 |
Главная |


Связанное распределение памяти
|
из
5.00
|
Связанное представление линейного списка называется связанным списком. При связанном распределении памяти для построения структуры необходимо задать отношения следования и предшествования элементов с помощью указателей. Указателями служат адреса, хранимые в записях данных. В отличие от последовательного распределения памяти, при котором с помощью адресной функции вычисляется адрес следующего элемента, при связанном распределении памяти значение адресной функции можно получить только путем просмотра хранящихся указателей. Такой метод распределения памяти позволяет расширить либо сократить структуру без перемещения самих данных в памяти ЭВМ, однако при этом требуется больше памяти для хранения структуры по сравнению с последовательным распределением.
Связанное распределение – более сложный, но и более гибкий способ хранения линейного списка. Каждый узел содержит указатель на следующий узел списка, т.е. адрес следующего узла списка (рис.8.3). При связанном распределении не требуется, чтобы список хранился в последовательных элементах памяти. Наличие адресов связи в данном способе хранения позволяет размещать узлы списка произвольно в любом свободном участке памяти. При этом линейная структура списка обеспечивается указателями.

Рис.8.3. Примеры связанных линейных списков:
а) – однонаправленный список;
б) – тот же список после удаления узла 4 и включения узлов 2а и 5
Структура линейного списка, представленная с помощью связанного распределения, называется также цепной структурой или цепью.
Для достижения большей гибкости при работе с линейными списками в каждый узел Х[i]вводятся два указателя. Один из указателей реализует связь рассматриваемого узла с узлом Х[i-1], а другой – с узлом Х[i+1] (рис.8.4).
Связанные списки – удобная форма представления динамически изменяющихся линейных структур. Любое произвольное изменение порядка записей, сокращение или расширение вектора данных в какой-либо записи не требуют перемещения записей в памяти ЭВМ. Для выполнения этих операций достаточно лишь изменить значения полей связи.

Рис.8.4. Пример двунаправленного линейного списка
Однако доступ к конкретному узлу может оказаться намного длительнее, чем при последовательном распределении памяти. Чтобы получить доступ к данным, хранящимся в узле Х[i], необходимо сделать i итераций, используя указатели и поля связи в узлах Х[k], где k=1, 2, …, i, т.е. последовательно просмотреть все предшествующие узлы списка. Этот недостаток можно устранить различными способами.
Одним из способов является организация связанного линейного списка с пропусками (рис.8.5, а). Для этого линейный список делится на группы узлов, связанные между собой обратными указателями. Вначале осуществляется доступ по обратным указателям к группе, в которой находится требуемый узел, а затем по прямым указателям перебираются узлы группы, пока не будет найден требуемый узел. Вход в список при таком способе организации осуществляется с конца.
Другой способ (рис.8.5, б) заключается в построении специального дополнительного линейного списка – индекса, например, с последовательным распределением памяти. Элементы индекса – значения первых узлов каждой группы и указатели на них.
Оптимальный размер группы (количество узлов в группе) при равновероятном нахождении узла в любой из групп 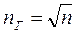 , где n – количество элементов списка.
, где n – количество элементов списка.
Число групп


Рис.8.5. Примеры реализации способов ускорения доступа к
узлам линейного связанного списка:
а) – организация линейного связанного списка с пропусками;
б) – организация линейного связанного списка с индексом
При равновероятном нахождении узла в любой из групп при доступе к узлу необходимо просмотреть в среднем l/2 групп, а в каждой группе nг/2 узлов. Следовательно, общее количество просмотров

Для связанных линейных одно- или двунаправленных списков в ряде случаев целесообразно создать специальный узел – голову списка – и хранить его в специальной фиксированной ячейке памяти по адресу b. В этот узел помещается указатель на первый узел списка. В голове списка можно хранить различную служебную информацию, необходимую при обработке списка (идентификатор списка, количество узлов в списке и т.п.).
Важной разновидностью представления в памяти линейного списка является циклический список. Циклически связанный линейный список обладает той особенностью, что связь от последнего узла идет к первому узлу списка (рис.8.6). Циклический список позволяет получить доступ к любому узлу списка, отправляясь от любого заданного узла. Циклические списки называются также кольцевыми структурами или кольцами.

Рис.8.6. Пример однонаправленного циклического списка
Наряду с однонаправленными используются двунаправленные циклические списки. В ряде случаев удобно использовать циклический список с указателями на голову списка из каждого узла, за исключением последнего узла, поскольку используется прямой указатель на голову списка.
Базируясь на использовании способов представления связанных линейных списков, можно реализовать в памяти ЭВМ сложные нелинейные структуры, например древовидные или сетевые. Такие представления структур называются многосвязанными списками. Для построения многосвязанного списка требуется иметь в узлах достаточное количество указателей. Наличие большого числа указателей в многосвязанной структуре в ряде случаев повышает эффективность обработки.
Таким образом, основой построения связанных списковых структур являются указатели.
При практической реализации на ЭВМ можно использовать три типа указателей (адресов записей):
- машинный (действительный);
- относительный;
- символический (идентификатор).
Первый тип указателей – действительный адрес – используется тогда, когда необходимо получить наибольшую скорость обработки данных, организованных в связанные списковые структуры. Этот тип указателей имеет серьезный недостаток – жесткую привязку записей к конкретному месту расположения в памяти. Если возникнет необходимость переместить список на новое место в памяти ЭВМ, то потребуется выполнить работу изменению указателей во всех записях.
Второй тип указателей – относительный адрес – позволяет размещать записи в любом месте памяти и на различных внешних устройствах без изменения значений указателей, при этом относительное расположение в памяти узлов списка между собой должно оставаться постоянным. При перемещении списка указатели в записях не изменяются, а изменяется базовый адрес при вычислении действительных машинных адресов. Относительные адреса в качестве указателей применяются при страничной организации памяти. Скорость доступа к узлам при использовании относительных адресов несколько замедляется по сравнению со случаем машинных адресов, однако появляется возможность размещать список в любом свободном месте памяти подходящего размера.
Третий тип указателей – символический адрес (идентификатор) – позволяет перемещать отдельные записи относительно друг друга, включать или удалять записи в список без изменения указателей во всех остальных записях списка. Однако при работе с символическими указателями скорость доступа меньше, чем при работе с машинными или относительными адресами. Идентификаторы в качестве указателей удобно использовать для интенсивно изменяющихся файлов. Преобразование идентификатора в машинный адрес при выполнении операций обращения к узлам списка выполняется с помощью специального алгоритма в соответствии с выбранным методом адресации.
С точки зрения организации структуры данных различают два типа указателей:
- встроенные указатели;
- справочник указателей.
Если указатели образуют часть записи, то они называются встроенными. Если указатели хранятся отдельно от записей, то они образуют справочник.
Указатели имеют следующие возможные пути использования:
1) определяют направление доступа (можно двигаться только в тех направлениях, которые заданы указателями);
2) соединяют вместе связанные по смыслу данные;
3) отображают ориентированные ребра в древовидных или сетевых структурах;
4) связывают память на дисках и организуют цепочки дисковых страниц и т.п.
Применение многосвязанных списков – это основной механизм, позволяющий разработчикам СУБД реализовать сложные нелинейные структуры. Однако следует избегать слишком большого количества указателей, поскольку на них тратится память и время на переходы по указателям. Кроме того, при большом количестве указателей основная структура, представляемая в памяти ЭВМ, теряет четкость, и могут возникнуть связи, которые в отображаемой структуре отсутствуют.
Модель внешней памяти
Данные хранятся во внешней памяти на магнитных дисках, магнитных лентах и т.д., а их обработка выполняется в оперативной памяти ЭВМ. Поэтому при обработке некоторые порции данных пересылаются из внешней памяти в оперативную либо наоборот.
При больших объемах данных в БД может потребоваться несколько томов внешней памяти. Однако обмен между внешней и оперативной памятью выполняется небольшими порциями данных – обычно объемом не более нескольких сотен байт. С этой целью внешняя память разбивается на части, называемые блоками или страницами. Данные пересылаются блоками. Операцию пересылки еще называют обменом данными между внешней и оперативной памятью. Такой обмен называется чтением блока, а в обратном направлении – записью блока.
При чтении блока, последний помещается в оперативной памяти в специально отведенный (буферный) участок памяти. Может отводиться участок под несколько буферов (буферный пул). Чем больше буферный пул, тем эффективнее обработка данных. При считывании другого блока из внешней памяти в тот же самый буфер предыдущее содержимое буфера теряется. При внесении изменений в блок вначале блок считывается в буфер, затем выполняются изменения и далее блок записываются во внешнюю память.
Для организации каждого файла в зависимости от его размера во внешней памяти ему выделяется от одного до n блоков, где размещаются записи файла. Предположим, что в одном блоке размещаются записи только одного файла. В зависимости от соотношения объемов записей и блоков может оказаться, что в одном блоке размещается либо одна, либо несколько записей файла, либо одна запись размещается в нескольких блоках. Обычно запись занимает несколько десятков байт.
Каждый байт в блоке пронумерован: 0, 1, 2, …, x. Номер байта блока, с которого начинается запись, определяет относительный адрес записи файла в блоке.
В качестве адресов записей файла во внешней памяти используют: машинный адрес, относительный адрес, ключ записи.
В качестве относительного адреса записи файла используют ее номер по порядку (внутрисистемный номер) в файле либо комбинацию таких составляющих адреса, как номер блока и относительный адрес в блоке, либо номер блока и значение ключа. В последнем случае, после считывания блока в буфер оперативной памяти, доступ к записи в буфере осуществляется в помощью какого-либо метода поиска записей в файле по значению ключа.
При чтении записи из блока, который уже находится в буфере, обмен с внешней памятью не выполняется. Во многих системах при вводе записи ей присваивается уникальный системный идентификатор – ключ базы данных.
Запись обычно состоит из:
1) служебных полей, в которых хранятся указатели, реализующие связи с другими записями, и другая информация, необходимая для организации управления файлом,
2) полей хранимых данных.
Записи могут быть фиксированной и переменной длины. Записи размещаются в блоках плотно, без промежутков, последовательно одна за другой. В блоке часть памяти отводится также для служебной информации о блоке: относительные адреса свободных участков памяти, указатели на следующий блок и т.д.
Если файл базы данных состоит из записей фиксированной длины, то в одном блоке может разместиться k записей:

где ë û - обозначает целую часть числа; Vбл. и Vз. – соответственно объем блока и записи в байтах.
Однако обычно блоки заполняются не полностью, например, наполовину. Оставшаяся область блока остается некоторое время при работе системы незаполненной (зарезервированной). В дальнейшем эта область заполняется при расширении (увеличении) записей, хранящихся в блоке, или при поступлении в систему новых записей, которые в соответствии со значениями их ключей или по другим условиям необходимо поместить в одном блоке с уже хранящимися записями. По истечении некоторого времени блок заполняют полностью.
Для хранения поступающих данных, которые должны были бы попасть в этот блок, выделяется дополнительный блок памяти в области переполнения. Записи, которые должны были размещаться в одном блоке, связываются специальными указателями в одну цепь.
Процесс выделения дополнительных блоков в области переполнения можно было бы не ограничивать, если бы при этом не снижалась эффективность (по временному критерию) обработки хранимых данных. Снижение эффективности обработки данных связано с тем, что система непроизводительно затрачивает время на поиск записей в области переполнения, что сказывается на увеличении общего времени поиска требуемых записей (по сравнению со случаем, когда область переполнения еще не была использована и все записи были размещены в основной области).
Поэтому периодически файл реорганизуется: при необходимости файлу добавляется требуемой количество блоков в основной области памяти и выполняется требуемая перекомпоновка записей. При этом исходят из расчета, чтобы можно было освободить область переполнения, а все записи разместить в блоках основной области, причем, в каждом блоке разместить записи последовательно и в таком количестве, чтобы r-я часть блока осталась незаполненной. В этом случае требуемое количество блоков


где r<1- незаполненная часть блока; Nз. – количество записей в файле.
Считается, что все блоки каждого файла пронумерованы: 1, 2, …, b, …, N и система определяет требуемый блок по имени файла и номеру блока. Если файл состоит из записей фиксированной длины, записи организованы последовательно и имеют внутри файла системный номер, то по этому номеру вычисляют номер блока, в котором находится запись:

Среднее время выполнения операций обмена зависит от типа устройства внешней памяти (от его характеристик) и от размера блока:
tо=Vбл. tр+ tподг.,
где tо – среднее время выполнения операции обмена; tр – время считывания, приведенное к одному байту (т.е. время считывания одного байта); tподг. – время подготовки устройства к выполнению операции обмена.
Время поиска данных в файле
tп=Хо tо + Хс tс,
где tп – время выполнения операции поиска; tс – среднее время выполнения в процессоре одной операции сравнения; Хо – количество операций обмена; Хс – количество операций сравнения.
Если tс<<tо, то время поиска в основном определяется временем, затрачиваемым на обмен с внешней памятью. Поэтому при составлении алгоритмов поиска данных в файле стремятся к сокращению количества операций обмена.
На скорость поиска данных в файле наибольшее влияние оказывают следующие характеристики файла и технических устройств внешней памяти, использованных для его организации:
- объем блока;
- объем байта;
- количество записей в блоке файла nз.бл.;
- количество записей в блоке индекса;
- количество блоков в файле данных nбл.ф.;
- доля резервируемой части блока r (при начальной организации данных в файле);
- длина поля, отведенного для указателя;
- количество записей в файле nз.ф.;
- число полей в записи nп.з.;
- размер записи Vз.;
- длина ключевого поля в записи;
- число записей файла, удовлетворяющих условию поиска Q;
- среднее число блоков переполнения на один блок файла;
- среднее время обмена tо.
На рис.8.7 изображен файл со следующими характеристиками: nз.ф.=10; nз.бл.=4; r=0,5. Записи файла описываются схемой: F(А1, А2, А3, А4), т.е. nп.з.=4. При начальной загрузке при таких характеристиках для организации файла требуется 5 блоков.
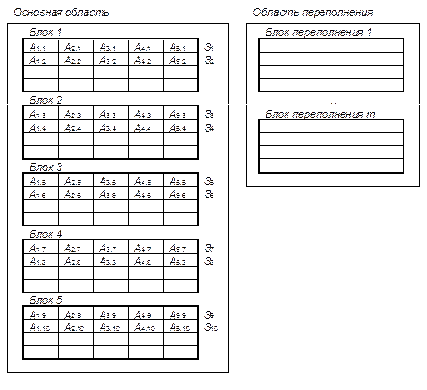
Рис.8.7. Пример организации файла при начальной загрузке
|
из
5.00
|
Обсуждение в статье: Связанное распределение памяти |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы