 |
Главная |


Монитор (синхронизация)
|
из
5.00
|
Подразделы
- Алгоритм parallel_for
- Алгоритм parallel_for_each
- Алгоритм parallel_invoke
- Алгоритмы parallel_transform и parallel_reduce
- Алгоритм parallel_transform
- Алгоритм parallel_reduce
- Пример. Параллельное выполнение сопоставления и уменьшения
- Секционирование работы
- Параллельная сортировка
- Выбор алгоритма сортировки
· Пример
· В следующем примере показана основная структура алгоритма parallel_for.Этот пример параллельно выводит на консоль все значения в диапазоне [1, 5].
· C++
· // parallel-for-structure.cpp
· // compile with: /EHsc
· #include <ppl.h>
· #include <array>
· #include <sstream>
· #include <iostream>
·
· using namespace concurrency;
· using namespace std;
·
· int wmain()
· {
· // Print each value from 1 to 5 in parallel.
· parallel_for(1, 6, [](int value) {
· wstringstream ss;
· ss << value << L' ';
· wcout << ss.str();
· });
· }
· В данном примере получается следующий результат.
· 1 2 4 3 5
·
Билет 15
1.Синхронизация процессов — приведение двух или нескольких процессов к такому их протеканию, когда определённые стадии разных процессов совершаются в определённом порядке, либо одновременно.
Синхронизация необходима в любых случаях, когда параллельно протекающим процессам необходимо взаимодействовать. Для её организации используются средства межпроцессного взаимодействия. Среди наиболее часто используемых средств — сигналы и сообщения, семафоры и мьютексы, каналы (англ. pipe), совместно используемая память.
Синхронизация данных — ликвидация различий между двумя копиями данных. Предполагается, что ранее эти копии были одинаковы, а затем одна из них, либо обе были независимо изменены.
Способ синхронизации данных зависит от делаемых дополнительных предположений. Главной проблемой тут является то, что независимо сделанные изменения могут быть несовместимы друг с другом (так называемый «конфликт правок»), и даже теоретически не существует общего способа разрешения подобных ситуаций.
Тем не менее, есть ряд частных способов, применимых в тех или иных случаях:
- Наиболее простой способ: предполагают, что изменения вносились лишь в одну из копий — «рабочую» — и другая копия просто перезаписывается её содержимым. Этот способ реализуют большинство приложений синхронизации; в силу необратимости делаемых изменений пользователю даётся выбор, какую копию считать «главной».
- Если данные представляют собой набор независимых записей (то есть любое сочетание записей является корректным — это, напр., телефонная книга), то можно просто объединить множества записей. Это ликвидирует риск потери информации, но чтобы удалить запись из набора, этот способ приходится сочетать с первым.
- Если наборы синхронизируются неоднократно, можно автоматически вводить в них дополнительную служебную информацию: дата и время последнего изменения записи, пометки об удалённых записях (стираются после следующей синхронизации или через достаточно большое время) и пр. . Этот подход используется, например, в Outlook.
- Обрабатывать конфликты правок: автоматически (если возможно), иначе — вручную. Этот, наиболее общий способ применяется только если указанные выше упрощённые недопустимы — например, в системах контроля версий. Так, CVS при обнаружении двух независимых изменений объявляет о «конфликте» и либо (в простых случаях) разрешает его автоматически, либо предоставляет пользователю разрешить его вручную. В этих случаях конфликтов стараются просто избегать — например, распределением областей компетенции.
Одним из механизмов синхронизации данных является репликация, которая в частности находит применение для синхронизации содержимого баз данных.
2.Зако́н Амдала — иллюстрирует ограничение роста производительности вычислительной системы с увеличением количества вычислителей. Джин Амдал сформулировал закон в 1967 году, обнаружив простое по существу, но непреодолимое по содержанию ограничение на рост производительности при распараллеливании вычислений: «В случае, когда задача разделяется на несколько частей, суммарное время её выполнения на параллельной системе не может быть меньше времени выполнения самого длинного фрагмента».[1] Согласно этому закону, ускорение выполнения программы за счёт распараллеливания её инструкций на множестве вычислителей ограничено временем, необходимым для выполнения её последовательных инструкций.
Закон Густафсона (иногда Густавсона) — Барсиса — оценка максимально достижимого ускорения выполнения параллельной программы, в зависимости от количества одновременно выполняемых потоков вычислений («процессоров») и доли последовательных расчётов. Аналог закона Амдала.
Закон Густафсона — Барсиса выражается формулой: 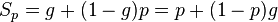 , где
, где
g — доля последовательных расчётов в программе,
p — количество процессоров.
Данную оценку ускорения называют ускорением масштабирования (англ. scaled speedup), так как данная характеристика показывает, насколько эффективно могут быть организованы параллельные вычисления при увеличении сложности решаемых задач.
Билет 5
Монитор (синхронизация)
в языках программирования, высокоуровневый механизм взаимодействия и синхронизации процессов, обеспечивающий доступ к неразделяемым ресурсам. Подход к синхронизации двух или более компьютерных задач, использующих общий ресурс, обычно аппаратуру или набор переменных.
При многозадачности, основанной на мониторах, компилятор или интерпретатор прозрачно для программиста вставляет код блокировки-разблокировки в соответствующим образом оформленные процедуры, избавляя программиста от явного обращения к примитивам синхронизации.
Изобретён Пером Бринчем Хансеном, впервые воплощён в языке Concurrent Pascal и использован для структурирования межпроцессного взаимодействия в операционной системе Solo.
2. Библиотека параллельных шаблонов (PPL) предоставляет алгоритмы, обеспечивающие параллельную работу с коллекциями данных.Эти алгоритмы похожи на алгоритмы из стандартной библиотеки шаблонов (STL).
Параллельные алгоритмы строятся на основе существующих функциональных возможностей среды выполнения с параллелизмом.Например, алгоритм concurrency::parallel_for использует объект concurrency::structured_task_group, чтобы выполнять итерации параллельного цикла.Алгоритм parallel_for оптимальным образом разделяет работу на секции в соответствии с определенным доступным количеством вычислительных ресурсов.
Подразделы
- Алгоритм parallel_for
- Алгоритм parallel_for_each
- Алгоритм parallel_invoke
- Алгоритмы parallel_transform и parallel_reduce
- Алгоритм parallel_transform
- Алгоритм parallel_reduce
- Пример. Параллельное выполнение сопоставления и уменьшения
- Секционирование работы
- Параллельная сортировка
- Выбор алгоритма сортировки
· Пример
· В следующем примере показана основная структура алгоритма parallel_for.Этот пример параллельно выводит на консоль все значения в диапазоне [1, 5].
· C++
· // parallel-for-structure.cpp
· // compile with: /EHsc
· #include <ppl.h>
· #include <array>
· #include <sstream>
· #include <iostream>
·
· using namespace concurrency;
· using namespace std;
·
· int wmain()
· {
· // Print each value from 1 to 5 in parallel.
· parallel_for(1, 6, [](int value) {
· wstringstream ss;
· ss << value << L' ';
· wcout << ss.str();
· });
· }
· В данном примере получается следующий результат.
· 1 2 4 3 5
Билет 6
1. Разработка алгоритмов (а в особенности методов параллельных вычислений) для решения сложных научно-технических задач часто представляет собой значительную проблему. Здесь же мы будем полагать, что вычислительная схема решения нашей задачи умножения матрицы на вектор уже известна. Действия для определения эффективных способов организации параллельных вычислений могут состоять в следующем: • Выполнить анализ имеющейся вычислительной схемы и осуществить ее разделение (декомпозицию) на части (подзадачи), которые могут быть реализованы в значительной степени независимо друг от друга; • Выделить для сформированного набора подзадач информационные взаимодействия, которые должны осуществляться в ходе решения исходной поставленной задачи; • Определить необходимую (или доступную) для решения задачи вычислительную систему и выполнить распределение имеющегося набора подзадач между процессорами системы. Такие этапы разработки параллельных алгоритмов впервые были предложены Фостером (I. Foster). При самом общем рассмотрении понятно, что объем вычислений для каждого используемого процессора должен быть примерно одинаков - это позволит обеспечить равномерную вычислительную загрузку (балансировку) процессоров. Кроме того, также понятно, что распределение подзадач между процессорами должно быть выполнено таким образом, чтобы наличие информационных связей (коммуникационных взаимодействий) между подзадачами было минимальным.
2. Быстрая сортировка использует стратегию «разделяй и властвуй». Шаги алгоритма таковы:
- Выбираем в массиве некоторый элемент, который будем называть опорным элементом. Для корректности алгоритма значение этого элемента должно быть между максимальным и минимальным значениями в массиве (включительно). С точки зрения повышения эффективности алгоритма выгоднее всего выбирать медиану; но без дополнительных сведений о сортируемых данных её обычно невозможно получить. Известные стратегии: выбирать постоянно один и тот же элемент, например, средний или последний по положению; выбирать элемент со случайно выбранным индексом. Часто хороший результат даёт выбор в качестве опорного элемента среднего арифметического между минимальным и максимальным элементами массива, особенно для целых чисел (в этом случае опорный элемент не обязан быть элементом сортируемого массива).
- Операция разделения массива: реорганизуем массив таким образом, чтобы все элементы со значением меньшим или равным опорному элементу, оказались слева от него, а все элементы, превышающие по значению опорный — справа от него. Обычный алгоритм операции:
- Два индекса — l и r, приравниваются к минимальному и максимальному индексу разделяемого массива, соответственно.
- Вычисляется значение опорного элемента m по одной из стратегий.
- Индекс l последовательно увеличивается до тех пор, пока l-й элемент не окажется больше или равен опорному.
- Индекс r последовательно уменьшается до тех пор, пока r-й элемент не окажется меньше или равен опорному.
- Если r = l — найдена середина массива — операция разделения закончена, оба индекса указывают на опорный элемент.
- Если l < r — найденную пару элементов нужно обменять местами и продолжить операцию разделения с тех значений l и r, которые были достигнуты. Следует учесть, что если какая-либо граница (l или r) дошла до опорного элемента, то при обмене значение m изменяется на r-й или l-й элемент соответственно, изменяется именно индекс опорного элемента и алгоритм продолжает свое выполнение.
- Рекурсивно упорядочиваем подмассивы, лежащие слева и справа от опорного элемента.
- Базой рекурсии являются наборы: пустой или состоящий из одного элемента, которые возвращаются в исходном виде. Все такие отрезки уже упорядочены в процессе разделения.
Поскольку в каждой итерации (на каждом следующем уровне рекурсии) длина обрабатываемого отрезка массива уменьшается, по меньшей мере, на единицу, терминальная ветвь рекурсии будет достигнута обязательно, и обработка гарантированно завершится.
Билет 8
1.
2.Обработка изображений — любая форма обработки информации, для которой входные данные представлены изображением, например, фотографиями или видеокадрами. Обработка изображений может осуществляться как для получения изображения на выходе (например, подготовка к полиграфическому тиражированию, к телетрансляции и т. д.), так и для получения другой информации (например, распознание текста, подсчёт числа и типа клеток в поле микроскопа и т. д.). Кроме статичных двухмерных изображений, обрабатывать требуется также изображения, изменяющиеся со временем, например, видео.
Билет 9
1. В основе алгоритмов обработки изображений положены в основном интегральные преобразования: cвертка, преобразование Фурье и др. Также используются статистические методы.
Методы обработки изображений классифицируют обычно по количеству пикселов участвующих в одном шаге преобразования:
- поточечные методы в процессе выполнения преобразуют значение в точке
 в значение
в значение  независимо от соседних точек;
независимо от соседних точек; - локальные (окрестностные) методы для вычисления значение используют значения соседних точек в окрестности ;
- глобальные методы определяют значение на основе всех значений исходного изображения
 .
.
|
из
5.00
|
Обсуждение в статье: Монитор (синхронизация) |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы