 |
Главная |


Типовая задача построения множественной регрессии и анализа ее качества
|
из
5.00
|
Задача. По 20 предприятиям (табл. 3.1) региона изучается зависимость выработки продукции на одного работника y (тыс. грн.) от ввода в действие новых основных фондов x1 (% от стоимости фондов на конец года) и от удельного веса рабочих высокой квалификации в общей численности рабочих x2 (%).
Таблица 3.1. Выработка продукции по предприятиям на одного работника
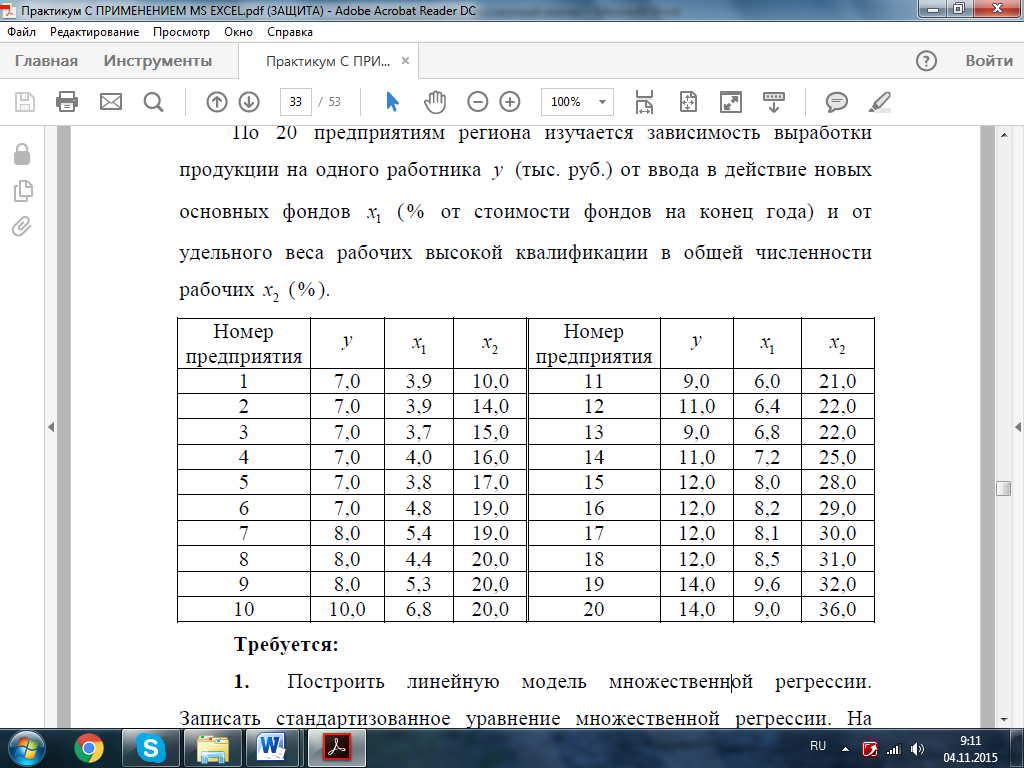
Требуется:
1. Построить линейную модель множественной регрессии. Записать стандартизованное уравнение множественной регрессии. На основе стандартизованных коэффициентов регрессии и средних коэффициентов эластичности ранжировать факторы по степени их влияния на результат.
2. Найти коэффициенты парной, частной и множественной корреляции. Провести анализ их значений.
3. Найти скорректированный коэффициент множественной детерминации. Сравнить его с общим коэффициентом детерминации.
4. С помощью F-критерия Фишера оценить статистическую надежность уравнения регрессии и коэффициента детерминации  .
.
5. С помощью t -критерия оценить статистическую значимость коэффициентов чистой регрессии.
6. С помощью частных F -критериев Фишера оценить целесообразность включения в уравнение множественной регрессии фактора x1 после x2 и фактора x2 после x1.
7. Составить уравнение линейной парной регрессии, оставив лишь один значащий фактор.
8. Найти матрицу парных коэффициентов корреляции с помощью инструмента анализа данных Корреляция MS Excel.
9. Выполнить решение задачи с помощью функции Регрессия пакета анализа MS Excel и привести графическую интерпретацию результатов решения.
Решение.
Для удобства проведения расчетов поместим результаты промежуточных расчетов в таблицу 3.2:
Таблица 3.2. Расчет компонент для нахождения уравнения регрессии

Найдем среднеквадратические отклонения регрессии и признаков:

1. Для нахождения параметров линейного уравнения множественной регрессии

рассчитаем сначала парные коэффициенты корреляции:

Находим по готовым формулам коэффициенты чистой регрессии и параметр a:

В результате получим следующее уравнение множественной регрессии:

Уравнение регрессии показывает, что при увеличении ввода в действие основных фондов на 1% (при неизменном уровне удельного веса рабочих высокой квалификации) выработка продукции на одного рабочего увеличивается в среднем на 0,946 тыс. грн., а при увеличении удельного веса рабочих высокой квалификации в общей численности рабочих на 1% (при неизменном уровне ввода в действие новых основных фондов) выработка продукции на одного рабочего увеличивается в среднем на 0,086 тыс. грн.
После нахождения уравнения регрессии составим новую расчетную таблицу 3.3 для определения теоретических значений результативного признака, остаточной дисперсии и средней ошибки аппроксимации.
Таблица 3.3. Расчет компонент регрессионного анализа
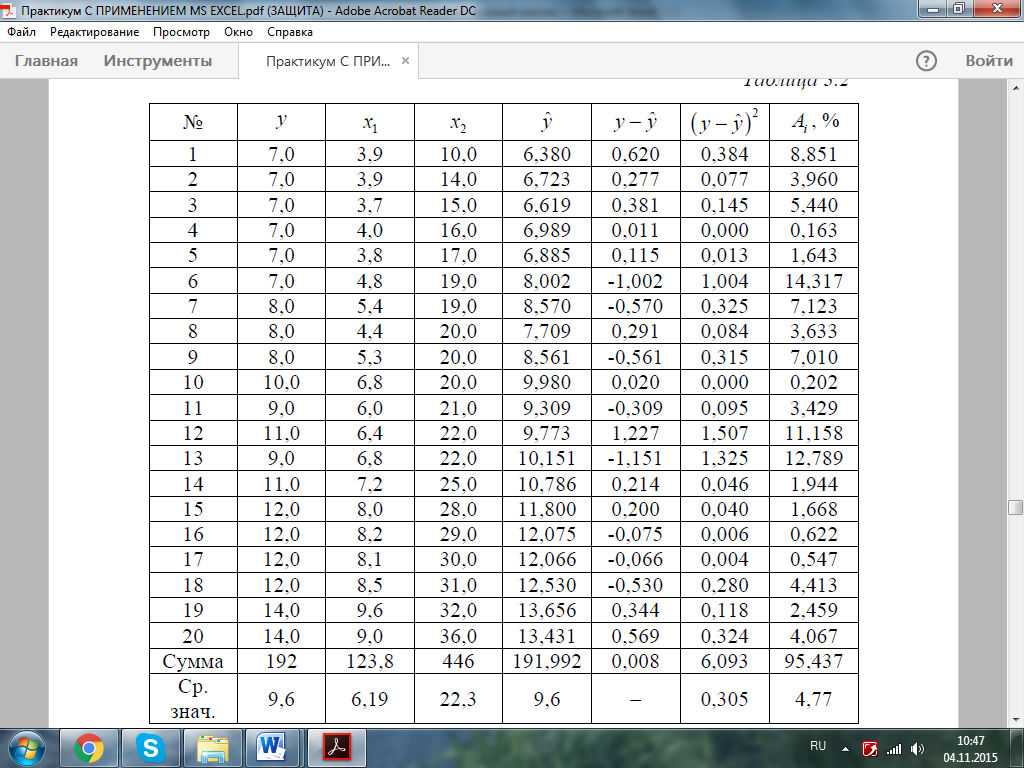
Остаточная дисперсия:

Средняя ошибка аппроксимации:

Качество модели, исходя из относительных отклонений по каждому наблюдению, признается хорошим, т.к. средняя ошибка аппроксимации не превышает 10%.
Коэффициенты b1 и b2 стандартизованного уравнения регрессии

находятся по формулам

То есть стандартизованное уравнение будет выглядеть следующим образом:

Так как стандартизованные коэффициенты регрессии можно сравнивать между собой, то можно сказать, что ввод в действие новых основных фондов оказывает большее влияние на выработку продукции, чем удельный вес рабочих высокой квалификации.
Сравнивать влияние факторов на результат можно также при помощи средних коэффициентов эластичности:

Вычисляем:

То есть увеличение только основных фондов (от своего среднего значения) или только удельного веса рабочих высокой квалификации на 1% увеличивает в среднем выработку продукции на 0,61% или 0,20% соответственно. Таким образом, подтверждается большее влияние на результат y фактора x1, чем фактора x2.
2. Коэффициенты парной корреляции мы уже нашли:

Они указывают на весьма сильную связь каждого фактора с результатом, а также высокую межфакторную зависимость (факторы x1 и x2 явно коллинеарны, так как  ). При такой сильной межфакторной зависимости рекомендуется один из факторов исключить из рассмотрения.
). При такой сильной межфакторной зависимости рекомендуется один из факторов исключить из рассмотрения.
Частные коэффициенты корреляции характеризуют тесноту связи между результатом и соответствующим фактором при устранении влияния других факторов, включенных в уравнение регрессии.
При двух факторах частные коэффициенты корреляции рассчитываются следующим образом:
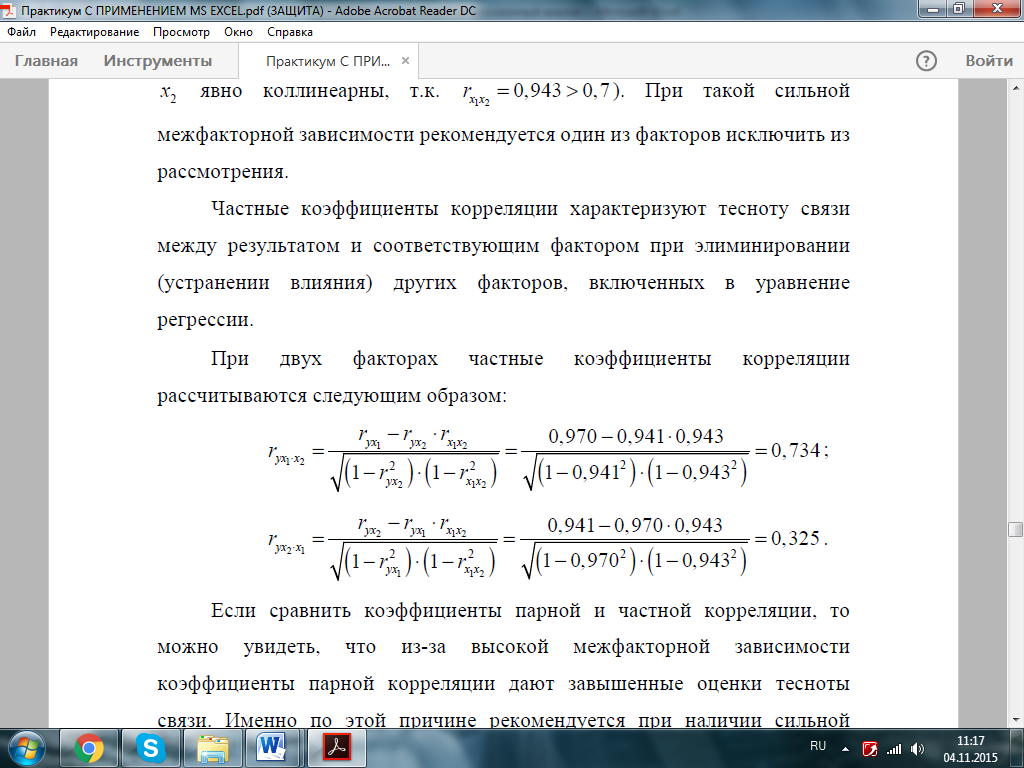
Если сравнить коэффициенты парной и частной корреляции, то можно увидеть, что из-за высокой межфакторной зависимости коэффициенты парной корреляции дают завышенные оценки тесноты связи. Именно по этой причине рекомендуется при наличии сильной коллинеарности (взаимосвязи) факторов исключать из исследования тот фактор, у которого теснота парной зависимости меньше, чем теснота межфакторной связи.
Коэффициент множественной корреляции определить через матрицы парных коэффициентов корреляции:
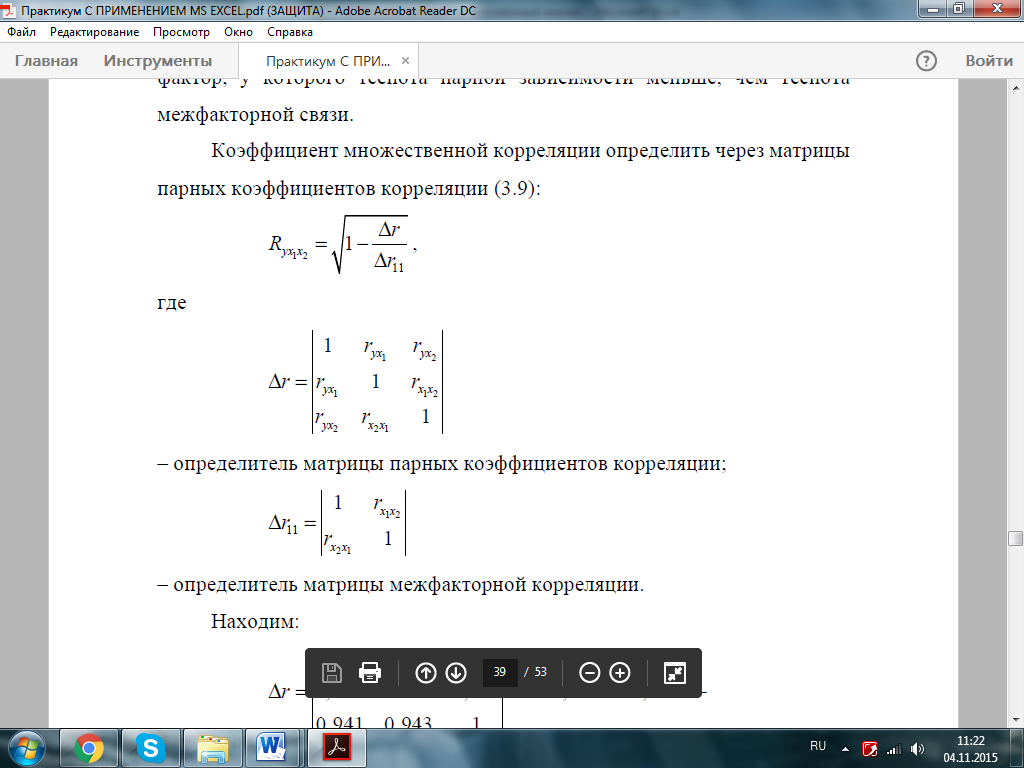
где Δr – определитель матрицы парных коэффициентов корреляции и Δr11– определитель матрицы межфакторной корреляции представляются как

Находим:

Аналогичный результат получим при использовании других формул:
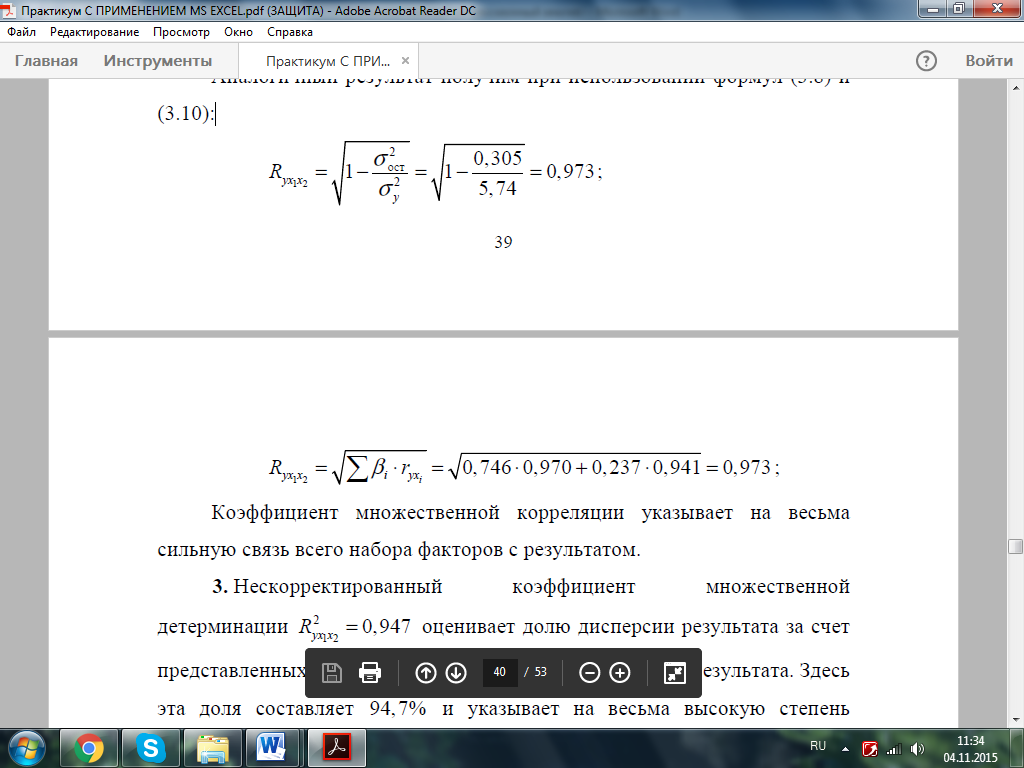
Коэффициент множественной корреляции указывает на весьма сильную связь всего набора факторов с результатом.
3. Нескорректированный коэффициент множественной детерминации 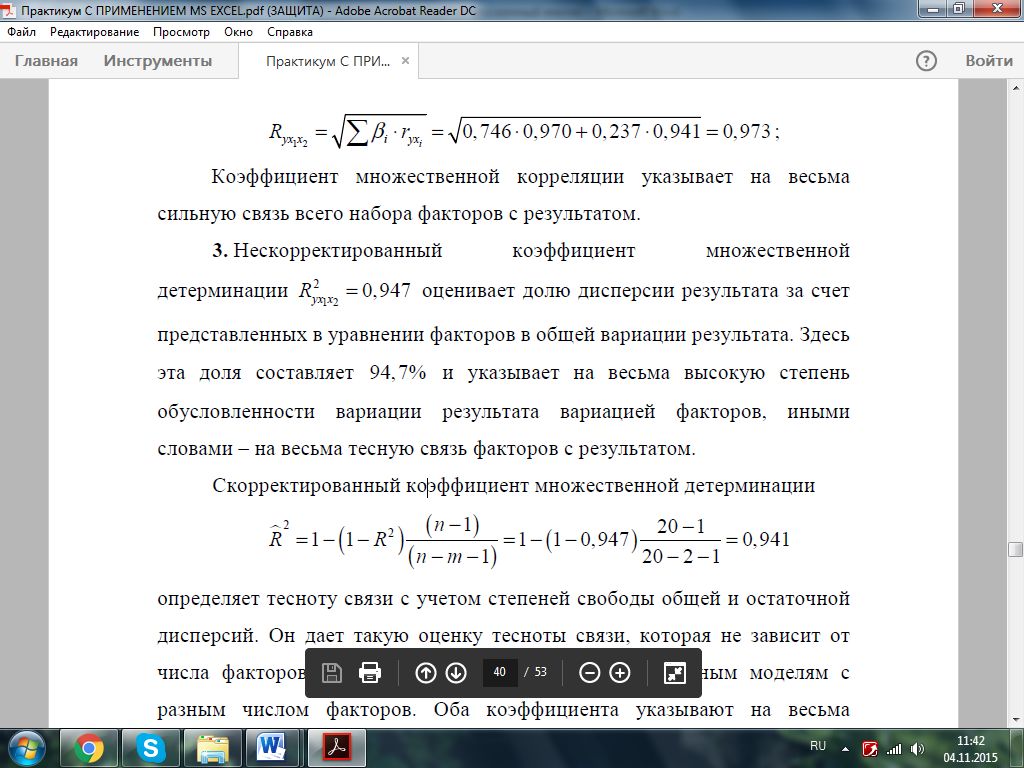 оценивает долю дисперсии результата за счет представленных в уравнении факторов в общей вариации результата. Здесь эта доля составляет 94,7% и указывает на весьма высокую степень обусловленности вариации результата вариацией факторов, иными словами – на весьма тесную связь факторов с результатом.
оценивает долю дисперсии результата за счет представленных в уравнении факторов в общей вариации результата. Здесь эта доля составляет 94,7% и указывает на весьма высокую степень обусловленности вариации результата вариацией факторов, иными словами – на весьма тесную связь факторов с результатом.
Скорректированный коэффициент множественной детерминации

определяет тесноту связи с учетом степеней свободы общей и остаточной дисперсий. Он дает такую оценку тесноты связи, которая не зависит от числа факторов и поэтому может сравниваться по разным моделям с разным числом факторов. Оба коэффициента указывают на весьма высокую (более 94%) детерминированность результата y в модели факторами x1и x2.
4. Оценку надежности уравнения регрессии в целом и показателя тесноты связи  дает F-критерий Фишера:
дает F-критерий Фишера:
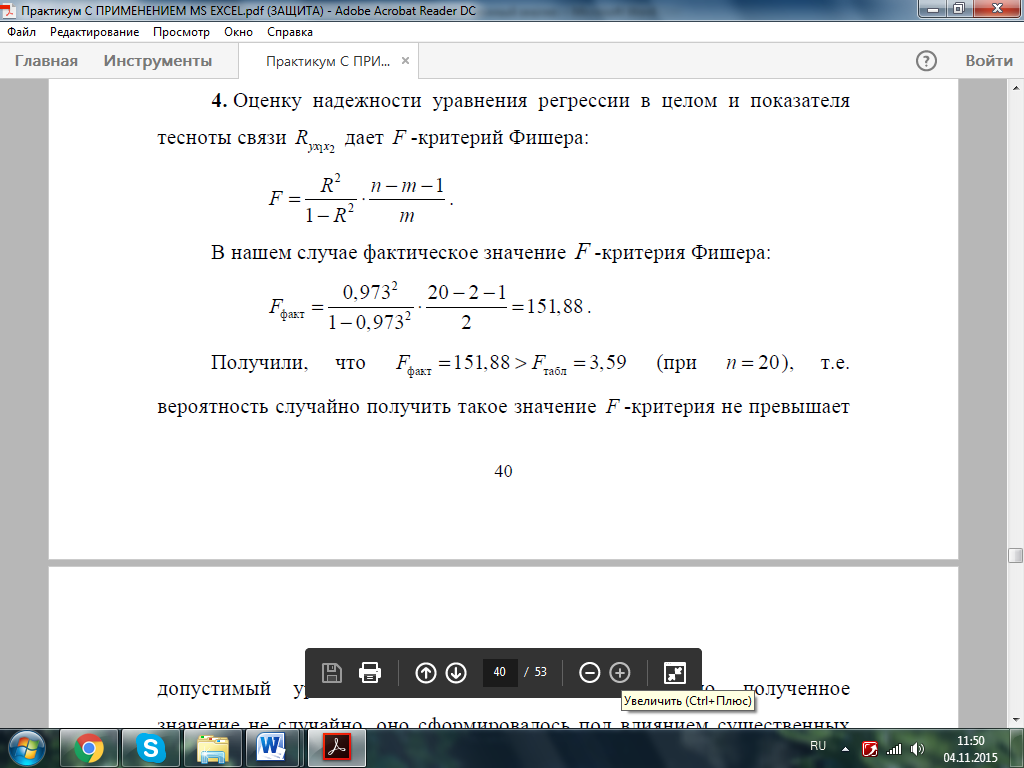
В нашем случае фактическое значение F-критерия Фишера:
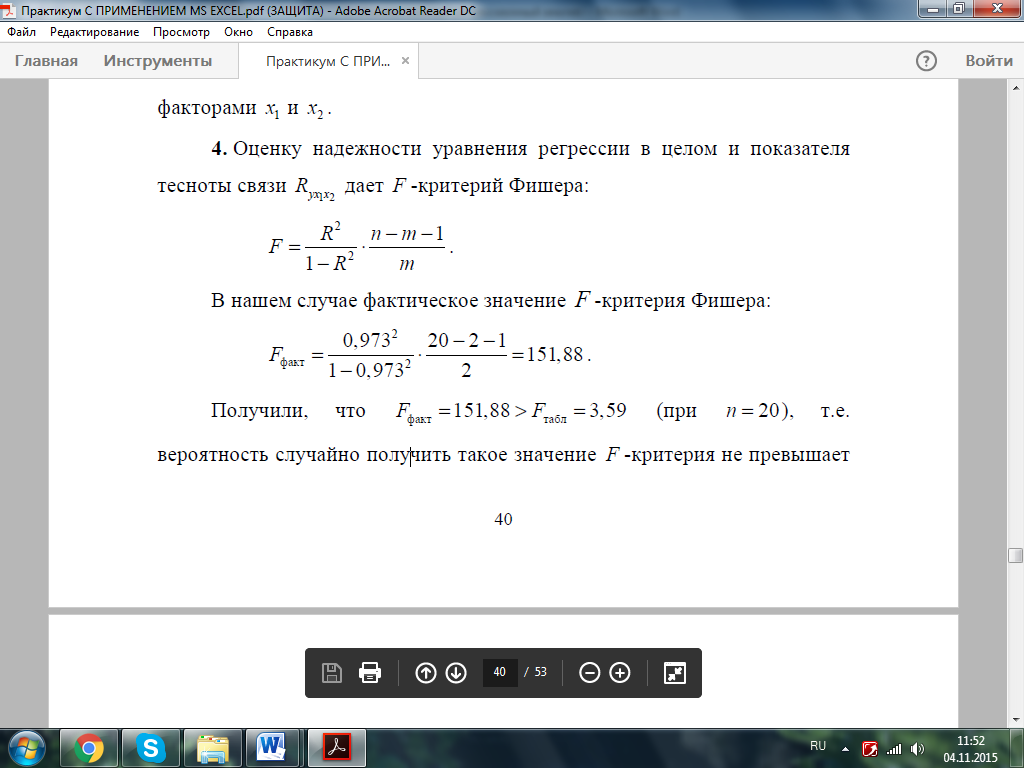
Получили, что факт  (при n=20), то есть вероятность случайно получить такое значение F-критерия не превышает допустимый уровень значимости 5%. Следовательно, полученное значение не случайно, оно сформировалось под влиянием существенных факторов, то есть подтверждается статистическая значимость всего уравнения и показателя тесноты связи
(при n=20), то есть вероятность случайно получить такое значение F-критерия не превышает допустимый уровень значимости 5%. Следовательно, полученное значение не случайно, оно сформировалось под влиянием существенных факторов, то есть подтверждается статистическая значимость всего уравнения и показателя тесноты связи  .
.
5. Оценим статистическую значимость параметров чистой регрессии с помощью t -критерия Стьюдента. Рассчитаем стандартные ошибки коэффициентов регрессии по формулам:

Фактические значения t-критерия Стьюдента:

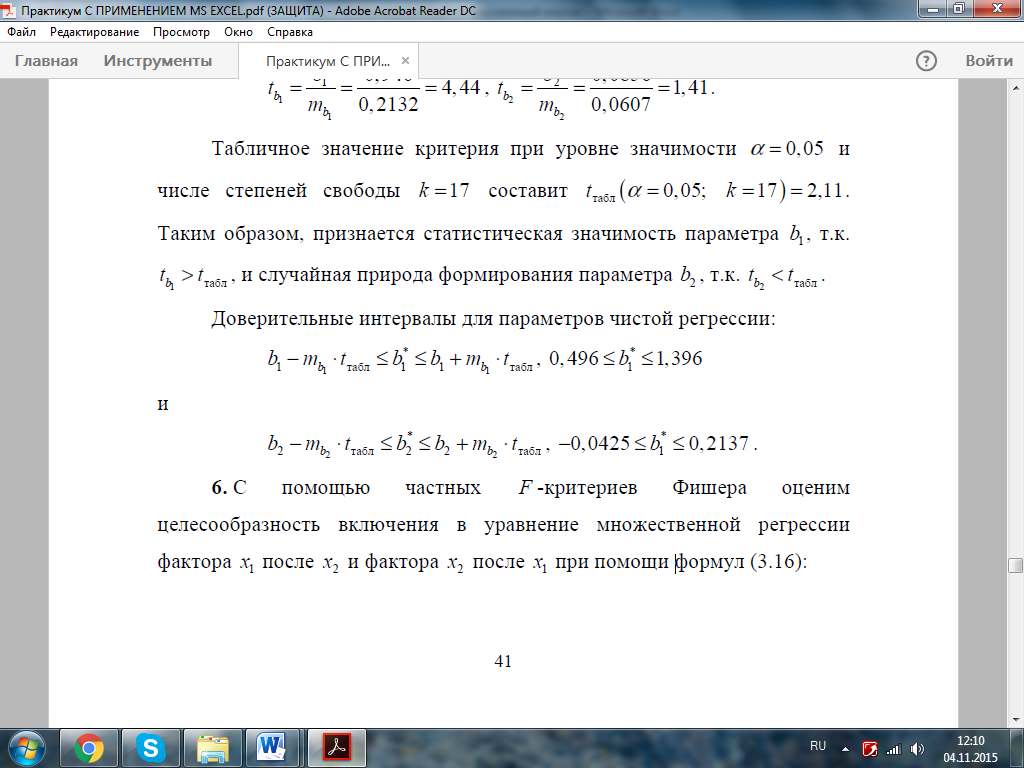
Табличное значение критерия при уровне значимости α = 0,05 и числе степеней свободы k =17 составит t табл (a = 0,05; k =17) = 2,11.
Таким образом, признается статистическая значимость параметра b1, так как t b1 > tтабл, и случайная природа формирования параметра b2, так как tb2 < tтабл.
Доверительные интервалы для параметров чистой регрессии:
6. С помощью частных F-критериев Фишера оценим целесообразность включения в уравнение множественной регрессии фактора x1 после x2 и фактора x2 после x1при помощи формул:

Найдем  и :
и :

Имеем:

Получили, что Fx2=1,924 < Fтабл (α = 0,05; k1= 1; k 2=17) = 4,145. Следовательно, включение в модель фактора x2 после того, как в модель включен фактор x1 статистически нецелесообразно: прирост факторной дисперсии за счет дополнительного признака x2 оказывается незначительным, несущественным; фактор x2 включать в уравнение после фактора x1 не следует.
Если поменять первоначальный порядок включения факторов в модель и рассмотреть вариант включения x1 после x2, то результат расчета частного F-критерия для x1 будет иным. Fx1 =19,89 > F табл = 4,45 , то есть вероятность его случайного формирования меньше принятого стандарта α = 0,05 (5%). Следовательно, значение частного F -критерия для дополнительно включенного фактора x1 не случайно, является статистически значимым, надежным, достоверным: прирост факторной дисперсии за счет дополнительного фактора x1 является существенным. Фактор x1 должен присутствовать в уравнении, в том числе в варианте, когда он дополнительно включается после фактора x2.
7. Общий вывод состоит в том, что множественная модель с факторами x1 и x2 с  содержит неинформативный фактор x2. Если исключить фактор x2, то можно ограничиться уравнением парной регрессии:
содержит неинформативный фактор x2. Если исключить фактор x2, то можно ограничиться уравнением парной регрессии:
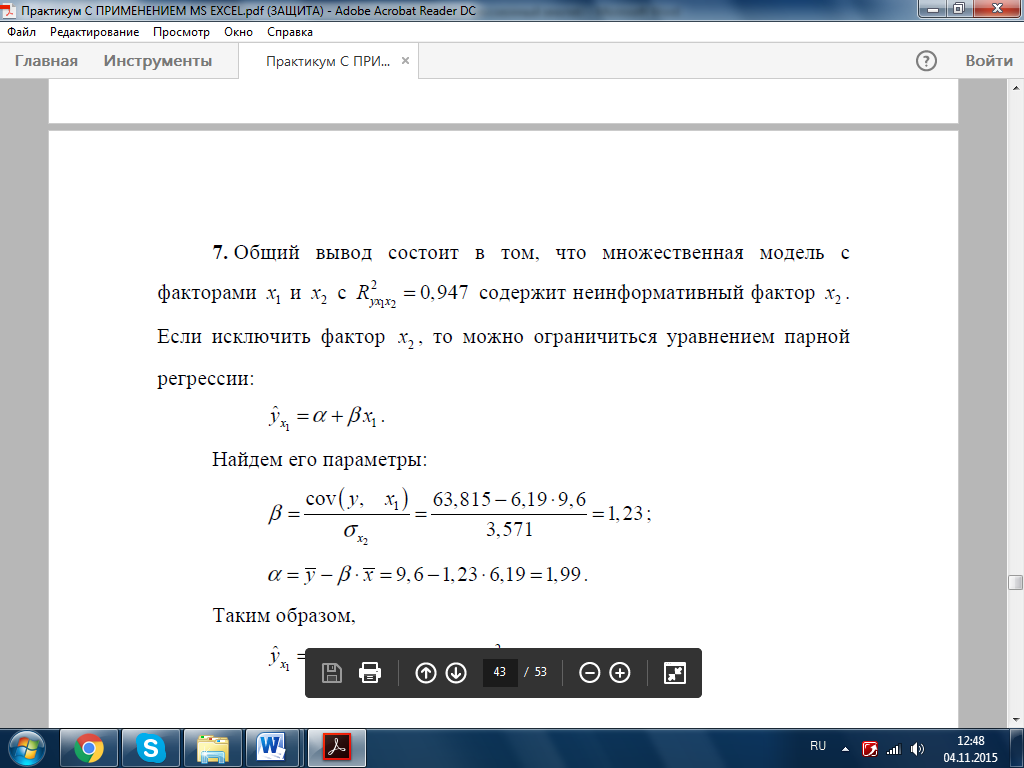
Найдем его параметры:ч

Таким образом, получаем уравнение парной регрессии вида:

8. Найдем матрицу парных коэффициентов корреляции с помощью инструмента анализа данных Корреляция MS Excel.


Рис. 3.1. Анализ данных с помощью функции Корреляция
9. C помощью инструмента анализа данных Регрессия получаем следующие результаты, представленные на рис. 3.2, 3.3:

Рис. 3.2.Множественный регрессивный анализ с помощью функции Регрессия
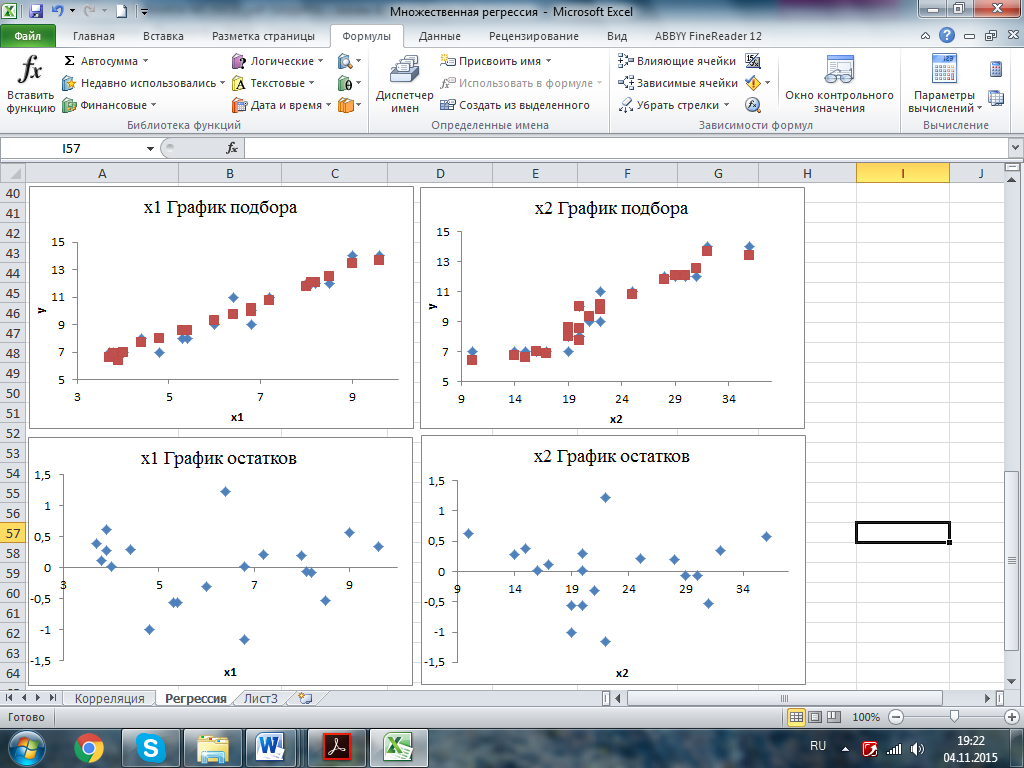
Рис. 3.3. Графики подбора регрессии и остатки по факторам
Уравнение регрессии:

Множественный коэффициент корреляции:
Коэффициент детерминации:
Скорректированный (нормированный) коэффициент детерминации:

Фактическое значение F-критерия Фишера:
Фактические значения t-критерия Стьюдента:
Доверительные интервалы для параметров регрессии:
Значения частного F -критерия Фишера можно найти как квадрат соответствующего значения t-критерия Стьюдента:
Оставшиеся характеристики можно найти, используя известные формулы и полученные здесь результаты.
|
из
5.00
|
Обсуждение в статье: Типовая задача построения множественной регрессии и анализа ее качества |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы