 |
Главная |


cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
|
из
5.00
|
ЛАБОРАТОРНАЯ РАБОТА №1
Основы Apache Hadoop. Развертывание и тестирование.
Методические указания
Для первой лабораторной работы преподаватель не дает индивидуальное задание каждому студенту. Студент должен самостоятельно выбрать среду развертывания и установить необходимое программное обеспечение. После установки и загрузки необходимо запустить тестовый пример, выполнение которого подтверждает корректность развертывания платформы.
Пример выполнения задания
Установка Hadoop
1.Скачивание и установка VMware Workstation 12 Player for Windows 64 – bit operating systems.
(https://my.vmware.com/web/vmware/free#desktop_end_usercomputing/vmware_workstation_player/12_0)
2.Скачивание и установка HDP 2.3 on Hortonworks Sandbox for VMware
(http://hortonworks.com/products/hortonworks-sandbox/#install)
3.В установленном VMware Workstation 12 Player File>Open>* путь к HDP 2.3 on Hortonworks Sandbox for VMware* > Import.
4. Выбираем из списка > Play virtual machine

5. Вставляем полученный IP-адрес в браузер.
Готово! Также на сайте предлагается работа этого же sandbox через облако на BitRefinery (возможен бесплатный 14 - дневный период, но через верификацию по телефону) и Windows Azure (месяц бесплатно, тоже через заявку).

Установка Java.
Для корректной установки Hadoop нам необходимо установить несколько компонентов. Первый компонент – это java jdk.

Добавление нового пользователя и группы.
Затем добавляем новую группу и пользователя, назовем их hadoop (группа) и hduser (пользователь).

Установка SSH.
Второй необходимый компонент – это ssh.
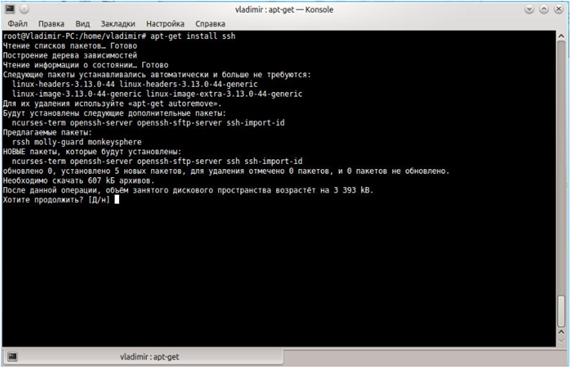
Hadoop требует установку ssh для доступа и управления его узлами, поэтому нам необходимо сконфигурировать ssh для доступа к localhost. Создадим public key authentication.

Установка Hadoop.
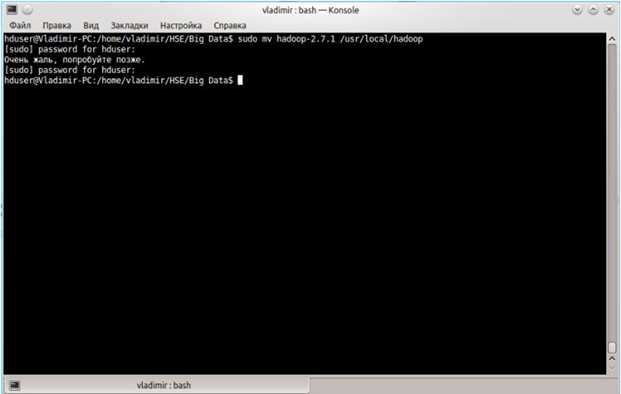
Качаем hadoop - 2.7.1.tar.gz с официально сайта и разархивируем его командой tar xvzf hadoop-2.7.1.tar.gz

Перенесем hadoop в /usr/local/hadoop.
Настройка конфигурационных файлов.
После этого добавляем следующие строчки в конец файл
~./bashrc (/home/hduser/.bashrc):
#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOP VARIABLES END

Затем, нам необходимо изменить файл /usr/local/hadoop/etc/hadoop/hadoop-env.sh добавив туда следующую строчку:
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64.
Данное действие обеспечивает доступность переменной JAVA_HOME, когда Hadoop запускается.

Файл /usr/local/hadoop/etc/hadoop/core-site.xml содержит конфигурационный настройки, которые Hadoop использует, когда запускается. Вставим следующие строчки в этот файл между тегами <configuration></configuration>. Данное действие определяет директорию для временных файлов.
Создадим папку для наших временных файлов.
hduser@laptop:~$ sudo mkdir-p /app/hadoop/tmp
hduser@laptop:~$ sudo chown hduser:hadoop /app/hadoop/tmp
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/tmp</va
lue>
<description>A base for other temporary directories.
</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:54310</value>
<description>The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.
</description>
</property>
</configuration>

По умолчанию /usr/local/hadoop/etc/hadoop/ содержит /usr/local/hadoop/etc/hadoop/mapred-site.xml.template, который должен быть переименован или скопирован с именем namemapred-site.xml.
cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
Этот файл используется для того, чтобы указать какой framework будет использовать MapReduce. Нам необходимо вставить следующий код между тегами <configuration></configuration>.
Данной конфигурацией мы задаем хост и порт, который будет запускать MapReduce job tracker.
JobTracker – это сервис внутри Hadoop, обеспечивающий выполнение задач MapReduce для конкретных узлов в кластере.
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:54311</value>
<description>The host and port that the MapReduce job tracker runs at. If "local", then jobs are run in
-process as a single map and reduce task.
</description>
</property>
</configuration>
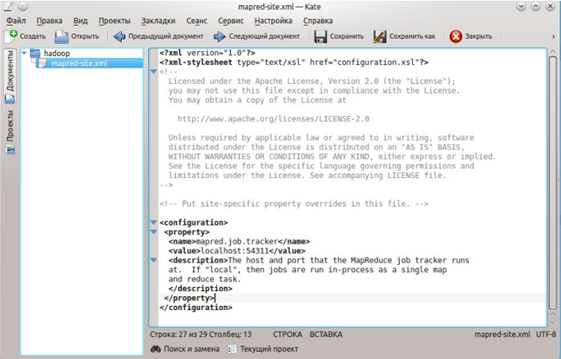
/usr/local/hadoop/etc/hadoop/hdfs-site.xml
данный файл необходимо сконфигурировать для каждого хоста, который будет использоваться в кластере. Нужно создать две директории, которые будут использоваться как namenode и datanode
на хосте. Это можно сделать следующими командами:
sudo mkdir –p /usr/local/hadoop_store/hdfs/namenode
sudo mkdir -p /usr/local/hadoop_store/hdfs/datanode
sudo chown -R hduser:hadoop /usr/local/hadoop_store
После этого открываем файл /usr/local/hadoop/etc/hadoop/hdfs-site.xml и добавляем между тегами <configuration></configuration>
следующие строчки. В них мы указываем расположение наших папок для namenode и datanode.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>Default block replication.
The actual number of replications can be specified when the
file is created. The default is used if replication is not
specified in create time.
</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop_store/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop_store/hdfs/datanode</value>
</property>
</configuration>

Форматирование HDFS.
Когда все конфигурационные файлы изменены, необходимо отформатировать HDFS, чтобы мы могли начать использовать ее. Команда должна быть запущена с возможностью записи в /usr/local/hadoop_store/hdfs/namenode директорию.

ВАЖНО! hadoop namenode -format должна быть запущена единожды, прежде чем мы начнем использовать Hadoop. Если эта команда запущена снова, после того как использовался Hadoop, она удалит все данные на HDFS.
Запуск Hadoop.
Сейчас запустим наш новый установленный single node
кластер. Для этого перейдем в папку /usr/local/hadoop/sbin и запустим скрипт start-all.sh

Мы можем проверить запустился ли hadoop. Для этого необходимо набрать команду jps.

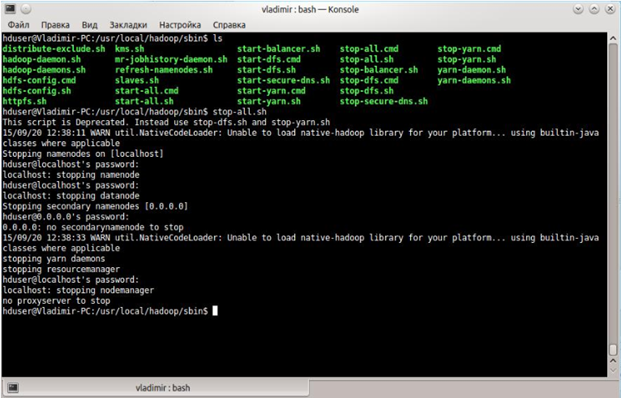
Остановка Hadoop.
Для остановки hadoop необходимо запустить скрипт stop-all.sh.
Hadoop Web интерфейс.
Запустим Hadoop снова и посмотрим на его Web интерфейс.

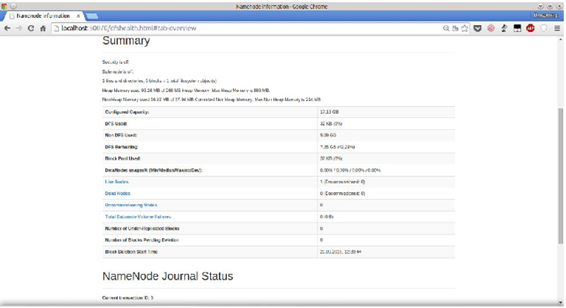

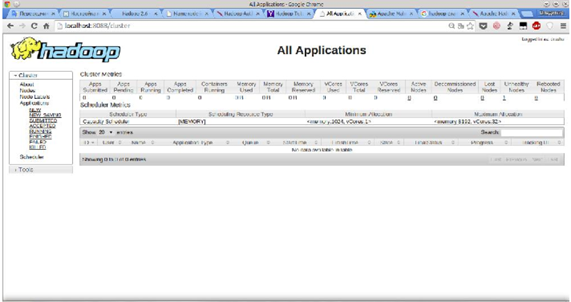
Проверка работы Hadoop.
Проверим работу Hadoop на программе, которая вычисляет число
Pi на основе выборки. Для этого запустим один из примеров и посмотрим,
как долго он будет вычислять значение Pi и какой будет результат.
Для запуска перейдем в папку
/usr/local/hadoop/share/hadoop/mapreduce
и выполним команду:
hadoop jar hadoop-mapreduce-examples-2.7.1.jar pi 1000 10

Контрольные вопросы
1.Основные компоненты Hadoop.
2.Архитектура HDFS.
3.Поддержка целостности данных в HDFS.
4.Назначение Hive
5.Экосистема Hadoop. Состав и назначение.
|
из
5.00
|
Обсуждение в статье: cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы