 |
Главная |


Топологическая сортировка
|
из
5.00
|
Это процесс сортировки элементов, для которых определен частичный порядок, т.е. упорядочение задано не на всех, а на некоторых парах элементов.
Пример: в университетской программе одни предметы опираются на другие, поэтому одни предметы должны прослушиваться раньше, чем другие, т.е. сначала базовые, а затем те, которые основываются на базовых.
В общем виде частичный порядок на множестве S – это отношения между элементами этого множества, оно обозначается символом “<” – предшествует. Удовлетворяет следующим аксиомам:
1) для любых элементов: x, y, z из S, если x<y и y<z, то x<z – транзитивность;
2) если x<y, то не y<x – асимметричность;
3) не x<x – иррефлексивность.
Будем считать, что множество S, которое нужно топологически рассортировать является конечным, поэтому отношения частичного порядка можно проиллюстрировать с помощью графа (рис. 6.4), в котором вершины обозначают элементы S, а ребра – отношения порядка.

Рис. 6.4. Исходный граф
Цель сортировки – преобразовать частичный порядок в линейный (рис. 6.5). Свойства 1 и 2 обеспечиваются отсутствием циклов. Это то необходимое условие, при котором преобразование возможно.

Рис. 6.5. Отсортированный граф
Рассмотрим необходимые структуры данных. Каждый элемент удобно представить тремя характеристиками: идентифицирующим ключом, множеством следующих за ним элементов и счетчиком предыдущих. Поскольку число последователей не задано a priori, то это множество удобно организовать в виде связанного списка. Аналогично множество последователей можно представить в виде списка.
type
lref = ^leader;
tref = ^trailer;
leader = record
key, count: integer;
trail: tref;
next: lref;
end;
trailer = record
id: lref;
next: tref;
end;
ДРЕВОВИДНЫЕ СТРУКТУРЫ
Пусть древовидная структура определяется следующим образом: древовидная структура с базовым типом Т – это либо пустая структура, либо узел типа Т, с которым связано конечное число древовидных структур с базовым типом Т, называемых поддеревьями.
Существует несколько способов изображения древовидной структуры. Например: вложенные множества, ломаная, граф (рис. 7.1).
Упорядоченное дерево – это дерево, у которого ветви каждого узла упорядочены. Узел y, который находится непосредственно под узлом x, называется (непосредственным) потомком x; если x находится на уровне i, то говорят, что y – на уровне i + 1. Наоборот, узел x называется (непосредственным) предком y. Считается, что корень дерева расположен на уровне 1. Максимальный уровень какого-либо элемента дерева называется его глубиной или высотой.
Если элемент не имеет потомков, он называется терминальным элементом или листом, а элемент, не являющийся терминальным, называется внутренним узлом. Число (непосредственных) потомков внутреннего узла называется его степенью. Максимальная степень всех узлов есть степень дерева. Число ветвей, или ребер, которые нужно пройти, чтобы продвинуться от корня к узлу x, называется длиной пути к x. Корень имеет длину пути 1, его непосредственные потомки – длину пути 2 и т. д. Вообще, узел на уровне i имеет длину пути i. Длина пути дерева определяется как сумма длин путей всех его узлов. Она также называется длиной внутреннего пути. Например, длина внутреннего пути дерева, изображенного на рис. 7.1, равна 52. Очевидно, что средняя длина пути  есть
есть  , где
, где  – число узлов на уровне i.
– число узлов на уровне i.


Рис. 7.1. Способы изображения дерева
Для того чтобы определить, что называется длиной внешнего пути, мы будем дополнять дерево специальным узлом каждый раз, когда в нем встречается нулевое поддерево (рис. 7.2). При этом мы считаем, что все узлы должны иметь одну и ту же степень – степень дерева.

Рис. 7.2. Дерево со специальными узлами
Длина внешнего пути теперь определяется как сумма длин путей всех специальных узлов. Если число специальных узлов на уровне i есть  , то средняя длина внешнего пути
, то средняя длина внешнего пути  равна
равна 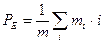 . У дерева, приведенного на рис. 7.2, длина внешнего пути равна 153.
. У дерева, приведенного на рис. 7.2, длина внешнего пути равна 153.
Максимальное число узлов в дереве заданной высоты h достигается в случае, когда все узлы имеют d поддеревьев, кроме узлов уровня h, не имеющих ни одного. Тогда в дереве степени d первый уровень содержит 1 узел (корень), уровень 2 содержит d его потомков, уровень 3 содержит d2 потомков d узлов уровня 2 и т. д. Это дает следующую величину:
 .
.
Дерево идеально сбалансировано, если для каждого его узла количества узлов в левом и правом поддеревьях различаются не более чем на 1.
Пример: построение сбалансированного дерева
ProgramBildTree;
Type ref = ^node;
Node = record
Key: Integer;
Left, Right: ref;
End;
Var
n: Integer;
Root: ref;
Function tree(n: integer): ref;
Var
newnode: ref;
x, nl, nr: Integer;
Begin
If n = 0 then tree:= nil
Else
Begin
nl:= n div 2; nr:= n- nl –1;
Read(x); New (newnode);
With newnode^ do
Begin
key:=x; left:=tree(nl); right:=tree(nr);
End;
tree:= newnode;
End;
End;
Procedure PrintTree (t: ref; h: Integer);
Begin
If t <> nil Then
Begin
PrintTree(left,h+1);
For i:= 1 to h do Write (' ');
Writeln(Key);
PrintTree(right,h+1);
End;
End;
Begin
Read(n);
Root:= Tree(n);
PrintTree(root,0);
End.
Упорядоченные деревья степени 2 играют особо важную роль. Они называются бинарными деревьями (рис. 7.3). Упорядоченное бинарное дерево – конечное множество элементов (узлов), каждый из которых либо пуст, либо состоит из корня (узла), связанного с двумя различными бинарными деревьями, называемыми левым и правым поддеревьями корня. Деревья, имеющие степень больше 2, называются сильно ветвящимися деревьями (multiway trees).

Рис. 7.3. Бинарное дерево
Бинарные деревья
Знакомыми примерами бинарных деревьев являются фамильное (генеалогическое) дерево с отцом и матерью человека в качестве его потомков, история теннисного турнира, где узлом является каждая игра, определяемая ее победителем, а поддеревьями – две предыдущие игры соперников; арифметическое выражение с двухместными операциями, где каждая операция представляет собой ветвящийся узел с операндами в качестве поддеревьев.
Теперь мы обратимся к проблеме представления деревьев. Ясно, что изображение таких рекурсивных структур с разветвлениями предполагает использование ссылок. Очевидно, что не имеет смысла описывать переменные с фиксированной древовидной структурой, вместо этого узлы определяются как переменные с фиксированной структурой, т. е. фиксированного типа, где степень дерева определяет число компонент-ссылок, указывающих на поддеревья данного узла. Ясно, что ссылка на пустое поддерево обозначается черезnil.
type node = record
key: integer;
left, right: ^node;
end;
Обход дерева
Имеется много задач, которые можно выполнять на древовидной структуре; распространенная задача – выполнение заданной операции P с каждым элементом дерева. Здесь P рассматривается как параметр более общей задачи посещения всех узлов, или, как это обычно называют, обхода дерева.
Если рассматривать эту задачу как единый последовательный процесс, то отдельные узлы посещаются в некотором определенном порядке и могут считаться расположенными линейно. В самом деле, описание многих алгоритмов существенно упрощается, если можно говорить о переходе к следующему элементу дерева, имея в виду некоторое упорядочение.
Существуют три принципа упорядочения, которые естественно вытекают из структуры деревьев. Так же, как и саму древовидную структуру, их удобно выразить с помощью рекурсии. Обозначив R – корнем, а A и B – левым и правым поддеревьями, мы можем определить такие три упорядочения:
1) сверху вниз: R, A, B (посетить корень до поддеревьев);
2) слева направо: А, R, В;
3) снизу вверх: А, В, R (посетить корень после поддеревьев).
Теперь выразим эти три метода обхода как три конкретные программы с явным параметром t, означающим дерево, с которым они имеют дело, и неявным параметром Р, означающим операцию, которую нужно выполнить с каждым узлом.
Эти три метода легко сформулировать в виде рекурсивных процедур.
Procedure preorder (t: ref)
Begin
If t <> Nil Then
Begin
P(t);
preorder(t^.Left);
preorder(t^.Right);
End
End;
Procedure postorder (t: ref);
Begin
If t <> Nil Then
Begin
postorder(t^.Left);
postorder(t^.Right);
P(t);
End;
End;
Procedure inorder (t: ref);
Begin
If t <> Nil Then
Begin
inorder(t^.Left);
P(t);
inorder(t^.Right);
End;
End;
Пример подпрограммы, осуществляющей обход дерева, – это подпрограмма печати дерева с соответствующим сдвигом, выделяющим каждый уровень узлов.
Поиск элементов
Бинарные деревья часто используются для представления множеств данных, элементы которых ищутся по уникальному, только им присущему ключу. Если дерево организовано таким образом, что для каждого узла t[i] все ключи в левом поддереве меньше ключа t[i], а ключи в правом поддереве больше ключа t[i], то это дерево называется деревом поиска. В дереве поиска можно найти место каждого ключа, двигаясь, начиная от корня, и переходя на левое или правое поддерево каждого узла в зависимости от значения его ключа. Как мы видели, n элементов можно организовать в бинарное дерево с высотой не более чем log2(n). Поэтому для поиска среди n элементов может потребоваться не более log2(n) сравнений, если дерево идеально сбалансировано. Очевидно, что дерево – намного более подходящая форма организации такого множества данных, чем линейный список.
Так как этот поиск проходит по единственному пути от корня к искомому узлу, его можно запрограммировать с помощью итерации:
Function Loc (x: integer; t: ref): ref;
Var
found: boolean;
Begin
found: = false;
While (t <> nil) and (Not found) do
Begin
if t^.key = x then found:= true
else
if t^.key > x then t:= t^.Left
else t:= t^.right
end;
Loc:= t;
End;
Функция Loc (x, t) имеет значение nil, если в дереве с корнем t не найдено ключа со значением x. Так же как в случае поиска по списку, сложность условия окончания цикла заставляет искать лучшее решение. При поиске по списку в конце его помещается барьер. Этот прием можно применить и в случае поиска по дереву. Использование ссылок позволяет связать все терминальные узлы дерева с одним и тем же барьером (рис. 7.4). Полученная структура – это уже не просто дерево, а скорее, дерево, все листья которого прицеплены внизу к одному якорю.

Рис. 7.4. Дерево с барьером
Барьер можно также считать общим представлением всех внешних (специальных) узлов, которыми дополняется исходное дерево. Полученная в результате упрощенная процедура поиска описана ниже:
Function Loc(x: integer; t: ref): ref;
Begin
s^.key:= x; [барьер]
While t^.key <> x do
If x < t^,key Then t:= t^.left
Else t:= t^.right;
Loc:= t;
End;
Если в дереве с корнем t не найдено ключа со значением x, то в этом случае loc(x, t) принимает значение s, т. е. ссылки на барьер. Ссылка на s просто принимает на себя роль ссылки nil.
Включение элементов
Прежде всего, рассмотрим случай постоянно растущего, но никогда не убывающего дерева. Хорошим примером этого является задача построения частотного словаря. В этой задаче задана последовательность слов, и нужно установить число появлений каждого слова. Это означает, что, начиная с пустого дерева, каждое слово ищется в дереве. Если оно найдено, увеличивается его счётчик появлений, если нет – в дерево вставляется новое слово (с начальным значением счетчика, равным 1). Предполагаются следующий способ описания типов:
Type
ref = ^Words;
Words = record
Key: Integer;
Count: Integer;
Left, Right: ref;
End;
Считая, кроме того, что у нас есть исходный файл ключей F, а переменная root указывает на корень дерева поиска, мы можем записать программу следующим образом:
Reset(f);
While Not EOF(f) do Begin
Read(f,k); Search(x, root);
End;
Определение пути поиска здесь вновь очевидно. Но если он приводит в «тупик», т.е. к пустому поддереву, обозначенному ссылочным значением nil, то данное слово нужно вставить в дерево на место пустого поддерева.
Процесс поиска представлен в виде рекурсивной процедуры. Использование барьера вновь упрощает задачу.
Procedure Search (x: integer; Var p: ref);
Begin
s^.key:= x;
If x < p^.key Then Search(x,p^.Left) Else
If x > p^.key Then Search(x,p^.Right) Else
If p <> s Then p^.Count:= p^.Count + 1 Else
Begin
{включение}
New(p);
With p^ do
Begin
Key:= x; Left:= s;
Right:= s; Count:=1;
End;
End;
End;
Удаление из дерева
Теперь мы переходим к задаче, обратной включению, а именно удалению. Нам нужно построить алгоритм для удаления узла с ключом x из дерева с упорядоченными ключами. К сожалению, удаление элемента обычно не так просто, как включение. Оно просто в случае, когда удаляемый элемент является терминальным узлом или имеет одного потомка.
Различают три случая:
1. Компоненты с ключом, равным x, нет.
2. Компонента с ключом x имеет не более одного потомка.
3. Компонента с ключом x имеет двух потомков.
Легко удалить терминальный узел, или узел, имеющий одного потомка. В случае двух потомков удаляемый элемент нужно заменить либо на самый правый элемент его левого поддерева, либо на самый левый элемент его правого поддерева. Ясно, что такие элементы не могут иметь более одного потомка.
Procedure Delete (x: integer; var p: ref);
Var
q: ref;
Procedure del (var r: ref);
Begin
If r^.right <> nil Then del(r^.right)
Else
Begin
q^.key:= r^.key;
q:= r; r:= r^.left
End
End;
Begin {delete}
If p = nil Then Writein ('word is not in tree')
Else If x < p^.key Then delete(x, p^.left)
Else If x > p^.key Then delete(x, p^.right)
Else
Begin {delete p^}
q:= p;
If q^.right = nil Then p:= q^.left
Else If q^.left = nil
Then p:= q^.right
Else del(q^.left);
Dispose(q)
End
End; [delete}
Вспомогательная рекурсивная процедура del вызывается только в 3-м случае. Она «спускается» вдоль самой правой ветви левого поддерева удаляемого узла q^ и затем заменяет существенную информацию (ключ и счетчик) в q^ соответствующими значениями самой правой компоненты r^ этого левого поддерева, после чего от r^ можно освободиться.
АВЛ-деревья
Анализ задачи поиска по дереву с включениями узлов показывает, что эффективность алгоритма зависит от формы, которую принимает растущее дерево. Легко найти наихудший случай: ключи поступают в порядке возрастания, и дерево оказывается полностью вырожденным, т. е. превращается в линейный список. В этом случае среднее число сравнений ключей равно N/2. Наилучший вариант получается, если дерево строится идеально сбалансированным, в этом случае среднее число сравнения равно log2N.
Н. Вирт показал, что строя идеально сбалансированное дерево, следует ожидать выигрыш в длине пути поиска в среднем не более 39%. Эта цифра достаточно низка и в большинстве случаев не оправдывает затрат на восстановление идеальной сбалансированности дерева.
Попробуем добиться эффективности менее дорогим способом, введя менее строгое понятие сбалансированности дерева. Критерий сбалансированности дерева (Адельсон-Вельский, Ландис, 1962): дерево является сбалансированным тогда и только тогда, когда для каждого его узла высота его двух поддеревьев различается не более чем на 1.
Дерево, удовлетворяющее этому критерию, называют АВЛ-деревом (по имени авторов) (рис. 7.5) или сбалансированным деревом. Понятно, что идеально сбалансированное дерево является АВЛ-деревом.

Рис. 7.5. АВЛ-дерево
Рассмотрим включение элемента в сбалансированное дерево.
Возможны 3 случая:
1. hL = hR: L и R становятся неравной высоты, но критерий сбалансированности не нарушается.
2. hL < hR: L и R приобретают равную высоту, т.е. сбалансированность даже улучшается.
3. hL > hR: критерий сбалансированности нарушается, и дерево нужно трансформировать, такая перестройка называется поворотом.
Рассмотрим третий случай. Включение узлов 1, 3, 5 или 7 требует последующей балансировки. Можно обнаружить, что имеется лишь две существенно различные ситуации, требующие индивидуального подхода. Оставшиеся могут быть получены симметричными преобразованиями этих двух.
Случай 1. Включение ключа 1 или 3. Для балансировки выполняется так называемый левый поворот (рис. 7.6).

Рис. 7.6. Добавление ключа (случай 1)
Случай 2. Включение узла 5 или 7. Теперь для балансировки выполняется два поворота – левый и правый (рис. 7.7).

Рис. 7.7. Добавление ключа (случай 2)
|
из
5.00
|
Обсуждение в статье: Топологическая сортировка |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы