 |
Главная |


Тест Гольдфельда-Квандта
|
из
5.00
|
Шаг 1. Упорядочение n наблюдений по мере возрастания переменной x.
Шаг 2. Исключение из рассмотрения C центральных наблюдений. При этом (n-C)/2 > k, где k – число оцениваемых праметров.
Шаг 3. Разделение совокупности из (n-C) наблюдений на две группы (с большими и малыми значениями фактора x). По каждой совокупности строится уравнение регрессии.
Шаг 4. Определение ESS для первой (S1) и второй (S2) групп и нахождение их отношения R=S1/S2, где S1>S2.
При выполнении нулевой гипотезы о гомоскедастичности R имеет распределение Фишера F((n-C-2k)/2; (n-C-2k)/2). Поэтому если R > F  , то делается выво о гетероскедастичности остатков.
, то делается выво о гетероскедастичности остатков.
Тест Глейзера.
Похож на метод Уайта.
Строится регрессия  , где c может быть как положительным, так и отрицательным, как целым, так и дробным. Строятся такие регрессии при разных c и отбирается отбирается та функция, для которой коэффициент регрессии b оказывается наиболее значимым, т.е. имеет наибольшее значение t-критерия Стьюдента, или же для которой уравнение в целом оказывается наиболее значимым, т.е. имеет наибольшее значение F-критерия Фишера или R2.
, где c может быть как положительным, так и отрицательным, как целым, так и дробным. Строятся такие регрессии при разных c и отбирается отбирается та функция, для которой коэффициент регрессии b оказывается наиболее значимым, т.е. имеет наибольшее значение t-критерия Стьюдента, или же для которой уравнение в целом оказывается наиболее значимым, т.е. имеет наибольшее значение F-критерия Фишера или R2.
Вопрос 34 - Модели ANOVA и ANСOVA.
Регрессионные модели, содержащие лишь качественные объясняющие переменные, называются ANOVA-моделями (моделями дисперсионного анализа). Например, в определенных случаях предполагаемую связь результирующего показателя и фактора можно представить моделью:
 .
.
При этом коэффициент a определяет среднее значение результата при отсутствии действия фактора, а коэффициент с указывает, на какую величину изменяется среднее при «включении» фактора. Проверяя статистическую значимость коэффициента с, можно определить, влияет или нет изучаемый фактор, на результирующий показатель.
Применимость таких моделей в экономике крайне ограничена. Гораздо чаще встречаются процессы, модели которых должны содержать как качественные, так и количественные переменные.
Модели, в которых объясняющие переменные носят как количественный, так и качественный характер, называются ANCOVA-моделями (моделями ковариационного анализа). Пример:
 .
.
О фиктивных переменных см. вопрос 32.
Вопрос 35 – Ряды динамики
Экономические процессы чаще всего проявляются в виде ряда последовательно расположенных в хронологическом порядке значений того или иного показателя, который в своих изменениях отражает ход развития изучаемого явления. Эти значения, в частности, могут служить для обоснования (или отрицания) различных моделей, в том числе изученных нами ранее. Они служат также основой для разработки прикладных моделей особого вида, называемых трендовыми моделями.
Последовательность наблюдений одного показателя (признака), упорядоченных в зависимости от последовательно возрастающих или убывающих значений другого показателя (признака), называют динамическим рядом, или рядом динамики. Если в качестве признака, по которому проводят упорядочение, берется время, то такой динамический ряд называется временным рядом.
При изучении последовательных наблюдений экономических показателей все три приведенных выше термина используются как равнозначные. Составными элементами рядов динамики являются, таким образом, цифровые значения показателя, называемые уровнями этих рядов, и моменты или интервалы времени, к которым относятся эти уровни.
Временные ряды, образованные показателями, характеризующими экономическое явление на определенные моменты времени, называются моментными.
Если уровни временного ряда образуются путем агрегирования за определенный промежуток (интервал) времени, то такие ряды называются интервальными временными рядами.
Временные ряды могут быть образованы как из абсолютных значений экономических показателей, так и из средних или относительных величин — это производные ряды.
Под длиной временного ряда понимают время, прошедшее от начального момента наблюдения до конечного. Часто длиной ряда называют количество уровней, входящих во временной ряд.
В отличие от анализа случайных выборок в эконометрике, анализ временных рядов основывается на предположении, что данные наблюдаются через равные промежутки времени (тогда как ранее нам не была важна последовательность наблюдений ко времени).
Анализ временных рядов преследует две основные цели: (1) определение природы ряда и (2) прогнозирование (т.е. предсказание будущих значений временного ряда по настоящим и прошлым значениям). Эти цели достижимы, если модель ряда идентифицирована с определенной адекватностью и точностью. Если модель определена, то с ее помощью интерпретировать имеющиеся и экстраполировать ряд, т.е. предсказать его будущие значения.
Если во временном ряду проявляется длительная («вековая») тенденция изменения экономического показателя, то говорят, что имеет место тренд. Таким образом, под трендом понимается изменение, определяющее общее направление развития, основную тенденцию временных рядов. В связи с этим экономико-математическая динамическая модель, в которой развитие моделируемой экономической системы отражается через тренд ее основных показателей, называется трендовой моделью.
На практике тренд, чаще всего, не является единственной составляющей ряда. Как правило, в анализируемых данных присутствуют циклическая компонента (составляющая) и нерегулярная компонента. Именно поэтому в общем случае динамический (временной) ряд при построении регрессионной модели представляется следующими составляющими:
- тренд ut;
- циклическая (чаще всего сезонная) компонента vt;
- случайная компонента et.
Основная цель регрессионного анализа временных рядов – выявить систематические компоненты и оценить характер нерегулярности в названной «случайной» составляющей.
Вопрос 36 - LPM-модели (linear probability model). Logit-модели.
В различных исследованиях зависимая переменная может являться дискретной. Возможны следующие представления зависимой переменной:
- Количественная целочисленная характеристика;
- Качественная целочисленная характеристика, определяющая одно из возможных состояний объекта;
- Порядковая, когда выбор среди нескольких альтернатив ранжированный.
Каждая из описанных переменных зависит от ряда факторов, и в каждом конкретном случае исследователи пытаются создать модели, описывающие эту зависимость. На данном семинаре мы будем рассматривать модели бинарного выбора. В этом классе моделей зависимая переменная может принимать только два значения, то есть она является качественной переменной, определяющей одно из двух зависимых состояний:

Для исследования зависимости переменной y от объясняющих факторов может быть использована модель линейной регрессии:
 .
.
Поскольку yi принимает значения {0, 1} и  , математическое ожидание yi равно:
, математическое ожидание yi равно:
 ,
,
поэтому такую модель называют линейной моделью вероятности. Линейная модель вероятности имеет множество недостатков, наличие которых не позволяет использовать ее для оценивания параметров и прогнозирования y. Так, в ряде случаев использование МНК может привести к неинтерпретируемым результатам: при подстановке конкретных значений факторов x значения y могут оказаться либо <0, либо >1, что противоречит самой постановке задачи (т.к. моделируется вероятность).
Поэтому для моделирования значений  подбирают функции, область значений которых определяется отрезком [0, 1], а
подбирают функции, область значений которых определяется отрезком [0, 1], а 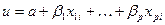 играет роль аргумента, т.е.
играет роль аргумента, т.е.
 .
.
В качестве F(u) естественно выбрать какую-либо дифференцируемую функцию распределения, определенную на всей прямой. Выбор функции F(u) определяет тип бинарной модели.
В качестве такой функции можно использовать функцию логистического распределения
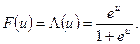
В этом случае модель называют логит-моделью (logit-model).
Независимо от того, какое распределение используется для оценки параметров модели, важно обратить внимание на то, что модель является нелинейной по факторам x, следовательно, интерпретация коэффициентов 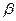 отличается от привычной интерпретации коэффициентов линейной регрессии. Так, коэффициенты бинарной модели не могут интерпретироваться как предельный эффект влияния факторов на зависимую переменную. Предельный эффект каждого объясняющего фактора xj (j=1,…,p) является переменным и зависит значения всех остальных факторов и вычисляется как:
отличается от привычной интерпретации коэффициентов линейной регрессии. Так, коэффициенты бинарной модели не могут интерпретироваться как предельный эффект влияния факторов на зависимую переменную. Предельный эффект каждого объясняющего фактора xj (j=1,…,p) является переменным и зависит значения всех остальных факторов и вычисляется как:
 .Для logit-модели:
.Для logit-модели:  .
.
Для оценки качества модели используется индекс R2 Макфаддена (McFadden). Пусть l – логарифмическая функция правдоподобия для нашей модели, а  - ограниченная логарифмическая функция правдоподобия, т.е. функция правдоподобия для модели только лишь со свободным членом. Очевидно, что
- ограниченная логарифмическая функция правдоподобия, т.е. функция правдоподобия для модели только лишь со свободным членом. Очевидно, что 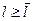 . Чем больше различаются эти показатели, тем лучше наша модель. Индекс R2 Макфаддена:
. Чем больше различаются эти показатели, тем лучше наша модель. Индекс R2 Макфаддена:
 .
.
Также рассчитывается показатель pseudo R2:
 ,
,
где N – объем выборки.
Значимость отдельных коэффициентов можно оценить с помощью t-критерия.
Вопрос 37 – LPM-модели. Probit-модели.
См. вопрос 36.
В качестве F(u) используется ф-ция нормального стандартного распределения:
 .
.
Угловые коэффициенты рассчитываются по формулам:
 .
.
Вопрос 38 – Проверка правильности выбора экзогенных переменных.
Экзогенность - буквально "внешнее происхождение" - свойство факторов эконометрических моделей, заключающееся в предопределенности, заданности их значений, независимости от функционирования моделируемой системы. Экзогенность противоположна эндогенности. Значения экзогенных переменных определяется вне модели и на их основе в рамках рассматриваемой модели определяются значения эндогенных переменных.
Факторы регрессионной модели называются экзогенными, если они некоррелированы со случайными ошибками.
См. вопросы 14 и 28.
Вопрос 39 - Инструментальные переменные. Тест Хаусмана
При наличии корреляции между независимыми переменными и ошибками МНК-оценки могут быть смещенными и несостоятельными. Один из способов преодоления этой трудности – использование новых переменных, называемых инструментальными. Для получения состоятельных оценок необходимо, чтобы:
- Новые независимые переменные должны были хорошо коррелированны с исходными независимыми переменными.
- Новые переменные не коррелировали с ошибками.
При этом совсем необязательно, чтобы число инструментальных переменных было равно числу исходных факторов. Достаточно лишь, чтобы число инструментальных переменных было не меньше, чем число исходных факторов.
В общем случае невозможно дать ответ на вопрос, как находить нужные инструментальные переменные. Все зависит от конкретной ситуации.
Одним из примеров получения инструментальных переменных является нахождение оценок эндогенных переменных в двухшаговом методе наименьших квадратов (см. вопрос 18). Т.е. от уравнения системы  переходят к уравнению с инструментальными переменными
переходят к уравнению с инструментальными переменными  :
:  , где - оценки величин
, где - оценки величин  , полученные по приведенной модели.
, полученные по приведенной модели.
Тест Хаусмана используется для того, чтобы определить, следует ли использовать инструментальные переменные.
Пусть Y –(n, 1)-вектор наблюдений величины Y, X – (n, k)-матрица наблюдений величин  , β -(k, 1)-вектор коэффициентов регрессии, Е -(n, 1)-вектор ошибок. В этих обозначениях уравнение регрессии: Y = Xβ + E.
, β -(k, 1)-вектор коэффициентов регрессии, Е -(n, 1)-вектор ошибок. В этих обозначениях уравнение регрессии: Y = Xβ + E.
Ответ на вопрос, нужно ли использовать инструментальные переменные, равносилен проверке гипотезы H0:  XTE = 0 (предел plim понимается в смысле сходимости по вероятности) против алтернативы H0:
XTE = 0 (предел plim понимается в смысле сходимости по вероятности) против алтернативы H0:  XTE ≠ 0. При наличии только n наблюдений проверить эту гипотезу нельзя. Предположим, что есть МНК-оценка вектора коэффициентов βМНК и оценка βИП, полученная с помощью инструментальных переменных. При нулевой гипотезе оценка βМНК состоятельна, а при альтернативной – нет. Оценка βИП состоятельна и при нулевой, и при альтернативной. Таким образом, при нулевой гипотезе разность βМНК - βИП стремится к нулю.
XTE ≠ 0. При наличии только n наблюдений проверить эту гипотезу нельзя. Предположим, что есть МНК-оценка вектора коэффициентов βМНК и оценка βИП, полученная с помощью инструментальных переменных. При нулевой гипотезе оценка βМНК состоятельна, а при альтернативной – нет. Оценка βИП состоятельна и при нулевой, и при альтернативной. Таким образом, при нулевой гипотезе разность βМНК - βИП стремится к нулю.
Хаусман показал, что величина (βИП - βМНК)Т(V(βИП) – V(βМНК))-1(βИП - βМНК) асимптотически имеет  -распределение с k степенями свободы, где
-распределение с k степенями свободы, где 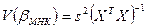 ,
,  ,
,  , X – матрица наблюдаемых значений факторов, Z – матрица значений инструментальных переменных.
, X – матрица наблюдаемых значений факторов, Z – матрица значений инструментальных переменных.
Поэтому если рассчитанное значение превышает критическое, нулевую гипотезу отклоняют, т.е. нужно использовать инструментальные переменные.
Вопрос 40 – Системы одновременных уравнений.
См. вопрос 17.
Вопрос 41 - Оценивание параметров структурной модели при отсутствии проблемы идентификации.
См. вопрос 17.
Вопрос 42 – Ряды динамики.
См. вопрос 35.
Вопрос 43 - Лаги и автокорреляция во временных рядах
Пусть исследуется показатель экономического процесса Y. Его значение в текущий момент (период) времени t обозначают yt;значения Yв последующие моменты можно тогда обозначить как yt+1, yt+2, …, yt+k, а в предыдущие моменты как yt-1, yt-2, …, yt-k.
При анализе таких показателей в качестве объясняющих переменных используются не только текущие значения переменных, но и некоторые предыдущие по времени значения, а также само время Т. Модели данного типа называют динамическими. Влияние предшествующих значенийисследуемого показателя на последующие приято называть автокорреляцией уровней динамического ряда.
Численной характеристикой такой автокорреляции является автокорреляционная функция, представляющая собой последовательность коэффициентов автокорреляции, рассчитываемых по зависимости

где
τ - порядок коэффициента автокорреляции, равный сдвигу во времени по уровням ряда;
 - средний уровень временного ряда.
- средний уровень временного ряда.
Сдвиг во времени называют лагом. Очевидно, что лаг, который следует принимать в расчет при анализе показателей процесса, определяется порядком коэффициента автокорреляции.
Рассчитав несколько коэффициентов автокорреляции, можно определить лаг, при котором автокорреляция наиболее высокая, выявив тем самым структуру временного ряда. Если наиболее высоким оказывается значение rt, t-1 , то исследуемый ряд содержит только тенденцию. Если наиболее высоким оказался rt, t-l, то ряд содержит (помимо тенденции) колебания периодом L. Если же ни один из коэффициентов не является значимым, то можно сделать одно из двух предположений:
• ряд не содержит тенденции и циклических колебаний, и его уровни определяются только случайной компонентой (в дальнейшем тогда проводится анализ на стационарность исследуемого процесса);
• ряд содержит сильную нелинейную тенденцию, для выявления и учета которой нужен многошаговый дополнительный анализ.
Временной ряд, отличающийся только тенденцией, можно выровнять в целях получения аналитического выражения для дальнейшего путем построения регрессионного уравнения. Наличие цикличности приводит к необходимости сглаживания с учетом сезонных эффектов.
Однако при анализе реальных экономических процессов часто приходится строить модели, содержащие и другие факторы помимо времени.
Факторы, которые проявляются с запаздыванием (по-английски -lag, откуда и пошел термин лаг) в бизнесе встречаются нередко. Например, капиталовложения в создание машиностроительного, автомобильного завода отразятся в росте объема производства не в том году, когда они произведены, а через два-три года, инвестиции в строительство крупной гидроэлектростанции - через 6-8 лет.
Причин наличия лагов в бизнесе достаточно много, и среди них можно выделить следующие.
Психологические причины, которые обычно выражаются через инерцию в поведении людей. Например, люди тратят свой доход постепенно, а не мгновенно. Привычка к определенному образу жизни приводит к тому, что люди приобретают те же блага в течение некоторого времени даже после падения реального дохода.
Технологические причины. Например, изобретение персональных компьютеров не привело к мгновенному вытеснению ими больших ЭВМ в силу необходимости замены соответствующего программного обеспечения, которое потребовало продолжительного времени.
Институциональные причины. Например, контракты между фирмами, трудовые договоры требуют определенного постоянства в течение времени контракта (договора).
Механизмы формирования экономических показателей. Например, инфляция во многом является инерционным процессом; денежный мультипликатор (создание денег в банковской системе) также проявляет себя на определенном временном интервале и т.д.
Переменные эконометрической модели, влияние которых характеризуется определенным запаздыванием, называются лаговыми переменными.
Динамические эконометрические модели, учитывающие запаздывание во влиянии факторов, подразделяют на два класса.
1. Модели с лагами (модели с распределенными лагами) — это модели, содержащие в качестве лаговых переменных лишь независимые (объясняющие) переменные. Примером является модель

2. Авторегрессионные модели — это модели, уравнения которых в качестве лаговых объясняющих переменных включают значения зависимых переменных. Примером может служить модель

Модели из первого класса при известном конечном числе лагов достаточно просто сводимы к уравнению множественной регрессии. Для этого полагают

и получают уравнение

После такого преобразования построение регрессионного уравнения осуществляется с помощью традиционного МНК. Сложность, однако, заключается в том, что этот подход предполагает полное отсутствие автокорреляции в остаточной последовательности, что, в свою очередь, означает идеальную спецификацию модели, на практике недостижимую. Вместе с тем явный смысл параметров такой модели делает проверку любых статистических данных об экономических процессах на автокорреляцию первым шагом аналитического исследования.
Вопрос 44 - Модели с распределенным лагом.
Модели с лагами (модели с распределенными лагами) — это модели, содержащие в качестве лаговых переменных лишь независимые (объясняющие) переменные. Примером является модель

В рамках данной модели отражается тот факт, что если в некоторый момент t происходит изменение независимой переменной х, то это изменение будет сказываться на значениях переменной у в течение p последующих периодов.
Коэффициент регрессии b0 при переменной хt, характеризует среднее абсолютное изменение у, при изменении хt на единицу своего измерения в фиксированный момент t без учета воздействия лаговых значений фактора х. Этот коэффициент называют краткосрочным мультипликатором.
В момент t + 1 совокупное воздействие факторной переменной х, на результат у составит уже  условных единиц и т.д. Поэтому такие суммы называют промежуточными мультипликаторами. С учетом конечной величины лага можно сказать, что изменение переменной хt в момент t на 1 у.е. приведет к общему изменению результата через p моментов времени на
условных единиц и т.д. Поэтому такие суммы называют промежуточными мультипликаторами. С учетом конечной величины лага можно сказать, что изменение переменной хt в момент t на 1 у.е. приведет к общему изменению результата через p моментов времени на  абсолютных единиц. Величину b называют долгосрочным мультипликатором.
абсолютных единиц. Величину b называют долгосрочным мультипликатором.
Предположим, что для промежуточных мультипликаторов за l периодов выполнимо соотношение
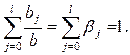
Отсюда следует, что относительные коэффициенты 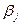 являются удельными весами для соответствующих значений краткосрочного мультипликатора в долгосрочном. Знание величин позволяет установить ожидаемый период
являются удельными весами для соответствующих значений краткосрочного мультипликатора в долгосрочном. Знание величин позволяет установить ожидаемый период
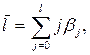
в течение которого будет происходить изменение результата под воздействием изменения фактора в момент времени t. Этот период называют также средним периодом воздействия.
Небольшая величина среднего лага свидетельствует о быстрой реакции результата на изменение фактора. Высокое же значение среднего лага свидетельствует о том, что воздействие фактора на результат будет сказываться постепенно и в течение длительного периода.
Поскольку на практике значение лага неизвестно, то изучение структуры лага и выбор вида уравнения с распределенным лагом рекомендуется проводить с последовательно увеличивающимся количеством лагов. Для завершения процедуры (принятия решения о величине лага) можно использовать следующие рекомендации:
• при добавлении нового лага какой-либо коэффициент регрессии 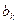 при переменной
при переменной  меняет знак. Тогда в уравнении регрессии оставляют переменные
меняет знак. Тогда в уравнении регрессии оставляют переменные  , т.е. те коэффициенты, при которых знак не поменялся;
, т.е. те коэффициенты, при которых знак не поменялся;
• при добавлении нового лага коэффициент регрессии при переменной становится статистически незначимым. Очевидно, что в уравнении будут использоваться только переменные  ,коэффициенты, при которых остаются статистически значимыми.
,коэффициенты, при которых остаются статистически значимыми.
Однако применение таких подходов весьма ограничено в силу постоянно уменьшающегося числа степеней свободы регрессии. Это сопровождается увеличением стандартных ошибок и ухудшением качества оценок для коэффициентов. Кроме того, возрастает вероятность мультиколлинеарности лаговых переменных. Наконец, неправильное определение количества лагов приводит к ошибкам спецификации.
Построение по МНК динамической модели в виде регрессии с распределенными лагами затрудняется следующими причинами.
Во-первых, текущие и лаговые значения независимой переменной, как правило, тесно связаны друг с другом. Тем самым оценка параметров модели проводится в условиях высокой мультиколлинеарности факторов.
Во-вторых, при большой величине лага уменьшается число наблюдений, по которому строится модель, и увеличивается число ее факторных признаков, что ведет к потере числа степеней свободы в модели.
В-третьих, в моделях с распределенным лагом часто возникает проблема автокорреляции остатков.
Указанные обстоятельства приводят к значительной неопределенности в оценках параметров модели и снижению точности моделирования. Чистое влияние факторов на результат в таких условиях выявить невозможно. Поэтому на практике параметры моделей с распределенным лагом учитывают определенные ограничения на коэффициенты регрессии и условия выбранной структуры лага.
Вопрос 45 - Модели с неизвестным лагом
Последовательное увеличение числа лагов, включаемых в модель(164), не эффективно ни с вычислительной, ни с содержательной точки зрения. Поэтому на практике изначально предполагают бесконечное число лагов и стараются либо найти критерий их ограничения, либо модифицировать исходную модель таким образом, чтобы избежать подбора величины лага.
Так в методе, предложенном Койком, предполагается, что коэффициенты  при лаговых значениях объясняющей переменной убывают в геометрической прогрессии. Таким образом, задается связь
при лаговых значениях объясняющей переменной убывают в геометрической прогрессии. Таким образом, задается связь

в которой выполняется неравенство  , что отражает скорость убывания коэффициентов с увеличением лага. Данное предположение достаточно логично, если считать, что влияние прошлых значений объясняющих переменных на текущее значение зависимой переменной со временем угасает.
, что отражает скорость убывания коэффициентов с увеличением лага. Данное предположение достаточно логично, если считать, что влияние прошлых значений объясняющих переменных на текущее значение зависимой переменной со временем угасает.
Такое представление позволяет исходную модель с распределенным лагом преобразовать в уравнение

Параметры данного уравнения  можно определить, например, путем присвоения параметру
можно определить, например, путем присвоения параметру  значений из интервала (0; 1) с произвольным фиксированным шагом ( 0,01; 0,001 или 0,0001). Для каждого из значений рассчитывается величина
значений из интервала (0; 1) с произвольным фиксированным шагом ( 0,01; 0,001 или 0,0001). Для каждого из значений рассчитывается величина

Значение лага р определяется из условия, что при дальнейшем добавлении лаговых значений X очередное изменении zt будетменьше некоторого наперед заданного числа. Затем по МНК оценивается уравнение регрессии

и из всех возможных значений выбирается то, при котором коэффициент детерминации R2 регрессии будет наибольшим. Найденные таким образом параметры  подставляются в уравнение:
подставляются в уравнение:
Однако более распространенной является схема вычислений, получившая название по фамилии автора метода: преобразование Койка.
Суть метода заключается в следующем.
Вычитая из уt такое же уравнение для предыдущего периода yt-1 , но умноженное на , т.е.

получим следующее соотношение:

где  - скользящая средняя между остатками
- скользящая средняя между остатками  и
и  .
.
Преобразование по данному методу и называется преобразованием Койка.
Отметим, что с помощью указанного преобразования уравнение с бесконечным числом лагов (с убывающими по степенному закону коэффициентами) преобразованов авторегрессионное уравнение, для которого требуется оценить лишь три коэффициента: . Это, кроме всего прочего, снимает одну из острых проблем моделей с лагами - проблему мультиколлинеарности.
Вместе с тем необходимо иметь в виду, что при применении преобразования Койка оценки, полученные по МНК, могут оказаться смещенными и несостоятельными.
Вопрос 46 – Сущность авторегрессионного преобразования
Для выявления автокорреляции в уравнении с лаговой зависимой переменной в качестве объясняющей вместо обычной статистики DW Дарбина-Уотсона необходимо использовать так называемую h-статистику Дарбина.
Модифицированная статистика Дарбина-Уотсона, или h–статистика Дарбина для предполагаемого регрессионного уравнении рассчитывается по формуле

где
 - оценка коэффициента автокорреляции первого порядка в остаточной последовательности ;
- оценка коэффициента автокорреляции первого порядка в остаточной последовательности ;
 - выборочная дисперсия при лаговой объясняющей переменной yt-1,
- выборочная дисперсия при лаговой объясняющей переменной yt-1,
n - число наблюдений.
При достаточно большом объеме выборки (n>20) нуль-гипотезу H0:  , т.е. об отсутствии автокорреляции, проверяют по нормальному распределению с заданной доверительной вероятностью (обычно 0,05). Если h>u(0,05), где u – аргумент функции Лапласа, то существование автокорреляции считается доказанным и возникает необходимость ее устранения.
, т.е. об отсутствии автокорреляции, проверяют по нормальному распределению с заданной доверительной вероятностью (обычно 0,05). Если h>u(0,05), где u – аргумент функции Лапласа, то существование автокорреляции считается доказанным и возникает необходимость ее устранения.
Устранение означает переход модели, в которой остаточная последовательность подчиняется предпосылкам МНК, в первую очередь о некоррелированности ее членов и равенстве нулю их математического ожидания.
Если имеется автокорреляция только первого порядка и известен коэффициент , т.е. имеет место

автокорреляцию можно устранить и получить оценки регрессии в модели с бесконечным числом лагов. В этом и состоит суть авторегрессионного преобразования.
Для коррекции устранения автокорреляции можно преобразовать исходные данные следующим образом:
 .
.
При этом для первого наблюдения применяется поправка Прайса-Уинстена – данные первого наблюдения умножаются на  . Далее с помощью обыкновенного метода наименьших квадратов оцениваются параметры уравнения:
. Далее с помощью обыкновенного метода наименьших квадратов оцениваются параметры уравнения:
 .
.
Переход к коэффициентам изучаемой регрессии осуществляется по формулам:
 .
.
В принципе изложенная схема может быть обобщена на автокорреляцию более высокого порядка, т.е. получены преобразования AR(2), AR(3) и т.д.
Оценить коэффициент автокорреляции можно, непосредственно построив регрессию
 .
.
Также возможно оценить его с помощью значения статистики Дарбина-Уотсона:
 , тогда
, тогда  .
.
По методу Хилдрета—Лу регрессия оценивается для каждого возможного значения ρ из отрезка [—1, 1] с любым шагом (например, 0,001; 0,01 и т.д.). Величина, дающая наименьшую стандартную ошибку регрессии, принимается в качестве оценки коэффициента авторегрессии. После этого значения  оцениваются из уравнения регрессии именно с данным значением ρ.
оцениваются из уравнения регрессии именно с данным значением ρ.
Этот итерационный метод широко используется в пакетах прикладных программ.
|
из
5.00
|
Обсуждение в статье: Тест Гольдфельда-Квандта |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы