 |
Главная |


ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
|
из
5.00
|
ПЕРВИЧНАЯ ОБРАБОТКА
Методические указания по контрольной работе № 8
для студентов заочного факультета всех специальностей
Магнитогорск
2011 г.
Составитель: Е.М. Гугина
Первичная обработка экспериментальных данных: Методические указания к выполнению контрольной работы № 8 для студентов всех специальностей заочного отделения. Магнитогорск: ГОУ ВПО «МГТУ им. Г.И. Носова», 2011. - 27 с.
Данные указания включают
-ход работы;
-пример выполнения работы;
-указание соответствующего теоретического материала и список вопросов для подготовки к защите работы.
Рецензент: Реент Н.А., доцент каф. мат. методы в экономике
ВВЕДЕНИЕ
Основной задачей современной математической статистики, методы которой опираются на теорию вероятностей, является научная оценка результатов измерений. В таких задачах, как контроль качества продукции, подвергнуть контролю всю продукцию практически невозможно и особенно в тех случаях, где контроль связан с разрушением пробы или изделия, например, при испытании ламп и электронных трубок на долговечность и т.п.
Именно здесь и приходят на помощь методы математической статистики, посредством которых можно по известным свойствам некоторого подмножества объектов, взятого из совокупности, судить о неизвестных свойствах всех объектов, принадлежащих данной совокупности.
Задачи математической статистики состоят:
1) в указании способа группировки статистических данных,
2) в разработке методов анализа статистических данных:
а) оценки неизвестных функций распределения, плотности распределения вероятностей, оценки зависимости между случайными величинами,
б) проверки статистических гипотез о виде неизвестных распределений и т.д.
В данной разработке содержатся методические рекомендации для студентов заочного отделения при подготовке и выполнении контрольной работы № 8, вопросы для подготовки и сдачи теоретической части и подробные указания по выполнению практической, снабженные соответствующими примерами всех расчетов.
Для изучения теории и выполнения работы рекомендуется литература:
- Краснов М.Л., Киселев А.И. и др. Вся высшая математика: Учебник. Т. 5.- М.: Эдиториал УРСС, 2001.- 296 с.
- Гмурман В.Е. Теория вероятностей и математическая статистика.- Учебн. пособие для вузов. - М.: Высш. шк.,2003.-479 с.
- Гмурман В.Е. Руководство к решению задач по теории вероятностей и математической статистике.- Учебн. пособие для вузов. - М.: Высш. шк.,2002.-405 с.
- Горелова Г.В., Кацко И.А. Теория вероятностей и математическая статистика в примерах и задачах с применением EXCEL. Ростов-на-Дону: Феникс,2002. 348 с.
- Кимайкина Н.И. и др. Теория вероятностей и математическая статистика. Учебные карты. Магнитогорск, МГМИ, 1991. 20 с.
6. Кимайкина Н.И., Кукушкина О.А. Элементы математической статистики. Методические указания к лабораторному практикуму. Магнитогорск: МГТУ, 2001. 30 с.
Теоретические вопросы
[Краснов и др. гл. XLIV, стр. 199 и далее,
Гмурман, гл. 16, §1-18, гл. 19, §1-6, 22, 23]
(какие понятия нужно знать, чтобы приступить к выполнению работы)
1. Генеральная и выборочная совокупности, способы организации выборки, объем совокупности, варианта, частота варианты, относительная частота варианты;
2. Статистический ряд, вариационный ряд, интервальный вариационный ряд, методика его получения группированием данных;
3. Эмпирическая функция распределения, способы её задания, полигон частот, гистограмма, выборочная оценка плотности вероятности.
4. Генеральные параметры (числовые характеристики) распределения - характеристики положения и рассеяния: математическое ожидание, дисперсия, среднее квадратичное отклонение.
5. Точечные и интервальные оценки параметров распределения.
6. Требования, предъявляемые к оценкам генеральных параметров (несмещенность, состоятельность, эффективность).
7. Статистическая проверка гипотез. Нулевая и конкурирующая, простая и сложная гипотезы.
8. Ошибки первого и второго рода.
9. Критерии значимости, критерии согласия.
10. Основные методы проверки нормальности распределения.
ХОД РАБОТЫ
1. Перед вами (в вашем варианте) сто чисел (Х) – статистический ряд объёма n =100. Упорядочите его по возрастанию. Данные запишите в таблицу и дайте ей номер1.
Для этого воспользуйтесь, например, Microsoft Excel: введите, например, в столбец А1-А100 все значения переменной Х, а в столбец В1-В100 – все значения переменной У. Скопируйте эти два столбца значений в любые соседние столбцы. Далее нам пригодятся и упорядоченные данные – для нахождения максимального и минимального значений, и исходные - для построения корреляционного поля и корреляционной таблицы. Теперь выберите встроенную функцию сортировки по возрастанию  в верхнем меню, примените ее по очереди к первым двум столбцам (выделив их и нажав на кнопку сортировки). Сохраните результат (или распечатайте на принтере).
в верхнем меню, примените ее по очереди к первым двум столбцам (выделив их и нажав на кнопку сортировки). Сохраните результат (или распечатайте на принтере).
2. Запишите минимальное и максимальное значения совокупности Х (статистического ряда):  .
.
3. Найдите размах варьирования измеримого признака:
 .
.
4. Выберите число интервалов равным 7: r =7.
Замечание: Напомним, что число интервалов может быть выбрано произвольно. Выбор r зависит от объёма n, размаха R и от цели статистического исследования. Принято, чтобы получилось не менее 6 и не более 20 интервалов.
5. Определите, чему равен шаг варьирования признака (длина интервала будущего вариационного ряда Х).
 .
.
6. Теперь найдем границы интервалов признака Х таким образом, чтобы минимальное значение стало серединой первого интервала, а максимальное – серединой последнего. Для этого отступим от  на полшага, а к правому концу каждого интервала будем прибавлять длину шага:
на полшага, а к правому концу каждого интервала будем прибавлять длину шага:
 ,
, 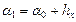 ,
,  ,
, 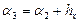 ,
, 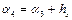 ;
;  ;
;  ;
;  ;
;  .
.
Таким образом, фактическое число интервалов равно 8.
(Убедитесь в правильности своих подсчетов: значение  должно быть больше максимального значения
должно быть больше максимального значения  на полшага.)
на полшага.)
7. Найдем середины получившихся интервалов:
 ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
, 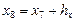 .
.
О верности подсчетов свидетельствует равенство (возможно приближенное) последних, восьмых, значений .
8. Составьте вариационный ряд измеримого признака Х .
Таблица 1
| х | 
| 
| 
| 
| 
| 
| 
| 
|

| 
| 
| 
| 
| 
| 
| 
| 
|
Здесь  - число значений
- число значений  , попавших в соответствующий интервал
, попавших в соответствующий интервал  .
.
(Проверьте: сумма абсолютных частот  , где n – объём выборки.)
, где n – объём выборки.)
9. Заполните таблицу «Статистическая совокупность» :
(с помощью пунктов 6, 7 и 8 заполняем первые три столбца таблицы; данные в остальные столбцы вписываем после подсчета соответствующей формулы, записанной в ячейке таблицы)
Таблица 2
Статистическая совокупность измеримого признака Х
Интер-валы

|
Серед. интерв.

| Частоты | Плот-ность относит. частот

| |||
Абсолют-ная

| Относитель-ная

| Накоплен. абсолютн.

| Накоплен. относит.
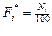
| |||

| 
| 
| / 100
| 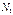 =0 =0
|  =0 =0
| 
|

| 
| 
|  / 100 / 100
|  = = 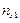
| 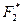 = = 
| 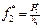
|
| … | … | … | … | … | … | … |

| 
| 
| / 100
|  =100- =100- 
|  =1- =1- 
| 
|

|
10. По данным таблицы 2, постройте (см. пример):
а) полигон и гистограмму распределения – графические оценки плотности распределения вероятностей генеральной совокупности;
б) полигон накопленных частостей – график эмпирической функции распределения:
 .
.
11. Запишите расчетные формулы для сгруппированных в r интервалов данных:
выборочного среднего  ;
;
выборочной дисперсии  ;
;
выборочного среднеквадратичного отклонения  ;
;
выборочной асимметрии  ;
;
выборочного эксцесса  .
.
12. Заполните расчетную таблицу, взяв данные для первых трех столбцов из таблицы 2:
Удобно воспользоваться для этого таблицей EXCEL: скопируйте первые три столбца из таблицы 2 на «новое» место таблицы EXCEL, оформите заголовки колонок.
Таблица 3
Расчет выборочных оценок признака Х
| Серед
инт.
|
Частота

| Относит. частота
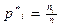
|
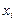 
|

|
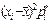
|

|

|
| … | … | … | … | … | … | … | … |

| n | 
| 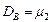
| 
| 
|
Для заполнения четвертого столбца, введите в первой строке четвертого столбца формулу содержимого этой колонки: произведение соответствующих ячеек первого и третьего столбцов нашей новой таблицы. Например, новая таблица располагается в ячейках А:101- H:101 (заголовок) и в нижележащих строках этих столбцов, тогда содержимое ячейки D:102 равно (А:102)*(С:102). Записывают расчетную формулу, «встав» в ячейку D:102 или в командной строке верхнего меню «  »:
»:

начиная со знака “=”, например: “=(A:102)*(С:102)”, нажимают ввод – в ячейке высветится результат. Скопировав первую строку D:102 в нижележащие строки этого столбца, автоматически заполним весь столбец.
Теперь находим сумму элементов этого столбца - среднее (ячейка D:110) - выделяем содержимое столбца и нажимаем мышью на значок автосуммы верхнего меню.
Заполняем оставшиеся колонки, вписывая необходимые формулы сначала в первые строки колонок, затем копируя в низлежащие. Например, в ячейке E:102 формула будет следующей: “=(A:102)-(D:110)”, в ячейке F:102 формула будет следующей: “=((E:102)^2)*(C:102)”, в ячейке G:102 формула будет следующей: “=((E:102)^3)*(C:102)”, в ячейке H:102 формула будет следующей: “=((E:102)^4)*(C:102)”. Просуммировав элементы соответствующих колонок (выделяем содержимое столбца и нажимаем мышью на значок автосуммы верхнего меню), находим ; ; .
13. По формулам (пункт 11) и по данным таблицы 3 (пункт 12), найдите выборочные оценки: выборочного среднего, выборочной дисперсии, выборочной асимметрии, выборочного эксцесса.
14. Найдите исправленные оценки (статистики) генеральных параметров:
- выборочное среднее = 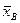 ; - исправленная дисперсия
; - исправленная дисперсия  ;
;
- исправленное среднеквадратичное отклонение  ;
;
-исправленная асимметрия  ;
;
- исправленный эксцесс  .
.
15. Найти моду и медиану по сгруппированным данным:
 , где
, где
 - середина интервала (модального) с наибольшей частотой
- середина интервала (модального) с наибольшей частотой  ;
;
 - нижняя граница модального интервала (левый конец отрезка, на котором самое большое значение частоты ); h – длина интервала (см. пункт 5);
- нижняя граница модального интервала (левый конец отрезка, на котором самое большое значение частоты ); h – длина интервала (см. пункт 5);
 , где
, где
 - середина интервала (медианного), содержащего накопленную частоту
- середина интервала (медианного), содержащего накопленную частоту  , не превосходящую половины выборки
, не превосходящую половины выборки 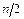 (
( 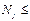
 );
);
 - нижняя граница медианного интервала;
- нижняя граница медианного интервала;
 и
и  - частота и накопленная частота соответственно этого интервала.
- частота и накопленная частота соответственно этого интервала.
16. Для проверки гипотезы Но: генеральная совокупность измеримого признака, из которой извлечена выборка, распределена при данном уровне значимости  =0,05 по нормальному закону с плотностью
=0,05 по нормальному закону с плотностью
 , где
, где
а и  - параметры нормального распределения, необходимо:
- параметры нормального распределения, необходимо:
- объединить интервалы (смотри пример) с абсолютными частотами , меньшими 5 , суммируя частоты;
- отметить, чему равно теперь r – число интервалов;
- записать число к - степеней свободы и по таблицам выписать 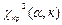 ;
;
- заполнить расчетную таблицу для вычисления 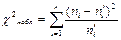 :
:
Таблица 4
Проверка гипотезыНо по критерию Пирсона
Левая граница
интерв.

| Правая гран.
нтер.

|
Абс.
Частота

| Zi=
= 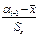
| Ф(Zi) |

|

|

|
| … | … | … | … | … | … | … | … |
|
|  1 1
| 
|
где Ф(zi) – значение функции Лапласа для значений zi, записанных в предыдущем столбце,
 =
=  Ф - теоретическая вероятность попадания случайной величины Х, распределенной нормально, в интервал -
Ф - теоретическая вероятность попадания случайной величины Х, распределенной нормально, в интервал -  (значение функции Лапласа можно найти по таблице приложения 2 ( см. [3] или [5]) или с помощью встроенной функции НОРМСТРАСП(z)).
(значение функции Лапласа можно найти по таблице приложения 2 ( см. [3] или [5]) или с помощью встроенной функции НОРМСТРАСП(z)).
Воспользуемся таблицей EXSEL для упрощения вычислений. Скопируйте первые три столбца табл. 3 на «новое» место таблицы EXCEL, оформите заголовки колонок.
Выполните «вручную» работу по объединению интервалов, для которых абсолютная частота , меньше 5: запишите в таблицу границы вновь полученных интервалов, их середины и новое значение абсолютной частоты, равной сумме абсолютных частот объединенных интервалов.
Подсчитайте количество полученных после объединения интервалов, найдите число степеней свободы к и (например, смотри приложение 5 [3, стр. 390]).
Для дальнейших вычислений удобно левую и правую границы интервалов оформить в отдельные столбцы, чтобы «обращаться» к номеру ячейки – левого (а для последнего интервала – и правого) конца интервала.
Приступим к заполнению четвертого столбца: запишите в первой строке этого столбца после знака ''='', формулу вычисления Zi=  с помощью номеров ячеек, в которых содержатся
с помощью номеров ячеек, в которых содержатся  , и
, и  .
.
Например, новая таблица располагается в ячейках А:101- H:101 (заголовок) и в нижележащих строках этих столбцов, тогда содержимое ячейки D:102 равно ((А:102)-37,67)/10,81 [взяты значения =37,67 и =10,81]. Записывают расчетную формулу, «встав» в ячейку D:102 или в командной строке верхнего меню « », начиная со знака “=”, например: “=((А:102)-37,67)/10,81 ”, нажимают ввод – в ячейке высветится результат. (Отметим, что кавычки при написании формулы на компьютере ставить не надо.) Скопировав первую строку D:102 в нижележащие строки этого столбца, автоматически заполним весь столбец. Добавим еще одно значение Zi , вычислив его для правого конца самого последнего интервала, взяв его значение в соответствующей ячейке. Таким образом, строк в четвертом столбце станет на одну больше, чем в первых трех столбцах.
Следующий, пятый, столбец заполним с помощью встроенной функции НОРМСТРАСП(z), или «вручную», взяв значения функции Лапласа Ф(Zi) в соответствующей таблице, например, в учебных картах [5] или учебнике [3, стр. 390, приложение 2].
Теоретическую вероятность (следующий, шестой, столбец) находим, «забивая» соответствующую формулу с указанием ячеек: например, в ячейке F:102 формула будет следующей: “=(E:103)-(Е:102)”; проследите за правильным заполнением остальных строк этого столбца. Отметим, что строк в этом столбце станет на одну меньше (первоначальное число строк).
Не будем описывать, как заполняются последние два столбца – это делается аналогично, с помощью введения в ячейки соответствующих формул; надеемся на то, что при выполнении первых двух работ вы освоили эти действия.
Заметим, что приближенные значения теоретических частот  (предпоследний столбец) можно заменить целыми значениями, «округляя» их с тем расчетом, чтобы сумма всех теоретических частот этого столбца была равна объему выборки п = 100.
(предпоследний столбец) можно заменить целыми значениями, «округляя» их с тем расчетом, чтобы сумма всех теоретических частот этого столбца была равна объему выборки п = 100.
После того, как получен последний столбец, суммируем его содержимое, получая, таким образом, значение  .
.
17. Сравните  с
с  и сделайте выводы о принятии гипотезы Но. (Если
и сделайте выводы о принятии гипотезы Но. (Если  меньше , гипотеза принимается, иначе – гипотеза о нормальном распределении измеримого признака Х – отвергается.)
меньше , гипотеза принимается, иначе – гипотеза о нормальном распределении измеримого признака Х – отвергается.)
ПРИМЕР. На заводе железобетонных изделий N для создания марки бетона высокого качества проводилось исследование 100 различных пробных сортов бетона, для которых подсчитывался процент прочности на сжатие (случайная величина Х) и процент сопротивления того же сорта бетона на разрыв (случайная величина У). Получен следующий результат
Статистический ряд. Исходные значения величин
| Х | У | Х | У | Х | У | Х | У | Х | У |
| 38,4 | 18,7 | 40,7 | 30,3 | 27,3 | 25,1 | ||||
| 40,2 | 11,7 | 50,8 | 28,4 | 15,7 | 20,6 | 28,6 | |||
| 24,1 | 20,9 | 38,2 | 22,8 | 47,6 | 11,3 | 52,8 | 15,2 | 19,5 | 19,7 |
| 32,5 | 22,4 | 19,8 | 30,3 | 21,3 | 24,5 | 20,3 | |||
| 29,5 | 35,7 | 15,3 | 30,5 | 27,8 | 28,7 | 27,8 | 15,5 | ||
| 38,1 | 19,6 | 34,3 | 20,7 | 48,7 | 11,5 | 32,5 | 35,2 | 30,7 | |
| 16,8 | 32,2 | 43,8 | 16,8 | 18,3 | 57,1 | 2,9 | 41,6 | 18,2 | |
| 28,8 | 29,7 | 35,5 | 23,9 | 20,2 | 23,8 | 42,5 | 15,3 | ||
| 47,1 | 14,7 | 45,9 | 54,3 | 14,2 | 50,7 | 15,9 | 32,9 | 22,5 | |
| 50,1 | 15,9 | 29,3 | 21,9 | 60,8 | 27,2 | 58,6 | 9,3 | 35,6 | 22,7 |
| 30,2 | 54,2 | 14,2 | 21,4 | 19,8 | 40,1 | 17,4 | 17,3 | ||
| 36,9 | 23,2 | 59,8 | 6,1 | 38,4 | 34,4 | 23,4 | 31,4 | 30,2 | |
| 36,6 | 7,9 | 32,2 | 22,3 | 46,8 | 20,5 | 53,7 | 12,4 | 28,2 | |
| 15,4 | 6,1 | 23,8 | 18,3 | 42,1 | 28,5 | 33,7 | 19,8 | ||
| 31,2 | 24,2 | 37,9 | 32,6 | 20,2 | 27,6 | 18,5 | |||
| 16,2 | 25,2 | 51,2 | 14,2 | 30,6 | 21,5 | 23,5 | 14,6 | 36,8 | 10,7 |
| 49,7 | 15,9 | 32,2 | 20,4 | 24,5 | 32,9 | 25,8 | 45,5 | 14,8 | |
| 49,7 | 19,5 | 30,9 | 20,7 | 57,6 | 20,3 | 14,4 | 18,6 | 15,3 | |
| 42,3 | 19,7 | 41,5 | 10,8 | 41,9 | 14,6 | 42,3 | 23,5 | 25,8 | 27,4 |
| 35,7 | 11,9 | 41,2 | 9,8 | 34,1 | 26,3 | 58,8 | 9,2 | 39,2 | 17,5 |
Найти эмпирическое распределение признака Х, построить графическое отображение распределения.
|
из
5.00
|
Обсуждение в статье: ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы