 |
Главная |


Мультимикропроцессорные вычислительные системы
|
из
5.00
|
В настоящее время выбор сделан в пользу многопроцессорных симметричных ВС типа MIMD, обеспечивающих виртуализацию вычислительных ресурсов. Основу такой ВС составляет суперскалер, сосредоточивший в себе все способы достижения максимального быстродействия при выполнении одиночной программы. Векторные и векторно-конвейерные процессоры и системы получили своё место. Их эффективность как самостоятельных установок могла быть достаточно высокой только при решении специальных задач и тестов. Поэтому достаточно быстро выяснилось, что эти установки могут выполнять функции интеллектуальных терминалов при решении основной задачи на другом универсальном вычислительном средстве и выполнять лишь отдельные его заявки. Сегодня стало окончательно ясно, что первые эффективны лишь в роли специализированных вычислительных устройств для решения специальных задач. Вторые твердо заняли место в составе многофункциональных арифметическо-логических устройств (АЛУ) суперскалеров, ибо без конвейеров мы не мыслим себе выполнение всех операций ВС.
Складывается и структура памяти ВС, которая может совмещать в одной установке все способы доступа: от разделяемой (общей) до распределенной оперативной памяти. Однако ограниченные возможности эффективной работы с общей памятью часто диктуют иерархическую структуру ВС, где уровни иерархии (кластеры) отличаются или способом доступа к оперативной памяти, или тем, что каждый кластер имеет свою собственную физическую память в общем адресном пространстве. При этом принцип буферизации, основанный на многоуровневой по быстродействию (и, конечно, — различной по технологии) памяти, на активном использовании Кэш-памяти, продолжает развиваться. Кэш-память, как память самого высокого уровня, претерпевает функциональное разбиение в зависимости от типа данных, для хранения которых она предназначена, либо, в зависимости от вида обработки, — программ или данных.
Все сказанное выше подтверждает перспективность структурных решений при проектировании многопроцессорного комплекса "Эльбрус-3" и его микропроцессорного развития "Эльбрус-3М", "Эльбрус-2К". Таким образом, структура "длинного командного слова" (архитектура VLIW, лежащая в основе EPIC) попадает в разряд классических.
Сейчас микропроцессор, сконцентрировавший все достижения микроэлектроники, является основной составляющей элементно-конструкторской базы ВС. Поэтому понятие "мультимикропроцессорные ВС" пришло на смену понятию "микропроцессорные ВС".
Анализ современных мультимикропроцессорных ВС позволяет выделить те развиваемые характерные решения, которые в условиях микроминиатюризации и снижения энергоемкости, "экономного" логического развития обеспечивают необходимые свойства универсального применения.
Такими решениями являются следующие.
1. Многопроцессорные кристаллы. Воспроизведение многопроцессорной ВС на одном кристалле в значительной степени характерно для сигнальных вычислительных средств, специализирующихся на обработке двух- и трехмерных изображений, которые применяются в цифровом телевидении и радиовещании, при передаче изображений по каналам связи и др. Такие средства эффективно используются в качестве нейрокомпьютеров.
Например, на одном кристалле MVP (Multimedia Video Processor) семейства TMS 320 C80 (фирма Texas Instrument) расположены 4 32-разрядных цифровых сигнальных процессора (DSP — Digital Signal Processor) с фиксированной запятой (ADSP-0 — ADSP-3). Их особенность — высокая степень конвейеризации и до 64 бит длина командного слова для параллельного выполнения нескольких операций. Система команд содержит команды над битовыми полями и структурами данных, несущими графическую информацию. Такая специализация обусловила понятие — DSP-архитектура.
Процессоры работают независимо. Т.е. ВС — типа MIMD — (Multiple-Instruction, Multiple-Data). Программируются отдельно на ассемблере или ЯВУ. Данными обмениваются через общую внутрикристальную память.
Каждый из ADSP содержит КЭШ-память команд (2 Кбайта), и через матричный коммутатор Crossbar получает доступ к 32 из имеющихся 50 Кбайт быстродействующей статической внутренней памяти. Память расслоенная — поделена на сегменты. Если два и более процессора в одном цикле попытаются обратиться к одному сегменту, аппаратная система управления доступом с циклическим изменением приоритета (round robin prioritization) позволит сделать это только одному процессору.
32-разрядное АЛУ ADSP может работать как два 16- или четыре 8-разрядных АЛУ. Этого достаточно для обработки видеоизображений. Специальные блоки ускоряют обработку графики. Блоки генерации адресов формируют кольцевые (бесконечные) буферы. Аппаратно поддержаны три вложенных цикла.
RISC-процессор управляет четырьмя ADSP с помощью диспетчера. Диспетчер и планировщик заданий тесно взаимодействуют с контроллером пересылок. Кроме того, управляющий процессор самостоятельно выполняет вычисления и обеспечивает обмен с внешними устройствами. Содержит встроенный блок плавающей арифметики и набор векторных операций с плавающей запятой, оптимизированных для обработки изображений, звука и трехмерной графики.
2. Транспьютерная технология. Представленная выше архитектура обладает такой конструктивной законченностью, которая позволяет как встраивать ее в некоторую систему, так и организовать взаимодействие нескольких кристаллов. Это обеспечивается развитыми средствами связи и обмена данными.
Возможность комплексирования привлекла внимание еще на раннем этапе развития микропроцессоров (в середине 1980-х годов) и привела к построению транспьютеров — микропроцессоров, снабженных развитыми средствами комплексирования. Таким образом, создавались "кирпичики", на основе которых можно было создавать сложные структуры. Эта тенденция не только сохранилась, но является необходимым средством построения мультимикропроцессорных ВС.
Преследуя многофункциональность средств обмена, не обязательно требовать их размещения на одном кристалле с центральным процессором.
Общее адресное пространство комплексируемых микропроцессоров "АКУЛА" обеспечивает псевдообщую память и исключает необходимость программной организации обмена данными. Если адрес физически принадлежит ОП другого процессора, то обмен организуется автоматически, без вмешательства пользователя (т.е. программно не предусматривается).
3. Межпроцессорный (магистральный) обмен инициируется в том случае, если адрес считывания или записи принадлежит адресному пространству другого процессора (единичный обмен). Аналогично возникают групповые пересылки данных с использованием "чужого" адресного пространства.
Пользователь не составляет программу обмена, даже для контроллера обмена данных. Достаточно указать "чужие" адреса.
Процессоры обмениваются сигналами состояния. Поэтому каждый процессор знает, кто является "хозяином" магистрали, т.е. ведет обмен, и свой приоритет в очереди к магистрали. По завершении каждого обмена производится циклическая смена приоритетов процессоров, которым нужна магистраль. Процессор с максимальным приоритетом становится "хозяином".Обмен может прерываться только ХОСТ-процессором.
Микропроцессор утверждается в роли основы элементно-конструкторской базы ВС, и это поняли ведущие разработчики.
В этом смысле привлекает внимание трансформация интересов "отца суперкомпьютеров" С.Крея, который признал определяющую роль принципа MIMD при построении ВС Cray Superserver 6400 System (CS640), выпускаемой корпорацией Cray Research в сотрудничестве с компанией SUN Microsystems (сотрудничество с фирмой SUN ныне характерно и для ведущих российских разработчиков).
Система предполагает наращиваемую конфигурацию от 4 до 64 процессоров SuperSPARC. Принято компромиссное решение на основе классической схемы разделения (общей) ОП при многопроцессорной обработке и распределенной памяти при параллельной обработке массивов. Чтобы работать с частично распределенной памятью в ОЗУ, ВС имеет в любой конфигурации 4 шины. Шина использует сетевую технологию "коммутации пакетов". Это позволяет находить путь обмена единицами информации в соответствии с занятостью или освобождением шин.
В целом, архитектуру следует считать шинной, хотя наличие нескольких шин делает ее промежуточной между шинной и использующей матричный коммутатор.
2.2 Направление "мини-супер" для персональных компьютеров
То, что говорилось выше, "по умолчанию" соответствует разработке супер-ЭВМ, предназначенных для решения особо сложных задач в составе систем управления в реальном времени, моделирования сложнейших физических процессов, решения задач исследования операций, задач искусственного интеллекта, выполнения роли майнфреймов и серверов в локальных, корпоративных и глобальных сетях.
Супер-ЭВМ уникальна, мало тиражируема, цена ее высока.
С другой стороны, ничто уже не может остановить "победного шествия" персональных компьютеров. Область применения их стала всеобъемлющей. Они используются и там, где могут справиться с задачами, и там, где уже не справляются, несмотря на применение современных суперскалеров.
Тогда целесообразно поставить следующую проблему.
Введем в состав персонального компьютера (РС), как его внешнее устройство, мультимикропроцессорную систему (мультипроцессор), использование которого в монопольном и однозадачном режиме может обеспечить успешное решение задач повышенной сложности.
Действительно, разрешение этой проблемы позволило бы заполнить определенную нишу между супер-ЭВМ и PC, вывести персональный компьютер на уровень мини-супер-ЭВМ. Применение мультипроцессора РС в однопрограммном режиме, при жестком распределении памяти, использование (см. далее) прогрессивной технологии "одна программа — много потоков данных" позволяют существенно снизить издержки производительности на работу ОС, легко "врезать" их в современные операционные системы компьютеров. Сборка такой системы должна производиться на основе существующей микропроцессорной элементно-конструкторской базы, с минимальным использованием вновь разрабатываемых элементов.
Здесь воспроизводится упомянутая выше идея о наличии мониторной системы, на которой решается основная задача, и о наличии интеллектуального терминала, который берет на себя функции, обеспечивающие общую эффективность системы.
Общая схема такой установки показана на рис.2.2.1 Выбраны конкретные значения параметров.

Рис. 2.2.1 Схема ВС для персонального компьютера
Мультимикропроцессорную приставку к персональному компьютеру целесообразно разработать на основе исследования принципов построения локально-асинхронной архитектуры (SPMD-технологии). Важным достоинством архитектуры является сведение традиционных функций ОС на уровень команд. Т.е. система команд мультипроцессора такова, что позволяет реализовать функции управления параллельным процессом, не требуя запуска процедур ОС. Способствует простоте управления параллельным процессом также монопольный и однозадачный режим использования мультипроцессора. Ниже мы подробнее остановимся на принципах SPMD-технологии. Предполагая первоначальное знакомство с этими принципами, отметим следующее.
Известно (см. далее), что семафоры — универсальное средство синхронизации. Однако семафоры традиционно используют ОС. Чтобы этого избежать, семафоры следует реализовать с помощью предикатного механизма, т.е. с использованием памяти предикатов.
Семафорный механизм может быть эффективно реализован с помощью механизма закрытия адресов (памяти закрытых адресов).
Тогда, в общем случае применения семафоров, должны быть введены команды следующего вида.
Считать по семафору (Сч(С) А). Считывание по адресу производится в случае, если указанный семафор (реализованный в памяти регистрового типа, наряду с индексными и базовыми регистрами) открыт. Если семафор закрыт, реализуется ожидание данного ПЭ без прерывания (т.е. в данном применении пользователь может быть допущен к операциям над семафорами типа "жужжать").
Записать по семафору (Зап(С) А). Запись по адресу производится аналогично предыдущей команде.
При использовании памяти закрытых адресов необходима лишь команда Закрыть адрес. Любое последующее считывание по этому адресу циклически возобновляется (в режиме "жужжания") до тех пор, пока по этому же адресу другой процессор не произведет запись.
В случае использования механизма предикатов адрес некоторой булевой переменной записывается в специальные разряды командного слова. Команда, для которой указанный в ней предикат имеет значение 0, выполняется, в соответствии с кодом операции, в спекулятивном режиме в двух модификациях:
· ожидается присвоение данному предикату значения 1 (в режиме "жужжания");
· пропускается выполнение данной команды.
ПЭ реализует идею RISC-архитектуры и представляет собой функционально законченное устройство, состоящее из микропроцессора, схем обрамления и локальной оперативной памяти (ЛОП). Локальная память процессора содержит область для хранения стеков вычислительного процесса, в том числе — стеков подпрограмм и вложенных циклов. В других областях этой памяти хранятся модификаторы, дескрипторы массивов и локальные величины. Здесь же находятся микропрограммы, реализующие систему команд ВС.
Общая (разделяемая) память (ОП) содержит M модулей с общим адресным пространством и реализует принцип интерливинга, предполагающий, что смежные ячейки памяти находятся в разных модулях.
Синхронизатор предназначен для обеспечения одновременного пуска программ или их модулей.
Возможно использование простейших коммутаторов для обмена ПЭ с модулями памяти.
3. Распараллеливание в ВС на уровне исполнительных устройств
Конвейеры операций
Выполнение любой операции складывается из нескольких последовательных этапов, каждый из которых может выполняться своим функциональным узлом. Это легко показать на операциях сложения и умножения. Выполнение деления мантисс (порядки вычитаются) чаще всего производятся с помощью вычитания из делимого делителя, сдвига влево полученного остатка, нового вычитания делителя из результата сдвига и т.д. В некоторых ВС находится обратная величина делителя с помощью аппроксимирующих полиномов. Затем делимое умножается на эту величину.
Пусть задана операция, выполнение которой разбито на n последовательных этапов. Пусть ti — время выполнения i-го этапа. При последовательном их выполнении операция выполняется за время

а быстродействие ЭВМ или одного процессора ВС, выполняющего только эту операцию, составит

Выберем время такта — величину tT = max ti} и потребуем при разбиении на этапы, чтобы для любого i = 1, ...,n выполнялось условие ti + t(i+1) mod n > tT. Т.е. чтобы никакие два последовательных этапа (включая конец и новое начало операции) не могли быть выполнены за время одного такта.
Функциональные узлы, выполняющие последовательные этапы одной операции, целесообразно выстроить в единую конвейерную линию, где устройство, выполняющее некоторый этап, закончив его для операции над одним набором данных, переходило бы в следующем такте к выполнению этого же этапа той же операции для другого набора исходных данных.
Например, на рис. 3.1.1 представлен конвейер выполнения операции сложения.

Рис. 3.1.1 Выполнение операции сложения на конвейере
Пусть реализуется поток команд одного процессора или существует доступ к этому устройству нескольких процессоров так, что в каждом такте возможно задание на выполнение сложения новой пары чисел. Тогда временная диаграмма работы конвейера может иметь вид, представленный на рис. 3.1.2
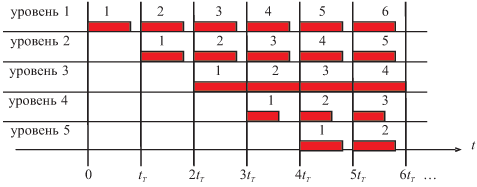
Рис. 3.1.2 Схема заполнения конвейера
Максимальное быстродействие процессора при полной загрузке конвейера составляет

Число n — количество уровней конвейера, или глубина перекрытия, т.к. каждый такт на конвейере параллельно выполняются n операций. Чем больше число уровней (станций), тем больший выигрыш в быстродействии может быть получен.
В проекте МВК "Эльбрус-3" АЛУ его ЦП имеет конвейерные ИУ сложения (n=5), умножения (n=5), деления (n=8 для полусловного формата, — 32 разряда, n=16 для словного формата). Логические операции также выполняются на конвейере с n=2.
Известна оценка

т.е. выигрыш в быстродействии получается в 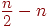 раз.
раз.
Реальный выигрыш в быстродействии оказывается всегда меньше, чем указанный выше, поскольку:
1. некоторые операции, например, над целыми, могут выполняться за меньшее количество этапов, чем другие арифметические операции. Тогда отдельные станции конвейера будут простаивать.
2. при выполнении некоторых операций на определённых этапах могут требоваться результаты более поздних, ещё не выполненных этапов предыдущих операций. Приходится приостанавливать конвейер.
3. поток команд порождает недостаточное количество операций для полной загрузки конвейера.
3.2 Векторные конвейеры. "Зацепление" векторов
Наряду с использованием конвейеров для обработки единичных (скалярных) данных, используют так называемые векторные конвейеры, единичной информацией для которых являются вектора — массивы данных. Применение векторных конвейеров определило класс ВС — векторно-конвейерных ВС, сегодня ещё являющихся основой построения некоторых супер-ЭВМ — ВС сверхвысокой производительности.
Для эффективности векторно-конвейерных ВС (например, для подготовки алгоритмов решения задач на ВС "Электроника-ССБИС") необходима векторизация задач. Это — такое преобразование алгоритма, при котором максимально выделяются (если не вся задача сводится к этому) элементы обработки массивов данных одинаковыми операциями. Сюда входят все задачи, основанные на матричных преобразованиях, обработка изображений, сигналов, моделирование поведения среды и т.д.
В основе векторного конвейера лежит то же самое разбиение операции на уровни или этапы выполнения, но он дополняется средствами аппаратной поддержки, позволяющими по информации о векторах организовать последовательную загрузку конвейера элементами векторов, учитывая их длину.
Пусть необходимо выполнить операцию C = A × B, т.е. cj = aj + bj, j = 1, ...,N. Пусть на регистрах СОЗУ записаны вектора A и B. Группа регистров отведена для результатов C. Для управления этим процессом известны дескрипторы векторов DA ,DB ,DC, где D  = {a , h , N}, = A,B,C,h — шаг переадресации. Если загрузка векторов производится всегда в одни и те же регистры АЛУ, то достаточно знать значение N. Может задаваться маска M длиной N, состоящая из нулей и единиц. Каждый элемент M соответствует элементу вектора-результата C. Если элемент mj = 1 (логическая переменная), то операция получения cj производится, в противном случае соответствующие элементы векторов пропускаются. Это применимо для альтернативного счёта в соответствии со значением логических переменных.
= {a , h , N}, = A,B,C,h — шаг переадресации. Если загрузка векторов производится всегда в одни и те же регистры АЛУ, то достаточно знать значение N. Может задаваться маска M длиной N, состоящая из нулей и единиц. Каждый элемент M соответствует элементу вектора-результата C. Если элемент mj = 1 (логическая переменная), то операция получения cj производится, в противном случае соответствующие элементы векторов пропускаются. Это применимо для альтернативного счёта в соответствии со значением логических переменных.
Пусть операция умножения выполняется за три этапа. Тогда можно представить временную диаграмму получения N результатов при предположении о назначении функциональных устройств (рис. 3.2.1).

Рис. 3.2.1 Умножение векторов на конвейере
В составе АЛУ может быть два и более конвейерных устройств, специализированных каждое для выполнения некоторой операции. Тогда возможно и эффективно "зацепление" векторов, иллюстрируемое примером на рис. 3.2.2 для выполнения сложной операции над векторами: D=A× B+C.

Рис. 3.2.2 "Зацепление" векторов
Здесь два конвейера образовали один, с глубиной перекрытия n = n× + n+. Очередной результат умножения немедленно направляется на конвейер сложения, куда параллельно направляется необходимый сомножитель.
|
из
5.00
|
Обсуждение в статье: Мультимикропроцессорные вычислительные системы |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы