 |
Главная |


ПРАКТИКУМ ПО ЭКОНОМЕТРИКЕ
|
из
5.00
|
учебное пособие для студентов специальностей
080109– «Бухгалтерский учет, анализ и аудит»
080105– «Финансы и кредит»
Краснодар 2014
УДК 330.43(075.5)
ББК 65в631я73
П69
Рецензенты:
С.И. Берлин
(дэн, профессор - зав. кафедрой)
Грачёв И.С., Практикум по эконометрике: Учебное пособие. Краснодар: типография ЮИМ « », 2014. – 63 с.
Дано краткое систематическое изложение разделов государственного образовательного стандарта по эконометрике – множественная регрессия, статистический анализ экономических временных рядов и системы одновременных эконометрических уравнений. Практикум обеспечивает методическую поддержку практических занятий. Содержит краткие методические указания, решение типовых задач, описание реализации на компьютере с помощью прикладной программы EXCEL.
Предназначено для студентов и аспирантов высших учебных заведений экономических специальностей, ориентированных на прикладные задачи моделирования и прогнозирования в экономике.
Оглавление
Лабораторная работа №1. Изучение возможностей Excel для получения и анализа уравнений множественной регрессии. 6
Лабораторная работа №2. Построение модели множественной регрессии со статистически значимыми факторами. 21
Лабораторная работа №3. Устранение гетероскедастичности и автокорреляции в остатках. 35
Лабораторная работа №4. Проверка однородности данных. Уравнение регрессии с фиктивными переменными. 43
Лабораторная работа №5. Построение автокорреляционной функции и коррелограммы. 50
Лабораторная работа №6. Выявление структуры одномерного временного ряда. 61
Лабораторная работа №7. Моделирование взаимосвязей по временным рядам 80
Лабораторная работа №8. Модели с распределенным лагом. Метод Алмон. 90
Лабораторная работа №9. Изучение двухшагового метода наименьших квадратов. 96
Лабораторная работа №1. Изучение возможностей Excel для получения и анализа уравнений множественной регрессии.
Для проведения эконометрической обработки исходных данных табличный процессор Microsoft Excel включает в себя программную надстройку «Пакет анализа» и библиотеку из 78 статистических функций. Если же пользователя не удовлетворяют возможности Excel,тогда необходимо обратиться к более мощным специализированным пакетам прикладных программ, как отечественные – STADIA, МЕЗОЗАВР, СИГАМД, СТОД, САНИ, ОЛИМП и др., так и зарубежные – Econometric Views, STATA, STATISTICA, STATGRAPHICS, SPSS, SAS, BMDP,NCSS, StatXact и др.
Рассмотрим некоторые аспекты работы с табличным процессором Excel,которые позволяют упростить расчеты, необходимые для решения эконометрических задач. Табличный процессор – это программный продукт, предназначенный для автоматизации обработки данных табличной формы.
Элементы экрана Excel.После запуска Excelна экране появляется таблица, вид которой показан на рис. 1.1.
Это изображение называется рабочим листом. Оно представляет собой сетку строк и столбцов, пересечения которых образуют прямоугольники, называемые ячейками. Рабочие листы предназначены для ввода данных, выполнения расчетов, организации информационной базы и т.п. В каждый конкретный момент времени активным может быть только один рабочий лист. Окно Excel отображает основные программные элементы: строку заголовка, строку меню, строку состояния, кнопки управления окнами.
При создании новой или открытии существующей книги Microsoft Excel появится окно активного рабочего листа. Для того, чтобы отыскать команду вызова надстройки Пакет анализа, необходимо воспользоваться меню Сервис.
Здесь возможны три ситуации, в которых нужно действовать следующим образом:
1. В меню Сервисприсутствует команда Анализ данных. Это идеальный случай - достаточно щелкнуть указателем мыши по данной команде, чтобы попасть в окно надстройки.
2. В меню Сервисотсутствует команда Анализ данных.В этом случаенеобходимо в том же меню выполнить командуНадстройки.Раскроется одноименное окно (рис. 1.2.) со списком доступных надстроек. В этом списке нужно найти элемент Пакет анализа, поставить рядом с ним «галочку» и щелкнуть по кнопке ОК. После этого в меню Сервис появится команда Анализ данных.
3. В меню Сервисотсутствует команда Анализ данных,а в списке окна Надстройки нет элемента Пакет анализа. В этом случае придется доустановить надстройку Excel (Пакет анализа)с дистрибутивного компакт-диска Microsoft Office.
Рис. 1.1.
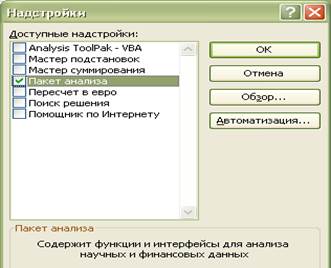
Рис. 1.2.
Рассмотрим пример построения модели множественной регрессии с помощью Excel.
Пример №1.
По данным за два года изучается зависимость оборота розничной торговли (Y, млрд. руб.) от ряда факторов: X1 – денежные доходы населения, млрд. руб.; X2 – доля доходов, используемая на покупку товаров и оплату услуг, млрд. руб.; X3 – уровень инфляции за последний год, %; X4 – официальный курс рубля по отношению к доллару США. Данные представлены в табл. 1.
Таблица 1
| Месяц | Y | X1 | X2 | X3 | X4 |
| 76,4 | 117,7 | 81,6 | 10,3 | 28,5 | |
| 77,6 | 123,8 | 73,2 | 11,4 | 28,7 | |
| 88,2 | 126,9 | 75,3 | 12,2 | 29,1 | |
| 87,3 | 134,1 | 71,3 | 11,5 | 29,2 | |
| 82,5 | 123,1 | 77,3 | 11,2 | 29,1 | |
| 79,4 | 126,7 | 76,1 | 10,5 | 29,2 | |
| 80,3 | 130,4 | 76,6 | 9,4 | 29,3 | |
| 80,1 | 129,3 | 84,7 | 9,5 | 29,2 | |
| 105,2 | 145,4 | 92,4 | 9,3 | 29,1 | |
| 102,5 | 163,8 | 80,3 | 9,2 | 28,7 | |
| 108,7 | 164,8 | 82,6 | 9,4 | 28,4 | |
| 104,5 | 165,3 | 70,9 | 9,7 | 27,8 | |
| 103,7 | 164,1 | 89,9 | 8,2 | 27,7 | |
| 117,8 | 183,7 | 81,3 | 8,4 | 27,6 | |
| 115,8 | 195,8 | 83,7 | 8,2 | 27,5 | |
| 117,8 | 219,4 | 76,1 | 8,1 | 27,5 | |
| 118,4 | 209,8 | 80,4 | 7,8 | 27,4 | |
| 120,4 | 223,3 | 78,1 | 7,2 | 27,5 | |
| 123,8 | 223,6 | 79,8 | 8,2 | 27,6 | |
| 134,9 | 236,6 | 82,1 | 7,5 | 27,7 | |
| 130,5 | 236,6 | 83,2 | 7,4 | 27,8 | |
| 140,7 | 248,6 | 80,8 | 7,3 | 28,7 | |
| 150,4 | 253,4 | 81,8 | 7,4 | 28,3 | |
| 172,7 | 254,3 | 87,5 | 7,5 | 28,1 |
Требуется:
1. Для заданного набора данных построить линейную модель множественной регрессии.
2. Оценить адекватность и значимость построенного уравнения регрессии.
3. Выделить значимые и незначимые факторы в модели.
4. Построить уравнение регрессии со статистически значимыми факторами. Дать экономическую интерпретацию параметров модели.
Решение
Запишем исходные данные (табл.1) в виде таблицы EXCEL, как это сделано на рис.1.3.
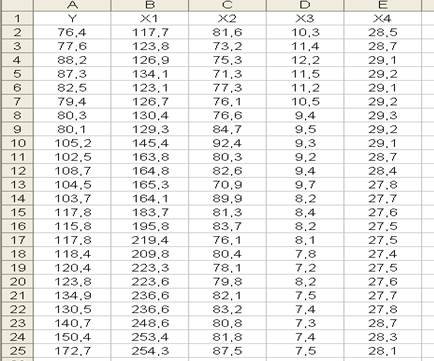
Рис. 1.3.
Для решения задачи необходимо выполнить следующие действия:
1. В меню Сервис выбираем строку Анализ данных. На экране появится окно
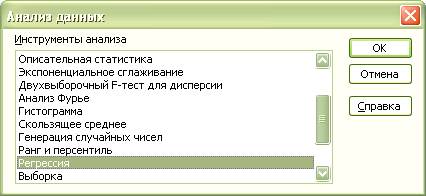
Рис. 1.4.
В появившемся окне выбираем пункт Регрессия. Появляется диалоговое окно рис.1.5.
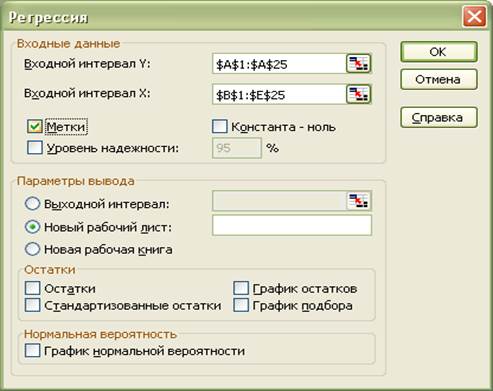
Рис. 1.5.
2. Диалоговое окно рис.1.5. заполняется следующим образом:
Входной интервал 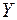 – диапазон (столбец), содержащий данные со значениями объясняемой переменной;
– диапазон (столбец), содержащий данные со значениями объясняемой переменной;
Входной интервал 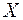 – диапазон (столбцы), содержащий данные со значениями объясняющих переменных.
– диапазон (столбцы), содержащий данные со значениями объясняющих переменных.
Метки – флажок, который указывает, содержат ли первые элементы отмеченных диапазонов названия переменных (столбцов) или нет;
Константа-ноль - флажок, указывающий на наличие или отсутствие свободного члена в уравнении ( 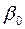 );
);
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона, в котором будет сохранен отчет по построению модели;
Новый рабочий лист – можно задать произвольное имя нового листа, в котором будет сохранен отчет.
Если необходимо получить значения и графики остатков ( 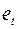 ), установите соответствующие флажки в диалоговом окне. Нажмите на кнопку Ok.
), установите соответствующие флажки в диалоговом окне. Нажмите на кнопку Ok.
Вид отчета о результатах регрессионного анализа представлен на рис.1.6.
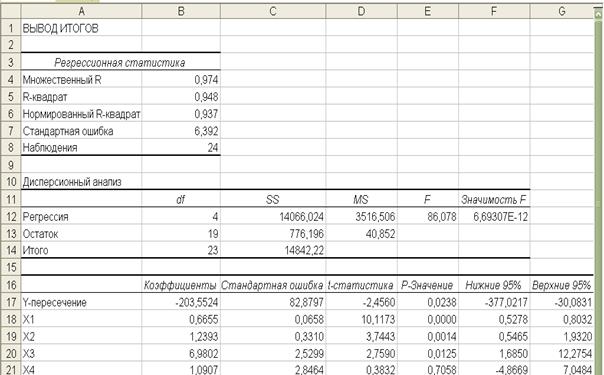
Рис. 1.6.
Рассмотрим таблицу «Регрессионная статистика»
Множественный R – это 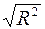 , где
, где 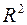 – коэффициент детерминации.
– коэффициент детерминации.
R-квадрат - это . Коэффициент является одной из наиболее эффективных оценок адекватности регрессионной модели, мерой качества уравнения регрессии (или, как говорят, мерой качества подгонки регрессионной модели к наблюденным значениям 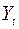 )
)
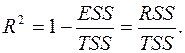
Величина показывает, какая часть (доля) вариации объясняемой переменной обусловлена вариацией объясняющей переменной ( 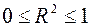 ). Чем ближе к единице, тем лучше регрессия аппроксимирует эмпирические данные. Если
). Чем ближе к единице, тем лучше регрессия аппроксимирует эмпирические данные. Если 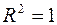 , то между и существует линейная функциональная зависимость. Если
, то между и существует линейная функциональная зависимость. Если 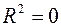 , то объясняемая переменная не зависит от данного набора объясняющих переменных.
, то объясняемая переменная не зависит от данного набора объясняющих переменных. 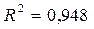 свидетельствует о том, что изменения зависимой переменной ( оборот розничной торговли) в основном (на 94,8%) можно объяснить изменениями включенных в модель объясняющих переменных – X1, X2, X3, X4. Такое значение свидетельствует об адекватности модели.
свидетельствует о том, что изменения зависимой переменной ( оборот розничной торговли) в основном (на 94,8%) можно объяснить изменениями включенных в модель объясняющих переменных – X1, X2, X3, X4. Такое значение свидетельствует об адекватности модели.
Нормированный R-квадрат – скорректированный (адаптированный, поправленный(adjusted)) коэффициент детерминации.
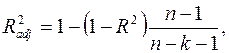
где 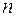 – число наблюдений,
– число наблюдений, 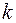 – число объясняющих переменных.
– число объясняющих переменных.
Недостатком коэффициента детерминации является то, что он увеличивается при добавлении новых объясняющих переменных, хотя это и не обязательно означает улучшение качества регрессионной модели. В этом смысле предпочтительнее использовать 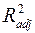 . В отличие от скорректированный коэффициент может уменьшаться при введении в модель новых объясняющих переменных, не оказывающих существенное влияние на зависимую переменную.
. В отличие от скорректированный коэффициент может уменьшаться при введении в модель новых объясняющих переменных, не оказывающих существенное влияние на зависимую переменную.
Стандартная ошибка регрессии 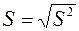 , где
, где 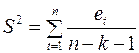 – необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
– необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
Наблюдения – число наблюдений.
Рассмотрим таблицу «Дисперсионный анализ»
Поясним заголовки столбцов этой таблицы:
df – degrees of freedom – число степеней свободы связано с числом единиц совокупности и с числом определяемых по ней констант ;
SS – сумма квадратов (регрессионная – RSS, остаточная – ESS и общая - TSS);
MS- сумма квадратов на одну степень свободы;
F – вычисленное значение критерия Фишера (F-статистики);
Значимость F – уровень значимости, при котором вычисленное значение критерия Фишера является критической точкой распределения Фишера. Нулевая гипотеза о незначимости (Н0: β=0) уравнения регрессии отклоняется, если это значение меньше заданного уровня значимости. Значимость F- значение уровня значимости, соответствующее вычисленному значению F-критерия Фишера.
F и Значимость F позволяют проверить значимость уравнения регрессии, т.е. установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включенных в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной.
По эмпирическому значению статистики F проверяется гипотеза равенства нулю одновременно всех коэффициентов модели. Значимость F – теоретическая вероятность того, что при гипотезе равенства нулю одновременно всех коэффициентов модели F-статистика больше эмпирического значения F.
Уравнение регрессии значимо на уровне 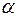 , если
, если 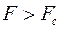 , где
, где 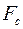 - табличное значение F-критерия Фишера (
- табличное значение F-критерия Фишера ( 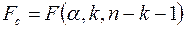 ).
).
На уровне значимости 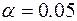 гипотеза
гипотеза 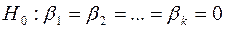 отвергается, если Значимость
отвергается, если Значимость 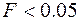 , и принимается, если Значимость
, и принимается, если Значимость 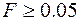 .
.
В нашем примере расчетное значение F- критерия Фишера равно 86,078. Значимость F= 6,69307E-12, что намного меньше 0,05. Таким образом, полученное уравнение в целом значимо.
В последней таблице (табл. 1, рис.1.6.) приведены значения параметров (коэффициентов) модели, их стандартные ошибки и расчетные значения t- критерия Стъюдента для оценки значимости отдельных параметров модели.
Таблица 1
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | |
| Y- | -203,5524 | 82,8797 | -2,4560 | 0,0238 | 377,0217 | -30,0831 |
| X1 | 0,6655 | 0,0658 | 10,1173 | 0,0000 | 0,5278 | 0,8032 |
| X2 | 1,2393 | 0,3310 | 3,7443 | 0,0014 | 0,5465 | 1,9320 |
| X3 | 6,9802 | 2,5299 | 2,7590 | 0,0125 | 1,6850 | 12,2754 |
| X4 | 1,0907 | 2,8464 | 0,3832 | 0,7058 | -4,8669 | 7,0484 |
В строке с именем «Y-пересечение» приводятся:
· оценка коэффициента b0;
· его стандартная ошибка mb0;
· вычисленное значение t-статистики для b0;
· P-значение, – вероятность того, что случайная величина распределенная по закону t(n-2) примет значение по абсолютной величине больше, чем модуль вычисленного значения t-статистики, т.е. P-значение это уровень значимости, при котором вычисленное значение t-статистики является критической точкой, следовательно, нулевая гипотеза 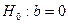 отклоняется, если P-значение меньше заданного уровня значимости, и принимается в противном случае;
отклоняется, если P-значение меньше заданного уровня значимости, и принимается в противном случае;
· нижняя и верхняя границы 95%-о доверительного интервала для b0.
В строках с именем «X» приводятся аналогичные данные для коэффициентов bk уравнения регрессии.
Таким образом, получена следующая модель зависимости оборота розничной торговли:
Y = -203,6 + 0,67X1 + 1,24X2 + 6,98X3 + 1,09X4 (1)
Анализ таблицы для рассматриваемого примера позволяет сделать вывод о том, что на уровне значимости α=0,05 незначимым оказался коэффициент при факторе X4, так как:
1) t–статистика (tp=0,38) для b4 меньше 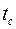 =2,08 – критическая точка распределения Стьюдента,
=2,08 – критическая точка распределения Стьюдента, 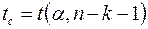 ;
;
2) Р – значение (P=0,7) больше 0,05;
3) Границы доверительного интервала для b4 содержит противоречивые результаты (-4,87 ≤ b4 ≤ 7,05), значения коэффициента одновременно содержат положительные и отрицательные величины и даже ноль, чего не может быть.
Проведенное исследование успешности параметров уравнения регрессии позволяет исключить несущественный фактор Х4 и построить уравнение зависимости Y= f(x1,x2,x3).
Лабораторная работа №2. Построение модели множественной регрессии со статистически значимыми факторами
Пример №2.
Используя исходные данные из примера №1 (рис.1.7.)
Требуется:
1. Построить модели множественной регрессии со статистически значимыми факторами.
2. Оценить гетероскедастичность дисперсии остатков.
3. Определить наличие автокорреляции остатков с помощью теста
Дарбина-Уотсона.
Решение
1. Исключим несущественный фактор Х4 (официальный курс рубля по отношению к доллару США) и построим уравнение зависимости
Y – оборот розничной торговли, млрд. руб.
от объясняющих переменных
X1 – денежные доходы населения, млрд. руб.;
X2 – доля доходов, используемая на покупку товаров и оплату услуг, млрд. руб.;
X3 – численность безработных, млн. чел.
Для оценки уравнения множественной регрессии в строке главного меню щелкнем на Сервиси в предложенном меню выберем Анализ данных.В предложенном списке инструментов анализа выберем Регрессия. В появившемся окне «Регрессия» укажем входные данные для оценки параметров регрессии, выводимые результаты и их расположение.
Заполнение окна «Регрессия» для рассматриваемого примера приведено на рис.1.5. (порядок построения уравнения регрессии аналогичен примеру №1). Результаты регрессионного анализа представлены на рис. 1.8.
Модель зависимости оборота розничной торговли запишется в следующем виде:
Y = -178,5 + 0,67X1 + 1,27X2 + 7,36X3 (2)
Оценим адекватность и значимость уравнения (2) по-сравнению с уравнением (1).
Из таблиц (рис. 1.6., 1.8.) видно, что значение коэффициента детерминации (R2) осталось на прежнем уровне, возросло значение скорректированного коэффициента детерминации (нормированный R2 ), следовательно, можно сделать ввод об адекватности модели.
Стандартная ошибка регрессии для второго уравнения меньше, чем для первого (6,254<6,392). Расчетное значение F-критерия Фишера увеличилось на 31,8. Значимость F=5,96E-13, что меньше 0,05, таким образом, полученное уравнение в целом значимо. Также можно сделать вывод о том, что все включенные в модель факторы являются значимыми, так как их Р-значение < 0,05 и границы доверительных интервалов не содержат противоречивых значений.
Экономическая интерпретация параметров модели.
Коэффициент b1 = 0,67, означает, что при увеличении только денежных доходов населения (Х1) на 1 тыс. руб. оборот розничной торговли возрастет на 0,67 тыс. руб., а то что коэффициент b2 = 1,27, означает, что увеличение только доли доходов, используемых на покупку товаров и оплату услуг на 1 тыс. руб., оборот розничной торговли возрастет на 1,27 тыс. руб. при условии неизменности других двух факторов, коэффициент b3 = 7,36, означает, что при увеличении только уровня инфляции на 1%, оборот розничной торговли возрастет на 7,36 млрд. руб. при условии неизменности других двух факторов.
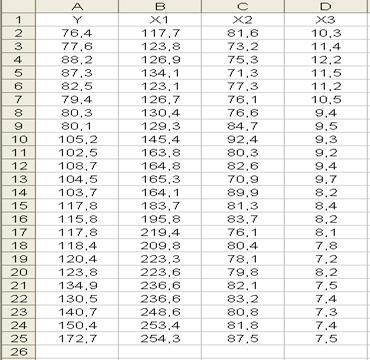
Рис. 1.7.
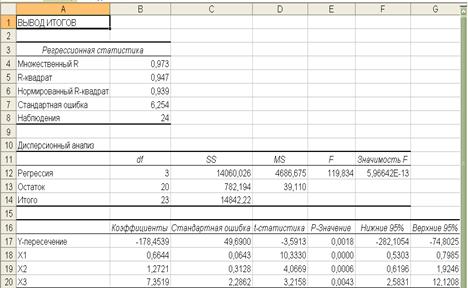
Рис. 1.8.
2. Оценить гетероскедастичность дисперсии остатков.
Одной из предпосылок МНК является условие постоянства дисперсий случайных отклонений.
Гомоскедастичность – дисперсия каждого отклонения 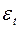 одинакова для всех значений Х.
одинакова для всех значений Х.
Гетероскедастичность – дисперсия объясняемой переменной (а следовательно, и случайных ошибок) не постоянна.
В тестах на гетероскедастичность проверяется основная гипотеза 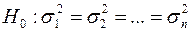 (т.е. модель гомоскедастична) против альтернативной гипотезы
(т.е. модель гомоскедастична) против альтернативной гипотезы 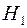 : не
: не 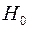 (т.е. модель гетероскедастична).
(т.е. модель гетероскедастична).
Тест Гольдфельда – Квандта (Goldfeld – Quandt).
Этот тест применяется, как правило, когда есть предположение о прямой зависимости дисперсии ошибок от величины некоторой объясняющей переменной, входящей в модель.
Предполагается, что 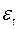 имеет нормальное распределение. Тест включает в себя следующие шаги:
имеет нормальное распределение. Тест включает в себя следующие шаги:
Упорядочить данные по убыванию (или по возрастанию) той независимой переменной, относительно которой есть подозрение на гетероскедастичность.
Исключить 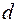 средних (в этом упорядочении) наблюдений (
средних (в этом упорядочении) наблюдений ( 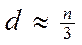 ), где – общее количество наблюдений).
), где – общее количество наблюдений).
Провести две независимых регрессии первых 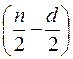 наблюдений и последних наблюдений и найти, соответственно,
наблюдений и последних наблюдений и найти, соответственно, 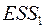 и
и 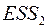 . Из и выбираем большую и меньшую величины, соответственно,
. Из и выбираем большую и меньшую величины, соответственно, 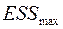 и
и 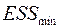 .
.
Составить статистику 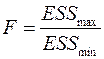 и найти по распределению Фишера
и найти по распределению Фишера 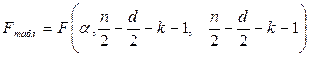 , где – число объясняющих переменных модели.
, где – число объясняющих переменных модели.
Если 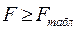 , то гипотеза отвергается, т.е. модель гетероскедастична, а если
, то гипотеза отвергается, т.е. модель гетероскедастична, а если 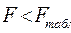 , то гипотеза принимается, т.е. модель гомоскедастична.
, то гипотеза принимается, т.е. модель гомоскедастична.
Тест выполнен для данных примера 2. Вначале данные упорядочиваем в порядке возрастания переменной 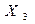 (рис. 1.9.). В данном случае
(рис. 1.9.). В данном случае
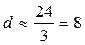 ;
; 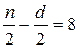
Результаты дисперсионного аназиза модели множественной регрессии, включающей восемь первых и восемь последних наблюдений (после ранжирования переменной 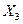 ), приведены в табл.2,3, соответственно.
), приведены в табл.2,3, соответственно.
F = 191,24 / 15,14 = 12,63.
Для того, чтобы узнать табличное значение, воспользуемся встроенной в EXCEL функцией FРАСПОБР с уровнем значимости α = 0,05.
Fтабл = FРАСПОБР(0,05;4;4)=6,39
Статистика F> Fтабл , следовательно, модель гетероскедастична.
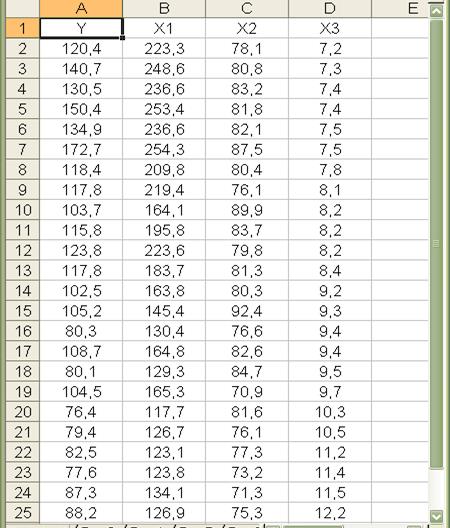
Рис.1.9.
Таблица 2
| Дисперсионный анализ | |||||
| df | SS | MS | F | Значимость F | |
| Регрессия | 2300,313646 | 766,7712153 | 16,03777006 | 0,010759656 | |
| Остаток | 191,241354 | 47,8103385 | |||
| Итого | 2491,555 |
Таблица 3
| Дисперсионный анализ | |||||
| df | SS | MS | F | Значимость F | |
| Регрессия | 568,9774082 | 189,6591361 | 50,09951753 | 0,001249136 | |
| Остаток | 15,14259182 | 3,785647955 | |||
| Итого | 584,12 |
3. Определить наличие автокорреляции остатков с помощью теста
Дарбина-Уотсона.
Этот тест используется для обнаружения автокорреляции первого порядка, т.е. проверяется некоррелированность не любых, а только соседних величин 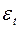 . Соседними обычно считаются соседние во времени (при рассмотрении временных рядов) или по возрастанию объясняющей переменной значения .
. Соседними обычно считаются соседние во времени (при рассмотрении временных рядов) или по возрастанию объясняющей переменной значения .
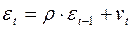
Гипотеза 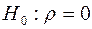 (автокорреляция отсутствует).
(автокорреляция отсутствует).
Общая схема критерия Дарбина – Уотсона следующая:
1) По эмпирическим данным построить уравнение регрессии по МНК и определить значения отклонений 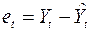 для каждого наблюдения t (t = 1, 2, …, n). (Для этого в диалоговом окне Регрессия установить флажок на функцию Остатки).
для каждого наблюдения t (t = 1, 2, …, n). (Для этого в диалоговом окне Регрессия установить флажок на функцию Остатки).
2) Рассчитать статистику DW:
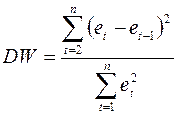
3) По таблице критических точек распределения Дарбина –Уотсона для заданного уровня значимости , числа наблюдений и количества объясняющих переменных определить два значения: 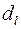 - нижняя граница и
- нижняя граница и 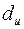 - верхняя граница (таблица 4).
- верхняя граница (таблица 4).
4) Сделать выводы по правилу:
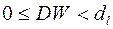 - существует положительная автокорреляция (
- существует положительная автокорреляция ( 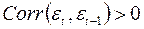 ),
), 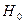 отвергается;
отвергается;
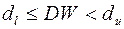 - вывод о наличии автокорреляции не определен;
- вывод о наличии автокорреляции не определен;
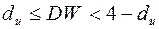 - автокорреляция отсутствует, принимается;
- автокорреляция отсутствует, принимается;
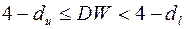 - вывод о наличии автокорреляции не определен;
- вывод о наличии автокорреляции не определен;
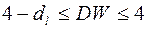 - существует отрицательная автокорреляция (
- существует отрицательная автокорреляция ( 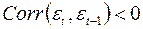 ), отвергается.
), отвергается.
Таблица 4.
| Статистика Дарбина – Уотсона, уровень значимости 0,05 | ||||||||||
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
| 1,20 | 1,41 | 1,1 | 1,54 | 1,00 | 1,67 | 0,90 | 1,83 | 0,79 | 1,99 | |
| 1,22 | 1,42 | 1,13 | 1,54 | 1,03 | 1,66 | 0,93 | 1,81 | 0,83 | 1,96 | |
| 1,24 | 1,43 | 1,15 | 1,54 | 1,05 | 1,66 | 0,96 | 1,80 | 0,86 | 1,94 | |
| 1,26 | 1,44 | 1,17 | 1,54 | 1,08 | 1,66 | 0,99 | 1,79 | 0,90 | 1,92 | |
| 1,27 | 1,45 | 1,19 | 1,55 | 1,10 | 1,66 | 1,01 | 1,78 | 0,93 | 1,90 | |
| 1,29 | 1,45 | 1,21 | 1,55 | 1,12 | 1,66 | 1,04 | 1,77 | 0,95 | 1,89 |
Тест проводится на исходных данных примера 2 (рис.1.7.). Для проведения теста надо поставить флажок «Остатки» в параметрах Регрессии. Отчет по регрессии приведен на рис. 1.8. Данные для теста по остаткам приведены в таблице 5. Сумма 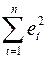 равна
равна 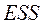 рис.1.8. Таким образом, получаем, что
рис.1.8. Таким образом, получаем, что 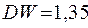 . По таблице при
. По таблице при 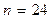 и
и 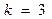 находим
находим 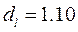 и
и 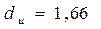 .
.
Следовательно, в рассматриваемом примере 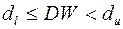 . Таким образом, вывод о наличии автокорреляции не определен.
. Таким образом, вывод о наличии автокорреляции не определен.
Таблица 5
| Наблюдение | Предсказанное Y | Остатки et | et-1 | (et- et-1)^2 | (et)^2 |
| 79,27 | -2,87 | 8,26 | |||
| 80,73 | -3,13 | -2,87 | 0,06 | 9,79 | |
| 91,34 | -3,14 | -3,13 | 0,00 | 9,87 | |
| 85,89 | 1,41 | -3,14 | 20,71 | 1,99 | |
| 84,01 | -1,51 | 1,41 | 8,52 | 2,28 | |
| 79,73 | -0,33 | -1,51 | 1,39 | 0,11 | |
| 74,74 | 5,56 | -0,33 | 34,73 | 30,97 | |
| 85,04 | -4,94 | 5,56 | 110,43 | 24,44 | |
| 104,07 | 1,13 | -4,94 | 36,95 | 1,29 | |
| 100,16 | 2,34 | 1,13 | 1,45 | 5,46 | |
| 105,22 | 3,48 | 2,34 | 1,30 | 12,09 | |
| 92,88 | 11,62 | 3,48 | 66,36 | 135,09 | |
| 105,22 | -1,52 | 11,62 | 172,79 | 2,32 | |
| 108,77 | 9,03 | -1,52 | 111,25 | 81,46 | |
| 118,40 | -2,60 | 9,03 | 135,07 | 6,74 | |
| 123,67 | -5,87 | -2,60 | 10,74 | 34,49 | |
| 120,56 | -2,16 | -5,87 | 13,79 | 4,66 | |
| 122,19 | -1,79 | -2,16 | 0,14 | 3,21 | |
| 131,91 | -8,11 | -1,79 | 39,86 | 65,70 | |
| 138,32 | -3,42 | -8,11 | 21,93 | 11,71 | |
| 138,99 | -8,49 | -3,42 | 25,65 | 72,01 | |
| 143,17 | -2,47 | -8,49 | 36,19 | 6,10 | |
| 148,37 | 2,03 | -2,47 | 20,28 | 4,13 | |
| 156,95 | 15,75 | 2,03 | 188,12 | 248,02 | |
| сумма | 1057,70 | 782,19 |
Лабораторная работа №3. Устранение гетероскедастичности и автокорреляции в остатках.
1. Устранение гетероскедастичности.
Как известно, гетероскедастичность приводит к неэффективности оценок. Это может обусловить необоснованные выводы по качеству модели.
Пример №3.
Используя исходные данные из примера №2 (рис.1.7.)
Требуется:
Обобщенным методом наименьших квадратов (ОМНК) оценить параметры модели, тем самым, устранить гетероскедастичность.
В рассматриваемом примере данный метод применяется при известных для каждого наблюдения дисперсиях σi2 отклонений εi , i=1, 2, ……,n. В этом случае можно устранить гетероскедастичность, разделив каждое наблюдаемое значение на соответствующее ему значение среднего квадратического отклонения σi и поэтому в данном примере ОМНК можно назвать взвешенным методом наименьших квадратов.
Решение
С помощью надстройки Excel Анализ данныхпо аналогиис примером №2 надо поставить флажок «Остатки» в параметрах Регрессиии получить значения остатков (табл. 5, столбец 3). Далее выполним расчеты в следующей последовательности (рис.1.10.):
1) в ячейку F27 поместить формулу =СРЗНАЧ(F2:F25) рассчитывающую среднюю арифметическую значений, заданных в списке аргументов;
2) в ячейку G2 поместить формулу =F2-$F$27 и с помощью процедуры автозаполнение распространить ее на ячейки диапазона G2:G25;
3) в ячейку I2 поместить формулу =A2/$G2 и с помощью процедуры автозаполнение распространить ее на ячейки диапазона I2:M25, тем самым, каждое значение исходной выборки A2:D25 (рис.1.7.) будет разделено на σi ;
4) по МНК для преобразованных значений 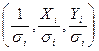 построить уравнение регрессии без свободного члена с гарантированным качеством оценок. Введем новые обозначения
построить уравнение регрессии без свободного члена с гарантированным качеством оценок. Введем новые обозначения
Z=1/ σi, Yi*=1/ σi, Xi*=1/ σi, рассчитаем, по известному алгоритму, параметры уравнения регрессии (рис. 1.11.) и запишем
Y* = -193,1 Z + 0,67 X1* + 1,34 X2* + 8,02 X3*,
где мы получили коэффициенты при переменных с несмещенными стандартными ошибками;
5) возвращаемся к начальному виду уравнения
Y = -193,1 + 0,67 X1 + 1,34 X2 + 8,02 X3
6) для новых данных (рис.1.10) выполним тест Тест Гольдфельда – Квандта (см. лабораторная работа №2). Значение F-статистики равно 2,2. Fтабл= 6,39.
Статистика F< Fтабл , следовательно, модель гомоскедастична.
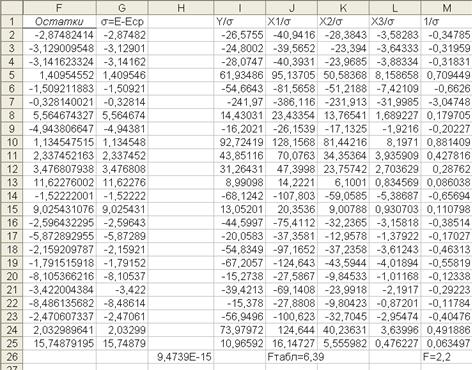
Рис. 1.10.
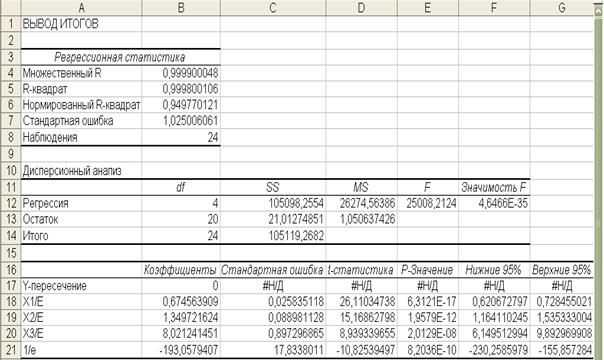
Рис.1.11.
2. Устранение автокорреляции в остатках.
Для устранения автокорреляции (как и в случае с гетероскедастичностью) можно воспользоваться обобщенным методом наименьших квадратов (ОМНК). Для применения ОМНК необходимо специфицировать модель автокорреляции регрессионных остатков. Обычно в качестве такой модели используется авторегрессионный процесс первого порядка.
Пример №4
Воспользуемся исходными данными и результатами лабораторной работы №2 (рис 1.7., табл.5), в которой после применения теста Дарбина-Уотсона гипотеза об отсутствии автокорреляции остатков не может быть ни принята, ни отвергнута. Следует заметить, что в этом случае на практике предполагают существование автокорреляции в остатках.
Требуется:
Обобщенным методом наименьших квадратов (ОМНК) оценить параметры модели, тем самым, устранить автокорреляцию в остатках.
Решение
Вначале определим преобразованные значения объясняемой переменной и объясняющих переменных (рис.1.12.) с применением следующих формул:
Yi*= Yi - ρ Yi-1, Xi*= Xi – ρ Xi-1, где
i=2,…,n,
ρ – коэф
|
из
5.00
|
Обсуждение в статье: ПРАКТИКУМ ПО ЭКОНОМЕТРИКЕ |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы