 |
Главная |


Характеристики системы прерываний
|
из
5.00
|
2. Время реакции – это время между появлением сигнала запроса прерывания и началом выполнения обработчика прерывания в том случае, если данное прерывание разрешено к обслуживанию.
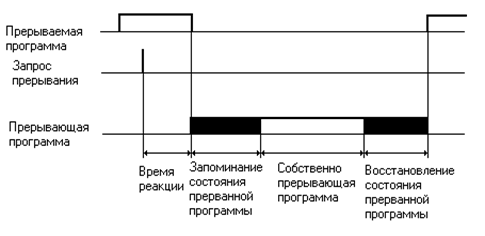
Рисунок 13.2 – Упрощенная временная диаграмма процесса прерывания
tреакции зависит от того, сколько программ с наивысшим приоритетом выставило запросы по отношению к текущему запросу на прерывание,
tзап – время запоминания состояния прерываемой программы;
tвосст – время, необходимое для восстановления прерываемой программы.
5.Глубина системы прерываний – это максимальное число программ, которые могут прерывать друг друга. Глубина прерывания обычно совпадает с числом уровней приоритетов, распознаваемых системой прерываний.
Частный случай – единичная глубина, когда прерываемую программу может прервать одна прерывающая программа, и никакая другая программа не может ее прервать до окончания ее выполнения. Системы с большей глубиной имеют меньшие издержки.
 |
Рисунок 13.4 – Демонстрация обработки прерываний разной глубины
Следует отметить, что система с большей глубиной прерывания обеспечивает более быструю реакцию на срочные запросы.
7. Число уровней прерывания (число классов прерывания).В ЭВМ число различных запросов (причин) прерывания может достигать нескольких десятков или сотен. В таких случаях часть запросов разделяют на отдельные классы или уровни. Совокупность запросов, инициирующих одну и ту же прерывающую программу, образует классилиуровень прерывания. Разделение запросов на классы прерывания представлено на рис. 9.3.

Рисунок 13.5 – Разделение запросов на классы прерывания
Запросы всех источников прерывания поступают на РгЗП, устанавливая соответствующие его разряды в единицу, которая указывает на наличие запроса прерывания определенного источника. Запросы классов прерывания ЗПК формируются схемами ИЛИ, объединяющих разряды РгЗП, относящихся к соответствующим уровням прерывания. Еще одна схема ИЛИ формирует общий сигнал прерывания ОСП, поступающий в устройство управления процессора. После принятия запроса прерывания на исполнение и передачу управления прерывающий программе соответствующий триггер РгЗП сбрасывается. Следует отметить, что объединение запросов в классы прерывания позволяет уменьшить объем аппаратуры, но приводит к замедлению работы системы прерываний.
Рассмотрим поэтапно процесс обслуживания прерывания.
1 этап. Прием и хранение запросов прерываний от многих источников
Эта функция реализуется на аппаратном уровне путем установки соответствующих битов специального регистра запросов при появлении этих запросов. Например, в микросхеме PIC (Intel 8259A) имеется специальный регистр IRR (Interrupt Request Register – регистр запросов прерываний), который является восьмибитным (по числу обслуживаемых запросов). Каждый бит этого регистра соответствует определенному источнику прерываний (например, запрос от таймера или клавиатуры), и установка этого бита свидетельствует о наличии запроса от источника. При количестве источников запросов больше восьми применяется так называемая схема каскадного подключения микросхем PIC. В типовой комплект ПК входят две микросхемы PIC, одна из них называется ведущей, а другая – ведомой.
2 этап. Выделение наиболее приоритетного запроса из множества поступивших.
Процедура опроса источников прерываний с целью выделения наиболее приоритетного из них обычно называется полинг (polling). В принципе, эта процедура может быть реализована как на аппаратном, так и на программном уровнях. Аппаратная реализация поллинга, как правило, осуществляется с помощью цепочной однотактной схемы, именуемой дейзи-цепочкой.
ЗП – запросы прерываний от источников 0, 1, 2, … Наиболее приоритетным является ЗП0.
CD – шифратор (кодер), преобразующий унитарный код запроса в позиционный. Позиционный код запроса сохраняется в Рг N.
 |
Рисунок 13.6 – Схема выделения наиболее приоритетного запроса прерывания
с помощью аппаратного полинга
Программный поллинг реализуется специальной программой, которая последовательно опрашивает разряды регистра запросов с целью выделения крайней левой или крайней правой единицы (в зависимости от упорядочивания запросов по приоритетам).
Для ускорения работы программы поллинга могут быть использованы специальные команды сканирования битов с мнемоникой BSF – Bit Scan Forward (прямое сканирование) или BSR – Bit Scan Reverse (обратное сканирование), с помощью которых можно выделить крайний левый (BSF) или крайний правый (BSR) бит, установленный в операнде-источнике. Эти команды введены в систему команд процессоров Intel, начиная с Intel 80386, и возвращают в качестве результатов номер позиции бита.
В стандартной микросхеме PIC встроен механизм аппаратного полинга на основе дейзи-цепочки, но имеется возможность реализации и программного поллинга.
3 этап. Проверка возможности обработки
выделенного запроса центральным процессором
Отношение ЦП к поступающим запросам прерываний выражается с помощью двух основных механизмов:
• механизм масок;
• механизм порога.
Механизм масок используется в ПК на базе процессоров Intel, а также в мэйнфреймах фирмы IBM.
Механизм масок основан на использовании специального бита для каждого запроса прерывания, с помощью которого разрешается или запрещается обработка этого запроса. Как правило, единичное значение бита маски определяет разрешение обработки (прерывание не замаскировано), а нулевое значение – запрещение обработки (прерывание замаскировано). В принципе, возможен и обратный подход.
В микросхеме PIC имеется соответствующий регистр IMR – Interrupt Mask Register, в котором маскирование запросов осуществляется единичным значением бита Mask.
Дальнейшим развитием механизма Mask является использование иерархического подхода к маскированию запросов прерываний. В качестве примеров иерархии масок, используемых в процессорах фирмы Intel, могут являться:
1. Маскирование внешних запросов. Локальные маски для каждого из запросов сосредоточены в регистре IMR микросхемы PIC. Глобальная маска представляет собой флаг IF. При установленном флаге разрешается обработка внешних прерываний, при сброшенном – запрещается. С помощью флага IF маскируются только те запросы, которые поступают на вход INTR процессоров (Interrupt Request). В свою очередь запросы, поступающие на внешний вход NMI (Non-Maskable Interrupt), принимаются к обслуживанию независимо от состояния флага IF.
2. Маскирование особых случаев в FPU. В управляющем регистре CR (Control Register) FPU крайние правые 6 бит являются масками особых случаев, к которым относятся:
- недействительная операция;
- денормализованный операнд;
- деление на ноль;
- переполнение порядка;
- исчезновение порядка (антипереполнение);
- потеря точности.
Кроме того, в этом же регистре имеется глобальная маска IEM, с помощью которой маскируются все особые случаи.
Механизм порога используется в мини-компьютерах с архитектурой DEC – Digital Equipment Corporation (PDP-8, VAX-11), а также в ПК на базе процессоров Motorola.
Порог прерываний представляет собой собственный приоритет процессора, точнее, уровень приоритета выполняемой им программы. Порог отражается с помощью специального трехбитного поля, находящегося в слове состояний процессора PS (Processor Status).
В интерфейсе Unibus (общая шина), используемом в компьютерах с архитектурой DEC, выделяются специальные линии запросов прерываний от ВУ и линий разрешения прерываний, которые являются однонаправленными. Упрощенная схема подключения к этим линиям имеет вид:
 |
Рисунок 13.7 – Упрощенная схема подключения к линиям запросов прерываний
в интерфейсе Unibus в компьютерах с архитектурой DEC
Все ВУ, в зависимости от их важности (приоритета), подключаются параллельно к соответствующей линии запроса прерываний ЗП1…ЗПn. Предполагается, что приоритет увеличивается с увеличением номера.
В свою очередь, линии разрешения прерываний проходят последовательно через ВУ каждого уровня, что соответствует так называемому цепочному интерфейсу. В CPU имеется специальный блок, называемый арбитром, который выделяет линию с наиболее приоритетным запросом. Если приоритет этой линии выше порога прерываний, то арбитр посылает сигнал разрешения прерывания по соответствующей линии этого уровня. Сигнал разрешения последовательно проходит через ВУ этого уровня и блокируется первым же ВУ, пославшим запрос на линию ЗП. В соответствии с этим, в подобной схеме подключения ВУ реализуется двумерная система приоритетов. Это означает, что приоритет ВУ, во-первых, зависит от уровня линий ЗП и РП, к которым оно подключается, во-вторых – от степени его электрической близости по линии РП к арбитру.
Функция проверки возможности обработки выделенного запроса центральным процессором реализуется чисто на аппаратном уровне.
4 этап. Сохранение состояния (контекста) прерываемой программы
Эта функция обычно реализуется с использованием как аппаратного, так и программного уровней. На аппаратном уровне сохраняется лишь минимальная часть контекста, в частности: обязательный адрес возврата и не очень обязательный регистр состояний (флагов). Содержимое остальных регистров процессора, которые могут быть востребованы программой-обработчиком прерываний, сохраняются на программном уровне. Действия, связанные с сохранением этих регистров, составляют начальную фазу программы-обработчика прерываний.
Применительно к процессорам фирмы Intel, исключительно удобной для этих целей (сохранение контекстов) является команда PUSHA, по которой сохраняются в стеке все РОНы (8 штук). В процессорах фирмы Intel на аппаратном уровне происходит сохранение в стеке содержимого регистра флагов FR, сегмента кода CS и IP. Последняя пара и представляет собой полный адрес возврата.
В тех случаях, когда выход на обработку прерываний сопровождается переключением задач, сохранение всего контекста прерываемой программы (задачи) реализуется на аппаратном уровне с использованием специального системного сегмента TSS – Task State (Status) Segment.
5 этап. Вызов соответствующего обработчика прерываний
Эта функция реализуется чисто на аппаратном уровне и предполагает загрузку начального адреса обработчика, обычно называемого вектором прерываний, в соответствующие регистры процессора (для процессоров Intel это регистры CS и IP).
6 этап. Обработка прерывания (выполнение программы-обработчика)
Эта функция реализуется на программном уровне.
7 этап. Восстановление состояния (контекста) прерванной программы
и возобновление ее выполнения
Эта функция является обратной функции сохранения состояния (контекста) прерываемой программы.
|
из
5.00
|
Обсуждение в статье: Характеристики системы прерываний |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы