 |
Главная |


МОДЕЛИРОВАНИЕ ПРОЦЕССА ЛЕКСИЧЕСКОГО АНАЛИЗАТОРА.
|
из
5.00
|
Спроектировать лексический анализатор языка программирования Java. Сам программный продукт должен быть выполнен на языке программирования C#. Должны проверяться следующие лексемы:
· Числовые константы.
· Типы данных:
1) Целочисленные.
2) Вещественные.
· Массивы и элементы массивов.
· Арифметические операторы.
· Операции сравнения.
· Описание данных.
· Операторы условного и безусловного перехода.
· Метки.
Составим классы лексем Java (таблица 3).
Таблица 3 – Классы лексем
| Тип | Обозначение |
| Константы целочисленные | С |
| Константы с плавающей точкой | Z |
| Тип данных | T |
| Идентификаторы | I |
| Арифметические операторы | A |
| Операторы | S |
| Разделитель | R |
| Ключевые слова | K |
В языке программирования Java числовые константы представляются в виде:
Таблица 4 – Числовые константы в языке программирования Java.
| Десятичные | Последовательность цифр (0 — 9), которая начинаются с цифры, отличной от нуля. Пример: 1, -29, 385. Исключение — число 0. | C1 |
Таблица 5 – Числовые константы с плавающей точкой в языке Java
| Знак | Порядок | Мантисса | Сдвиг | |
| 32 bit Float | 1 бит [31] | 8 бит [30-23] | 23+1 бит [22-0] | -127 |
| 64 bit double | 1 бит [63] | 11 бит [62-52] | 52+1 бит [51-0] | -1023 |
Лексический анализатор должен определять все числовые константы. Он должен отличать константы от чисел в имени переменной.
Целочисленные типы данных в Java (таблица 6):
Таблица 6 – Целочисленные типы данных в Java.
| Имя | Токен |
| Byte | 1 |
| Short | 2 |
| Int | 3 |
| Long | 4 |
Типы данных с плавающей точкой в Java (таблица 7).
Таблица 7 – Типы данных с плавающей точкой.
| Имя | Токен |
| Double | 5 |
| Float | 6 |
Таблица 8 – Ссылочный тип данных
| Имя | Токен |
| Scanner | 7 |
Имеют вид:
1)Имя Список переменных;
2)Имя переменная = числовая константа;
В языке программирования Java массивы представлены в виде:
Тип_данных переменная [размер массива] = [константа] ….
Тип_данных переменная [размер массива] [размер массива] = [константа][константа] [константа][константа] [константа][константа]….
Лексический анализатор должен определять типы переменных и типы массивов. Определять является ли переменная массивом и считывает каждый элемент массива.
Арифметические операции в Java (таблица 9):
Таблица 9 – Арифметические операции в Java.
| Cимвол | Токен | Неформальное описание |
| + | 1 | Сложение |
| - | 2 | Вычитание |
| * | 3 | Умножение |
| / | 4 | Деление |
| % | 5 | Деление с остатком |
Операторы условного и безусловного перехода в Java имеют вид:
break
for(int i = 0; i < 100; i++) {
if(i == 5) break; // выходим из цикла, если i равно 5
mInfoTextView.append("i: " + i + "\n");
}
mInfoTextView.append("Цикл завершён");
Continue
for (int i = 0; i < 10; i++) {
mInfoTextView.append(i + " ");
if (i % 2 == 0)
continue;
mInfoTextView.append("\n");
}
return
Оператор return используют для выполнения явного выхода из метода. Оператор можно использовать в любом месте метода для возврата управления тому объекту, который вызвал данный метод. Таким образом, return прекращает выполнение метода, в котором он находится.
Таблица 10 – Операторы
| Имя | Токен | Неформальное описание |
| > | 1 | Больше чем |
| < | 2 | Меньше чем |
| <= | 3 | Меньше или равно |
| >= | 4 | Больше или равно |
| == | 5 | Равно |
| = | 0 | Присвоить |
| println | 6 | Ввод |
| out | 7 | Ввывод |
| break | 8 | Безусловные |
| Continue | 9 | |
| return | 10 | |
| Goto | 11 | |
| if | 12 | Условные |
| else | 13 |
Таблица 11 – Разделители
| Разделитель | Код |
| пробел | 1 |
| , | 2 |
| ; | 3 |
| ( | 4 |
| ) | 5 |
| . | 6 |
| { | 7 |
| } | 8 |
| “ | 9 |
| ” | 10 |
| конец строки | 11 |
Таблица 12 – Ключевые (служебные) слова
| Имя | Токен |
| public | 1 |
| main | 2 |
| class | 3 |
| new | 4 |
| System | 5 |
| nextDouble | 6 |
| String | 7 |
| import | 8 |
| java | 9 |
| util | 10 |
При лексическом разборе входной цепочки пробелы не кодируются как разделители и в выходную цепочку не попадают. Это связано с тем, что в исходном тексте программы пробелы служат только для структурирования текста программы и не несут дополнительной смысловой нагрузки.
Рассмотрим работу сканера на примере исходной программы, представленной ниже:
import java.util.Scanner;
public class main {
public static void main(String[] args) {
int a = 10;
Scanner in = new Scanner(System.in);
double b = in.nextDouble();
String text = "Больше";
String text1 = "Меньше";
if ( a > b ) {
System.out.println(text);
}
if( a < b) {
System.out.println(text1);
}
if (a == b){
System.out.println("=");
} } }
Спроектируем лексический анализатор. Для этого построим блок-схемы будущего приложения (блок-схемы 1 - 3). В таблицах приведены токены, которые будет видеть выдавать лексический анализатор.
Каждая обработанная лексема преобразуется к виду:
<буква><код>
где: <буква> – это признак класса лексемы
<код> – номер лексемы в соответствующей таблице.
на выходе сканера будет сформирована следующая последовательность
кодов лексем:
Для данной исходной программы лексический анализатор сформирует следующую выходную последовательность лексем (таблица 13):
Таблица 13 - Выходную последовательность лексем
| Входная последовательность текста исходной программы | Выходная последовательность лексем во внутреннем представлении |
| //программа сравнения чисел | |
| import java.util.Scanner; | K8 K9 R6 K10 R6 T7 R3 |
| public class main { | K1 K2 K3 R7 |
| int a = 10; | T3 I S0 W1 R3 |
| Scanner in = new Scanner(System.in); | T7 I S0 K4 T7 K5 R6 I R3 |
| double b = in.nextDouble(); | T5 I S0 I R6 K6 R4 R5 R3 |
| String text = "Больше"; | K7 I S0 R9 I R10 R3 |
| String text1 = "Меньше"; | K7 I S0 R9 I R10 R3 |
| if ( a > b ) { | S12 R4 I S1 I R5 R7 |
| System.out.println(text); | K5 R6 K8 R6 S6 R4 I R5 R3 |
| } | R8 |
| if( a < b) { | S12 R4 I S2 I R5 R7 |
| System.out.println(text1); | K5 R6 K8 R6 S6 R4 I R5 R3 |
| } | R8 |
| if (a == b){ | S12 R4 I S5 I R5 R7 |
| System.out.println("="); | K5 R6 S7 R6 S6 R4 R9 I R10 R5 R3 |
| } } } | R8 R8 R8 |
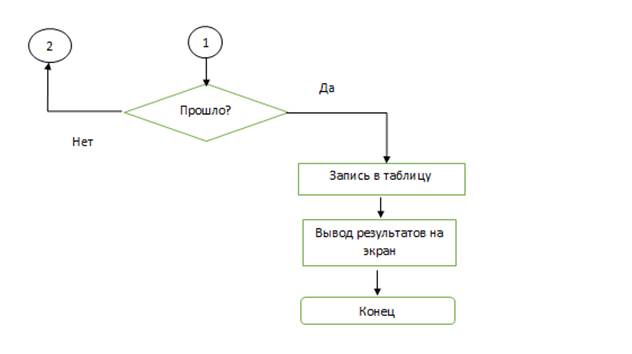
Разработаем блок-схемы для лексического анализатора (блок-схема 1, 2, 3). После составления всех таблиц с лексемами вы видим, что в нашем лексическом анализаторе буду отдельно проверяться типы данных, операции, Константы, операторы. На основе этих данных мы должны разобрать, как же будут у нас заполняться таблицы. Блок-схемы выглядят следующим образом
Блок-схема 1 - Схема работы лексического анализатора.
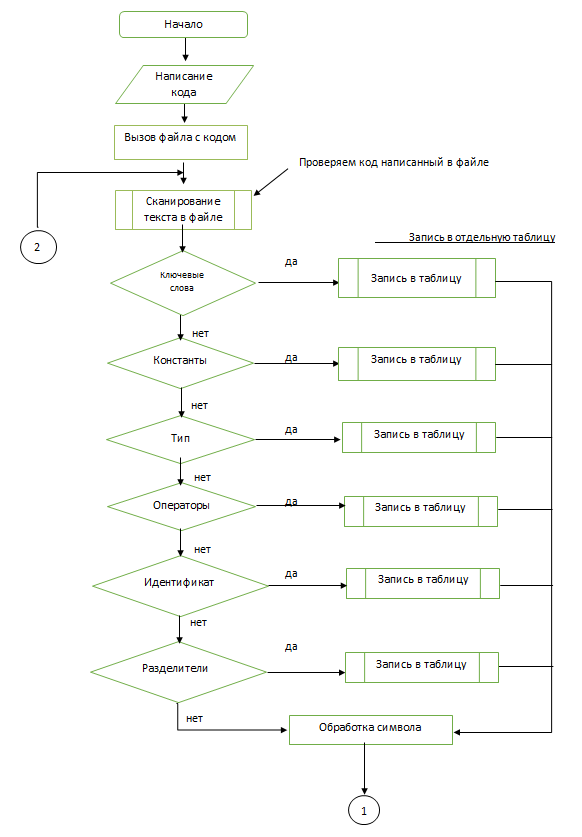
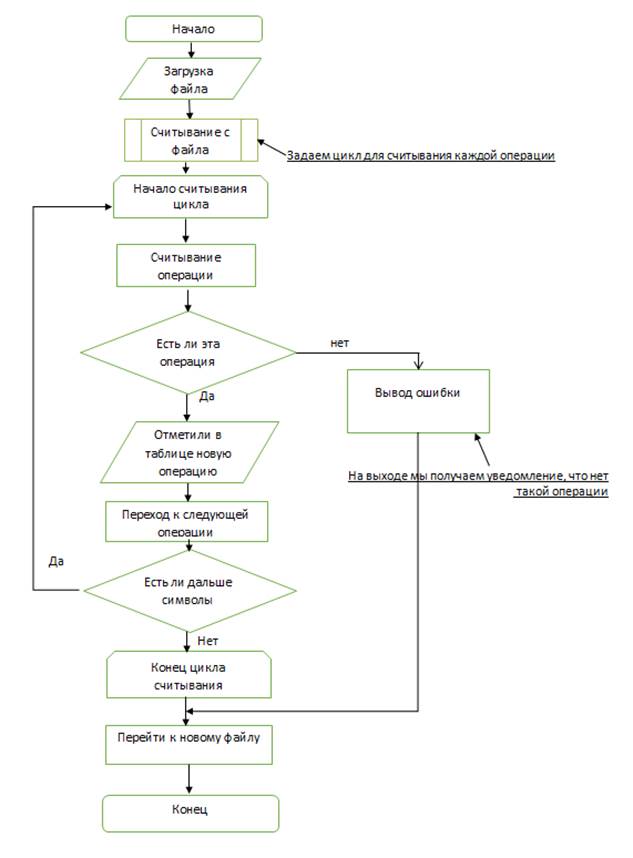
Блок-схема 2 - Сканирование документа (операции).
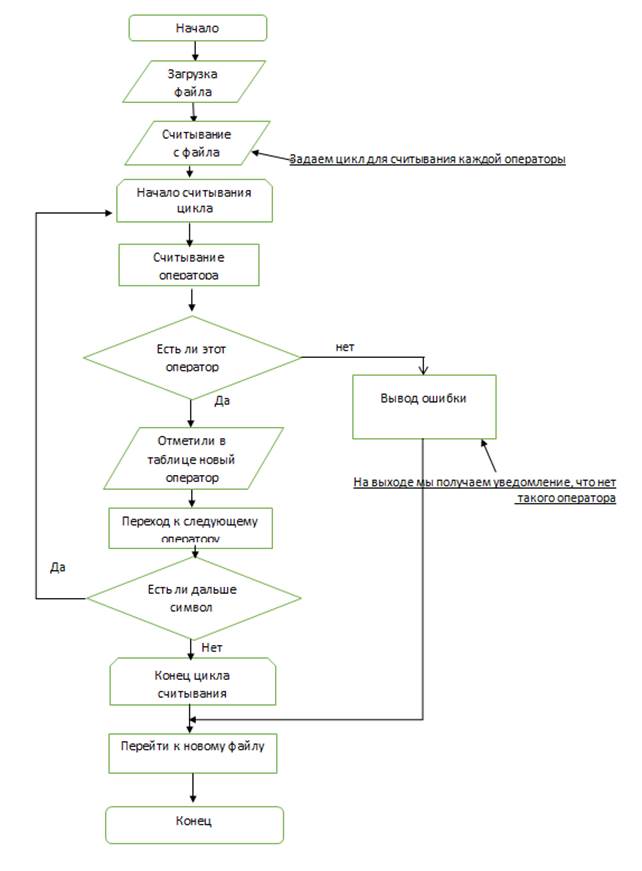
Блок-схема 3 - Сканирование документа (операторы).
После того как мы составили блок-схемы и выяснили как у нас будет работать лексический анализатор перейдем в главу 3, где будет рассматриваться программное средство с помощью, которого будет написан лексический анализатор.
3.ПРОЕКТИРОВАНИЕ ЛЕКСИЧЕСКОГО АНАЛИЗАТОРА.
C# (произносится “си шарп”) — объектно-ориентированный язык программирования. Разработан в 1998—2001 годах группой инженеров компании Microsoft под руководством Андерса Хейлсберга и Скотта Вильтаумота как язык разработки приложений для платформы Microsoft .NET Framework.
На языке программирования С# написана входная программа, которую будет анализировать лексический анализатор. В файл формата “txt” мы запишем небольшую программу, которая будет сравнивать числа (рисунок - 2). В данном коде создается класс. Далее создаем метод, котором реализуем основную функцию нашей программы. В методе идет ввод первого числа, затем второго. Так как два числа получены, запустим блоки if…else для сравнения. В первый блок вписали условие, что если первое число больше второго, то выведется в консоль слово “больше”. Аналогично также сделали с следующими блоками: “равно”, “меньше”.
Далее спроектируем лексический анализатор на языке программирования Java. Java — строго типизированный объектно-ориентированный язык программирования, разработанный компанией Sun Microsystems (в последующем приобретённой компанией Oracle). Разработка ведётся сообществом, организованным через Java Community Process, язык и основные реализующие его технологии распространяются по лицензии GPL. Права на торговую марку принадлежат корпорации Oracle.
Приложения Java обычно транслируются в специальный байт-код, поэтому они могут работать на любой компьютерной архитектуре с помощью виртуальной Java-машины. Дата официального выпуска — 23 мая 1995 года. На 2019 год Java — один из самых популярных языков программирования.
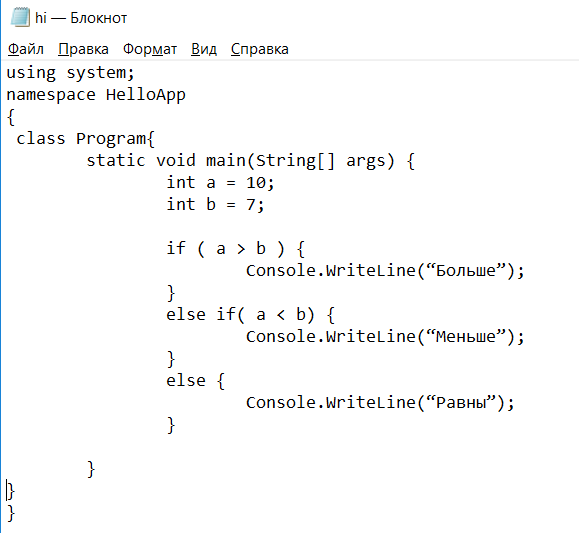
Рисунок - 2 – Входная программа на языке C#.
Создадим класс, класс в котором будет реализовано меню. Меню будет состоять из пунктов:
1) Вывести программный код.
2) Вывести лексемы программного кода.
3) Закрыть приложение.
С помощью конструкции switch, case создадим меню, а также добавим вводимую переменную, которая будет отвечать за выбор меню (рисунок - 3). В первый пункт меню добавим метод созданный метод чтения. Этот метод переносит из указанного файла все содержимое построчно в формате String в консоль (на экран). В методе чтения мы копируем каждый символ строки файла в массив, который выводится на экран. При достижении конца файла, строка становится равна null и прекращается чтение файла.

Рисунок - 3 – Фрагмент программного кода, с реализацией лексического анализатора.
В третьем пункте меню мы говорим Java завершить выполнение приложения. Также был добавлен пункт default. Данный пункт выполнится, если пользователь выберет пункт меню неправильно, тогда на экране выведется сообщение об ошибке.
Во второй пункт меню “Вывести лексемы программного кода” добавим экземпляр класса LA. При выборе второго пункта меню выполнится класс LA. В классе LA мы реализуем работу нашего лексического анализатора. В данном классе мы будем использовать базу данных. В эту базу мы поместим наши лексемы. PostgreSQL является одной из наиболее популярных систем управления базами данных. Сам проект postgresql эволюционировал из другого проекта, который назывался Ingres. Формально развитие postgresql началось еще в 1986 году. Тогда он назывался POSTGRES. А в 1996 году проект был переименован в PostgreSQL, что отражало больший акцент на SQL. И собственно 8 июля 1996 года состоялся первый релиз продукта.
PostgreSQL — свободная объектно-реляционная система управления базами данных (СУБД). Существует в реализациях для множества UNIX-подобных платформ, включая AIX, различные BSD-системы, HP-UX, IRIX, Linux, macOS, Solaris/OpenSolaris, Tru64, QNX, а также для Microsoft Windows.
Функции являются блоками кода, исполняемыми на сервере, а не на клиенте БД. Хотя они могут писаться на чистом SQL, реализация дополнительной логики, например, условных переходов и циклов, выходит за рамки SQL и требует использования некоторых языковых расширений. Функции могут писаться с использованием одного из следующих языков:
Встроенный процедурный язык PL/pgSQL, во многом аналогичный языку PL/SQL, используемому в СУБД Oracle;
Скриптовые языки — PL/Lua, PL/LOLCODE, PL/Perl, PL/PHP, PL/Python, PL/Ruby, PL/sh, PL/Tcl, PL/Scheme, PL/v8 (Javascript);
Классические языки — C, C++, Java (через модуль PL/Java);
Статистический язык R (через модуль PL/R).
PostgreSQL допускает использование функций, возвращающих набор записей, который далее можно использовать так же, как и результат выполнения обычного запроса.
Функции могут выполняться как с правами их создателя, так и с правами текущего пользователя.
Иногда функции отождествляются с хранимыми процедурами, однако между этими понятиями есть различие. С девятой версии возможно написание автономных блоков, которые позволяют выполнять код на процедурных языках без написания функций, непосредственно в клиенте.
Для упрощения администрирования на сервере postgresql в базовый комплект установки входит такой инструмент как pgAdmin. Он представляет графический клиент для работы с сервером, через который мы в удобном виде можем создавать, удалять, изменять базы данных и управлять ими. В системе Linux устанавливается отдельно, но в операционные системы Windows идет в пакете установки PostgreSQL.
Рисунок 4.1 – pgAdmin в системе Linux
После открытия программы у нас открывается следующая страница программы.
 Рисунок 4.2 – pgAdmin
Рисунок 4.2 – pgAdmin
Дальше нам нужно самостоятельно создать сервер, на котором мы будем разрабатывать нашу базу данных (рисунок 4.3).
 Рисунок 4.3 – Сервер AgAdmin4
Рисунок 4.3 – Сервер AgAdmin4
Тут мы можем увидеть название сервера MyLocalServev, название нашей базы данных Encryption и уже внутри базы данных мы создаем наши таблицы с токенами.
Рисунок 4.4 – Таблицы базы данных
Всего у нас 5 таблиц, которые взаимосвязаны между собой по ID и одно представление, где будет взаимодействовать файл и наши таблицы.
И из этой базы наше приложение будет брать лексемы в соответствии с программным кодом. Для этого установим соединение с нашей базой (рисунок - 5).
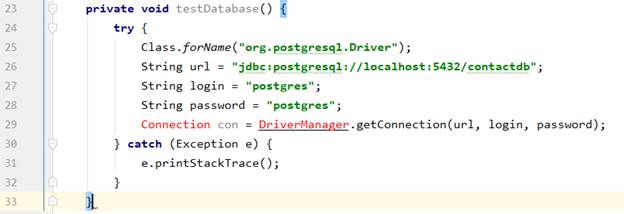
Рисунок - 5 – Соединение с базой данных.
К данному фрагменту кода мы будем добавлять объекты, которые будут передавать к нам из базы лексемы, соответствуя принимаемому коду.
Теперь в конструкторе класса LA напишем код, который будет выполнять нужный нам функционал. Создали параметр, в котором будут ключевые слова. В конструкторе установим соединение с файлом программы на С#. Далее добавили цикл, который будет считывать весь код с файла (рисунок - 6).

Рисунок - 6 – Фрагмент кода, реализующего лексический анализатор.
Далее на входе мы имеем путь к .txt-файлу с программой в переменной. Считываем весь в файл в массив. В цикле while берем последовательно каждый символ из mass и отправляем его в метод Analysis. Если встречаем апостроф, то отходим от правил и идем по переменной mass, пока ни найдем второй апостроф. В циклах необходимо добавить дополнительные условия выхода из проверки. Добавили переменная type, которая отвечает за получение значения таблицы, к которому относится лексема. Переменная берет лексему из таблицы базы данных. Получаем код символа. Проверяем, относится ли код символа к буквам английского алфавита и знаку нижнего подчеркивания. Проверяем, относится ли код символа к цифрам или к точке. Отдельная проверка, если код символа относиться к точке проверяем, чтобы в переменной temp было число. Если в temp число, значит, теперь мы считаем его дробным, в противном случае это что-то другое. Так же делаем проверку на все символы нашего словаря лексем. В методе Result мы определяем, что же мы нашли. В самом начале проверяем переменную temp на принадлежность к ключевым словам. Проверяем в начале, чтобы не перепутать найденную лексему с идентификатором. Если найденное не является ключевым словом, то через switch проверяем тип лексемы, определенный заранее в методе Analysis. Также проверяем, чтобы найденный идентификатор/константа/разделитель уже не значился в таблице. После проверки получаем лексемы слова, или символа. Далее мы выводим лексему на экран. Так в ходе цикла идет проверка всего кода и вывод каждой лексемы. В ходе цикла выводим строки лексем, соответствуя строкам кода.
Наш лексический анализатор готов. Теперь при выборе второго пункта меню при запуске программы, выведет лексемы нашего кода (рисунок - 7).
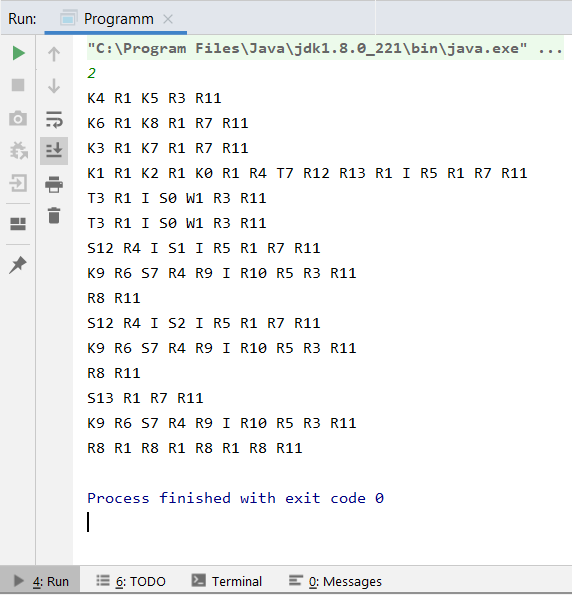
Рисунок - 7 – Работа лексического анализатора.
Заключение
В данном курсовом проекте была разработана программа-анализатор, разбивающая исходный текст программы на лексемы и заполняющая таблицу имен. В качестве языка входной программы был использован C#. Кроме того, была задействована система управления базами данных PosgreSQL.
В ходе выполнения курсового проекта были получены следующие результаты:
1. Написана грамматика для учебного языка программирования;
2. Спроектирован и построен лексический анализатор.
Библиографический список:
1. Ключко В. И. Теория вычислительных процессов и структур. Учебное пособие,
- КубГТУ, 1998.
2. Теория вычислительных процессов и структур. Методические указания к курсовой работе для студентов специальности 220400. Составитель проф.
В. И. Ключко. - КубГТУ,1997. -27 с.
3. Соколов А. П. Системы программирования: теория, методы, алгоритмы: Учеб. Пособие, - М.: Финансы и статистика, 2004. – 320 с.: ил.
4. Гордеев А. В., Молчанов А. Ю. Системное программное обеспечение. – СПб.: Питер, 2001. – 736 с.
5. Ахо А, Сети Р., Ульман Д. Компиляторы: принципы, технологии инструменты. : Пер. с англ. – М.: Издательский дом «Вильямс» , 2003. – 768 с.: ил. ISBN5-8459-0189-8(рус), ББК 32.973.26.-018.2.75
6. Вольфенгаген В. Э. Конструкции языков программирования. Приемы описания. - М.: АО «Центр ЮрИнфоР», 2001.-276 с.
7. Карпов В. Э. Теория компиляторов. Учебное пособие — Московский государственный институт электроники и математики. М., 2001. – 79 с (электронный вариант)
8. Alfred V. Aho, Ravi Sethi, Jeffrey D. Ullman . Compilers Principles, Techniques, and Tools. 2000. (электронный вариант).
9. Серебряков В. А. Лекции по конструированию компиляторов. Москва, 1993 (электронный вариант).
|
из
5.00
|
Обсуждение в статье: МОДЕЛИРОВАНИЕ ПРОЦЕССА ЛЕКСИЧЕСКОГО АНАЛИЗАТОРА. |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы