 |
Главная |


Парный корреляционный анализ
|
из
5.00
|
Основные понятия.
В курсе математического анализа одним из основных понятий является понятие функциональной зависимости, при которой каждому значению одной переменной ставится в соответствие единственное вполне определенное значение другой. Такая зависимость на практике встречается достаточно редко и является, как правило, некоторой идеализацией реально существующих зависимостей. Тем не менее функциональная зависимость играет важную роль в тех областях науки, где подобная идеализация не приводит к грубым неточностям и противоречиям (классическая механика, классическая электродинамика и др.). Развитие естественных наук (особенно в XX веке) привело к тому, что стали изучаться явления и процессы, для описания которых функциональные зависимости оказались непригодными.
В математической статистике вводится понятие статистической зависимости.
Определение 1. Зависимость между случайными величинами Y и Х называется статистической (стохастической), если каждому значению одной случайной величины (Х) соответствует определенное условное распределение другой случайной величины (Y).
Статистическую зависимость можно перевести в функциональную, если рассмотреть зависимость условного математического ожидания СВ Y от Х или условного математического ожидания Х от Y.
Определение 2. Корреляционной зависимостью называется функциональная зависимость между значениями одной случайной величины и условным математическим ожиданием другой.
Аналитически корреляционную зависимость можно задать следующим образом
MX(Y) = f(x), MY(X) = g(y), (*)
где f(x) ¹ const и g(y) ¹ const.
Уравнения (*) называются уравнениями регрессии.
Основные задачи данного раздела:
1) выявление связи между случайными величинами и оценка ее тесноты;
2) установление вида регрессии.
Первая задача является основной задачей корреляционного анализа, вторая – регрессионного.
Парный корреляционный анализ.
Решение основной задачи корреляционного анализа можно разбить на следующие этапы.
1. Сбор выборки пар (xi, yj) для характеристики закона распределения двумерной СВ (Х, Y) и ее запись в удобной для работы форме.
2. Расчет численных значений выборочных коэффициентов, характеризующих связь между СВ Х и Y.
3. Проверка гипотезы о значимости связи между Х и Y.
Рассмотрим каждый из этапов подробнее.
1. Данные о статистической зависимости удобно задавать в виде корреляционной таблицы 1.
В данной таблице nij – частота, с которой в опыте встречается пара
(xi, yj), где i = 1, 2, 3, …, k; j = 1, 2, 3, …, m.
Таблица 1.
| yj xi | y1 | y2 | … | ym | S = nx |
| x1 | n11 | n12 | … | n1m | 
|
| x2 | n21 | n22 | … | n2m | 
|
| … | … | … | … | … | … |
| xk | nk1 | nk2 | … | nkm | 
|
| S = ny | 
| 
| … | 
| 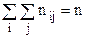
|
2. Для оценки тесноты используются коэффициент корреляции rXY (rYX) и корреляционное отношение hXY (hYX).
Коэффициент корреляции служит для характеристики тесноты линейной зависимости между СВ Х и Y.
По данным выборки коэффициент корреляции рассчитывается следующим образом
 ,
,
где  ,
,  ,
,  , SX, SY – выборочные средние квадратические отклонения случайных величин Х и Y соответственно.
, SX, SY – выборочные средние квадратические отклонения случайных величин Х и Y соответственно.
Свойства коэффициента корреляции.
1) rXY = rYX = r.
2) Коэффициент корреляции принимает значения на отрезке [-1; 1], т.е.
-1 £ r £ 1.
3) При r = ± 1 корреляционная связь является линейной функциональной.
4) При r = 0 линейная корреляционная связь отсутствует.
5) Если случайные величины независимы, то r = 0.
Заметим, что равенство r = 0 говорит об отсутствии только линейной корреляционной связи, а не корреляционной связи вообще
Несложно заметить, что r является выборочной точечной оценкой коэффициента корреляции rГ между случайными величинами Х и Y генеральной совокупности
 .
.
Для проверки значимости выборочного коэффициента корреляции рассматривается гипотеза Н0: rГ = 0 и гипотеза Н1: rГ ¹ 0.
При справедливости гипотезы Н0 статистика

имеет t-распределение Стьюдента с l = n – 2 степенями свободы.
Приведем правило проверки гипотезы о значимости выборочного коэффициента корреляции.
1. По данным выборки рассчитывается величина  .
.
2. Находится значение t(1 - a; n – 2) по таблице IV распределения Стьюдента.
3. Если |tЭ| £ t(1 - a; n – 2), то нет оснований отвергнуть гипотезу Н0:
rГ = 0. Если |tЭ| > t(1 - a; n – 2) гипотеза Н0 отвергается, т.е. rГ ¹ 0.
Коэффициент корреляции r является показателем тесноты линейной связи. Для оценки тесноты нелинейной связи вводится числовая характеристика – корреляционное отношение.
Генеральным корреляционным отношением называется величина
 или
или  (*)
(*)
В уравнении (*)  и
и 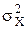 – общие дисперсии СВ Y и Х,
– общие дисперсии СВ Y и Х,  – межгрупповая дисперсия СВ Y, которая характеризует разброс значений реализаций СВ Y относительно определенных реализаций СВ Х (для
– межгрупповая дисперсия СВ Y, которая характеризует разброс значений реализаций СВ Y относительно определенных реализаций СВ Х (для  - аналогично). Величины hY,X и hX,Y в общем случае являются различными, поэтому там, где это необходимо, мы будем снабжать символ корреляционного отношения соответствующими индексами. Если такой необходимости нет, то будем использовать символ h.
- аналогично). Величины hY,X и hX,Y в общем случае являются различными, поэтому там, где это необходимо, мы будем снабжать символ корреляционного отношения соответствующими индексами. Если такой необходимости нет, то будем использовать символ h.
Корреляционное отношение характеризует степень концентрации двумерного распределения (X, Y) вблизи линии регрессии.
Аналогично можно ввести выборочное корреляционное отношение, для чего в уравнении (*) значения и нужно заменить на их выборочные аналоги.
Свойства корреляционного отношения.
1) 0 £ h £ 1.
2) Если h = 0, то корреляционная связь отсутствует.
3) Если h = 1, между переменными Х и Y существует функциональная связь.
4) h ³ |r|.
5) Если h = |r|, то между случайными величинами существует линейная корреляционная зависимость.
Для проверки значимости корреляционного отношения используется статистика
 ,
,
где n – объем выборки, m – число интервалов по сгруппированным данным.
Если справедлива гипотеза Н0: h = 0, то СВ F имеет распределение Фишера.
Таким образом, если  , где a - выбранный уровень значимости, k1 = n – 1, k2 = n – m, то нет оснований отвергнуть гипотезу Н0. Если
, где a - выбранный уровень значимости, k1 = n – 1, k2 = n – m, то нет оснований отвергнуть гипотезу Н0. Если  , то гипотеза Н0 отвергается и делается вывод о наличии между случайными величинами корреляционной зависимости.
, то гипотеза Н0 отвергается и делается вывод о наличии между случайными величинами корреляционной зависимости.
П р и м е р 1. Распределение Х и Y приводится в корреляционной таблице 2.
Таблица 2.
| Y X | nx | |||||||||
| -2 | ||||||||||
| -1 | ||||||||||
| ny |
Найти коэффициент корреляции r, корреляционные отношения hX,Y и hY,X и проверить их значимость.
Решение. Найдем выборочные числовые характеристики случайных величин Х и Y.
 .
.
 .
.

 .
.
 .
.
 .
.
 .
.
 .
.
 .
.
Найдем коэффициент корреляции
 .
.
Полученный результат говорит о том, что между величинами Х и Y нет линейной корреляционной связи. Выясним, есть ли между величинами Y и Х нелинейная корреляционная связь, рассчитав корреляционные отношения и hY,X и hX,Y.
Для расчета hY,X необходимо найти значение межгрупповой дисперсии Y для определенных значений xi
 .
.
Найдем средние значения величины Y, вычисленные по группам
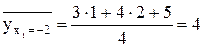 ,
,
 ,
,
 ,
,
 ,
,
 .
.
 .
.
Следовательно, 
Таким образом СВ Y не зависит корреляционно от величины Х.
Рассчитаем hX,Y.
Найдем значение межгрупповой дисперсии величины Х для определенных значений yi.
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 .
.
 .
.
 .
.
Проверим значимость hX,Y.
Рассмотрим наблюдаемое значение критерия F
 .
.
Используя таблицу V приложений, найдем значение  .
.
Так как , то величина Х корреляционно зависит от величины Y. Более того, можно сказать, что данная зависимость близка к функциональной, поскольку hX,Y » 1.
Случай, когда корреляционная зависимость Х от Y есть, а зависимости Y от Х нет, не является чем-то экстраординарным. Например, существует зависимость средней урожайности от количества выпавших осадков, однако количество осадков от урожайности не зависит.
Парная регрессия.
Если задачей корреляционного анализа является установление зависимости между величинами Х и Y, то задачей регрессионного анализа является установление формы зависимости между переменными.
В предыдущем пункте мы определили уравнение регрессии как уравнение вида
МХ(Y) = f(x). (*)
Уравнение (*) можно записать следующим образом
у = f(x) + e,
где f(х) – функция регрессии, e - случайная составляющая, характеризующая отклонение у от функции регрессии.
В дальнейшем будем полагать, что величина e удовлетворяет следующим условиям:
1) М(e) = 0;
2) выборочные значения e являются независимыми значениями;
3) величина e имеет нормальное распределение.
Регрессионный анализ не может самостоятельно по данной выборке предложить ту или иную форму регрессионной кривой. Вид регрессии должен быть выяснен с помощью иной теории, в которой рассматривалась бы суть данного явления. Например, утверждение о том, что энергия равновесного излучения пропорциональна четвертой степени температуры, было получено Стефаном и Больцманом из термодинамических соображений, а коэффициент s (U = s T4) был найден в результате обработки опытных данных.
На практике наиболее часто встречается одна из простейших моделей регрессии – линейная. Уравнение линейной регрессии имеет вид
y = а x + b + e.
Сформулируем задачу регрессионного анализа для данного случая.
По выборке объемом n, составленной из реализаций двумерной СВ (Х,Y), найти оценки параметров а и b и проверить, соответствует ли линейная модель экспериментальным данным.
Очевидно, что оценки а и b следует подобрать так, чтобы значения
 = a xi + b как можно ближе находились к экспериментальным значениям. В качестве меры близости удобно взять сумму квадратов отклонений экспериментальных данных от теоретических. Можно показать, что в случае, когда e имеет нормальное распределение, наилучшие оценки параметров регрессии получают с помощью метода наименьших квадратов (МНК).
= a xi + b как можно ближе находились к экспериментальным значениям. В качестве меры близости удобно взять сумму квадратов отклонений экспериментальных данных от теоретических. Можно показать, что в случае, когда e имеет нормальное распределение, наилучшие оценки параметров регрессии получают с помощью метода наименьших квадратов (МНК).
Применим МНК для отыскания оценок параметров а и b.
Составим сумму квадратов отклонений как функцию возможных, но неизвестных параметров а и b:
 .
.
Для минимизации функции F приравняем к нулю ее частные производные по параметрам

Преобразуем полученную систему к более удобному виду

Учитывая, что  ,
,  и
и  (k = 1, 2), получим
(k = 1, 2), получим

Отсюда
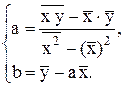 (*)
(*)
Заметим, что, если искать уравнение линейной регрессии х от у, т.е.
x = c y + d, то
 (**)
(**)
Учитывая, что 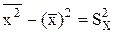 ,
,  , rXY = rYX = r =
, rXY = rYX = r =  , где SX и SY – выборочные средние квадратические отклонения, преобразуем уравнения (*) и (**) к следующему виду
, где SX и SY – выборочные средние квадратические отклонения, преобразуем уравнения (*) и (**) к следующему виду


Таким образом, уравнения линейной регрессии можно записать в виде:
 ,
,

или
 ,
,
 ,
,
где ух, ху – условные (групповые) средние, представляющие выборочные оценки MX(Y) и MY(X) соответственно.
Найдем тангенс угла между прямыми регрессии (см. рис.1) с угловыми коэффициентами а и  .
.
  у у
 a a
  
|

 х
хРис.1.
 .
.
Из полученной формулы видно, что при r = ± 1 уравнения регрессии совпадают. Если r = 0, то прямые регрессии перпендикулярны и их уравнения имеют вид:  ,
,  .
.
Значимость уравнения регрессии проверяют, используя дисперсионный анализ. В данном случае общую дисперсию разбивают на дисперсию, которая обусловлена регрессией, и дисперсию, которая обусловлена действием случайных факторов, т.е.
 .
.
Введем обозначения  ,
, 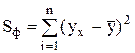 ,
,  .
.
|
из
5.00
|
Обсуждение в статье: Парный корреляционный анализ |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы