 |
Главная |


Приложение для Application for PID control
|
из
5.00
|
Введение.
В 1995 году Кеннеди и Элберхарт, вдохновленные тем, как птицы ищут себе пищу, предложили алгоритм оптимизации роя частиц (PSO), который привлек внимание ученых кругов и продемонстрировал превосходство в решении практических задач. PSO – это тип эволюционного алгоритма, который похож на алгоритм имитации отжига (SA). PSO начинается из случайного решения, ищет итеративно оптимальное решение, а затем оценивает качество решения на основе пригодности. PSO следует текущему оптимальному значению для поиска глобального оптимума, поэтому он проще, чем генетический алгоритм (GA), без необходимости для операций «крест» и «мутация». Однако PSO страдает двумя проблемами: преждевременная конвергенция и медленная конвергенция на поздней стадии. В последние два десятилетия многие исследователи сосредоточились на решении этих проблем путем введения некоторых методов и концепций. (Далее перечисляются эти методы) Концепция веса инерции была введена и применена в формуле Y.Shi и Эберхарта, они установили вес от 0,9 до 0,4 для обеспечения баланса между эксплуатацией и исследованием. На основании этого более поздние исследователи разработали адаптивный инерционный вес и коэффициенты. Чтобы избежать преждевременной сходимость роя частиц, Риджет Дж. и Вестерстрим Джс. предложили концепцию многообразия: они устанавливают нижнюю границу многообразия для хорошей поисковой возможности роя. Идея имитации отжига (SAPSO) была введена, чтобы помочь частице выпрыгнуть из локального оптимума [9]. Серый реляционный анализ был введен для изменения параметров PSO, чтобы помочь улучшить производительность алгоритма [10]. Идея хаотического поиска для глобального поиска была предложена в [11], которая была улучшена введением алгоритма квадратичной последовательности программы (SQP) для ускорения сходимости в [12]. Градиентный поиск для точного вычисления глобальный минимум был предложен в [13]. Между тем, некоторые исследователи сосредоточились на структурных и гетерогенный фактор, такой как SIPSO [14], SFPSO [15] и LIPSO [16].
Чтобы решить мультимодальные проблемы, J.J. Лян предложил всеобъемлющий обучающий частицу оптимизатор роя (CLPSO) [17]. Позже Лян и Сугантан предложили адаптивный оптимизатор с историческим обучением, для которого вероятности обучения частиц отрегулированы адаптивно. Исходя из этого, исследователи поняли, что метод поиска CLPSO был достаточно эффективным для поиска глобального оптимума. Однако CLPSO имел медленное разрешение как недостаток. К этому моменту было предложено несколько его улучшенных версий. Ортогональный экспериментальный дизайн был введен в CLPSO для того, чтобы определить лучшую комбинацию обучения из лучшей позиции частицы или её исторически сложившихся соседей [19]. Zheng et al. [20] было предложено ACLPSO, который адаптивно устанавливает коэффициенты алгоритма, то есть вес инерции и коэффициент ускорения. Насир [21] предложил DNLPSO, в котором использовалась стратегия обучения, при которой все историческая лучшая информация других частиц была использована для обновления скорости частицы, как в CLPSO. Однако, в отличие от CLPSO, образец частицы был выбран из окрестности. Окрестности создавались динамически по своей природе, то есть реформировались через определенные промежутки времени. Сян Юй ввел некое возмущение в итерационные формы CLPSO. Он определил вероятности обучения частиц между их историческими лучшими ценностями и размерные границы. Поскольку есть предел для возмущения, это ускорит конвергенцию. На основе CLPSO, некоторые многоцелевые задачи оптимизации могут быть решены с использованием концепции доминирования Парето.
В этом исследовании был предложен новый улучшенный алгоритм, названный LILPSO, который был основан на CLPSO, введя метод интерполяции Лагранжа. Есть два основных различия между LILPSO и CLPSO. Во-первых, когда этот алгоритм работает как метод поиска CLPSO, иногда вводится одно интерполяционное вычисление Лагранжа для каждого измерения лучшей точки (  ). Это локальный метод поиска, и он поможет ускорить сходимость. Во-вторых, CLPSO выбирает лучший из исторических оптимумов (
). Это локальный метод поиска, и он поможет ускорить сходимость. Во-вторых, CLPSO выбирает лучший из исторических оптимумов ( 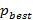 ) двух других частиц как образец в d-м измерении. По сравнению с CLPSO, LILPSO выбирает три точки, которые являются - i-ым историческим оптимумом этих частиц, другим случайным исторический оптимумом частиц и глобальным оптимумом ( ), -чтобы выполнить интерполяцию Лагранжа, а затем получить параболу, оптимум которой - ожидаемый образец.
) двух других частиц как образец в d-м измерении. По сравнению с CLPSO, LILPSO выбирает три точки, которые являются - i-ым историческим оптимумом этих частиц, другим случайным исторический оптимумом частиц и глобальным оптимумом ( ), -чтобы выполнить интерполяцию Лагранжа, а затем получить параболу, оптимум которой - ожидаемый образец.
Остальная часть этой статьи организована следующим образом: в разделе 2 представлены связанные работы, касающиеся PSO и CLPSO, и обсуждается теория интерполяции Лагранжа. В разделе 3 предлагается LILPSO обсуждается достаточно подробно. В разделе 4 приведены экспериментальные результаты на разных функции, чтобы доказать превосходство LILPSO. В разделе 5 представлены выводы документа.
Сопутствующие работы
2.1 PSO algorithm (Метод роя частиц)
Предполагая, что проблема оптимизации:

Если частица обозначается как  , то лучшее найденное значение позиции этих частиц равно
, то лучшее найденное значение позиции этих частиц равно  , также обозначаемое
, также обозначаемое  . Индекс наилучшего положения в группе частиц, представленной символом g, обозначается
. Индекс наилучшего положения в группе частиц, представленной символом g, обозначается  или
или  . Скорость i -ой частицы обозначается как
. Скорость i -ой частицы обозначается как  , для каждого поколения его итерационные функции d-го измерения:
, для каждого поколения его итерационные функции d-го измерения:

где  и
и  - положительные постоянные, называемые коэффициентами/факторами обучения;
- положительные постоянные, называемые коэффициентами/факторами обучения;  и
и  векторы случайных чисел от 0 до 1;
векторы случайных чисел от 0 до 1; 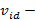 скорость измерения каждой частицы,
скорость измерения каждой частицы,  i-й частицы d-го измерения,
i-й частицы d-го измерения,  d-го измерения. Первая часть справа от знака равенства в уравнении 1 обусловлена предыдущей скоростью частицы, называемой «инерционной» частью. Вторая часть – это часть «познания», которая показывает, что частица мыслит сама, а также влияет сама информация о частицах следующего шага. Третья часть — это «социальная» часть, которая иллюстрирует обмен информацией и сотрудничество, а также влияние на рой информации о следующем шаге.
d-го измерения. Первая часть справа от знака равенства в уравнении 1 обусловлена предыдущей скоростью частицы, называемой «инерционной» частью. Вторая часть – это часть «познания», которая показывает, что частица мыслит сама, а также влияет сама информация о частицах следующего шага. Третья часть — это «социальная» часть, которая иллюстрирует обмен информацией и сотрудничество, а также влияние на рой информации о следующем шаге.
2.2 CLPSO algorithm (Комплексное Обучение Метода Роя Частиц)
Итерационная функция CLPSO отличается от стандартной PSO:

где,  ,
,  = 0,9 и
= 0,9 и  = 0,4 (используется концепция веса инерции),
= 0,4 (используется концепция веса инерции),  является образцом i-ой частицы в d-м измерении. Если i-я частица не обновляет свой исторический оптимум ( ) непрерывно и через промежуток m (обычно m = 7), тогда будет сгенерировано случайное число от 0 до 1; для каждого измерения, если полученное число меньше, чем pc (i) (вероятность обучения) (уравнение 5), то еще два исторические оптимальные значения частиц будут сравниваться с лучшим выбранным для образца в d-м измерении. Если все образцы частицы являются ее собственным , то мы случайным образом выберем одно измерение, чтобы изучить другие версии соответствующего измерения.
является образцом i-ой частицы в d-м измерении. Если i-я частица не обновляет свой исторический оптимум ( ) непрерывно и через промежуток m (обычно m = 7), тогда будет сгенерировано случайное число от 0 до 1; для каждого измерения, если полученное число меньше, чем pc (i) (вероятность обучения) (уравнение 5), то еще два исторические оптимальные значения частиц будут сравниваться с лучшим выбранным для образца в d-м измерении. Если все образцы частицы являются ее собственным , то мы случайным образом выберем одно измерение, чтобы изучить другие версии соответствующего измерения.

2.3 Lagrange interpolation (Метод интерполяции Лагранжа)
Теория интерполяции Лагранжа заключается в использовании полинома для представления отношения между несколькими объектами. Например, при наблюдении физической величины, если мы получаем разные значения в разных местах, то полином может быть смоделирован методом интерполяции Лагранжа. Цель этого метода в основном - подбор данных в инженерных экспериментах.
Это своего рода метод плавного подбора кривой. Как правило, если оптимумы (позиции / пригодности)  в n+1 точках
в n+1 точках  ,
,  ,…,
,…,  функции
функции  известны, тогда рассматривается многочлен
известны, тогда рассматривается многочлен  , который занимает n+1 точек и число которых равно не менее чем n.
, который занимает n+1 точек и число которых равно не менее чем n.

Если мы хотим оценить точку  ,
,  , то пригодность
, то пригодность 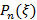 может быть приблизительным значением
может быть приблизительным значением  . В этом случае получаем:
. В этом случае получаем:

где ошибка 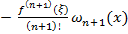 ,
,  параметр, связанный с x,
параметр, связанный с x, 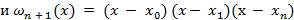 .
.
Предлагаемые методы
3.1 Local search with Lagrange interpolation (LSLI) (Локальный поиск с помощью метода интерполяции Лагранжа)
Основная идея метода поиска CLPSO состоит в том, чтобы заставить частицу сменить максимально возможное количество локальных оптимумов. Следовательно, уравнение 3 CLPSO обрезает глобальную часть оптимума по сравнению с уравнением 1 PSO. Более того, после изучения оптимума другой частицы, CLPSO устанавливает значение разрыва m, чтобы обработать эту информацию. Эта процедура замедляет сходимость частиц роя, однако является полезна для решения многомодальной функций.
Чтобы ускорить конвергенцию, было решено добавить в CLPSO своего рода локальный поиск. Безусловно есть несколько видов эффективной техники: субградиент, возмущение, мутация или хаотический поиск с соседством. Техника субградиента может легко найти направление сходимости. Однако для прерывистых и недифференцируемых задач полученное направление вводит в заблуждение сходимость. В дополнение размер шага определить сложно. На технику возмущения с соседством не влияет по форме функции. Однако этот метод не имеет направления сходимости, и обычно нуждается во многих дополнительных оценках функций (FE). Следовательно, мы адаптируем технику локального поиска лагранжевой интерполяции, чтобы ослабить эти проблемы.
Для j-го измерения (итерации) мы выбираем три точки, чтобы сгенерировать информацию и выполнить интерполяцию Лагранжа. Одна точка — это сам , другие две точки - возмущения на значение  рядом с . Значение возмущения обозначается , показанной в уравнении 7:
рядом с . Значение возмущения обозначается , показанной в уравнении 7:

где v (i, j) - скорость частицы, которая наилучшим образом подходит для каждой итерации; η - очень маленький коэффициент. В этом исследовании устанавливается 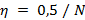 , N - размер роя частиц. В j-о(м/й) измерении/итерации пространства три точки могут генерировать параболу методом интерполяции Лагранжа, и таким образом можно будет получить минимальную точку, от которой будет выполняться поиск. Уравнения 9 и 10 являются интерполяционными вычислениями Лагранжа.
, N - размер роя частиц. В j-о(м/й) измерении/итерации пространства три точки могут генерировать параболу методом интерполяции Лагранжа, и таким образом можно будет получить минимальную точку, от которой будет выполняться поиск. Уравнения 9 и 10 являются интерполяционными вычислениями Лагранжа.

где  = позиция ,
= позиция ,  = позиция ,
= позиция ,  -позиция
-позиция  . Пусть
. Пусть
После вычислений получается квадратичный полином:

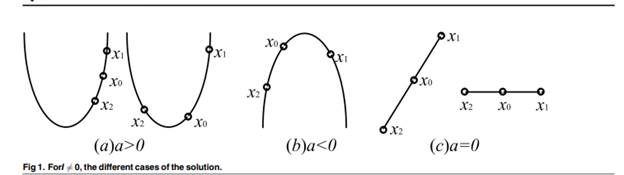
На рис. 1 показаны различные случаи искомого решения. В случае, когда 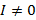 , имеется три разные точки, если a > 0, то произойдут два случая: во-первых, находится между и , а другой - то, что находится на одной стороне от между и . На этот раз выбирается минимальная точка
, имеется три разные точки, если a > 0, то произойдут два случая: во-первых, находится между и , а другой - то, что находится на одной стороне от между и . На этот раз выбирается минимальная точка  в качестве решения, затем сравнивается с . Если а < 0, то мы случайным образом сгенерируем точку около наименьшей по формуле 11. Где
в качестве решения, затем сравнивается с . Если а < 0, то мы случайным образом сгенерируем точку около наименьшей по формуле 11. Где  ,
,  и
и  специальные точки , и в зависимости от их пригодности отдельно. Если а = 0, то три точки образуют линию. Если a = 0 и b = 0, это означает, что = = , тогда мы случайным образом выберем положение от области, обозначенной как x3 (уравнение 12), где
специальные точки , и в зависимости от их пригодности отдельно. Если а = 0, то три точки образуют линию. Если a = 0 и b = 0, это означает, что = = , тогда мы случайным образом выберем положение от области, обозначенной как x3 (уравнение 12), где 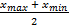 — это поисковый центр, а поскольку -0,5 < RAND - 0,5 < 0,5, случайный радиус поиска составляет от 0 до половины площади. Если a = 0 и b != 0, тогда решение будет выбрано уравнением 11. Когда I = 0, что означает v (i, j) = 0, тогда процедура будет прекращена.
— это поисковый центр, а поскольку -0,5 < RAND - 0,5 < 0,5, случайный радиус поиска составляет от 0 до половины площади. Если a = 0 и b != 0, тогда решение будет выбрано уравнением 11. Когда I = 0, что означает v (i, j) = 0, тогда процедура будет прекращена.


По сравнению с другими методами локального поиска интерполяция Лагранжа имеет три характеристики. Во-первых, этот метод имеет очень высокую скорость сходимости, особенно для одномодальных функций. Например, для вычисления функции сферы, глобальный оптимум которой  , предположим, что
, предположим, что  это
это  , а delta = 2. После одного интерполяционного вычисления Лагранжа мы получили следующий - . Во-вторых, для каждого измерения интерполяции Лагранжа, это будет стоить три дополнительных оценки функций (FE), и для задачи размерности D дополнительные FE в будут 3*D. В-третьих, поведение лагранжевой интерполяции является лишь локальным поиском, оно не нарушит разнообразие роя частиц, следовательно, оно останется поисковой способностью CLPSO для мультимодальных функций.
, а delta = 2. После одного интерполяционного вычисления Лагранжа мы получили следующий - . Во-вторых, для каждого измерения интерполяции Лагранжа, это будет стоить три дополнительных оценки функций (FE), и для задачи размерности D дополнительные FE в будут 3*D. В-третьих, поведение лагранжевой интерполяции является лишь локальным поиском, оно не нарушит разнообразие роя частиц, следовательно, оно останется поисковой способностью CLPSO для мультимодальных функций.
3.2 Lagrange interpolation learning (LIL)
В CLPSO, если i -ой частицы не обновляется определенное количество раз, тогда другие из двух частиц будут выбраны для сравнения, а лучшим будет один из них. Однако, если он будет все еще хуже, чем i-ой частицы, тогда эта частица останется до следующего flag (i)>m, с большой вероятностью. Следовательно, лучший способ улучшить эффективность поиска заключается в том, чтобы установить в качестве образца. Тем не менее, так называемый в вычисления — это не настоящий , скорее, это может быть лучшим из многих локальных оптимумов, которые программа запускает до текущего момента. Если мы установим в качестве примера напрямую, как в традиционном PSO, то тогда точно произойдет преждевременная конвергенция.
Чтобы избежать как застойной природы частицы, так и преждевременной конвергенции, авторы статьи гарантируют, что информация образца имеет две характеристики. Во-первых, пригодность образца, по крайней мере, лучше, чем i-й частицы. Во-вторых, информация из образца изначально имеет разнообразие, что не может привести к тому, что все частицы преждевременно улетят в одну и ту же область. Следовательно, авторы решили выбрать три точки, чтобы получить информацию, упомянутую выше. Одна точка имеет пригодность i-ой частицы, другая точка — это , а последняя точка — это случайной частицы, исключая i-ю частицу. В пространстве d-го измерения три точки могут создать параболу методом интерполяции Лагранжа, и желаемую минимальную точку соответственно.
Это поисковое поведение имеет три сильных стороны: во-первых, образец является минимумом из интерполяция Лагранжа с тремя точками, которые являются двумя и одним , этот процесс гарантирует, что направление обучения всегда летит к теоретической точке, которая лучше, чем . Во-вторых, для большей части локального поиска необходимо потратить дополнительное время на вычисление функций оценки (FE) для получения некоторой ключевой информации, тогда как LIL не требует каких-либо дополнительных FEs. В-третьих, после выполнения LSLI, упомянутого в разделе 3.1, мы получили лучший , поэтому LIL может передать эту информацию другим частицам так быстро, как только возможно.
3.3 Parametric settings
Для удобного вычисления планируется запустить LSLI для N раз, который равен размеру частицы роя. Однако, для честного сравнения, отмечается, что будет 3*D дополнительных FE для каждого LSLI, и надеются, что суммарные FE всех сравниваемых алгоритмов равны, поэтому сокращают максимальное число итераций (max_gen) до max_gen - 3*D. Стоимость FE в LSLI составляет 3*D*N, и стоимость FE на остальной части  , итого получается общее количество FE max_gen * N, что то же самое с CLPSO.
, итого получается общее количество FE max_gen * N, что то же самое с CLPSO.
Когда запускать LSLI? Устанавливается разрыв g,  , где
, где  . Следовательно, когда рой частиц обновляется для g раз по формулам 3 и 4, LSLI будет работать один раз. В CLPSO вероятность обучения pc (i) установлена как уравнение 5. В этом исследовании выбрана линейная вероятность для увеличения шанса обучения:
. Следовательно, когда рой частиц обновляется для g раз по формулам 3 и 4, LSLI будет работать один раз. В CLPSO вероятность обучения pc (i) установлена как уравнение 5. В этом исследовании выбрана линейная вероятность для увеличения шанса обучения:

Для сравнения с OLPSO в этом алгоритме выбраны и равными 2,  и
и  . Установка границ пространства поиска и скорости любой частицы влияет на процедуру поиска, поэтому были выбраны те же настройки границы скорости, которые используются в большинстве алгоритмов.
. Установка границ пространства поиска и скорости любой частицы влияет на процедуру поиска, поэтому были выбраны те же настройки границы скорости, которые используются в большинстве алгоритмов.
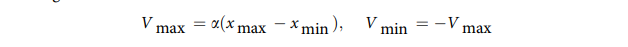
где α = 0,2.
Numerical experiments







В таблице представлены семнадцать функций, где F1, F3, F4 и F5 - унимодальные функции; Розенброк (F2) является мультимодальной функцией, имеющей узкую долину и трудно достижимый глобальный оптимум; F5 - шумная функция, у которой есть дискретная проблема; не повернутые мультимодальные функции включают F6-F11; F12 и F13 вращаются мультимодальные функции; F14-F16 - сдвинутые повернутые мультимодальные функции. Ортогональный матрица M генерируется согласно [38].
Так как некоторые другие алгоритмы, такие как PSO-cf-local [36], UPSO [40], FIPS [41] и DMSPSO [42], доказано, что они менее превосходят CLPSO в ссылке [19]; следовательно, в этом исследовании мы просто нужно сравнить LILCLPSO с CLPSO, ECLPSO, OLPSO и DNLPSO, чей итеративный формы представлены в таблице 2. Параметрическая настройка ЭКЛПСО такая же, как ЭКЛПСО-4 в [22]. Поскольку мы не знаем точную ортогональную матрицу для OLPSO, мы вводим результат непосредственно из ссылки [19]. Для DNLPSO нет точных данных топологии, поэтому вводится результат непосредственно из ссылки [26]. Чтобы доказать производительность LSLI и LIL, тестируются два алгоритма, называемые LILPSO1 и LILPSO2, где, LILPSO1 просто адаптирует технику LSLI, а LILPSO2 адаптирует и технику LSLI, и LIL.
Для задач 10*D используются следующие параметры: количество частиц - 50, номер итерации - 2000 и FE - 100 000;
Для задач 30*D используются следующие параметры: количество частиц - 40, число итераций - 5000 и FE - 200 000;
Для задач 50*D используются следующие параметры: номер частицы - 100, номер итерации - 5000 и FE - 500 000. Каждая функция, каждый алгоритм выполняется по 25 раз, и решения анализируются с использованием двухстороннего t-критерия с уровнем достоверности 0,05, ‘+’, ‘-’ и ‘=’ означают, что LILPSO лучше, хуже и равны другим алгоритмам статистически соответственно.
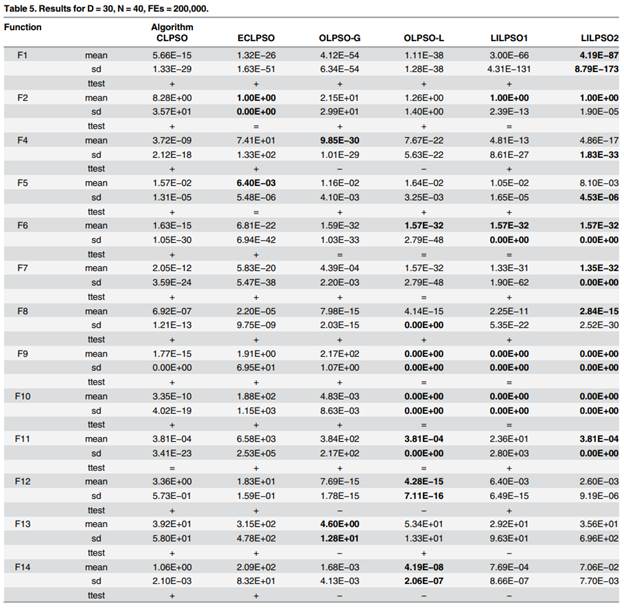
Для одномодальных и низкоразмерных задач DNLPSO имеет относительно лучшую производительность. Для шумной функции F5 LILPSO имеет лучшую производительность. Для универсальной функции F3, DNLPSO и LILPSO имеют равные решения. Потому что итеративная форма DNLPSO содержит часть, это, без сомнения, будет иметь быструю сходимость для одномодальных функций. Кроме того, поведение топологии окрестностей на самом деле играет роль уменьшения пространства поиска. Тем не менее, для задач большого размера, то есть 50*D, у LILPSO есть все лучшие решения, которые иллюстрирует, что метод интерполяции Лагранжа обладает высокой скоростью сходимости для сложных задач большой размерности.
Для мультимодальных задач DNLPSO мало превосходит LILPSO практически по всем функциям. Сравнивая OLPSO с LILPSO в 30D задачах, для F2 и F8, LILPSO имеет лучшее решения - для F6, F7, F9, F10 и F11, - LILPSO имеет статистически равные решения с OLPSO, которые иллюстрируют, что метод интерполяции Лагранжа может помочь ускорить сходимость при выполнении локального поиска. Для F12, F13 и F14 OLPSO превосходит LILPSO, который иллюстрирует, что LSLI ограничен вращающимися проблемами, хотя все еще лучше, чем CLPSO.
Сравнивая LILPSO1 с LILPSO2, для большинства проблем LILPSO2 превосходит LILPSO1, который показывает, что LIL может помочь в обмене информацией LSLI для ускорения конвергенции. Между тем, в отличие от - части DNLPSO, LIL также не нарушает разнообразия частиц, ни привести частицы к преждевременной конверсии. Тем не менее, для повернутых функций, таких как F13, F14, F16 и F17, решения LILPSO1 лучше, чем LILPSO2, что показывает, что LIL также не подходит для решения повернутых задач.
Сравнивая CLPSO с LILPSO, LILPSO предлагает решения, лучшие, чем CLPSO, тем самым иллюстрирует, что интерполяция Лагранжа является стабильной и эффективной техникой локального поиска.
Сравнивая OLPSO с LILPSO, они оба наследуют преимущество CLPSO в решении мультимодальные проблемы, тем не менее, LILPSO явно превосходит OLPSO в решении одномодальные проблемы. Кроме того, OLPSO-L необходимо  для хранения связанных с алгоритмом структур данных, что означает более длительное время для сложных задач мирового уровня. В сравнении LILPSO просто нужно небольшое количество памяти для хранения некоторых связанных переменных, то есть
для хранения связанных с алгоритмом структур данных, что означает более длительное время для сложных задач мирового уровня. В сравнении LILPSO просто нужно небольшое количество памяти для хранения некоторых связанных переменных, то есть  .
.
Приложение для Application for PID control
Система вращения вентилятора, управляемая запуском турбовентиляторного масла. Передаточная функция системы:

ПИД-регулирование по усмотрению:

Целевая функция:

где |e ( t )| - ошибка,  - время нарастания, u ( t ) - выходной сигнал контроллера,
- время нарастания, u ( t ) - выходной сигнал контроллера,  ,
,  ,
,  - веса. Чтобы решить проблему перегрузки системы, используется штрафная функция, как только система проходит перерегулирование, целевой функцией будет:
- веса. Чтобы решить проблему перегрузки системы, используется штрафная функция, как только система проходит перерегулирование, целевой функцией будет:

Где  >>
>>  ,
,  ,
,  - выход управляемого объекта. В этом примере = 0,5,
- выход управляемого объекта. В этом примере = 0,5,  = 1,
= 1,  = 1, = 200, диапазон
= 1, = 200, диапазон  ,
,  ,
, 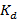 составляет соответственно [0,2, 10], [1,50], [1e-7, 1e-1], и превышение должно быть меньше 20%. Следовательно, проблема заключается в следующем:
составляет соответственно [0,2, 10], [1,50], [1e-7, 1e-1], и превышение должно быть меньше 20%. Следовательно, проблема заключается в следующем:

Параметры устанавливаются следующим образом: размер роя N=30, функциональные оценки FE = 3000. Результаты показаны в таблице ниже:

Это показывает, что результаты, оптимизированные с помощью LILPSO2, имеют наименьшую цель значение функции и средняя ошибка. Следовательно, алгоритм LILPSO2 более эффективен.
Заключение
В этом исследовании авторы предложили новый метод, известный как LILPSO, чтобы улучшить современный метод CLPSO. Сначала вводится интерполяционный подход Лагранжа для локального поиска рядом с оптимумом и помощь в ускорении сближения. Во-вторых, этот метод введен для замены простого сравнения, используемого в CLPSO, для достижения лучшего образца. После выполнения численных экспериментов LILPSO было доказано, что он превосходит CLPSO, ECLPSO, DNLPSO, OLPSO для большинства рассмотренных тестовых функций. Интерполяция Лагранжа зарекомендовала себя как эффективный подход локального поиска, за исключением чередующихся задач.
|
из
5.00
|
Обсуждение в статье: Приложение для Application for PID control |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы