 |
Главная |


Частотные распределения качественных признаков
|
из
5.00
|
Напомним, что для качественных признаков категории в частотных распределениях играют ту же роль, что и интервалы для количественных признаков, т.е. можно считать абсолютные и относительные частоты категорий. Однако подсчет кумулятивных частот имеет смысл для качественного признака лишь в том случае, если его категории упорядочены, т.е. если он является ранговым.
Пример 1.3. Вернемся к таблице данных по депутатам 1-й Государственной думы (файл Duma.sta). В этой таблице большинство признаков являются качественными, причем номинальными (за исключением уровня образования – это ранговый признак). Построим частотное распределение признака "уровень образования". Поскольку эта переменная является по существу ранговой, процедура построения частотных распределений (как и в случае количественного признака) может включать не только обычные, но и накопленные (кумулятивные) частоты: количества и доли депутатов, имеющих уровень образования не ниже или не выше данного (в зависимости от порядка категорий).
Если попробовать построить частотное распределение признака "уровень образования" по аналогии с признаком "возраст" (в разделе Categorization methods for Tables & Graphs надо в этом случае выбрать поле Integer categories), то окажется, что таблица результатов содержит категории признака в произвольном порядке, а не по возрастанию или убыванию уровня образования. Это происходит потому, что в пакете STATISTICA всем текстовым данным ставятся в соответствие числовые коды, которые и используются при всех операциях с данными. Очевидно, что программа не знает смысла названий текстовых данных и поэтому производит оцифровку категорий качественных переменных произвольным образом.

Рис. 1.14. Перекодировка категорий ранговой переменной
"уровень образования"
Например, если в таблице данных дважды щелкнуть на имени переменной "уровень образования", а потом нажать графическую кнопку Text Labels, можно видеть что категория образования "высшее" имеет код 104, "неоконченное высшее" – код 102, "среднее" – код 105, "неоконченное среднее" – код 101, "низшее" – код 103, "малограмотный" – код 106 и "неграмотный" – код 107. Для того чтобы восстановить естественный порядок категорий признака (т.е. "неграмотный" обозначить кодом "1", "малограмотный" – кодом "2", "низшее" – кодом "3" и т.д.), необходимо либо перекодировать значения, либо создать новую переменную, которая будет содержать числовые ранги. Перекодировку категорий рангового признака можно выполнить непосредственно в окне Text Labels (см. рис. 1.14).
Поскольку порядок рангов можно поменять на обратный, то интересно также добавить к частотной таблице колонку 100% minus Cumulative percentages (кумулятивные относительные частоты в обратном порядке). Для этого на вкладке Optionsдиалогового окна Frequency Tables надо пометить соответствующее поле (поставить флажок). Щелчок по графической кнопке Summary: Frequency Tables дает готовую частотную таблицу.
В табл. 1.1 приведен результат работы модуля Frequency Tables с перекодированной переменной "уровень образования".
Таблица 1.1. Частотное распределение признака "уровень образования"
| Категория | Числовой ранг | Абсол. частота | Кумулят. абс. частота | % | Кумулят. процент | Кум. проц. в обрат. порядке |
| неграмот. | 0,47 | 0,47 | 100,00 | |||
| малограм. | 3,95 | 4,42 | 99,53 | |||
| низшее | 26,51 | 30,93 | 95,58 | |||
| неок. средн. | 2,33 | 33,26 | 69,07 | |||
| среднее | 11,17 | 44,42 | 66,74 | |||
| неок. высш. | 3,26 | 47,67 | 55,58 | |||
| высшее | 52,33 | 100,00 | 52,32 |
Примечание. Числа, выделенные жирным шрифтом в табл. 1.1, указывают соответственно долю депутатов:
– с неоконченным средним образованием;
– с неоконченным средним образованием или более низким (образование ниже "среднего");
– с неоконченным средним образованием или более высоким (образование выше "низшего").
Теперь рассмотрим построение частотных распределений номинальных качественных признаков. Здесь категории не могут быть упорядочены, и кумулятивные показатели теряют смысл. Для того, чтобы отключить построение кумулятивных показателей, на вкладкеOptions диалогового окна Frequency Tables надо "снять" соответствующие флажки: Cumulative Frequencies, Cumulative Percents и 100 minus Cumulative Percentages. При этом надо оставить "включенными" Percentages (relative frequencies), для того, чтобы в таблице результатов присутствовала колонка с относительными частотами (процентными долями) категорий признака, а не только с абсолютными частотами.
Пример 1.4. Построим частотное распределение признака "профиль образования" в таблице Duma (результаты представлены в табл. 1.2 и для удобства упорядочены по алфавиту).
Таблица 1.2. Частотное распределение признака “Профиль образования”
| Категория | Абсолютная частота | Процент |
| военное | 5,1 | |
| гуманитарное | 3,2 | |
| духовное | 6,0 | |
| естественнонаучное | 3,9 | |
| медицинское | 6,9 | |
| общее | 29,9 | |
| педагогическое | 3,7 | |
| разное | 1,1 | |
| сельскохозяйственное | 3,9 | |
| техническое | 5,5 | |
| экономическое | 0,6 | |
| юридическое | 16,9 | |
| Missing | 12,7 |
Примечание. Как обычно, в строке Missing (пропущенные данные) подсчитано число и доля депутатов, для которых нет сведений о профиле образования.
Визуализация данных
Графическое изображение частотного распределения называется гистограммой. Гистограмма показывает зависимость частоты встречаемости признака от соответствующего интервала группировки. Разумеется, вид гистограммы существенно зависит от количества интервалов: чем больше интервалов и чем меньше длина каждого из них, тем более четко выступают характерные черты распределения: симметричность, унимодальность (одновершинность) и т.п. Гистограмма также показывает моду распределения.
Гистограмма с параметрами по умолчанию доступна при нажатии графической кнопки Histogram на вкладке Quick (для количественных признаков при этом выбирается интервальный ряд с числом интервалов, равным 10 и границами интервалов, заканчивающимися на 0 или 5). Можно также получить гистограмму прямо из исходной таблицы: выделив нужный признак и щелкнув правой кнопкой мыши, выбрать в появившемся контекстном меню Graphs of Input Data | Histogram.
Для получения более сложных гистограмм на вкладке Advanced в диалоговом окне Frequency Tables надо задать те же параметры группировки, что и для построения частотных распределений, а затем нажать на графическую кнопку Histogram. Наконец, все возможности построения графиков доступны из пункта Graphs главного меню программы.
Пример 1.5. Построим гистограммы распределения депутатов I Государственной думы (файл Duma.sta) по возрасту, сначала задавая длину интервала группировки (пять лет), а затем – число интервалов группировки (пять).
Воспользовавшись любым из указанных выше способов, построим обе гистограммы (результаты показаны на рис. 1.15).
| а) длина интервала = 5 | б) число интервалов = 5 |

| 
|
Рис. 1.15. Гистограммы распределения по возрасту (файл Duma.sta)
На рис. 1.15 числа на границах колонок по горизонтальной оси показывают интервалы значений возраста. По вертикальной оси откладывается число наблюдений (объектов) – в нашем случае, депутатов Думы – в соответствующей возрастной группе.
Заметим, что в данном случае мы имеем одномодальное (одновершинное) распределение, которое не является вполне симметричным.
 Рис. 1.16
Рис. 1.16
|
Часто гистограмма используется в статистических пакетах для сопоставления распределения с нормальным (для проверки гипотезы о том, что значения данного признака распределены по нормальному закону – очень важному в теории вероятностей типу распределения) [2]. С этой целью на изображение реальной гистограммы накладывается теоретически вычисленный на основе среднего арифметического и среднего квадратического отклонения график нормального распределения (см. рис. 1.16).
Аналогично строятся гистограммы и для качественных признаков. Для большинства из них, однако, порядок групп (категорий) не имеет значения, Поэтому для них гораздо интереснее выглядят графики другого типа, а именно – круговые диаграммы, которые отображают долю каждой категории признака в виде соответствующего сектора круга.
Пример 1.6. Вернемся к нашим данным и построим круговую диаграмму (Pie Chart) для признака "профиль образования". Выберем команду 2D Графики | Смешанные графики | PieCharts в пункте Graphs основного меню программы. Откроется диалоговое окно, представленное на рис. 1.17.

Рис. 1.17. Диалоговое окно построения круговых диаграмм (вкладка Быстрый)

Рис. 1.18. Диалоговое окно построения круговых диаграмм
(вкладка Дополнительно)
В диалоговом окне на вкладке Быстрый (см. рис. 1.17) или вкладке Дополнительно (см. рис. 1.18) в разделе Тип графика обязательно надо указать Counts (группировка), а не Values (исходные значения). В разделе Частота интервалов надо выбрать Integer Mode (Авто), что соответствует работе с номинальными данными, а в разделе Легенда (только на вкладке Дополнительно) – Text and Percent (Название и процент), чтобы видеть не только названия категорий, но и частоты их встречаемости в совокупности объектов. Щелкнув по графической кнопке OK, получим результат, показанный на рис. 1.19.

Рис. 1.19. Круговая диаграмма с параметрами, соответствующими рис. 1.18
До сих пор предполагалось, что строками в таблице исходных данных являются единичные объекты, а столбцами – конкретные значения признаков (качественных или количественных) для этих объектов. Однако в статистике исходным материалом часто служат уже сгруппированные данные, например, готовые вариационные ряды, когда строками являются интервалы значений какого-либо количественного признака или категории какого-либо качественного признака, а в столбцах стоят частоты (число единичных объектов, попадающих в каждую группу).
В первом случае для графического изображения необходимо сначала построить частотное распределение, тогда как во втором случае это распределение уже дано. Поэтому пользоваться описанными выше способами визуализации данных нельзя (иначе вы будете строить "гистограмму гистограммы"). Поэтому надо помнить, что для изображения уже готовых вариационных рядов в программе STATISTICA нельзя обращаться к командам и графическим кнопкам, которые называются Histograms. В этом случае подходят команды построения двумерных и трехмерных графиков из раздела Графики главного меню (2D Графики или 3D Последовательные графики).
Пример 1.7. Обратимся к таблице распределения заболеваемости основными заразными болезнями по регионам Российской Империи в 1912 г. (файл Deseases.sta). В отличие от предыдущего файла в этой таблице содержатся не индивидуальные данные о том, какой болезнью заболел каждый человек, а суммарные данные, сгруппированные по названиям болезней. Таким образом, в строках этой таблицы стоят различные категории болезней, в столбцах – количество заболевших (т.е. частоты этих категорий). Различным регионам страны соответствуют разные столбцы таблицы.

Рис. 1.20. Исходные данные (файл Deseases.sta)
Построим графическое изображение уже готового вариационного ряда заболеваемости по Европейской России (первый столбец). Поскольку категории болезней не могут быть упорядочены, выберем круговую диаграмму для представления структуры заболеваемости.
Мы уже рассматривали построение круговой диаграммы для признака "профиль образования" в таблице Duma, поэтому обратим внимание на отличия в использовании этого типа графика в данном случае.

Рис. 1.21. Диалоговое окно построения круговой диаграммы
для сгруппированных данных
Как и раньше, выберем команду 2D Графики | Смешанные графики | PieCharts в пункте Graphs основного меню программы. На вкладке Дополнительно в разделе Тип графика надо обязательно надо указать Values (исходные значения), тогда программа не станет вторично группировать данные. В разделе Ярлыки надо выбрать Case Names (имена объектов, в нашем случае – имена категорий), чтобы названия категорий появились на графике. Наконец, в разделе Легенда надо, как и раньше, выбрать Text and Percent, чтобы на графике были проставлены не только названия категорий, но и относительные частоты их встречаемости (см. рис. 1.21). После нажатия графической кнопки ОК получится круговая диаграмма, представленная на рис. 1.22.
Для сравнения структуры заболеваемости в различных регионах можно на одном двумерном (или даже трехмерном, объемном) графике построить сразу несколько распределений. На рис. 1.23 показан такой линейный график для Сибири и Средней Азии, полученный при выполнении последовательности действий Graphs | 2D Графики | Последовательный/Стыковочный и выбором в разделе Variables двух упомянутых регионов. Анализ такого графика позволяет сделать вывод о существенном совпадении структуры заболеваемости в двух регионах страны.

Рис. 1.22. Круговая диаграмма, соответствующая параметрам рис. 1.21
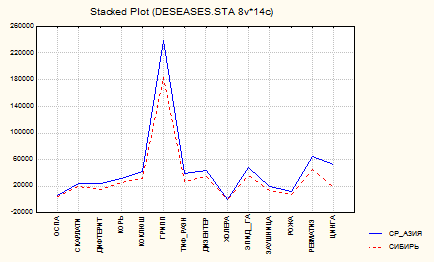
Рис. 1.23. Линейный график для двух вариационных рядов
1.4. Категоризованные распределения [3]
Дескриптивная статистика позволяет также строить распределения значений одной переменной в зависимости от значений другой. Чаще всего категоризованные распределения строят для того, чтобы выявить взаимосвязи между количественным и качественным признаками, точнее, влияние категории качественного признака на характер распределения количественного. Результаты при этом представляются либо в виде категоризованных гистограмм, либо в виде категоризованных средних.
Пример 1.8.Вернемся к таблице Duma.sta. Эта таблица кроме количественного признака "возраст" содержит номинальный признак "партия", отражающий фракционную принадлежность депутата. Построим распределение депутатов по возрасту отдельно для фракций кадетов и трудовиков.
Прежде всего, вернемся к диалоговому окну дескриптивной статистики, воспользуемся графической кнопкой Variables и выберем тот признак, для которого будут строиться распределения – "возраст". Далее перейдем на вкладку Categ. Plots (категоризованные графики – см. рис. 1.24).

Рис. 1.24. Вкладка Categ. Plots диалогового окна дескриптивной статистики
Здесь в разделе Categorized histograms надо выбрать группирующие признаки (их быть несколько, но мы ограничимся более простым случаем – см. рис. 1.25). В нашем случае это будет признак "партия". Нажав кнопку OK, мы окажемся в диалоговом окне (см. рис. 1.26), в котором необходимо указать, для каких значений группирующей переменной мы хотим строить распределение.
Рис. 1.25. Окно выбора группирующей переменной

Рис. 1.26. Диалоговое окно выбора групп для построения
категоризованных распределений
В нашем распоряжении две графические кнопки – All (все категории) и Zoom (просмотр списка категорий). Если вы не помните числовых кодов категорий, нажмите Zoom и просмотрите список кодов; затем впишите нужные, разделяя их пробелами. Задав коды, соответствующие значениям "кадет" и "трудовик", мы получим одновременно две гистограммы, приведенные на рис. 1.27.
Видно, что для двух разных категорий параметры распределения несколько различаются. К примеру, мода возраста для категории "трудовик" находится на интервале от 30 до 35 лет, в то время как для "кадетов" – от 35 до 40 лет. Видно также, что во фракции трудовиков больше молодых депутатов, тогда как во фракции кадетов – больше пожилых.
 Рис. 1.27. Распределение по возрасту в зависимости
Рис. 1.27. Распределение по возрасту в зависимости
от фракционной принадлежности

Рис. 1.28. Зависимость среднего возраста
от категории группировочного признака "партия"
Если же на вкладке Categ. Plots в диалоговом окне дескриптивной статистики воспользоваться другой графической кнопкой – Categorized Means (Interaction) Plots (график категоризованных средних), то можно получить графическое представление зависимости среднего возраста от фракционной принадлежности по всем значениям признака "партия" (см. рис. 1.28). Для того чтобы получить результат, необходимо выполнить ту же последовательность действий, что и для построения категоризованных гистограмм, только в диалоговом окне выбора категорий для признака "партия" надо указать – All (все).
ВОПРОСЫ
1. Типы признаков.
2. Что такое количественный признак? Непрерывные и дискретные признаки.
3. Что называется вариационным рядом?
4. Что такое относительная частота?
5. Графическая интерпретация вариационного ряда.
6. Что такое гистограмма?
7. Меры среднего уровня.
8. Меры разброса.
9. В чем сходство и различие между s и V?
10. В каких единицах измеряется коэффициент вариации?
11. Как можно сравнить два вариационных ряда?
12. Что такое категоризованное распределение?
ЗАДАНИЯ
1. Используя файл Industry.sta, построить распределение предприятий по:
а) числу рабочих;
б) мощности двигателей;
в) объему производства.
В какую группу попадает наибольшая доля предприятий? Объяснить значения кумулятивных частот.
2. Используя файл Industry.sta, построить распределение предприятий по:
а) числу рабочих в целом по всей совокупности;
б) числу рабочих в металлообрабатывающей отрасли промышленности;
в) объему производства по всей совокупности;
г) объему производства в металлообрабатывающей отрасли промышленности.
3. Построить гистограмму ряда:
возраст число людей
до 20 40
20-40 60
40-80 70
4. Найти медиану ряда: 25, 20, 27, 32, 21, 17, 22, 28.
5. Найти  , s и V для ряда: 2, 3, 4, 5, 6.
, s и V для ряда: 2, 3, 4, 5, 6.
6. Некий коллектив людей разбит на 3 группы, составляющие, соответственно, 1/4, 5/8 и 1/8 части от численности всего коллектива. Средний возраст в первой группе – 20 лет, во второй – 23 года и в третьей – 29 лет. Найти средний возраст для всего коллектива.
7. Первая группа, состоящая из 14 человек, имеет средний стаж работы 10 лет, а вторая группа, состоящая из 36 человек, имеет средний стаж 15 лет. Определить средний стаж объединенной группы из 50 человек.
[1] Упомянем также квартили, разбивающие ранжированный ряд значений признака на 4 части по 25% значений в каждой. Квартили при этом называются нижней, средней и верхней (при этом, очевидно, средняя квартиль совпадает с медианой). Аналогично можно ввести децили, разбивающие вариационный ряд значений на группы по 10% чисел и другие квантили - числа, разбивающие упорядоченную совокупность значений признака на равные по объему части.
[2] Среди всех вероятностных распределений есть такие, которые особенно часто используются на практике, они хорошо изучены. Особую роль играет т.н. нормальное распределение, которое часто реализуется во многих ситуациях, в которых на поведение случайной величины влияет большое количество независимых случайных факторов, среди которых нет сильно выделяющихся. Нормальное распределение можно изобразить графически в виде симметричной одновершинной кривой, напоминающей по форме колокол. Высота (ордината) каждой точки этой кривой показывает, как часто встречается соответствующее значение. Эти ординаты обобщают введенное ранее понятие частоты вариационного ряда. Форма нормальной кривой и положение ее на оси абсцисс полностью определяются двумя параметрами: средним арифметическим значением и средним квадратическим отклонением. Вершина кривой соответствует среднему арифметическому значению, т.е. наиболее часто встречаются значения, близкие к среднему, а по мере удаления от него частота падает. Более подробно нормальное распределение рассматривается в главе 2.
[3] Этот раздел имеет отношение также и к материалу главы 3, поскольку он касается зависимости между признаками. Исходя из этого, к нему полезно вернуться при изучении методов анализа взаимосвязей.
|
из
5.00
|
Обсуждение в статье: Частотные распределения качественных признаков |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы