 |
Главная |


Глава 3. использование некоторых лингвистических программ в исследовании русскоязычных и англоязычных искусствоведческих текстов
|
из
5.00
|
В данной главе мы попытаемся оценить возможности некоторых программ применительно к исследованию русскоязычных и англоязычных искусствоведческих текстов.
Рассмотримпрограммы анализа и лингвистической обработки текстов TextAnalyst 2.0 и Худломер исистемы обработки естественного языка и машинного перевода Translate . Ru и Google Переводчик .
Сначала обратимся к программе TextAnalyst 2.0 (для использования необходимо скачивание) [11] Это смысловой анализатор, который за считанные минуты позволяет ознакомиться с текстами любой тематики. Программа разработана в качестве инструмента для анализа содержания текстов, смыслового поиска информации, формирования электронных архивов и предоставляет пользователю следующие основные возможности:
· анализ содержания текста с автоматическим формированием семантической сети с гиперссылками;
· получение смыслового портрета текста в терминах основных понятий и их смысловых связей;
· анализ содержания текста с автоматическим формированием тематического древа с гиперссылками;
· выявление семантической структуры текста в виде иерархии тем и подтем;
· смысловой поиск с учетом скрытых смысловых связей слов запроса со словами текста;
· автоматическое реферирование текста;
· автоматическая индексация текста с преобразованием в гипертекст;
· ранжирование всех видов информации о семантике текста по «степени значимости» с возможностью варьирования детальности ее исследования.
При исследовании искусствоведческих текстов многие из этих возможностей могут быть полезными. Для начала работы запускаем программу и выбираем текстовый файл для анализа. В нашем случае это будет файл "Поэзия земли.txt", содержащий статью о русском художнике Владимире Копылове. Теперь главное окно TextAnalyst должно выглядеть примерно так:

Рисунок 1 – Интерфейс программы TextAnalyst
Вся работа по анализу текста уже сделана, остается лишь ознакомиться с ее результатами. Прежде всего, изучив предложенный материал, TextAnalyst формирует сеть основных (наиболее значимых) понятий, содержащихся в представленных ему текстах (верхнее левое окно на Рис. 1). В нашем случае в сеть понятий входят: "Копылов", "Владимир", "пейзажист", "натюрмортах", "творчества", "вода", "главным", "живописца", "рисунок", "художественный" и др.
Такая сеть служит представлением смысла текста и основой для всех видов дальнейшего анализа. Сеть понятий – это множество терминов из текстов – слов и словосочетаний, связанных между собой по смыслу. В сеть включены не все термины текста, а лишь наиболее значимые, несущие основную смысловую нагрузку. Аналогичным образом представлены и смысловые связи между понятиями текстов – отражаются лишь наиболее явно выраженные из них. Поэтому, с одной стороны сеть достаточно полно описывает смысл текстов, а с другой – позволяет отбросить несущественную информацию и представить содержание в сжатом виде, так называемом “смысловом портрете”.
Таким образом, можно сразу увидеть всю информацию по каждому понятию, буквально бросив единственный взгляд на набор его связей в сети. В результате, передвигаясь по смысловым связям от понятия к понятию, можно находить и прицельно исследовать лишь интересующие места текстов, не затрудняя себя просмотром всей попавшейся на пути информации.
Теперь обратим внимание на числа, стоящие в дереве возле понятий. Ближайшее к понятию число представляет его смысловой вес (например, "Копылов" – 100, "Владимир" – 99, "творчества" – 98). Его значение (от 1 до 100) показывает, сколь важную роль играет понятие для смысла всего текста – как много информации в тексте касается данного понятия. Максимальное значение, равное 100, говорит о том, что понятие является ключевым и представляет важнейшую тему текста. Маленькое, близкое к единице значение показывает, что соответствующая тема лишь вскользь упомянута в тексте и в нем очень мало информации, относящейся к данному понятию. Второе число, стоящее перед смысловым весом, ближе к раскрытому узлу, представляет вес связи от понятия в вершине раскрытого списка к данному. Вес связей также всегда принимает значение от 1 до 100.
Кроме того, программа предоставляет услугу автоматического реферирования (в меню "Анализ" выбираем пункт "Реферирование"). Формируемый реферат содержит список наиболее информативных предложений текстов (тезисов) (Рисунок 2, правое верхнее окно). Конечно, это еще не полноценный реферат, так как тезисы в основном не связаны между собой стилистически, а просто выбраны из текста и расположены в порядке их встречаемости. Однако и такой подстрочник реферата оказывается достаточно информативным, чтобы составить общее представление о тексте и уяснить его основные мысли. Более того, все предложения реферата снабжены отсылками к соответствующим местам исходных текстов, что позволяет просмотреть контекст интересующего тезиса. Подробность реферата можно легко настраивать, изменяя количество формирующих его предложений. При этом каждое предложение реферата характеризуется относительной степенью значимости во всем тексте.

Рисунок 2 – Реферирование
Таким образом, данная программа может быть достаточно полезной в исследовании автора, поскольку позволяет быстро получить смысловой портрет текста, что необходимо в процессе работы с большим количеством разнообразных текстов, когда нелегко удержать в памяти содержание каждого из них. TextAnalyst удобно использовать и при поиске текстов для исследования: не обязательно тратить время на чтение полного текста, с помощью реферирования можно быстро соориентироваться, о чем идет речь (о каких художниках, картинах, направлениях в живописи и т.д.), и сделать вывод о том, подходит ли данный текст для исследования. Однако серьезным недостатком программы применительно к нашему исследованию, связанному с англоязычными текстами, является отсутствие возможности обрабатывать такие тексты.
Теперь рассмотрим автоматический on-line классификатор функционального стиля текста Худломер [13]. Данная программа определяет стиль текста: разговорный стиль, стиль художественной литературы, газетно-информационный стиль, научно-деловой стиль. На Рисунке 3 представлен интерфейс Худломера:

Рисунок 3 – Интерфейс Худломера
В поле под надписью "Введите текст (не менее 75 слов)" вставляем исследуемый текст (в нашем случае, например, статью о русском живописце Ю. Маланенкове "Волшебное зеркало"). Затем нажимаем "SUBMIT" и получаем результат (Рисунок 4):

Рисунок 4 – Ответ Худломера
Итак, видим, что Худломер считает данный текст газетной статьей, то есть относит ее к газетно-информационному стилю. С таким определением вполне можно согласиться, если учесть, что статья была взята из искусствоведческого журнала "Художественный совет" и поэтому является примером публицистики. К тому же, на рисунке видно, что красная полоска под названиями стилей едва пересекает границу между "худло" (стиля художественной литературы) и "газетной статьей", а публицистика как раз и занимает это промежуточное положение.
В нашем случае Худломер определил стиль достаточно точно, однако, как отмечают сами создатели программы, он может давать погрешности, особенно при малых объемах текстов.
Мы также провели подобный эксперимент со статьей на английском языке, взятой из англоязычного искусствоведческого журнала "Art in America", в результате которого Худломер отнес ее к разговорной речи, что, очевидно, не является верным. Возможно, это и есть пример ошибочной работы программы, а возможно, Худломер не анализирует тексты на английском языке, о чем, кстати, в описании программы не упоминается.
Стоит отметить, что построен автоматический классификатор функционального стиля текста на основе спектров длин слов, характерных для каждого из четырех стилей (то есть предполагается, что самые короткие слова встречаются в текстах разговорного стиля, а самые длинные – в научных статьях).
Теперь обратимся к переводчикам Translate.Ru [1] и Google Переводчик [14]. В нашем исследовании, непосредственно связанном с англоязычными текстами, без перевода не обойтись. Более того, перевод обязательно должен быть точным и высококачественным, ведь статьи на английском языке с параллельным русским переводом помещаются в Приложение к магистерской диссертации. Это выглядит примерно так, как представлено ниже (Рис. 5):
| Текст на английском языке | Параллельный русский перевод |
| No wonder Doig has exerted such an influence on recent painting. He has been able to paint ordinary, nearly kitsch subjects (boats, water, weather, people copied from photos) in disarmingly alluring ways that somehow, almost by the by, tend to accede to modernist pictorial criteria of flatness and materiality and avoidance of the anecdotal. These criteria remain in force despite the waning of modernism as an ideology. At the same time, he conveys a contemporary rather than a historicist sensibility, and a yearning for the unfamiliar rather than the known. Doig's work of the last few years, however, registers a shift – the import of which remains hard to define since it may still be in progress – away from the quietly delirious, mutedly overelaborated manner of painting that served him so well throughout the '90s. One might say he's beginning to evade his own influence. It's hard not to see the change as connected with his move back to Trinidad in 2002. | Не удивительно, что Дойг оказал такое сильное влияние на современную живопись. Он смог нарисовать красками простые, почти китчевые предметы (лодки, воду, погоду, людей, скопированных с фотографий) в такой обезоруживающе-притягательной манере, которая как-то почти между прочим тяготеет к тому, чтобы соответствовать модернистским критериям живописи – плоскостность и материальность, и нелюбовь к сюжетности. Эти принципы остаются в силе, несмотря на спад модернизма как идеологии. В то же время он передает современную, а не основанную на историзме восприимчивость и выражает стремление к незнакомому, а не к известному. Однако, творчество Дойга в последние годы отмечается сдвигом (значение которого трудно определить, поскольку он может все еще длиться) – уходом от тихо-сумасшедшей, приглушенно перегруженной деталями (слишком сложной) манеры рисования, которая так хорошо служила ему в 90-е годы. Можно было бы сказать, что он начинает избегать своего собственного влияния. Трудно не связывать эту перемену с его возвращением в Тринидад в 2002-ом году. |
Рисунок 5 – Пример самостоятельного перевода для магистерской работы
Данный перевод выполнен автором самостоятельно. А теперь посмотрим, какие варианты перевода этого фрагмента текста предлагают Translate . Ru и Google Переводчик :
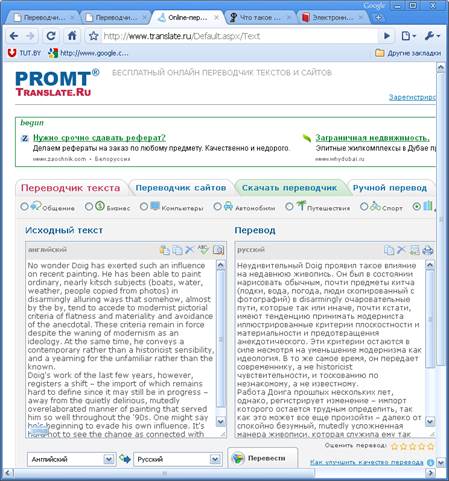
Рисунок 6 – Перевод Translate.Ru

Рисунок 7 – Перевод Google Переводчика
Итак, трудно не заметить, что предложенные варианты перевода очень "шероховатые", во многих местах стилистически и грамматически неточные, уже не говоря о том, что некоторые слова и словосочетания и вовсе остались без перевода ("mutedly overelaborated", "historicist"). Такой перевод несомненно требует доработки, и немалой. На наш взгляд, рассмотренные программы-переводчики скорее будут полезны тому, кто почти не владеет иностранным языком, но хочет понять основную идею текста, ведь они действительно передают общий смысл при переводе. Профессиональному же лингвисту, который хорошо знает язык, общий смысл понятен и так. Ему нужен точный перевод с учетом всех тонкостей и оттенков значений. В это плане на помощь приходит один из самых известных электронных словарей ABBYY Lingvo (Рисунок 7) с большим количеством встроенных словарей различной тематики, толкованиями, примерами, устойчивыми выражениями и т.д.

Рисунок 8 – ABBYY Lingvo 12
Итак, все описанные выше лингвистические программы действительно могут быть полезны при исследовании англоязычных и русскоязычных искусствоведческих текстов. Однако не стоит всецело полагаться на данные, полученные с помощью таких программ. Лучше еще раз проверить и проанализировать их самостоятельно.
заключение
Данный реферат представляет собой самостоятельное исследование возможностей и эффективности применения ИТ в лингвистике в целом и при изучении англоязычных и русскоязычных искусствоведческих текстов в частности.
Обзор литературных источников, посвященных взаимодействию и взаимосвязи ИТ и лингвистики, показал, что их авторы в основном освещают следующие вопросы: ИТ в обработке текстов; автоматическое чтение текста; системы понимания устной речи; системы автоматического реферирования и аннотирования текстов; машинный перевод текстов; системы порождения текстов; автоматизированные информационно-поисковые системы; разработка различных баз данных для гуманитарных наук; разработка различного типа автоматических словарей; создание систем обучения языку.
Все эти направления, находящиеся на пересечении сфер лингвистики и ИТ, реализованы на практике в виде конкретных лингвистических программ и ресурсов сети Интернет, которые можно разделить на 9 групп, рассмотренных выше. Каждая из этих групп, как мы убедились, представлена, в свою очередь, большим разнообразием программ (ресурсов), многие из которых мы кратко охарактеризовали, назвав их основные преимущества. Большинство программ действительно эффективны, а иногда и вовсе необходимы при проведении лингвистических исследований.
Мы также на практике ознакомились с программами TextAnalyst 2.0, Худломер, Translate.Ru и Google Переводчик и оценили их возможности применительно к исследованию русскоязычных и англоязычных искусствоведческих текстов. Выяснилось, что TextAnalyst 2.0 помогает анализировать содержание текста, автоматически формирует семантическую сеть с гиперссылками, создает "смысловой портрет" текста в терминах основных понятий и их смысловых связей, осуществляет реферирование текста. Худломер автоматически определяет стиль текста, однако не всегда делает это правильно. Translate.Ru и Google Переводчик переводят англоязычные искусствоведческие тексты недостаточно точно и корректно – полученный перевод подлежит обязательному редактированию.
ИТ в наше время развиваются очень быстрыми темпами. В перспективе, возможно, появятся технологии, которые будут настолько точно обрабатывать языковой материал, что лингвисту не придется сомневаться в полученных результатах.
список литературы к реферату
1. Бесплатный онлайн переводчик текстов и сайтов PROMT Translate.Ru [Электронный ресурс]. – 2003-2009. Режим доступа: http://www.translate.ru/. – Дата доступа: 15.12.2010.
2. Вигурский К.В., Пильщиков И.А. Филология и современные информационные технологии (К постановке проблемы) // Научно-технический центр "Информрегистр" [Электронный ресурс]. – 2007-2009. – Режим доступа: http://feb.inforeg.ru/vigursky-03.html. – Дата доступа: 02.12.2010.
3. Всеволодова А.В. Компьютерная обработка лингвистических данных: учеб. пособие / А.В. Всеволодова. – 2-е изд., испр. – М.: Наука: Флинта, 2007. – 96 с.
4. Зубов А.В. Информационные технологии в лингвистике: Учеб. пособие для студ. лингв. фак-тов высш. учеб. заведений / А.В. Зубов, И.И. Зубова. – М.: Академия, 2004. – 208 с.
5. Зубов А.В., Зубова И.И. Основы искусственного интеллекта для лингвистов: Учеб. пособие. – М.: Университетская книга; Логос, 2007. – 320 с.
6. Информационные системы и применение компьютерной техники в профессиональной деятельности. Основные понятия // Электронный учебник по предмету ИТ [Электронный ресурс]. – 2009. – Режим доступа: http://it-uchebnik.ru/it/glava1/1.html. – Дата доступа: 01.12.2010.
7. Компьютерная лингвистика // Онлайн Энциклопедия "Кругосвет" [Электронный ресурс]. – 2001-2009. Режим доступа: http://www.krugosvet.ru/enc/gumanitarnye_nauki/lingvistika/KOMPYUTERNAYA_LINGVISTIKA.html. – Дата доступа: 04.12.2010.
8. Леонтьева Н.Н. Автоматическое понимание текстов: системы, модели, ресурсы: учеб пособие для студ. лингв. фак. вузов / Н.Н. Леонтьева. – М.: Академия, 2006. – 304 с.
9. Логичев С.В. Каталог лингвистических программ и ресурсов в Сети / С.В. Логичев // Русская виртуальная библиотека [Электронный ресурс]. – 1999-2009. Режим доступа: http://www.rvb.ru/soft/catalogue/index.html. – Дата доступа: 25.11.2010
10. Мечковская Н.Б. История языка и история коммуникации: от клинописи до Интернета: курс лекций по общему языкознанию / Н.Б. Мечковская. – М.: Флинта: Наука, 2009. – 584 с.
11. Персональная система автоматического анализа текстов TextAnalyst 2.0 // Microsystems, Ltd [Электронный ресурс]. – 2009. Режим доступа: http://www.analyst.ru/index.php?lang=eng&dir=content/downloads/. – Дата доступа: 05.12.2010.
12. Потапова Р.К. Новые информационные технологии и лингвистика: Учебное пособие. – Изд. 4-е, стереотипное. – М.: КомКнига, 2005. – 368 с.
13. Худломер (автоматический определитель стиля текста) // Тенета (Конкурс русской сетевой литературы) [Электронный ресурс]. – 1996-2003. Режим доступа: http://www.teneta.ru/hudlomer/. – Дата доступа: 10.12.2010.
14. Google Переводчик // Google [Электронный ресурс]. – 2010. – Режим доступа: http://translate.google.com.by/?hl=ru&tab=wT#. – Дата доступа: 04.12.2010.
|
из
5.00
|
Обсуждение в статье: Глава 3. использование некоторых лингвистических программ в исследовании русскоязычных и англоязычных искусствоведческих текстов |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы