 |
Главная |


Кодирование текстовой информаци и
|
из
5.00
|
Кодирование информации
В ЭВМ применяется двоичная система счисления, т.е. все числа в компьютере представляются с помощью нулей и единиц, поэтому компьютер может обрабатывать только информацию, представленную в цифровой форме.
Для преобразования числовой, текстовой, графической, звуковой информации в цифровую необходимо применить кодирование. Кодирование – это преобразование данных одного типа через данные другого типа.
Информация в ЭВМ кодируется, как правило, в двоичной или в двоично-десятичной системе счисления. Система счисления – это принятый способ наименования и записи чисел с помощью символов, имеющих определенные количественные значения.
В зависимости от способа изображения чисел системы счисления делятся на позиционные и непозиционные.
В позиционной системе счисления количественное значение каждой цифры зависит от ее места (позиции) в числе. В непозиционной системе счисления цифры не меняют своего количественного значения при изменении их расположения в числе. Количество различных цифр (P), используемых для изображения числа в позиционной системе счисления, называется основанием системы счисления. Значения цифр лежат в пределах от 0 до Р-1. В общем случае запись любого смешанного числа в системе счисления с основанием Р будет представлять собой ряд вида:
| am-1Pm-1+am-2Pm-2+...+a1P1+a0PO+a-1P-1+a-2P-2+...+a-sP-s, | (1.1) |
где нижние индексы определяют местоположение цифры в числе (разряд):
· положительные значения индексов - для целой части числа (m разрядов);
· отрицательные значения – для дробной (s разрядов).
Пример. Позиционная система счисления – арабская десятичная система, в которой основание P=10, для изображения чисел используются 10 цифр (от 0 до 9). Непозиционная система счисления – римская, в которой для каждого числа используется специфическое сочетание символов (XIV, CXXVII и т.п.).
Двоичная система счисления имеет основание Р=2 и использует для представления информации всего две цифры: 0 и 1. Существуют правила перевода чисел из одной системы счисления в другую, основанные в том числе и на соотношении (1.1).
Пример. 101110,101(2) = 1*25 +0*24 +1*23 +l*22 +1*21 +0*20 +l*2-1 +0*2-2 +l*2-3 = 46,625(10), т.е. двоичное число 101110,101 равно десятичному числу 46,625.
Пример: Перевести число 75 из десятичной системы в двоичную,
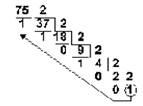
75(10) = 1 001 011(2)
При программировании иногда используется шестнадцатеричная система счисления, перевод чисел из которой в двоичную систему счисления весьма прост – выполняется поразрядно (полностью аналогично переводу из двоично-десятичной системы).
Для изображения цифр, больших 9, в шестнадцатеричной системе счисления применяются буквы А=10, В=11, С=12, D=13, Е=14, F=15.
Пример. 1А16 = 1*16+1*10=2610 и наоборот,
26:16=1
(26-16)=10=А
Для кодирования нечисловой информации используется следующий алгоритм: все возможные значения кодируемой информации нумеруются и эти номера кодируются с помощью двоичного кода.
Кодирование текстовой информаци и
В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code for Information Interchange), а в последнее время используется кодировка UNICODE.
Международная кодировка ASCII – American Standard Code for Information Interchange – американский стандартный код для обмена информацией для представления десятичных цифр, латинского и национального алфавитов, знаков препинания и управляющих символов. Для кодирования одного символа используется 1 байт (8 бит), что позволяет кодировать 255 символов (00000000 – 11111111). Первые 128 символов (занимающие семь младших бит) стандартизированы и занимают символы US-ASCII, а верхнюю (128 – 255) – другие символы. Так как в этот стандарт не входят символы национальных алфавитов других стран, то в каждой стране 128 кодов расширенных символов заменяются символами национального алфавита. Для кодировки русских букв используют различные кодовые таблицы:
KOI8R — восьмибитовый стандарт кодирования букв кириллических алфавитов (для операционной системы UNIX). Разработчики KOI8R поместили символы русского алфавита в верхней части расширенной таблицы ASCII таким образом, что позиции кириллических символов соответствуют их фонетическим аналогам в английском алфавите в нижней части таблицы. Это означает, что из текста написанного в KOI8R, получается текст, написанный латинскими символами;
СР1251 – восьмибитовый стандарт кодирования, используемый в OS Windows;
CP10007 - восьмибитовый стандарт кодирования, используемый в кириллице операционной системы Macintosh (компьютеров фирмы Apple);
ISO-8859-5 – восьмибитовый код, утвержденный в качестве стандарта для кодирования кирилического алфавита.
В настоящее время существует универсальный стандарт UNICODE (предложен в 1991 году некоммерческой организацией «Консорциум Юникода»), основанный на 16 – разрядном кодировании символов. Он определяет связь между символом и некоторым числом, а формат, согласно с которым эти числа будут превращаться в байты, определяется Юникод-кодировками (например, UTF-8 или UTF-16). На данный момент в Юникод-стандарте есть немного более 100 тысяч символов, тогда как UTF-16 позволяет поддерживать более одного миллиона.
|
из
5.00
|
Обсуждение в статье: Кодирование текстовой информаци и |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы