 |
Главная |


ИНДИВИДУАЛЬНЫЕ ЗАДАНИЯ ДЛЯ САМОСТОЯТЕЛЬНОЙ РАБОТЫ
|
из
5.00
|
Методические указания
Необходимо разработать программу моделирования нейронной сети для решения конкретной задачи в Neural Network Toolbox системы MATLAB.
Прежде всего, необходимо провести анализ задания и разобраться с исходными данными. Исходные данные, указанные в каждом задании, берутся из Репозитория UCI (UCI Machine Learning Repository http://mlr.cs.umass.edu/ml/). UCI — это крупнейший репозиторий реальных и модельных задач машинного обучения, созданный в университете г. Ирвайн (Калифорния, США). Содержит реальные данные по прикладным задачам в области биологии, медицины, физики, техники, социологии, и др. Задачи (наборы данных, data set) этого репозитория чаще всего используются научным сообществом для эмпирического анализа алгоритмов машинного обучения. Краткое описание репозитория на русском языке можно найти здесь: http://www.machinelearning.ru/wiki/index.php?title=UCI.
Внимание! Загруженные из репозитория файлы могут содержать пустую последнюю строку, которую необходимо удалить!
Исходные данные представляют собой текстовые файлы. Загрузку текстового файла рассмотрим на примере файла iris.data, первые четыре столбца которого являются характеристиками цветков ириса, представленными в форме вещественных чисел. Последний столбец — латинские названия сортов ирисов, записанные в форме строк символов. В качестве разделителей полей в файле используется запятая.
Качественные входные переменные в таблице исходных данных часто представляются строковыми переменными, в нашем примере — названия сортов цветов. Часто качественные переменные кодируются порядковым номером значения качественного признака, например, 1, 2, 3, 4. Качественные переменные необходимо кодировать. При кодировании бинарных признаков в зависимости от вида функции активации "ложь" кодируется как "-1" или "0", а "истина" – как "1".
Для кодирования неупорядоченной качественной переменной используется вектор, содержащий столько компонентов, сколько значений может принимать этот качественная переменная. Пусть  — интервал изменения входных данных. Как правило, этот интервал равен
— интервал изменения входных данных. Как правило, этот интервал равен  или
или  . Тогда первое значение неупорядоченной переменной кодируется вектором
. Тогда первое значение неупорядоченной переменной кодируется вектором  , второе значение — вектором
, второе значение — вектором 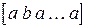 , третье — вектором
, третье — вектором  и так далее. Упорядоченные качественные переменные также кодируются в виде векторов, имеющих стольких компонентов, сколько значений у переменной. Но, в отличие от неупорядоченных переменных необходимо накапливать число максимальных компонентов. Например, если значения качественной переменной упорядочены следующим образом:
и так далее. Упорядоченные качественные переменные также кодируются в виде векторов, имеющих стольких компонентов, сколько значений у переменной. Но, в отличие от неупорядоченных переменных необходимо накапливать число максимальных компонентов. Например, если значения качественной переменной упорядочены следующим образом:  , то значению
, то значению  соответствует вектор
соответствует вектор  , значению
, значению 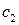 соответствует вектор
соответствует вектор  , значению
, значению  соответствует вектор
соответствует вектор  .
.
Кодирование качественных переменных несложно реализовать программным путем. Но проще в текстовом файле исходных данных провести замену всех значений качественной переменной на соответствующие компоненты векторов и удалить столбцы с текстовыми переменными. Например, все значения выходной переменной Iris-setosa надо заменить на 1,0,0,значенияIris-versicolorзаменить на0,1,0, значенияIris-virginicaзаменить на0,0,1.
Если качественная переменная обозначена порядковым номером ее значения, то качественная переменная заменяется вектором, содержащим столько компонент, каково максимальное значение переменной. Например, если качественная переменная принимает значения 1, 2, 3, 4, то она заменяется вектором из четырех значений. Проблема может состоять в том, в исходной таблице может быть несколько столбцов качественных переменных, принимающих разное число значений. Например, качественная переменная одного столбца принимает 3 значения, а другого столбца — 5 значений. Использование формальной замены приведет к некорректным данным.
Следует учесть, что исходные данные могут содержать пропуски. Надо определить, каким символом обозначается пропуск, и заполнить пропуски, как будет показано ниже. Пропуски проще заполнить в MATLAB. В крайнем случае, допускается удаление неполных данных.
Преобразуем в блокноте файл iris.data в файл iris_1.txt, в котором в результате кодирования качественных переменных последний столбец заменен тремя столбцами. Пропусков данных в нашем примере нет.
Далее необходимо разделить данные на входные и целевые (известные выходные). Подготовку исходных данных для нейронной сети проще выполнить вручную, редактируя файл исходных данных и выполняя операции в командном окне MATLAB.
Для чтения текстового файла с исходными данными используем функцию textscan.Предварительно необходимо открыть текстовый файл для чтения и получить идентификатор fidфайла. Если файл расположен в текущем директории, это можно сделать командой
>>fid = fopen('iris_1.txt','r');
Если файл расположен не в текущем директории, то необходимо указать полный путь к файлу. При успешном открытии файла возвращается положительное значение идентификатора файла. Отрицательное значение идентификатора говорит о том, что не удалось открыть (например, файл с указанным именем отсутствует в текущем директории).
В нашем примере чтение текстового файла производится следующим образом
>> C = textscan(fid, '%f%f%f%f%u%u%u','Delimiter',',');
Здесь %f%f%f%f%u%u%u — формат (первые четыре столбца — вещественные числа, последние четыре — целые числа без знака), Delimiter—параметр, задающий вид разделителя. Спецификацию форматов можно узнать, задав команду help textscan.
Функция возвращает массив ячеек C. Первая ячейка C{1}представляет собой массив — первый столбец таблицы исходных данных. Остальные ячейки представляют другие столбцы таблицы. Обучающая выборка должна представлять собой два двумерных массива: массив входных данных (обозначим P) и массив целевых данных (обозначим T). Каждый столбец этих массивов является частью соответствующей строки текстового массива исходных данных. В нашем примере первые четыре элемента каждой строки используются как входные данные, следующие три — как целевые. Массивы легко формируются с использование транспонирования массивов, расположенных в ячейках массива C:
>> P=[C{1}';C{2}';C{3}';C{4}'];
>> T=[C{5}';C{6}';C{7}'];
Это означает, что к вектору‑строке, полученной из вектора‑столбца, расположенного в ячейке C{1}, снизу присоединяется вектор‑строка, полученная из вектора‑столбца, расположенного в ячейке C{2}и так далее.
Теперь в рабочем пространстве MATLAB содержатся два массива P и T, которые может использовать программа. Решение задачи моделирования нейронной сети проще всего начать, используя инструменты Neural Network Toolbox с графическим интерфейсом, например, для задачи распознавания образов — Neural Network Pattern Recognition Tool. Для этого необходимо сохранить в текущем директории массивы, из рабочего пространства, в нашем примере сохраним P.mat и T.mat. Далее эти массивы загружаются в инструмент Neural Network Toolbox. В программу моделирования файлы входных данных и целей (если они отсутствуют в рабочем пространстве) загружаются с помощью функции load.
Исходные данные могут содержать пропуски (отсутствие данных). В данных, загруженных из Репозитория UCI, отсутствующие данные обычно обозначаются вопросительным знаком. Обучающая выборка не должна содержать пропущенные данные. В общем виде заполнение пропусков представляет собой довольно сложную задачу. Если в исходной таблице немного строк с пропущенными данными, то можно удалить эти строки. Пропуски в числовых входных данных можно заполнить в MATLAB с помощью функции fixunknowns.Для этого в исходной таблице пропущенные данные необходимо заменить строкамиNaN. Проще всего это сделать заменой в блокноте. Далее, как уже было описано, читается текстовый файл с пропущенными данными, отмеченными как NaN. Форматы столбцов, содержащих пропуски надо оставить цифровыми. В сформированных после чтения текстового файла массивах ячеек пропущенные значения будут отмечены NaN. Далее, как было описано, формируются входы нейронной сети. Функция fixunknownsприменяется к сформированному массиву входов сети. В простейшем виде обращение к функции имеет вид
>>P1= fixunknowns(P)
где P — массив входных данных с пропусками, P1 — массив входных данных с заполненными пропусками.
Функция заменяет каждую строку с пропусками двумя строками. Первая строка представляет собой исходную строку, в которой пропущенные значения NaN заменены на среднее значение по данной строке. Во второй (служебной) строке единицы указывают на не измененные элементы, нули — на восстановленные. Служебные строки необходимо удалить, что несложно сделать вручную. Далее следует массив с заполненными пропусками сохранить с помощью функции save. Если массив P1 подготовленных данных сохраняется в текущем каталоге, то обращение к функции имеет вид
>>save('P1')
Файл 'P1' сохраняется с расширением mat. Для сохранения файла в произвольном месте необходимо указать полный путь к файлу.
С помощью функции fixunknownsнельзя заполнить пропуски в качественных данных и целевых значениях любого типа. Заполнение средним значением не всегда возможно. Например, если пропущенные значения представляют собой результаты анализов здоровых и больных пациентов, то заполнение средним значение некорректно. Однако можно разделить таблицу исходных данных на две части — на данные здоровых и больных пациентов. Тогда заполнение средним значением в каждой таблице допустимо. После заполнения пропусков таблицы следует объединить.
По результатам индивидуального задания оформляется отчет. Отчет о выполнении индивидуального задания должен содержать титульный лист, оформленный по правилам оформления отчетов по лабораторным работам. В качестве названия отчета указать название задания, например, Ирисы Фишера. В качестве вида документа указать: Индивидуальное задание по дисциплине "Нейронные сети и нечеткие системы"
Отчет должен содержать следующие разделы.
Постановка задачи
Описывается задача (что надо сделать) и исходные данные задачи (атрибуты). Указывается наличие пропусков в данных.
Описание метода решения
Обосновывается выбор вида нейронной сети и предполагаемых экспериментов с сетью. В тексте должны быть ссылки на источники.
Описание программы
Описывается разработанная программа
Анализ результатов
Проводится анализ результатов решения задачи.
Заключение
Общий вывод (в терминах исходной задачи). Вывод, какую сеть рекомендуется использовать для решения данной задачи.
Список использованных источников
Варианты заданий
Ирисы Фишера
Провести классификацию сортов цветка ирис на три вида: Iris Setosa, Iris Versicolour, Iris Virginica.
Исходные данные загрузить из репозитория UCI, созданного вКалифорнийском университете в Ирвайне (University of California, Irvine):
http://archive.ics.uci.edu/ml/datasets/Iris
|
из
5.00
|
Обсуждение в статье: ИНДИВИДУАЛЬНЫЕ ЗАДАНИЯ ДЛЯ САМОСТОЯТЕЛЬНОЙ РАБОТЫ |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы