доступом читаются от начала к концу, поэтому невозможно одновременно и считывать из них данные, и записывать таковые. Обычно информация из текстового файла считывается вся в память и сохраняется вся в файле после окончания работы с ней. Чтобы изменить одну запись файла последовательного доступа, его нужно весь записать заново. Если же приложению требуется частый доступ к данным, хранящимся в некотором файле, следует использовать файлы с произвольным доступом.
23. Функции. Описание функции. Вызов функции. Формальные и фактические параметры. Оператор return. Прототип функции. Функции. Способы передачи параметров. Понятие ссылки и указателя.
Функция — это поименованный набор описаний и операторов, выполняющих определенную задачу. Функция может принимать параметры и возвращать значение. Информация, передаваемая в функцию для обработки, называется параметром, а результат вычислений функции ее значением.
Обращение к функции называют вызовом.
Перед вызовом функция должна быть обязательно описана. Описание функции состоит из заголовка и тела функции:
тип имя_функции (список_переменных)
{ тело_функции }
Заголовок функции содержит:
- Тип возвращаемого функцией значения. Он может быть любым. Если функция не возвращает значения, указывают тип void;
- имя_функции, под которым она будет вызываться;
- список_переменных — перечень передаваемых в функцию аргументов, которые отделяются друг от друга запятыми; для каждой переменной из списка указывается тип и имя;
Тело функции представляет собой последовательность описаний и операторов, заключенных в фигурные скобки.
Стоит отметить, что тексты функции могут следовать после главной функции main(). Однако заголовки необходимо перечислить до нее. Эти заголовки называют прототипом функции.
тип имя_1 (список_переменных); //прототип функции имя_1
тип имя_2 (список_переменных); //прототип функции имя_2
Возврат результата из функции в вызывающую ее функцию осуществляется оператором
return (значение);
- Формальный параметр — аргумент, указываемый при объявлении или определении функции;
- Фактический параметр — аргумент, передаваемый в функцию при ее вызове.
// Описание функции. int a - формальный параметр, имя параметра может отсутствовать.
int myfunction(int a);
// Определение функции. int b - формальный параметр, имя параметра может не совпадать с указанным при объявлении функции.
int myfunction(int b)
{ return 0;}
int main()
{ int c=0;
myfunction(c); // Вызов функции. c - фактический параметр.
return 0;}
Функция — это поименованный набор описаний и операторов, выполняющих определенную задачу. Функция может принимать параметры и возвращать значение. Информация, передаваемая в функцию для обработки, называется параметром, а результат вычислений функции ее значением.
Передача параметров в функцию может осуществляться по значению и по адресу.
При передаче данных по значению функция работает с копиями фактических параметров, и доступна к исходным значениям аргументов у нее нет. При передаче по адресу в функцию передается не переменная, а ее адрес, и, следовательно, функция имеет доступ к ячейкам памяти, в которых хранятся аргументов. Таким образом, данные, переданные по значению, функция изменить не может, в отличие от данных, переданных по адресу.
Для передачи данных по адресу требуется после типа переменной указать символ «*» (операция разадресации). Чтобы передать в функцию фактический параметр по адресу, нужно использовать операцию взятия адреса «&».
Указатель — это переменная, значением которой является адрес памяти, по которому хранится объект определенного типа (другая переменная). Например, если C - это переменная типа char, а P - указатель на C, то, значит, в P находится адрес, по которому в памяти компьютера хранится значение переменной C.
Как и любая переменная, указатель должен быть объявлен. При объявлении указателей всегда указывается тип объекта, который будет храниться по данному адресу:
Например,
int *p
Звездочка в описании указателя относится непосредственно к имени, поэтому, чтобы объявить несколько указателей, ее ставят перед именем каждого из них:
float *x, y, *z;
Операция получения адреса обозначается знаком &. Она возвращает адрес своего операнда. Например:
float a; //объявлена вещественная переменная a
float *adr_a; //объявлен указатель на тип float
adr_a = &a; //оператор записывает в переменную adr_a адрес переменной a
Операция разадресации * возвращает значение переменной, хранящееся в по заданному адресу, то есть выполняет действие, обратное операции &:
float a,b; //объявленs вещественная переменная a и b
float *adr_a; //объявлен указатель на тип float
adr_a=&a;
b = *adr_a; //оператор записывает в переменную b
//вещественное значение, хранящееся по адресу adr_a
24. Функции. Параметры со значениями по умолчанию. Перегрузка функций. Inline-функции. Структура проекта. Программный модуль. Заголовочный файл. Создание библиотеки пользовательских функций.
Функция — это поименованный набор описаний и операторов, выполняющих определенную задачу. Функция может принимать параметры и возвращать значение. Информация, передаваемая в функцию для обработки, называется параметром, а результат вычислений функции ее значением.
Обеспечить значения по умолчанию для параметров функции очень легко. Для этого необходимо присвоить значение параметру с помощью оператора присваивания прямо при объявлении функции, как показано ниже:
void some_function(int size=12, float cost=19.95)…
Если программа опускает определенный параметр для функции, обеспечивающей значения по умолчанию, то следует опустить и все последующие параметры. Другими словами, вы не можете опускать средний параметр. В случае предыдущей программы, если требовалось опустить значение параметра b в show_parameters, программа также должна была опустить значение параметра с. Вы не можете указать значение для а и с, опуская значение b.
ПЕРЕГРУЗКА ФУНКЦИЙ — возможность использования одноимённых функций в языках программирования.
Перегружаемые функции имеют одинаковое имя, но разное количество или типы аргументов. Перегруженная функция фактически представляет собой несколько разных функций, и выбор подходящей происходит на этапе компиляции.
Например:
main()
{
cout<<volume(10);
cout<<volume(2.5,8);
cout<<volume(100,75,15);
}
// volume of a cube
int volume(int s)
{
return(s*s*s);
}
// volume of a cylinder
double volume(double r,int h)
{
return(3.14*r*r*h);
}
// volume of a cuboid
long volume(long l,int b,int h)
{
return(l*b*h);
}
inline-функция — это такая функция, чье тело подставляется в каждую точку вызова, вместо того, чтобы генерировать код вызова. Это подобно использованию параметризованных макросов в С.
Иногда программный код оказывается слишком большим и сложным, чтобы хранить его в одном файле. В таких случаях удобнее разбить программу на несколько исходных файлов, которые обычно называют модулями. Каждый из этих модулей можно компилировать отдельно, а затем объединить их в процессе построения конечной программы.
Процесс объединения отдельно скомпилированных модулей называется связыванием (компоновкой).
Чтобы создать отдельные модули программы, необходимо в окне Обозревателя Решений с помощью контекстного меню для пункта Исходные Файлы создать отдельные файлы проекта. Все они будут иметь расширение .cpp и будут компилироваться отдельно. Основная программа при этом может содержать только главную функцию main и прототипы всех остальных функций, которые содержатся в других модулях. После успешной компиляции каждого отдельного модуля необходимо выполнить компоновку проекта с помощью пункта «Построить решение» или клавиши F7. Далее можно запускать программу на выполнение обычным способом.
Для того чтобы в одном модуле можно было использовать функции других модулей, необходимо описать описывать их прототипы. Это не очень удобно, так как при описании можно допустить ошибку. Особенно это актуально в том случае, если одни и те же функции используется не в одном модуле, а в нескольких. Придется каждый раз повторять описание их прототипов. Поэтому удобнее создать заголовочный файл, в котором будут описаны все прототипы функций, а затем включить его с помощью директивы #include.
25. Рекурсивные функции. Виды рекурсии. Механизм реализации рекурсии с использованием стека. Примеры.
РЕКУРСИЯ — это такой способ организации вспомогательного алгоритма (подпрограммы), при котором эта подпрограмма в ходе выполнения ее операторов обращается сама к себе. Вообще, рекурсивным называется любой объект, который частично определяется через себя.
Выполнение действий может происходить:
1. На рекурсивном спуске
тип rec(параметры)
{
<действия на входе в рекурсию>;
If <проверка условия> rec(параметры);
[else S;]
}
2. На рекурсивном возврате
тип Rec(параметры);
{
If <проверка условия> Rec(параметры);
[else S1];
<действия на выходе из рекурсии>;
}
3. На рекурсивном спуске и на рекурсивном возврате
тип Rec (параметры);
{
<действия на входе в рекурсию>;
If <условие> Rec(параметры);
<действия на выходе из рекурсии>
}
или
тип Rec(параметры);
{
If <условие>
{ <действия на входе в рекурсию>;
Rec;
<действия на выходе из рекурсии> }
}
Обращение к рекурсивной подпрограмме ничем не отличается от вызова любой другой подпрограммы. При каждом рекурсивном вызове информация о нем сохраняется в специальной области памяти, называемой стеком. В стеке записываются значения локальных переменных, параметров подпрограммы и адрес точки возврата. Таким образом, какой-либо локальной переменной A на разных уровнях рекурсии будут соответствовать разные ячейки памяти, которые могут иметь разные значения. Поэтому воспользоваться значением переменной A i-ого уровня можно только находясь на этом уровне. Информация в стеке для каждого вызова подпрограммы будет порождаться до выхода на граничное условие. Очевидно, в случае отсутствия граничного условия, неограниченный рост количества информации в стеке приведёт к аварийному завершению программы за счёт переполнения стека.
26. Одномерные массивы.Описание статического массива. Задание массивам первоначальных значений. Ввод и вывод массива. Одномерные массивы. Динамические выделение памяти под массив. Операции new и delete. Обращение к элементу массива через явное использование указателя и без него.
Массив – это совокупность пронумерованных однотипных элементов, имеющих общее имя. Массив, который можно представить в виде таблицы, состоящей из одной строки, называется одномерным массивов.
Статически описать массив в C++ можно так:
тип имя_массива [размерность];
Задать массиву первоначальное значение можно несколькими способами:
тип имя_переменной [размерность] = {элемент_0, элемент_1, …};
Задать значение элементам массива (и вывести их) по ходу выполнения программы можно совершенно также, как это делается с любыми другими переменными (при условии правильного обращения к элементам).
Так, запись *(a) аналогична записи a[0], а запись *(a+i) аналогична записи a[i]. Записи &a[i] и a+i также будут эквивалентными, т. е. и в том и в другом случае это адрес i-го элемента после элемента a[0].
Память под массивы может выделяться статически (на этапе компиляции) и динамически (в ходе выполнения программы). Динамическое выделение памяти необходимо для эффективного использования памяти компьютера.
В С++ операции new и delete предназначены для динамического распределения памяти компьютера. Операция new выделяет память из области свободной памяти, а операция delete высвобождает выделенную память. Выделяемая память, после её использования обязательно должна высвобождаться, поэтому операции new и delete используются парами. Если не высвобождать память явно, то она освободится ресурсами ОС только по завершению работы программы.
Синтаксис выделения памяти для массива имеет вид:
указатель = new тип[размер]
Например:
float *ptrarray = new float [10];
После того как динамический массив стал ненужным, нужно освободить участок памяти, который под него выделялся.
delete [] ptrarray;
После оператора delete ставятся квадратные скобки, которые говорят о том, что высвобождается участок памяти, отводимый под одномерный массив.
В языке С существуют два метода обращения к элементу массива: индексация массива и адресная арифметика.
Например, написав
pa = &a[0];
pa = a;
где pa – указатель, то получим один и тот же результат.
Так, запись *(a) аналогична записи a[0], а запись *(a+i) аналогична записи a[i]. Записи &a[i] и a+i также будут эквивалентными, т. е. и в том и в другом случае это адрес i-го элемента после элемента a[0]
27. Основные операции с одномерными массивами: поиск минимума и максимума и их индексов. Эффективный поиск максимума (минимума) и их количества. Эффективный поиск двух различных максимумов (минимумов).
Дан массив X, состоящий из n элементов. Найти максимальный элемент массива и номер, под которым он хранится в массиве.
Алгоритм решения задачи следующий. Пусть в переменной с именем Max хранится значение максимального элемента, а в переменной Nmax — его номер. Предположим, что нулевой элемент массива является максимальным и запишем его в переменную Max, а в Nmax - его номер (ноль). Затем все элементы начиная с первого сравниваем в цикле с максимальным. Если текущий элемент массива оказывается больше максимального, то записываем его в переменную Max, а в переменную Nmax — текущее значение индекса i.
for (Max=X[0], Nmax=0, i=0; i<n; i++)
if (Max<X[i])
{
Max=X[i];
Nmax=i;
}
cout<<"Max="<<Max<<"\n";
cout<<"Nmax="<<Nmax<<"\n";
Алгоритм поиска минимального элемента в массиве будет отличаться лишь тем, что в конструкции if знак поменяется с < на >.
Задачу можно решить следующим образом:
#include <iostream>
using namespace std;
void main()
{
int a[100];
int i, n, max, t;
cin >> n; max = -255; t = 0;
for (i = 0; i<n; i++)
{
cin >> a[i];
cout << a[i];
}
for (i = 0; i<n; i++)
{
if (a[i] == max) t++;
if (a[i]>max)
{
t = 1;
max = a[i];
}
}
cout << endl;
cout << max << endl << t;
}
Задачу можно решить следующим образом:
#include <iostream>
using namespace std;
void main()
{
int a[10];
int max1 = INT_MIN, max2 = INT_MAX;
for (int i = 0; i<10; i++)
{
cin >> a[i];
if (a[i]>max1)
{
max2 = max1;
max1 = a[i];
}
if (a[i] < max1 && a[i] > max2) max2 = a[i];
}
cout << max1 << endl << max2;
}
28. Перестановки в одномерном массиве. Обращение массива, циклический сдвиг элементов массива. Эффективные алгоритмы решения этих задач.
Существует множество методов сортировок (перестановок) одномерного массива:
|
из
5.00
|
Обсуждение в статье: Каков тип результата при вычислении выражения? |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы