 |
Главная |


Динамический анализ. Принципы организации
|
из
5.00
|
Идея динамического анализа заключается в определении зависимостей по данным в программе на основании информации, собранной в результате ее выполнения на тестовых наборах начальных данных [6]. Схематически это выглядит так (Рисунок 5):
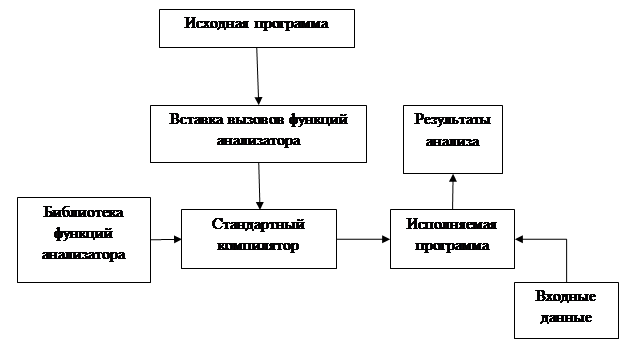
1. В исходный текст программы вставляются вызовы трассировочных функций, позволяющих анализатору получать информацию о ходе выполнения программы. Обычно трассировочные вызовы сопровождают обращения к переменным, входы и выходы циклов, изменения индексных переменных в циклах, вызовы функций и процедур
2. Полученная программа подается на вход стандартному компилятору
3. Исполняемый модуль запускается на различных наборах входных данных. По полученной трассировочной информации анализатор определяет зависимости по данным в исходной программе.
Динамический анализ дает полную картину зависимостей по данным, но только для текущего конкретного запуска программы. Поэтому очень важно, чтобы тестовый набор входных данных полностью охватывал все возможное поведение программы.
Рассмотрим организацию динамического анализа зависимостей по данным с использованием дерева контекстов [6].
Введем ряд определений:
Определение 1: Контекстное дерево CT(program) программы program – дерево с тремя типами вершин: процедура, цикл или доступ к памяти. Две вершины контекстного дерева связаны ребром, если они непосредственно вложены друг в друга или если одна из этих вершин вызывает другую. Корень контекстного дерева – процедура, с которой начинает свое выполнение программа. Сложные программные выражения делятся на ряд контекстных вершин, по одной на каждое обращение к памяти.
Определение 2: Контекстом CT(program) назовем путь от корня дерева контекстов до любой его вершины. Пусть S(a) – контекстная вершина обращения к переменной ‘a’. Тогда, контекст C(a) обращения к ‘a’ – это путь от корня дерева контекстов до вершины S(a). Контекст процедуры(цикла) – контекст, заканчивающийся соответствующей этой процедуре(циклу) вершиной. Процедурная секция – наибольший подпуть контекста C, содержащий единственную процедурную вершину, с которой он и начинается.
Определение 3: Цепочка векторов итерации IVC(a) доступа к памяти «a» - список векторов итераций, соответствующих всем процедурным секциям в контексте C(a) на момент доступа ‘a’. Если процедурная секция не содержит ни одного цикла, то вектор итераций будет пустым вектором.
Определение 4
Виртуальная точка доступа к памяти «a» - пара VP(a) = (C(a), IVC(a)).
Для определения прямых зависимостей по памяти в программе используется следующий алгоритм:
Для каждой ячейки памяти мы храним виртуальные точки последнего чтения и последней записи. Тогда, при каждом доступе к ячейке памяти на чтение ar производим следующие действия:
1. определяем ячейку памяти m, к которой происходит доступ ar;
2. получаем виртуальную точку VP(aw) последней записи aw в ячейку памяти m;
3. получаем по точкам доступа VP(aw) и VP(ar) значения цепочек векторов итераций IVC(aw) и IVC(ar);
4. определяем контекст CL, являющийся наибольшим общим подпутём контекстов C(aw) и C(ar) в дереве контекстов CT(p);
5. находим контекст Cm, являющийся наибольшим процедурным подконтекстом или подконтекстом цикла контекста CL, такой, что все его процедурные секции, кроме последней, имеют одинаковые значения векторов итераций в IVC(aw) и IVC(ar);
6. получаем по значениям цепочек IVC(aw) и IVC(ar) вектора итераций w и r последней процедурной секции контекста Cm; если размерность вектора r больше нуля, то определяем расстояние зависимости d: d = r – w, в противном случае полагаем d пустым вектором;
7. пусть вершина st1 следует сразу после подконтекста Cm в контексте C(aw), а вершина st2 следует сразу после подконтекста Cm в контексте C(ar), тогда добавим новую зависимость с расстоянием d между операторами st1 и st2.
Похожие алгоритмы можно применять для определения обратных зависимостей и зависимостей по записи. Для регистрации обратных зависимостей мы должны для всех операций записи анализировать предшествующие операции чтения. Для регистрации зависимостей по записи необходимо для каждой записи в ячейку памяти анализировать предыдущую запись в эту же ячейку.
|
из
5.00
|
Обсуждение в статье: Динамический анализ. Принципы организации |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы