 |
Главная |


Генерация случайных чисел
|
из
5.00
|
Генерация случайных чисел - слишком важный вопрос, чтобы оставлять его на волю случая.
Роберт Ковзю, Окриджская лаборатория.
Процессы в окружающем нас мире можно условно разделить на две категории – стохастические (т.е. имеющие случайную природу) и детерминированные (определённые, «жёстко заданные»). Например, в модели идеального газа каждая молекула движется по своему строго определённому пути, однако движение совокупности таких молекул практически нельзя просчитать и предсказать. Достаточно большой набор молекул будет обладать стохастическими свойствами
Когда вы попросите своего знакомого назвать вам случайное число, он без затруднений это сделает. Таким образом, этот процесс можно считать стохастическим. Но все действия, выполняемые компьютером, происходят по определённым алгоритмическим правилам. А это значит, что получение случайных величин представляет собой нетривиальную задачу.
В С++ для генерации псевдослучайных чисел есть специальные функции rand() и srand(). Они описаны в заголовочном файле cstdlib. Если воспользоваться только функцией rand() – будем получать одинаковые “случайные числа” от запуска к запуску. Наберите следующий код и откомпилируйте и запустите программу несколько раз. Обратите внимание, что “случайные числа” всегда будут одинаковы.
#include <iostream>
#include <cstdlib>
#define SIZE 10
int main(){
int random[SIZE];
for (int i = 0; i < SIZE; i++){
random[i] = rand(); // "случайное число"
std::cout << random[i] << " ";
}
return 0;
}
Функция srand() инициализирует генератор случайных чисел (здесь и далее будем их так называть, отдавая себе отчет в том, что на самом деле они псевдослучайные). Функция srand() устанавливает исходное число для последовательности, генерируемой функцией rand(). Т.е., изменяя каждый единственный аргумент этой функции – целое число, мы будем получать разные наборы случайных чисел. Чаще всего в качестве аргумента srand() используется значение функции time, возвращающее текущее время в секундах.
Значение максимальной величины псевдослучайных чисел определяется константой RAND_MAX в cstdlib. Для того чтобы ограничить диапазон значений, скажем, от 0 до 99 используем операцию вычисления остатка деления на 100.
#include <iostream>
#include <cstdlib>
#include <time.h>
#define SIZE 10
int main(){
int random[SIZE];
srand(time(NULL));
for (int i = 0; i < SIZE; i++){
random[i] = rand() % 100; //"случайное число" от 0 до 99
std::cout<<random[i] << " ";
}
}
Если нам потребуется диапазон от -20 до 50, в котором 71 число (20 отрицательных, ноль и 50 положительных), то формулу можно изменить так
random[i] = rand() % 71 - 20; //"случайное число" от -20 до 50
Задача №116. Случайная перестановка
Необходимо сгенерировать случайную перестановку из N элементов, так чтобы каждая перестановка имела одинаковую вероятность.
Решение
Применим алгоритм тасования Фишера-Йетса[25]. Основная процедура тасования Фишера–Йетса аналогична случайному вытаскиванию записок с числами из шляпы или карт из колоды, один элемент за другим, пока элементы не кончатся. Алгоритм обеспечивает эффективный и строгий метод таких операций, не требуя дополнительной памяти [1 стр. 26-27].
#include <iostream>
#include <cstdlib>
#include <algorithm>
#include <time.h>
#define N 20
using namespace std;
int main(){
int a[N], j;
for (int i = 0; i < N; i++) a[i] = i+1;
srand(time(NULL));
for (int i = 0; i < N; i++){
j = rand() % (i+1);
swap(a[i],a[j]);
}
for (int i = 0; i < N; i++) cout << a[i] << " ";
}
Задачи с символами и строками
Помимо математических способностей, жизненно важным качеством программиста является исключительно хорошее владение родным языком.
Э. Дейкстра
Символьный тип данных
Тип данных char — это целочисленный тип данных, который используется для представления символов. То есть, каждому символу соответствует определённое число из диапазона 0..255.
Этот тип в памяти занимает 1 байт и обладает одной интересной особенностью – несмотря на то, что он фактически целочисленный однобайтный, он обрабатывается как символ. Если требуется вывести его как число, необходимо использовать преобразование типа. Например,
char ch = 71; // то же самое, что ch='G'
cout << ch << endl; // выведет G
cout << (int)ch; // выведет 71
Коды символов соответствуют стандарту ASCII[26].
ASCII (англ. American Standard Code for Information Interchange) — американская стандартная 8-битная кодировочная таблица для печатных символов и некоторых специальных кодов.
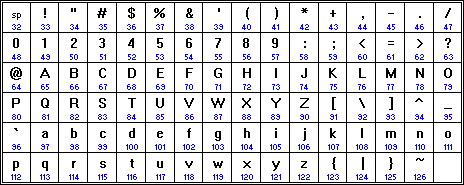
Рис. 20. Базовая таблица кодов ASCII
Кодовая таблица обладает интересными структурными особенностями, на которые стоит обратить внимание.
Во-первых, цифры располагаются в порядке возрастания подряд. То же самое касается и букв. Таким образом, если символ является цифрой, значение которой нам нужно получить, то
char ch = '7';
int valch = ch - '0'; // то же, что valch=7
Обратите внимание, значение символьного типа, в отличие от строкового, берётся в одинарные кавычки.
Во-вторых, такое представление позволяет работать с символами, как с числами, коими они в памяти компьютера, в сущности, являются. Например, вывести все заглавные латинские буквы позволяет строка кода:
for(char letter = 'A'; letter <= 'Z'; letter++)
cout << letter;
В итоге отобразится:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
В-третьих, цифры 0—9 представляются своими двоичными значениями (например, 5=01012), перед которыми стоит 00112. Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит 1002 (для букв верхнего регистра) или 1102 (для букв нижнего регистра).
Например, фрагмент программы
char ch[]="DURA LEX SED LEX"; //”закон суров, но это закон”
int len = sizeof(ch);
for(int i = 0; i < len; i++) cout << char(ch[i] | 0x20);
выведет в нижнем регистре
dura lex sed lex
В данном случае мы используем побитовую дизъюнкцию (битовое «ИЛИ») с числом 0x20 (в двоичной системе 00100000, в десятичной 32)
| D | U | R | A | |||||||||||||||||||||||||||||
| код | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0х20 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| или | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
| d | u | r | a | |||||||||||||||||||||||||||||
ВАЖНО: Для изменения регистра символа латинского алфавита можно применятьусловный оператор для определения текущего регистра и применять арифметическую операцию +32 для перевода в верхний регистр и -32 для перевода в нижний соответственно. Но гораздо проще и быстрее применить XOR (побитовое исключающее «ИЛИ»)с числом 0x20. Например, для
char ch = 'R';
ch ^= 0x20;
cout << ch; // выведет r
ch ^= 0x20;
cout << ch; //выведет R
| ASCII-код | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | символ 'R' |
| 0x20 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |
| ch^=0x20 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | символ 'r' |
| 0x20 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |
| ch^=0x20 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | символ 'R' |
Однако сведения о преобразовании регистра символов с помощью побитовых операций приводятся лишь для общего ознакомления и лучшего понимания структуры ASCII. В языках C/C++ нет необходимости применять побитовые операции, т.к. существует ряд полезных функций, описанных в заголовочном файле cctype. Например, если нужно вывести строку в верхнем, а затем в нижнем регистре, удобнее использовать функции toupper и tolower.
#include <cstdio>
#include <cctype>
int main (){
char s[] = "Test123.\n";
for(int i=0; s[i]; i++)
putchar (tolower(s[i]));
for(int i=0; s[i]; i++)
putchar (toupper(s[i]));
}
Данная программа выведет 2 строки:
test123.
TEST123.
Каждый цикл последовательно перебирает символы массива s вплоть до нахождения символа конца строки («нуль-терминатора») с кодом 0. Функция putchar из заголовочного файла cstdio позволяет выводить один символ, который преобразуется с помощью функций tolower или toupper. Там же описан и ряд других полезных функций, таких как isalpha для проверки, является ли символ алфавитным (буквой) и др.
Задача №117. Счастливый билет ("символьное решение")
Номер автобусного билета называют «счастливым», если сумма первой половины его цифр совпадает с суммой второй половины. Например, номер билета 1450 – счастливый. С консоли вводится шестизначный номер билета. Определите, является ли он счастливым.
Входные данные
Одно шестиразрядное натуральное число (первыми цифрами могут быть нули)
Выходные данные
Одно слово YES– если билет счастливый, NO– в другом случае.
Решение
#include <iostream>
using namespace std;
intmain() {
char a, b, c, x, y, z;
cin >> a >> b >> c >> x >> y >> z;
cout <<((a + b + c == x + y + z) ? "YES" : "NO");
}
Задача №118. Клетки (acmp.ru)
Известно, что шахматная доска имеет размерность 8×8 и состоит из клеток 2х цветов, например, черного и белого (см. рисунок). Каждая клетка имеет координату, состоящую из буквы и цифры. Горизонтальное расположение клетки определяется буквой от A до H, а вертикальное – цифрой от 1 до 8. Заметим, что клетка с координатой А1 имеет черный цвет. Требуется по заданной координате определить цвет клетки.
Входные данные
В единственной строке записана координата клетки на шахматной доске: всего два символа – буква и цифра (без пробелов).
Выходные данные
Нужно вывести «WHITE», если указанная клетка имеет белый цвет и «BLACK», если она черная.
Примеры
| № | Ввод | Вывод |
| 1 | C3 | BLACK |
| 2 | G8 | WHITE |
Решение
#include <iostream>
int main () {
char a, b;
std::cin >> a >> b;
std::cout << ((a+b)%2 ? "WHITE" : "BLACK");
}
Задача №119. Искатели сокровищ (чтение из строк)
Вася играет в игру «Искатели сокровищ». Суть игры состоит в следующем: игрок поочерёдно проходит в игре уровень за уровнем, попутно собирая сундуки с золотом. Золото в сундуках с первого уровня умножается на 1, со второго – на 2, с третьего – на 3 и т.д. Прохождение каждого уровня описывается строкой с числами, каждое из которых – золото, найденное Васей в сундуке. Игра завершается, когда игрок находит пустой сундук. Определите, какую сумму очков S набрал Вася в игре.
Входные данные
Заранее неизвестное количество строк (уровней), не превышающее 100, в каждую из которых записаны целые неотрицательные числа, не превышающие 109 – количество золота в найденных сундуках. Последнее число 0.
Выходные данные
Единственное число S– сумма очков, набранная за игру
Пример
| Ввод | Вывод |
| 1 2 3 8 4 5 11 12 0 | 101 |
Решение
#include <iostream>
using namespace std;
int main(){
unsigned long long gold, level = 0, sum=0;
do{
level++;
do{
cin >> gold;
sum += gold * level;;
} while (cin.get() != '\n');
} while(gold);
cout << sum << endl;
}
ВАЖНО: Последний символ строки обозначается '\0' (символ с кодом «ноль», нуль-терминатор). Если объявить строку как массив символов, то после нуль-терминатора в ячейках массива будет размещен «мусор» из оперативной памяти.
Рассмотрим следующую задачу.
Задача №120. Улитка на цветке
Одноклассница Васи Пупкина Маша Дроздова находит биологию очень увлекательной. Она проводит научный эксперимент, наблюдая целыми днями за улиткой, которая ползает по растению. Маша заметила, что в ясный день улитка поднимается на 5 сантиметров. А в пасмурный опускается на 3 см. Маша вела лабораторный журнал, в котором каждый ясный день обозначала знаком «плюс», а каждый пасмурный – знаком «звездочка» (правильно – астериск).
Определите, где должна находиться улитка, если у Вас есть Машин лабораторный журнал, известная начальная высота улитки и высота растения.
Входные данные
В первой строке два числа H – начальная высота улитки и L – высота растения.
Во второй строке набор символов, не превышающий 500, состоящий исключительно из + и *.
Выходные данные
Одно число – высота расположения улитки на момент конца наблюдений.
Пример
| Ввод | Вывод |
| 15 20 +++***+** | 10 |
Решение
#include<iostream>
int main() {
int h, l;
char day[500]; // задаём массив символов
std::cin >> h >> l >> day;
for(int i = 0; day[i]; i++){ // обрабатывать строку до '\0'
h += (day[i]== '+')? 5 : -3; // считаем высоту
if(h < 0) h = 0; // корректируем
if(h > l) h = l;
}
std::cout << h;
}
Задача №121. Напёрстки (acmp.ru)
Шулер показывает следующий трюк. Он имеет три одинаковых наперстка. Под первый (левый) он кладет маленький шарик. Затем он очень быстро выполняет ряд перемещений наперстков, каждое из которых – это одно из трех перемещений - A, B, C:
· A - обменять местами левый и центральный наперстки,
· B - обменять местами правый и центральный наперстки,
· C - обменять местами левый и правый наперстки.
Необходимо определить, под каким из наперстков окажется шарик после всех перемещений.
Входные данные
Строка длиной не более 50 символов из множества {A, B, C} – последовательность перемещений.
Выходные данные
Нужно вывести номер наперстка, под которым окажется шарик после перемещений.
Пример
| Ввод | Вывод |
| CBABCACCC | 1 |
Решение
Эту задачу можно решить непосредственно моделированием при помощи трёх переменных, поочередно применяя к ним swap, однако проще её сделать с помощью таблицы перемещений.
Пронумеруем возможные положения шарика под напёрстками (1 – под напёрстком есть шарик, 0 – нет): 100 – 0, 010 – 1, 001 – 2.
Тогда результаты всех перемещений можно описать при помощи таблицы
| A | B | C | |
| 0 | 1 | 0 | 2 |
| 1 | 0 | 2 | 1 |
| 2 | 2 | 1 | 0 |
#include <cstdio>
int main () {
char s[50];
scanf("%s", &s);
int x = 0, p[3][3] = {1, 0, 2,
0, 2, 1,
2, 1, 0};
for(int i = 0; s[i++];)
x = p[x][s[i]-'A'];
printf("%d", ++x);
}
Задача №122. Детали (acmp.ru)
На клеточном поле N×M расположены две жёсткие детали. Деталь A накрывает в каждой строке несколько (не ноль) первых клеток, деталь B — несколько (не ноль) последних; каждая клетка либо полностью накрыта одной из деталей, либо нет.
| A | A | . | B | B | B |
| A | . | . | . | . | B |
| A | A | A | . | . | B |
| A | . | . | B | B | B |
Деталь B начинают двигать влево, не поворачивая, пока она не упрётся в A хотя бы одной клеткой. Определите, на сколько клеток будет сдвинута деталь B.
Входные данные
В первой строке входного файла INPUT.TXT записано два числа N и M — число строк и столбцов соответственно (1 ≤ N, M ≤ 100). Далее следуют N строк, задающих расположение деталей. В каждой находится ровно M символов "A" (клетка, накрытая деталью A), "B" (накрытая деталью B) или "." (свободная клетка).
Выходные данные
В единственную строку выходного файла OUTPUT.TXT нужно вывести одно число — ответ на задачу.
Пример
| INPUT.TXT | OUTPUT.TXT |
| 4 6 AA.BBB A....B AAA..B A..BBB | 1 |
Решение
#include <cstdio>
#define SIZE 100
int n, m, ans = SIZE, cnt, i;
char c[SIZE];
int main(){
freopen("input.txt","r",stdin);
freopen("output.txt","w",stdout);
scanf("%d%d", &n, &m);
while(n--){
cnt = 0;
scanf("%s", &c);
for(i = 0; i < m; i++)
if(c[i] == '.') cnt++;
if(cnt < ans) ans = cnt;
}
printf("%d", ans);
}
ВАЖНО: В тех случаях, когда в задаче требуется найти реальную длину строки, а не размер массива символов, можно использовать функцию strlen из заголовочного файла cstring. (Не используйте для этого sizeof !!!). Например,
#include <iostream>
#include <cstring> // функция strlen
using namespace std;
int main(){
char str[1024];
cin.getline(str,1024);
cout << strlen(str);
}
Задача №123. Шахматы – кони (acmp.ru)
Совсем недавно Вася занялся программированием и решил реализовать собственную программу для игры в шахматы. Но у него возникла проблема определения правильности хода конем, который делает пользователь. Т.е. если пользователь вводит значение «C7-D5», то программа должна определить это как правильный ход, если же введено «E2-E4», то ход неверный. Так же нужно проверить корректность записи ввода: если например, введено «D9-N5», то программа должна определить данную запись как ошибочную. Помогите ему осуществить эту проверку!
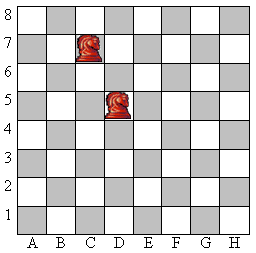
Рис. 21. Иллюстрация к задаче "Шахматы - кони"
Входные данные
В единственной строке записан текст хода (непустая строка), который указал пользователь. Пользователь не может ввести строку, длиннее 5 символов.
Выходные данные
Нужно вывести «YES», если указанный ход конем верный, если же запись корректна (в смысле правильности записи координат), но ход невозможен, то нужно вывести «NO». Если же координаты не определены или заданы некорректно, то вывести сообщение «ERROR».
Примеры
| № | Ввод | Вывод |
| 1 | C7-D5 | YES |
| 2 | E2-E4 | NO |
| 3 | BSN | ERROR |
Решение
#include<iostream>
#include<cmath>
#define ERR {cout << "ERROR"; return 0;}
using namespace std;
int main() {
string s;
cin >> s;
int n = s.size();
if (n-- <5 || s[2] != '-')ERR;
int a[] = {s[0]-'A', s[1]-'1', s[3]-'A', s[4]-'1'};
for(; n--;)
if(a[n] < 0 || 7 < a[n])ERR;
cout << (abs((a[2]-a[0])*(a[3]-a[1]))==2 ? "YES" : "NO");
}
Задача №124. Ферзь, ладья и конь (acmp.ru)
На шахматной доске 8х8 расположены три фигуры: ферзь, ладья и конь. Требуется определить количество пустых полей доски, которые находятся под боем. Для простоты будем полагать, что фигуры могут «бить» через другие фигуры. Например, в рассмотренной справа ситуации будем считать, что ферзь бьет D5 через ладью.
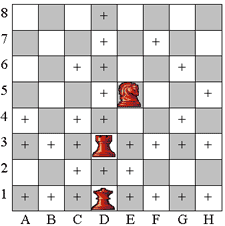
Рис. 22. Иллюстрация к задаче "Ферзь, ладья и конь"
Входные данные
В единственной строке входного файла INPUT.TXT записаны через пробел координаты расположения трех фигур: ферзя, ладьи и коня соответственно. Каждая координата состоит из одного латинского символа (от A до H) и одной цифры (от 1 до 8).
Выходные данные
В выходной файл OUTPUT.TXT нужно вывести количество пустых полей, которые бьют указанные во входных данных фигуры.
Пример
| Ввод | Вывод |
| D1 D3 E5 | 29 |
Решение
#include <iostream>
#include <cmath>
#define X(p) abs(x[p]-i)
#define Y(p) abs(y[p]-j)
using namespace std;
int main() {
string s;
getline(cin, s);
int x[] = {s[0] - 'A', s[3] - 'A', s[6] - 'A'}, c = -3,
y[] = {s[1] - '1', s[4] - '1', s[7] - '1'}, i, j;
for(i = 0; i < 8; i++)
for(j = 0; j < 8; j++)
c += !X(0) || !Y(0) || X(0)==Y(0) // ферзь
|| !X(1) || !Y(1) // ладья
|| X(2)*Y(2)==2 || !X(2) && !Y(2); // конь
cout << c;
}
Для коня необходимо было условие !X(2) && !Y(2), чтобы не исключить ту клетку, на которой находится сам конь.
Задача №125. Уравнение для 5 класса! (acmp.ru)
Уравнение для пятиклассников представляет собой строку длиной 5 символов. Второй символ строки является либо знаком '+' (плюс) либо '-' (минус), четвёртый символ — знак '=' (равно). Из первого, третьего и пятого символов ровно два являются цифрами из диапазона от 0 до 9, и один — буквой x, обозначающей неизвестное.
Требуется написать программу, которая позволит решить данное уравнение относительно x.
Входные данные
Входной файл INPUT.TXT состоит из одной строки, в которой записано уравнение.
Выходные данные
В выходной файл OUTPUT.TXT выведите целое число — значение x.
Примеры
| № | INPUT.TXT | OUTPUT.TXT |
| 1 | x+5=7 | 2 |
| 2 | 3-x=9 | -6 |
Решение
#include <cstdio>
using namespace std;
int main() {
freopen("input.txt", "r", stdin);
freopen("output.txt", "w", stdout);
char s[5];
scanf("%s", &s);
int ix, r, i;
for (i = 0; i < 5; i++) //ищем позицию x
if (s[i] == 'x') ix = i;
if (s[1] == '+'){ //если 2 символ «+»
if (ix == 4) r = s[0] + s[2] - 2*'0';
else
if (ix == 2) r = s[4] - s[0];
else r = s[4] - s[2];
} else { //если 2 символ «-»
if (ix == 0) r = s[2] + s[4] - 2*'0';
else
if (ix == 2) r = s[0] - s[4];
else r = s[0] - s[2];
}
printf("%d", r);
}
Задача №126. Кругляши (acmp.ru)
Однажды в просторах рунета появился следующий ребус:
157892 = 3
203516 = 2
409578 = 4
236271 = ?
Никто так и не смог его разгадать. Позже оказалось, что число в правом столбце равно сумме "кругляшей", которые есть в цифрах числа, расположенного слева. Ваша задача написать программу, которая определяет, сколько кругляшей в числе.
Входные данные
Во входном файле INPUT.TXT записано целое число N (0 <= N <= 10100).
Выходные данные
В выходной файл OUTPUT.TXT выведите одно число – количество кругляшей в числе N.
Примеры
| № | INPUT.TXT | OUTPUT.TXT |
| 1 | 157892 | 3 |
| 2 | 203516 | 2 |
| 3 | 409578 | 4 |
| 4 | 236271 | 1 |
Решение
Очевидно, размер данных при вводе может существенно превышать возможности стандартных типов. Воспользвемся представлением числа как строки.
#include<cstdio>
intmain() {
freopen("input.txt", "r", stdin);
freopen("output.txt","w",stdout);
char s[100];
int count = 0;
scanf("%s", &s);
for(int i=0; s[i]; i++) {
if(s[i]=='8') count += 2;
if(s[i]=='0' || s[i]=='6' || s[i]=='9') count++;
}
printf("%d", count);
}
Задача №127. Черно-белая графика (acmp.ru)
(Время: 1 сек. Память : 16 Мб)
Одна из базовых задач компьютерной графики – обработка черно-белых изображений. Изображения можно представить в виде прямоугольников шириной w и высотой h, разбитых на w×h единичных квадратов, каждый из которых имеет либо белый, либо черный цвет. Такие единичные квадраты называются пикселами. В памяти компьютера сами изображения хранятся в виде прямоугольных таблиц, содержащих нули и единицы.
Во многих областях очень часто возникает задача комбинации изображений. Одним из простейших методов комбинации, который используется при работе с черно-белыми изображениями, является попиксельное применение некоторой логической операции. Это означает, что значение пиксела результата получается применением этой логической операции к соответствующим пикселам аргументов. Логическая операция от двух аргументов обычно задается таблицей истинности, которая содержит значения операции для всех возможных комбинаций аргументов.
Например, для операции «исключающее ИЛИ» эта таблица выглядит так:
| Первый аргумент | Второй аргумент | Результат |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Требуется написать программу, которая вычислит результат попиксельного применения заданной логической операции к двум черно-белым изображениям одинакового размера.
Входные данные
Первая строка содержит два целых числа w и h (1 ≤ w, h ≤ 100). Последующие h строк описывают первое изображение и каждая из этих строк содержит w символов, каждый из которых равен нулю или единице. Далее следует описание второго изображения в аналогичном формате. Последняя строка входного файла содержит описание логической операции в виде четырех чисел, каждое из которых – ноль или единица. Первое из них есть результат применения логической операции в случае, если оба аргумента – нули, второе – результат в случае, если первый аргумент – ноль, второй – единица, третье – результат в случае, если первый аргумент – единица, второй – ноль, а четвертый – в случае, если оба аргумента – единицы.
Выходные данные
Необходимо вывести результат применения заданной логической операции к изображениям в том же формате, в котором изображения заданы во входном файле.
Пример
| № | Ввод | Вывод |
| 1 | 5 3 01000 11110 01000 10110 00010 10110 0110 | 11110 11100 11110 |
Решение
Опишем логическую функцию с помощью массива символов. В самом деле, её аргументы можно перечислить
| x | y | F |
| 0 | 0 | F0 |
| 0 | 1 | F1 |
| 1 | 0 | F2 |
| 1 | 1 | F3 |
Легко заметить, что F(x, y) = F2x+y.
#include <iostream>
using namespace std;
int h, w, i, j, k = 2, x[100][100];
char c, f[4];
int main(){
cin >> w >> h;
while(k--)
for(i = 0; i < h; i++)
for(j = 0; j < w; j++){
cin >> c;
(x[i][j] *= 2) += c - '0';
}
cin >> f;
for(i = 0; i < h; i++){
for(j = 0; j < w; j++)
cout << f[x[i][j]];
cout << endl;
}
}
Задача №128. Распаковка строки (acmp.ru)
(Время: 1 сек. Память: 16 Мб)
Будем рассматривать только строчки, состоящие из заглавных латинских букв. Например, рассмотрим строку AAAABCCCCCDDDD. Длина этой строки равна 14. Поскольку строка состоит только из латинских букв, повторяющиеся символы могут быть удалены и заменены числами, определяющими количество повторений. Таким образом, данная строка может быть представлена как 4AB5C4D. Длина такой строки 7. Описанный метод мы назовем упаковкой строки.
Напишите программу, которая берет упакованную строчку и восстанавливает по ней исходную строку.
Входные данные
Входной поток содержит одну упакованную строку. В строке могут встречаться только конструкции вида nA, где n — количество повторений символа (целое число от 2 до 99), а A — заглавная латинская буква, либо конструкции вида A, то есть символ без числа, определяющего количество повторений. Максимальная длина строки не превышает 80.
Выходные данные
Выведите восстановленную строку. При этом строка должна быть разбита на строчки длиной ровно по 40 символов (за исключением последней, которая может содержать меньше 40 символов).
Примеры
| № | Ввод | Вывод |
| 1 | 3A4B7D | AAABBBBDDDDDDD |
| 2 | 22D7AC18FGD | DDDDDDDDDDDDDDDDDDDDDDAAAAAAACFFFFFFFFFF FFFFFFFFGD |
| 3 | 95AB | AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA AAAAAAAAAAAAAAAB |
| 4 | 40AB39A | AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA BAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA |
Решение
Опишем вспомогательную функцию out без параметров и возвращаемого значения для вывода одного символа. Это позволит разбить задачу на более простые подзадачи и сделать код более читабельным.
#include <iostream>
#define SIZE 40
char c;
int len = 0, count = 0;
void out(){
std::cout << c;
len++;
if(len == SIZE){
std::cout << '\n';
len = 0;
}
}
int main(){
while(std::cin >> c)
if(c>='A'){
if(!count) out();
else while(count--) out();
count = 0;
} else (count *= 10) += c - '0';
}
Задача №129. Сапер (acmp.ru)
Мальчику Васе очень нравится известная игра "Сапер" ("Minesweeper").
В "Сапер" играет один человек. Игра идет на клетчатом поле (далее будем называть его картой) NxM (N строк, M столбцов). В K клетках поля стоят мины, в остальных клетках записано либо число от 1 до 8 — количество мин в соседних клетках, либо ничего не написано, если в соседних клетках мин нет. Клетки являются соседними, если они имеют хотя бы одну общую точку, в одной клетке не может стоять более одной мины. Изначально все клетки поля закрыты. Игрок за один ход может открыть какую-нибудь клетку. Если в открытой им клетке оказывается мина — он проигрывает, иначе игроку показывается число, которое стоит в этой клетке, и игра продолжается. Цель игры — открыть все клетки, в которых нет мин.
У Васи на компьютере есть эта игра, но ему кажется, что все карты, которые в ней есть, некрасивые и неинтересные. Поэтому он решил нарисовать свои. Однако фантазия у него богатая, а времени мало, и он хочет успеть нарисовать как можно больше карт. Поэтому он просто выбирает N, M и K и расставляет мины на поле, после чего все остальные клетки могут быть однозначно определены. Однако на определение остальных клеток он не хочет тратить свое драгоценное время. Помогите ему!
По заданным N, M, K и координатам мин восстановите полную карту.
Входные данные
В первой строке входного файла INPUT.TXT содержатся числа N, M и K (1 ≤ N ≤ 200, 1 ≤ M ≤ 200, 0 ≤ K ≤ N×M). Далее идут K строк, в каждой из которых содержится по два числа, задающих координаты мин. Первое число в каждой строке задает номер строки клетки, где находится мина, второе число — номер столбца. Левая верхняя клетка поля имеет координаты (1,1), правая нижняя — координаты (N,M).
Выходные данные
Выходной файл OUTPUT.TXT должен содержать N строк по M символов — соответствующие строки карты. j-й символ i-й строки должен содержать символ ‘*‘ (звездочка) если в клетке (i,j) стоит мина, цифру от 1 до 8, если в этой клетке стоит соответствующее число, либо ‘.‘ (точка), если клетка (i,j) пустая.
Пример
| Ввод | Вывод |
| 10 9 23 1 8 2 3 3 2 3 3 4 3 5 7 6 7 7 1 7 2 7 3 7 4 7 5 7 6 7 7 7 8 8 1 8 3 8 5 8 7 9 3 9 5 9 6 9 7 | .111..1*1 13*2..111 1**3..... 13*2.111. .111.2*2. 233335*41 ********1 *6*7*8*41 13*4***2. .1122321. |
Решение
#include <iostream>
#define SIZE 200
using namespace std;
int main(){
int n, m, k, a[SIZE][SIZE] = {0,};
char c;
cin >> n >> m >> k;
while(k--){
cin >> i >> j;
a[--i][--j] = -1; // мина
}
for(int i = 0; i<n; i++){
for(int j = 0; j<m; j++) {
if(!a[i][j]){ // поиск мин в соседних клетках
for(int x = max(j-1, 0); x <= min(j+1, m-1); x++)
for(int y = max(i-1,0); y <= min(i+1, n-1); y++)
a[i][j] += (a[y][x]<0);
}
c= a[i][j] ? (a[i][j]<0 ? '*' : '0'+a[i][j]) : '.';
cout << c;
}
cout << endl;
}
}
В некоторых случаях требуется ввести символьную строку, в которой могут содержаться пробелы. Для этого используется функция gets
Задача №130. Наименьшая система счисления (acmp.ru)
(Время: 1 сек. Память: 16 Мб)
Известно, что основанием позиционной системы счисления называют количество различных символов, используемых для записи чисел в данной системе счисления. Также известно, что любое число x в b-ичной системе счисления имеет вид x=a0∙b0+a1∙b1+…+an∙bn, где b ≥ 2 и 0 ≤ ai < b.
Для записи чисел в b-ичной системе счисления, где b ≤ 36, могут быть использованы первые b символов из следующего списка 0,1,…, 9, A, B, …, Z. Например, для записи чисел в троичной системы используются символы 0, 1, 2, а в двенадцатеричной - 0,1,…, 9, A, B.
Требуется написать программу, которая по входной строке S определит, является ли данная строка записью числа в системе счисления, с основанием не большим 36, и, если является, определит минимальное основание этой системы счисления.
Входные данные
Входной файл INPUT.TXT содержит в единственной строке входную строку. Длина строки не превышает 255. Все символы строки имеют коды от 32 до 127.
Выходные данные
Выходной файл OUTPUT.TXT должен содержать одно число. Если строка является записью числа в некоторой системе счисления, то нужно вывести минимальное основание такой системы счисления. Иначе вывести -1.
Примеры
| № | INPUT.TXT | OUTPUT.TXT |
| 1 | 123 | 4 |
| 2 | ABCDEF | 16 |
| 3 | AD%AF | -1 |
Решение
#include <cstdio>
int main(){
freopen("input.txt","r",stdin);
freopen("output.txt","w",stdout);
char s[255];
int val, ans = 1;
gets(s); //считывание до перевода строки
for(int i = 0; s[i]; i++){
if (s[i]<'0' || s[i]>'Z' || ('9'<s[i] && s[i]<'A')){
printf("-1");
return 0;
}
val = (s[i] <= '9' ? s[i] - '0' : 10 + s[i] - 'A');
if(val > ans) ans = val;
}
printf("%d", ++ans);
}
Задача №131. Распознавание языка (acmp.ru)
Важным понятием теории формальных грамматик и автоматов является формальный язык. Неформально его можно определить как некоторое множество слов, где под словом понимается некоторая строка из символов.
В этой задаче необходимо проверить, принадлежит ли данное слово языку {0n1n2n, n ≥ 1}. В этот язык входят те и только те слова, которые имеют такую структуру: в них нулей столько же, сколько единиц, а единиц - столько же, сколько и двоек. При этом любой ноль находится ближе к началу слова, чем любая единица, а любая единица находится ближе к началу слова, чем любая двойка. Например, слово 001122 принадлежит этому языку, а слово 0000111122220 - не принадлежит.
Входные данные
Первая строка входного файла INPUT.TXT содержит целое положительное число n (n ≤ 10) – количество слов, которые надо проанализировать. Далее идут n строк, каждая из которых содержит по одному слову. Слова имеют длину не более тридцати тысяч символов и состоят только из нулей, единиц и двоек. Каждое из слов состоит хотя бы из одного символа.
Выходные данные
Выходной файл OUTPUT.TXT должен содержать ровно n строк. Для каждого слова из входного файла выведите по одной строке, содержащей слово YES, если оно принадлежит указанному выше языку, и NO - иначе.
Примеры
| № | INPUT.TXT | OUTPUT.TXT |
| 1 | 3 001122 00011122222 000111222 | YES NO YES |
| 2 | 2 0000111122220 012 | NO YES |
Решение<
|
из
5.00
|
Обсуждение в статье: Генерация случайных чисел |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы