 |
Главная |


Текст: представление, хранение, ввод
|
из
5.00
|
ТЕХНОЛОГИЙ В ЛИНГВИСТИКЕ
План
1. Автоматический анализ и синтез звучащей речи
2. Технологии обработки текста
3. Автоматическое распознавание текста
4. Автоматическое аннотирование и реферирование текста
5. Автоматический анализ и синтез текста
(Слайд 2)1. Автоматический анализи синтез звучащей речи
Одним из первых важных шагов использования информационных технологий в лингвистике является дигитализация текстов — переведение языкового материала, существующего в печатном или устном виде, в цифровую форму. Именно в этом случае появляетсявозможность привлечения компьютеров для выполнения определенныхопераций над текстами на естественном языке: их преобразования,выделения их них отдельных элементов и создания (синтеза)аналогичных текстов.
При автоматическом анализе звучащей речи она преобразуется в печатный текст, над которым можно производить дальнейшие операции.
Автоматический синтез звучащей речи представляет собой обратный процесс преобразования печатного текста, существующегов цифровой форме, в звучащий текст на естественном человеческом языке.
(Слайд 3) Процесс автоматического анализа речи включает следующие этапы:
1) ввод звучащей речи в компьютер с помощью микрофона.
2) выделение компьютерной программой в звуковом потоке отдельныхзнаков.
3) идентификация выделенных знаков звучащей речи со знакамиязыка.
Минимальными знаками звучащей речи являются звуки, производимые артикуляторным аппаратом человека. Каждый звук имеет свои акустические характеристики (высота, частота колебаний звуковых волн и т.д.), которые можно измерить специальными приборами (например, осциллографом).
Параметры звукового сигнала непрерывно меняются, и такой (непрерывный) тип сигнала называется аналоговым. В отличие от аналогового, цифровой сигнал представляет собой набор дискретных (отдельных) числовых значений, фиксирующих разные уровни звуковой волны. При использовании микрофона аналоговый звуковой сигнал преобразуется в аналоговый электрический, который спомощью аналогово-цифровых преобразователей, встроенных в звуковые карты современных компьютеров, переводится в дискретный цифровой сигнал.
Первые устройства автоматического распознавания устной речи, которых на сегодняшний день большинство, в качестве выделяемых в речевом потоке знаков использовали не звуки, а слова. Слова вводимой в компьютер речи идентифицировались со словами, заранее записанными диктором, читающим слова. Но такой тип распознавания речи связан с определенными ограничениями:
• личность говорящего: автомат распознает речь только определенного говорящего,
• запас слов: автомат распознает только ограниченное количество слов,
• подготовленность речи: автомат распознает речь, лишь если она подготовлена.
Для преодоления этих ограничений требуется, чтобы компьютерная программа
распознавала не слова, а звуки, т.е. работала не сдискретной речью (которая содержит паузы между словами), а со слитной естественной человеческой речью.
(Слайд 4) В основе пофонемного распознавания звуков речи лежит анализ: 1) длительности и динамики звучания, 2) чередования акустического сигнала и пауз. При этом на основе универсальной классификации звуков Гуннара Фанта, Морриса Халле и Романа Якобсона акустические признаки звуков выводятся из артикуляционных. Правда, акустические признаки в отношении к артикуляционным оказываются недостаточно универсальными. Кроме того, в этой теории недостаточно учитывается слогоделение, акцентуация и ритм (главные носители смысла).
В настоящее время наиболее доступной формой точной фиксации звучащей речи (в том числе ее тембра и динамики) становится спектрограмма — фотографическое изображение звуков. Результаты наблюдений показывают, что в произнесении звуков активно используются четыре частоты называемые формантами. Так, на рис. изображены форманты русских звуков и и у. При переходе от звука и к звуку у наиболее заметно изменение форманты F2 (рис.).
(Слайд 5) Задачей автоматического анализа звучащей речи при использовании спектрограмм становится перевод спектрограмм в фонологическую транскрипцию.
Рис. 3. Спектрограмма русских звуков и и у
В итоге процесс автоматического анализа речи включает ввод слов в компьютер через микрофон, начитанных разными дикторами, их спектральную обработку и создание набора признаков, своеобразного образца слова, который выступает знаком языка. При распознавании звучащей речи реальные признаки составляющих ее единиц сравниваются с признаками и образцами слов, существующими в памяти машины. Результатом сравнения является транскрипция или орфографическая запись слова.
Но при автоматическом анализе слитной речи дополнительную трудность составляет отсутствие четких границ между словами. Человек для преодоления этой трудности кроме акустических сигналов обычно использует самые разные другие источники информации: ситуацию, контекст, структуру языкового высказывания, прошлый опыт в данной области и т.п. Аналогичные правила ученые пытаются применитьи к машинам и стремятся задействовать в современных системах анализа речи кроме акустического другие уровни системы языка: лексический, синтаксический, семантический, прагматический.
Включение семантического уровня в автоматический анализ речи приводит, в частности, к следующим последствиям:
1) машина устанавливает, что введенные предложения многозначны и правдоподобны;
2) машина прогнозирует, что в определенных речевых контекстах могут возни-
кать определенные типы общения; в зависимости от такого прогнозируемого типа общения машина интерпретирует предложение.
Очевидно, что создание систем анализа речи такого сложного уровня предусматривает сотрудничество представителей самых разных специальностей. Для экономии времени и усилий ученых и практиков различные компании, в том числе Microsoft, выпускают средства анализа и синтеза речи в виде программных модулей и интерфейсов.
Программисты, не обладающие познаниями в области лингвистики, математики и биологии, могут использовать готовые интерфейсы и программные модули в собственных разработках.
Правда, в этом случае речевые возможности программ будут ограничены использованными средствами и технологиями. Например, многие средства анализа и синтеза речи не способны работать с русским языком, что ограничивает их использование в России.
(Слайд 6) Можно назвать следующие примеры программ, в которых применяются средства автоматического анализа речи:
• программы голосового управления компьютером и бытовой техникой Voice Navigator и Truffaldino (компания «Центр речевых технологий», С.-Петербург);
• комплекс голосового управления мобильным телефоном DiVo («Центр речевых технологий»);
• программный модуль Voice Key для идентификации личности по парольной фразе длительностью 3-5 секунд («Центр речевыхтехнологий»);
• программы диктовки текста на английском языке: Voice Type Dictation ( IBM ), Dragon Dictate (« DragonSystems »);
на русском языке: Комбат («БайтГруп») к Диктограф (« Voice Member Technology )));
• система распознавания речи, встроенная в Microsoft Office ХР (работает только с английским языком);
• голосовой поиск (например, в поисковой системе Google).
Так, программа Voice Navigator позволяет запускать компьютерные приложения и выполнять заданные команды голосом без использования клавиатуры. Перед применением программы ее необходимо обучить, произнеся в микрофон слова команд (команды можно произносить на любом языке и любым голосом). Чтобы программа начала распознавать голосовые команды, ее необходимо «разбудить», произнеся ключевое слово.
Использование модулей распознавания речи весьма перспективно в различных областях деятельности: в обслуживании клиентов, проведении судебных экспертиз, биометрии, обучении, научных исследованияхи т.д. Но массовое внедрение речевых технологий тормозится высокой стоимостью разработок и предлагаемых технологий, а также их пока еще низким качеством.
(Слайд 7) В целом задача автоматического анализа речи является весьма сложной и решена лишь отчасти. В сравнении с ней задача автоматического синтеза речи оказывается более простой, и с примерами ее массового использования в обиходной жизни мы сталкиваемся постоянно. В частности, автоматически синтезируется речь в следующих ситуациях:
• называние текущего времени по телефону,
• объявление остановок в метро,
• называние остатка средств на счету и другие услуги мобильных операторов,
• оповещение систем гражданской безопасности и т.д.
Автоматический синтез (генерация) речи в настоящее время осуществляется путем составления слов и фраз из заранее записанных диктором образцов отдельных звуков (метод компилятивного синтеза) или путем моделирования речевого тракта человека (формантно-голосовой метод).
Первый метод используется главным образом для синтеза относительно небольшого и заранее известного набора фраз. При этом обеспечивается довольно высокое качество звучания, поскольку синтезируемая речь базируется на элементах естественной человеческой речи. Тем не менее на стыке составляемых звуковых фрагментов возможны интонационные искажения и разрывы, заметные на слух.
Кроме того, создание крупной базы данных звуковых фрагментов, учитывающей все особенности произношения фонем с разными интонациями,представляет собой сложную и кропотливую работу.
Второй метод оказывается более сложным, поскольку здесь необходимо точное моделирование особенностей речевого тракта человека,а также учет интонационной модуляции речи. В силу названных особенностей формантно-голосовая модель обладает относительно низкой точностью синтезируемых звуков речи.
В качестве примера программы, синтезирующей речь, можно назвать программу Govorilka (разработчик:А. Рязанов, бесплатная версия программы размещена по адресу http://www.vector-ski.com/vecs/govorilka). Основные особенности данной программы состоят в следующем:
• программа читает текст разными голосами и на разных языках, в том числе на русском;
• исходный текст для чтения может быть загружен из текстового файла или набран в окне программы при помощи клавиатуры;
• можно сохранить результаты синтеза речи, записав файл формата WAV или МРЗ.
Таким образом, несмотря на мощность современных компьютеров,проблема оснащения компьютера полноценным речевым интерфейсомеще далека от своего завершения. Главной проблемойпри создании программ автоматического распознавания речи являетсято, что компьютер не умеет работать со смыслом. В синтезеречи уже имеются определенные достижения, которые внедрены в массовую практику.
(Слайд 8) 2. Технологии обработки текста
Текст: представление, хранение, ввод
Представление текста
Представление информации в виде текста стало одним из первых доступных для обработки с помощью ЭВМ и до сих пор остается одним из наиболее универсальных. Энциклопедический словарь дает такое определение понятию “текст”: “Текст — это упорядоченный набор слов, предназначенный для того, чтобы выразить некий смысл. В лингвистике термин используется в широком значении, включая в себя и устную речь”.
Представление информации в виде текста при обработке с помощью вычислительной техники близко к этому определению. Под “текстовым” понимают такое представление информации, в котором она представлена в виде записи слов (логических элементов) некоторого языка и доступна для чтения человеком.
Язык для такого представления характеризуется некоторым алфавитом — т.е. допустимым набором символов. Поскольку компьютер работает только с двоичным кодом, то для записи и обработки требуется взаимно-однозначно сопоставить символы и двоичные коды. Правило сопоставления кодов и символов, входящих в алфавит, называется кодировкой.
Первый широко распространенный стандарт кодирования — таблица (т.е. прямое сопоставление кодов символам) кодировки ASСII (American Standard Codefor Information Interchange, американский стандартный код для обмена информацией) — был разработан в 1963 году. Стандарт предполагал использование не только в вычислительной технике, но и в телеграфии (он стал заменой 5-битного кода Бодо). В нем для кодирования каждого символа отводилось 7 бит. Восьмой бит использовался для служебных целей — контроля четности при передаче.
Эта часть таблицы кодировки содержит символы латинского алфавита, цифры, некоторые знаки препинания и набор управляющих символов (возврат каретки, перевод строки, конец файла, сигнал и т.п.).
Позже восьмой бит стали использовать для представления символов национальных алфавитов: первая часть таблицы — US-ASCII — использовалась по-прежнему, а содержание второй менялось в зависимости от исходного естественного языка. Каждый вариант этой второй половины (расширенной таблицы) исходной таблицы получил название “кодовой страницы” языка (code page).
Для русского языка таких расширений несколько (разрабатывались они в разное время). Наиболее известны: CP866 (DOS), KOI-8R (UNIX), CP1251 (Windows) и MacCyr.
Применение такого способа кодирования сильно затрудняет передачу текстовых сообщений между разными странами, объединение в сообщении текста на нескольких языках, а в случае с русским языком — и обмен файлами между разными ОС (для русского языка до сих пор активно применяется 4 разных кодовых таблицы). Для решения этих проблем в 1991 году некоммерческим объединением был предложен стандарт кодирования Юникод (Unicode).
Стандарт состоит из двух частей: универсального набора символов (UniversalCharacterSet) и правил трансформации (Unicode Transformation Format). Универсальный набор символов предполагает описание всех возможных при записи текстов символов в виде общей таблицы кодов. Правила трансформации определяют способ записи этих кодов.
Первая версия стандарта предполагала использование двух байтов для кодирования каждого символа. В дальнейшем это кодовое пространство было расширено.
Сейчас чаще всего применяется способ трансформации UTF-8, обеспечивающий совместимость с предыдущими реализациями и стандартами. В частности, коды менее 128 записываются одним байтом, что автоматически превращает их в коды ASCII.
Применение этого стандарта кодирования позволяет объединять в одном тексте слова на различных языках (без ограничений на их количество), использовать устаревшие языки, дополнительные символы.
Наиболее переносимым и легко используемым с технической точки зрения способом хранения и передачи текста являются текстовые файлы. По сути, эти файлы представляют собой последовательности символов, разбитых на абзацы или строки.
Текстовые файлы
Понятие “текстового файла” не предусматривает строго заданного формата или расширения. Тем не менее, помимо характерной для той или иной ОС таблицы кодировки, в текстовых файлах могут применяться три основных способа деления текста на строки (абзацы):
1. Windows (DOS) — символы “Возврат каретки” + “Перевод строки” (CR+LF).
2. Unix — символ “Перевод строки” (LF).
3. MacOs — символ “Возврат каретки” (CR).
Текстовые файлы применяются для самых различных целей и часто оказываются формой хранения данных, описанных более сложными формальными языками. Эти файлы часто используются для записи конфигурации ПО, документирования, переноса данных, описания HTML- или XML-кода.
(Слайд 9) Правила машинописного набора текста
Для облегчения анализа и последующего преобразования текста при его наборе в самых различных случаях рекомендуется соблюдать общие правила машинописного набора:
1. Все слова разделяются пробелом, и только одним пробелом.
2. Знаки препинания примыкают к предыдущему слову.
3. Скобки и кавычки всех видов примыкают к первому и последнему слову заключенного в них текста.
4. Текст разрывается только в конце абзаца.
5. Большие форматированные пробелы делаются вставкой символа табуляции, а не несколькими пробелами подряд.
Соблюдение этих правил позволяет легко использовать текст при подготовке более сложных документов, в которые он входит как важнейший элемент, или при организации автоматической обработки.
Текст может появиться из самых разных источников. Чаще всего текстовую информацию вводят с помощью клавиатуры. Стандартная клавиатура и программа, принимающая от нее информацию о нажатых клавишах, позволяют вводить текст (набирая его посимвольно), указывать место ввода в уже введенном тексте (перемещая маркер места ввода клавишами перемещения курсора либо с помощью мыши) и удалять неверно введенные символы слева или справа от курсора (с помощью клавиш  и
и  ).
).
Возможность исправлять ошибки и набирать текст постепенно стала одной из существенных причин, по которым подготовка текстовой информации практически повсеместно была переведена с бумажной на компьютерную основу.
Текстовые редакторы с развитыми возможностями предоставляют пользователям возможность протоколировать и сохранять наборы действий — создавать макрокоманды, или макросы. Использование макросов позволяет ускорить выполнение частых простых задач обработки.
Специализированные программы, основной задачей которых является обеспечение набора текста, разделяют на текстовые редакторы, т.е.программы, которые помогают именно подготовить тот или иной специфический текст, но не оформить его для печати, и текстовые процессоры — более сложныепрограммные комплексы, позволяющие выполнить оформление текста, точно задать его расположение, сопроводить его графическими материалами и т.д.
Пример программных продуктов — текстовых редакторов:
Блокнот, Notepad++, PSPad, vi
(Слайд 10) Оформление текста
Шрифты
Чаще всего текстовая информация используется при подготовке различных печатных материалов. Конечная цель подготовки такого материала — его печать или точное изображение печатной страницы на экране. В отличие от простой подготовки текстового файла, при подготовке печатного материала важно, как отображается текст. Практически все основные элементы и приемы оформления текстовых материалов заимствованы у давно существующих технологий — печатных, оттуда же пришла и основная часть терминологии.
Основным и наиболее важным средством определения внешнего вида текста является шрифт (schreiben, от нем. — “писать”). Шрифт — это графический рисунок букв, цифр и символов, обладающий общими для всех символов стилистическими особенностями изображения.

Отдельный символ контурного шрифта с обозначенными элементами рисунка (из книги В.Кричевского “Типографика в терминах и образах”.М.: Слово, 2000)
Шрифт характеризуется рядом параметров:
1. Рисунок шрифта — графические особенности, определяющие общность шрифта и его отличие от всех других.
2. Кегль (кегель) — размер шрифта — предельная высота большой буквы и окружающих ее пробелов (термин введен для описания высоты площадки литеры при наборе с помощью типографской кассы). Чаще всего задается в типографских пунктах (1 пункт = 1/72 дюйма = 0,375 мм). По историческим причинам некоторые размеры имеют собственные названия: 8 пт — “петит”, 9 пт — “боргес”, 10 пт — “корпус”, 12 пт — “цицеро”.
3. Начертание — шрифт с общим рисунком, но какими-либо отличительными признаками: более жирный, наклонный, разреженный. Иногда параметр плотности шрифта (светлый, полужирный, жирный) отделяют от начертания.
4. Часто как параметр задается подчеркивание или зачеркивание шрифта, или его написание как индекса — с уменьшением размера и подъемом/спуском относительно текущей строки.
(Слайд 11) Совокупность всех возможных размеров и вариантов написания шрифта называется гарнитурой. Гарнитуры имеют имена, по которым часто называют и конкретный шрифт.
По общим чертам рисунка различают три основных вида шрифтов:
1. Рубленые шрифты. Для этих шрифтов характерно угловое соединение штрихов. Чаще всего у таких шрифтов нет засечек. Такими шрифтами часто набирают заголовки.
2. Антиквенные шрифты. Происходят от созданного Альбрехтом Дюрером шрифта “Антиква”.
В этом шрифте соединения между штрихами сглажены, обязательны засечки. Это наиболее популярная “книжная” группа шрифтов для набора больших объемов текстов. Пример одного символа такого шрифта приведен на рисунке.
3. Акцидентные (оформительские) шрифты. Шрифты с самым разным рисунком, применяемые для оформительских целей, часто — стилизованные под рукописные буквы. Большие объемы текста такими шрифтами набирать не рекомендуется, он начинает утомлять взгляд.
Шрифт задается для набранного текста и не изменяет самих символов — он только определяет написание каждого символа, исходя из эталонного изображения. Библиотека таких изображений называется просто “шрифтом”.
Существует несколько основных способов описания шрифтов (точнее — гарнитуры шрифта):
1. Растровые шрифты. При таком способе каждая буква описывается отдельно, как некоторая матрица точек. Способ позволяет максимально ускорить обработку, но сильно затрудняет изменение размеров или начертаний. Для достижения качества каждый символ такой гарнитуры должен быть отредактирован вручную и должен храниться отдельно.
2. Векторные шрифты. При таком способе описания шрифт задается с помощью некоторых математических кривых, совокупность которых и составляет рисунок символов. Такой шрифт может изменять размеры без потери качества, но с помощью примитивов трудно добиться прорисовывания заполняемых элементов.
3. Контурные шрифты. Аналогично векторным, описываются с помощью некоторых математических кривых, но они определяют не символ, а его контур, который заполняется по определенным правилам. Именно этот тип шрифтов и является наиболее популярным.
Для использования векторных и контурных шрифтов необходимо выполнение операции, “создающей” шрифт (заданного рисунка, размера и начертания), годного для отображения. Такая операция называется “растеризацией”. В состав графических оболочек современных операционных систем входят программы — растеризаторы шрифтов определенного формата.
Наиболее популярные форматы шрифтов — это True Type Fonts (TTF, поддерживается ОС Windows и MacOS) и Post Script (разработан фирмой Adobe, для использования необходима программа Adobe Type Manager). Сейчас на смену этим форматам приходит совместно разработанный этими компаниями формат Open Type.
Растеризация шрифта — достаточно ресурсоемкая операция, поэтому контурные шрифты получили распространение только с началом массового применения достаточно мощных компьютеров.
(Слайд 12) Структурирование теста
Помимо внешнего вида букв, важное значение имеет пространственное расположение текста. Единицей пространственного размещения служит абзац. Как и в литературе, в компьютерном тексте абзацем называется выделенный по смыслу участок.
Для оформления абзаца используют несколько параметров:
1. Выравнивание (выключка) — правило расположения букв в строке абзаца. Видов выравнивания четыре: по левому краю, центральное, по правому краю и по ширине полосы набора.
2. Отступы от краев полосы набора.
3. Абзацный отступ (красная строка) — положение первой строки абзаца.
4. Интервалы. Различают межстрочное расстояние — задается множителем размера шрифта (одинарный, полуторный, двойной интервал) — и промежутки до и после абзаца.
5. Буквица — крупная выступающая первая буква абзаца. Часто задается не просто более крупным размером буквы, но и буквой другого рисунка.
Абзацы размещаются в рамках полосы — выделенного участка страницы, как правило, прямоугольной формы, в котором размещаются текст и иллюстрации. На листе может быть либо одно такое место (одна колонка), либо несколько — тогда говорят о многоколоночном тексте.
Как правило, текстовые процессоры не дают появляться висячим строкам —отдельным строкам абзацев в начале или конце полосы.
Важным элементом оформления текста на странице являются поля — пробелы вдоль края страницы и интервалы между колонками. Для удобочитаемости, в силу особенностей восприятия, такие пробелы должны быть обязательно.
Как правило, в достаточно большом (больше нескольких страниц) тексте выделяется несколько смысловых блоков (разделов) и видов содержательного текста — обычный текст, примечания, ссылки и т.п.
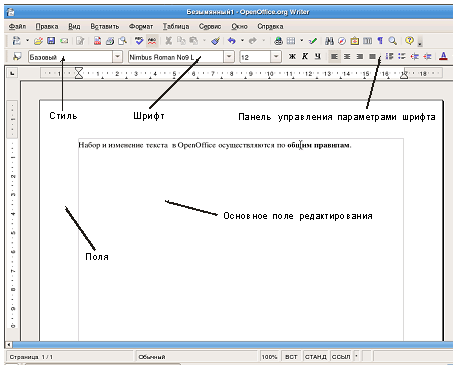
Окно текстового процессора OpenOffice.org Write с основными элементами
Для оформления таких типовых элементов создаются стили — определенные наборы параметров оформления шрифта и абзацев. Применение стилей позволяет ускорить набор, автоматизировать оформление (например, автоматически создавать оглавления) и изменять внешний вид различных элементов, не разыскивая их по всему тексту. Практически все современные текстовые процессоры опираются на стили, даже если пользователь не использует их. Единство оформления — одно из условий удобочитаемости и красоты печатного издания.
Для решения некоторых типовых задач оформления текстов существующие текстовые процессоры предусматривают два мощных средства автоматизации.
1. Списки. При оформлении текста это набор визуально выделенных элементов перечисления. Элементы выделяют с помощью символа-маркера (маркированные списки) либо номером — в упорядоченных списках. При оформлении списка чаще всего также предусматривают форматирование абзацев — так, чтобы они не выступали за маркер. Автоматизация оформления позволяет автоматически маркировать и выделять новые элементы списков.
2. Таблицы. Современные текстовые процессоры предусматривают средства для создания двухмерной структуры размещения информации. Применение таких средств позволяет редактировать структуру и содержание таблицы, добавлять строки и столбцы, изменять их линейные размеры, выделять их с помощью сетки или фона. Фактически каждая ячейка таблицы становится листом в миниатюре.
Стоит отметить, что файлы текстового процессора содержат массу дополнительных (по отношению к тексту) данных об оформлении и текстовыми очень часто не являются.
Как и текстовые редакторы, текстовые процессоры обладают средствами создания макрокоманд. Современные процессоры реализуют их на развитом языке сценариев, позволяющем решать довольно сложные задачи преобразования и оформления публикаций.
Примеры программных продуктов
Microsoft Word, Open Office Writer, StarOffice Word
|
из
5.00
|
Обсуждение в статье: Текст: представление, хранение, ввод |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы