|
Главная |


ПРИМЕРЫ НЕПРЕРЫВНЫХ РАСПРЕДЕЛЕНИЙ
|
из
5.00
|
1. Равномерное распределение. Плотность Равномерного или Прямоугольного распределения:
 ,
,
Т. е. вероятности  всех возможных значений
всех возможных значений  случайной величины
случайной величины  одинаковы и равны
одинаковы и равны  .
.
Математическое ожидание случайной величины с Равномерным распределением равно
 ,
,
Дисперсия  .
.
Функция распределения имеет вид 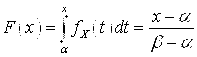 ,
,  (рис. 3.5).
(рис. 3.5).

Рис. 3.5. Графики плотности и функции равномерного распределения
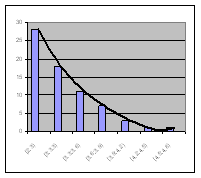
2. Показательное (экспоненциальное) распределение -Закон, функция плотности распределения которого имеет вид:  , где параметр распределения
, где параметр распределения  есть действительное число (постоянный параметр) (рис. 3.6).
есть действительное число (постоянный параметр) (рис. 3.6).
Функция распределения показательного закона имеет вид:

Математическое ожидание и дисперсия случайной величины, распределенной по показательному закону, равны соответственно  ,
,  .
.

Рис. 3.6. Графики плотности и функции показательного распределения
3. Нормальное распределение.Нормальный закон распределения вероятностей занимает особое место среди других законов распределения. В теории вероятности доказывается, что плотность вероятности суммы независимых или Слабо зависимых, равномерно малых (т. е. играющих примерно одинаковую роль) слагаемых при неограниченном увеличении их числа как угодно близко приближается к нормальному закону распределению независимо от того, какие законы распределения имеют эти слагаемые (центральная предельная теорема А. М. Ляпунова).
Плотность вероятности нормально распределенной случайной величины  имеет вид:
имеет вид:  , где
, где  и
и 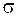 – вещественные параметры распределения, имеющие конечные значения, при этом часто используют обозначение
– вещественные параметры распределения, имеющие конечные значения, при этом часто используют обозначение  .
.
Функция распределения записывается в виде
 ,
,
Здесь  – табулированный интеграл вероятности (значения интеграла можно найти во всех учебниках и задачниках по теории вероятностей). Функция и плотность нормального распределения изображены на рис. 3.7.
– табулированный интеграл вероятности (значения интеграла можно найти во всех учебниках и задачниках по теории вероятностей). Функция и плотность нормального распределения изображены на рис. 3.7.


Рис. 3.7. Графики плотности и функции нормального распределения
Математическое ожидание нормально распределенной случайной величины равно  , дисперсия
, дисперсия 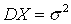 . Таким образом, параметры и имеют смысл математического ожидания и среднеквадратического значения (отклонения) случайной величины.
. Таким образом, параметры и имеют смысл математического ожидания и среднеквадратического значения (отклонения) случайной величины.
Распределение, описываемое функцией 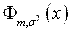 , называется Нормальным или Распределением Гаусса.
, называется Нормальным или Распределением Гаусса.
На рис.3.8 изображены кривые нормального распределения случайных погрешностей для различных значений среднеквадратического отклонения  .
.

Рис. 3.8. Кривые нормального распределения, .
Из рис. 3.8 видно, что по мере увеличения среднеквадратического отклонения распределение все более и более расплывается, вероятность появления больших значений погрешностей возрастает, а вероятность меньших погрешностей сокращается, т. е. увеличивается рассеивание результатов наблюдений.
Широкое распространение нормального распределения погрешностей в практике измерений объясняется Центральной предельной теоремой теории вероятностей, являющейся одной из самых замечательных математических теорем, в разработке которой принимали участие многие крупнейшие математики – Муавр, Лаплас, Гаусс, Чебышев и Ляпунов.
Центральная предельная теорема утверждает, что распределение случайных погрешностей будет близко в нормальному всякий раз, когда результаты наблюдения формируются под влиянием большого числа независимо действующих факторов, каждый из которых оказывает лишь незначительное действие по сравнению с суммарным действием всех остальных.
Свойства нормального распределения.
А. Если случайная величина 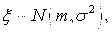
 .
.
В. Если случайная величина то

В частности,  .
.
Таким образом, вычисление любых вероятностей для нормально распределённой случайной величины сводится к вычислению функции распределения  . Она обладает следующими свойствами:
. Она обладает следующими свойствами: 
С. Если  , то для любого
, то для любого 

D.Правило трех сигм. Если то

Большого смысла в запоминании числа 0.0027 нет, но полезно помнить, что почти вся масса нормального распределения сосредоточена в границах от 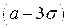 до
до  .
.
Пример 3.7. Дана случайная величина  . Найти
. Найти  .
.
Решение. По формуле свойства В при 
 получаем
получаем  По таблице для функции Лапласа находим
По таблице для функции Лапласа находим  .
.
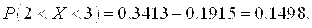
Пример 3.8.Случайная величина X – отклонение размера изделия от нормы – нормально распределенная, причём М (Х)= 0. Найти s (Х), если известно, что Р(– 3 < X < 3) = 0.7.
Решение. Р(– 3 < X < 3) = Р( | X | < 3) = 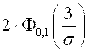 = 0.7. Отсюда следует, что
= 0.7. Отсюда следует, что  , и, используя табличные данные (приложение 1), получаем 3/s =1.4, или s = 3/1.4 » 2.14.
, и, используя табличные данные (приложение 1), получаем 3/s =1.4, или s = 3/1.4 » 2.14.
 (простая выборка, не сгруппированные данные)
При этом значение
(простая выборка, не сгруппированные данные)
При этом значение  получено при первом наблюдении случайной величины Х,
получено при первом наблюдении случайной величины Х,  – при втором наблюдении той же случайной величины и т. д.
Выборку преобразуют в Вариационный ряд, располагая результаты наблюдений в порядке возрастания:
– при втором наблюдении той же случайной величины и т. д.
Выборку преобразуют в Вариационный ряд, располагая результаты наблюдений в порядке возрастания:  Каждый член
Каждый член  Вариационного ряда называется Вариантой.
Пример 4.1.
1. Измерена масса тела 10-ти детей 6-ти лет. Полученные данные образуют простой статистический ряд: 24 22 23 28 24 23 25 27 25 25.
2. Из 10000 выпущенных на конвейере электрических лампочек отобрано 300 штук для проверки качества всей партии. Здесь
Вариационного ряда называется Вариантой.
Пример 4.1.
1. Измерена масса тела 10-ти детей 6-ти лет. Полученные данные образуют простой статистический ряд: 24 22 23 28 24 23 25 27 25 25.
2. Из 10000 выпущенных на конвейере электрических лампочек отобрано 300 штук для проверки качества всей партии. Здесь  а
а  Отдельные значения статистического ряда называются Вариантами. Если варианта ХI появилась M раз, то число M называют Частотой, а ее отношение к объему выборки M/N – Относительной частотой.
Последовательность вариант, записанная в возрастающем (убывающем) порядке, называется Ранжированным рядом.
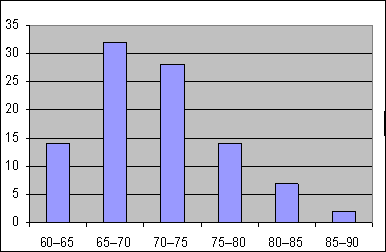
Пример 4.2. Для ранжированного ряда: 23 23 24 24 25 25 25 27 28 в нижеприведенной таблице в первой строке записаны все значения величины (варианты), во второй – соответствующие им частоты (безынтервальный вариационный ряд), в третьей – накопленные частоты, в четвертой – относительные частоты (табл.4.1).
Таблица 4.1. Значения вариант и их частот
Отдельные значения статистического ряда называются Вариантами. Если варианта ХI появилась M раз, то число M называют Частотой, а ее отношение к объему выборки M/N – Относительной частотой.
Последовательность вариант, записанная в возрастающем (убывающем) порядке, называется Ранжированным рядом.
Пример 4.2. Для ранжированного ряда: 23 23 24 24 25 25 25 27 28 в нижеприведенной таблице в первой строке записаны все значения величины (варианты), во второй – соответствующие им частоты (безынтервальный вариационный ряд), в третьей – накопленные частоты, в четвертой – относительные частоты (табл.4.1).
Таблица 4.1. Значения вариант и их частот

 (M — количество различных вариант). Сумма относительных частот равна единице.
(M — количество различных вариант). Сумма относительных частот равна единице.

 (4.1)
(4.1) по выборке
по выборке 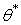 .
Определение 4.1. Оценка
.
Определение 4.1. Оценка  .
Данное свойство характеризует отсутствие Систематической ошибки, т. е. при многократном использовании вместо параметра
.
Данное свойство характеризует отсутствие Систематической ошибки, т. е. при многократном использовании вместо параметра 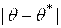 равно нулю.
Так, выборочное среднее арифметическое
равно нулю.
Так, выборочное среднее арифметическое  является Несмещенной оценкой математического ожидания, а выборочная дисперсия
является Несмещенной оценкой математического ожидания, а выборочная дисперсия  – Смещенная оценка генеральной дисперсии D. Несмещенной оценкой генеральной дисперсии является оценка («исправленная дисперсия»)
– Смещенная оценка генеральной дисперсии D. Несмещенной оценкой генеральной дисперсии является оценка («исправленная дисперсия»)  Определение 4.2. Оценка
Определение 4.2. Оценка  называется Состоятельной, если она сходится по вероятности к оцениваемому параметру
называется Состоятельной, если она сходится по вероятности к оцениваемому параметру 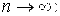
 Данное свойство характеризует улучшение оценки с увеличением объема выборки.
Сходимость по вероятности означает, что при большом объеме выборки вероятность больших отклонений оценки от истинного значения мала.
Определение 4.3.. Несмещенная оценка является Эффективной, если она имеет наименьшую среди всех несмещенных оценок дисперсию.
Пример 4.4.:
1. Вычислить среднее значение массы тела детей 6 лет.
Данное свойство характеризует улучшение оценки с увеличением объема выборки.
Сходимость по вероятности означает, что при большом объеме выборки вероятность больших отклонений оценки от истинного значения мала.
Определение 4.3.. Несмещенная оценка является Эффективной, если она имеет наименьшую среди всех несмещенных оценок дисперсию.
Пример 4.4.:
1. Вычислить среднее значение массы тела детей 6 лет.
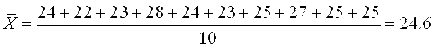 2. Если выборочное среднее вычисляется по вариационному ряду, то находят сумму произведений вариант на соответствующие частоты, и делят на количество элементов в выборке:
2. Если выборочное среднее вычисляется по вариационному ряду, то находят сумму произведений вариант на соответствующие частоты, и делят на количество элементов в выборке:  .
.
 3. В том случае, когда статистические данные представлены в виде интервального вариационного ряда, при вычислении выборочного среднего значениями вариант считают середины интервалов. Так, для вычисления среднего значения массы тела женщин 30 лет из примера 4.3. используют формулу:
3. В том случае, когда статистические данные представлены в виде интервального вариационного ряда, при вычислении выборочного среднего значениями вариант считают середины интервалов. Так, для вычисления среднего значения массы тела женщин 30 лет из примера 4.3. используют формулу:
 .
Другими характеристиками являются МодаИ Медиана.
В теории вероятностей МодойМо дискретной случайной величины называется ее значение, которое имеет максимальную вероятность. Модой непрерывной случайной величины называется такое ее значение, при котором достигается максимум плотности распределения
.
Другими характеристиками являются МодаИ Медиана.
В теории вероятностей МодойМо дискретной случайной величины называется ее значение, которое имеет максимальную вероятность. Модой непрерывной случайной величины называется такое ее значение, при котором достигается максимум плотности распределения  Закон распределения называется унимодальным, если мода единственна. В математической статистике мода Мо определяется по выборке, как Варианта с наибольшей частотой.
Медианой называется варианта, расположенная в центре Ранжированного ряда. Если ряд состоит из четного числа вариант, то медианой считают среднее арифметическое двух вариант, расположенных в центре ранжированного ряда.
Пример 4.5. Найти моду и медиану выборочной совокупности по массе тела детей 6 лет.
Ответ: Мо = 24; Ме = 24.
Основные числовые характеристики выборочной совокупности:
1) Размах вариационного ряда R=Xmax – Xmin. Этот показатель является наиболее простой характеристикой рассеяния и показывает диапазон варьирования величины. Этой характеристикой пользуются при работе с малыми выборками;
2) Выборочное среднее находится как взвешенное среднее арифметическое
Закон распределения называется унимодальным, если мода единственна. В математической статистике мода Мо определяется по выборке, как Варианта с наибольшей частотой.
Медианой называется варианта, расположенная в центре Ранжированного ряда. Если ряд состоит из четного числа вариант, то медианой считают среднее арифметическое двух вариант, расположенных в центре ранжированного ряда.
Пример 4.5. Найти моду и медиану выборочной совокупности по массе тела детей 6 лет.
Ответ: Мо = 24; Ме = 24.
Основные числовые характеристики выборочной совокупности:
1) Размах вариационного ряда R=Xmax – Xmin. Этот показатель является наиболее простой характеристикой рассеяния и показывает диапазон варьирования величины. Этой характеристикой пользуются при работе с малыми выборками;
2) Выборочное среднее находится как взвешенное среднее арифметическое  , которое характеризует среднее значение признака X в пределах рассматриваемой выборки;
3) Выборочная дисперсия Определяется по формуле:
, которое характеризует среднее значение признака X в пределах рассматриваемой выборки;
3) Выборочная дисперсия Определяется по формуле: 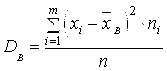 , которая является мерой рассеяния возможных значений показателя X вокруг своего среднего значения, и ее размерность совпадает с квадратом размерности варианты;
4) Выборочное среднее квадратическое отклонение
, которая является мерой рассеяния возможных значений показателя X вокруг своего среднего значения, и ее размерность совпадает с квадратом размерности варианты;
4) Выборочное среднее квадратическое отклонение  описывает абсолютный разброс значений показателя X. Его размерность совпадает с размерностью варианты;
5) «Исправленная» Дисперсия (вычисляют при малых N, n<30)
описывает абсолютный разброс значений показателя X. Его размерность совпадает с размерностью варианты;
5) «Исправленная» Дисперсия (вычисляют при малых N, n<30)  и «Исправленное» стандартное отклонение
и «Исправленное» стандартное отклонение  ;
6) Коэффициент вариации
;
6) Коэффициент вариации  характеризует относительную изменчивость показателя X, то есть относительный разброс вокруг его среднего значения
характеризует относительную изменчивость показателя X, то есть относительный разброс вокруг его среднего значения  . Коэффициент вариации является безразмерной величиной, поэтому он пригоден для сравнения рассеяния вариационных рядов, варианты которых имеют различную размерность.
Пример 4.6.: Измерена длина (Х) и масса тела (Y) девочек 10-ти лет. Получены следующие показатели: Х=130 см, SХ = 5 см, Y = 32 кг, SY = 4 кг. Какая величина имеет большую вариативность?
Так как длина и масса тела измеряются в разных единицах, то вариативность нельзя сравнить при помощи СКО. Необходимо вычислить относительный показатель вариации.
. Коэффициент вариации является безразмерной величиной, поэтому он пригоден для сравнения рассеяния вариационных рядов, варианты которых имеют различную размерность.
Пример 4.6.: Измерена длина (Х) и масса тела (Y) девочек 10-ти лет. Получены следующие показатели: Х=130 см, SХ = 5 см, Y = 32 кг, SY = 4 кг. Какая величина имеет большую вариативность?
Так как длина и масса тела измеряются в разных единицах, то вариативность нельзя сравнить при помощи СКО. Необходимо вычислить относительный показатель вариации.
 Таким образом, масса тела имеет большую вариативность, чем длина тела.
Таким образом, масса тела имеет большую вариативность, чем длина тела.
 .
Нам уже известно, что
.
Нам уже известно, что  . Можно показать [1-5], что
. Можно показать [1-5], что  (сумма
(сумма  нормально распределенных случайных величин
нормально распределенных случайных величин  сама является нормальной).
Зададим доверительную вероятность ¡ и найдем доверительный интервал (
сама является нормальной).
Зададим доверительную вероятность ¡ и найдем доверительный интервал (  . (4.1)
Таким образом, для отыскания величины Доверительной границы случайного отклонения результатов наблюдений по Доверительной вероятности ¡ имеем уравнение:
. (4.1)
Таким образом, для отыскания величины Доверительной границы случайного отклонения результатов наблюдений по Доверительной вероятности ¡ имеем уравнение:
 , где
, где 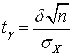 ,
Где значение
,
Где значение  находим по таблице Лапласа (приложение 1),
находим по таблице Лапласа (приложение 1),  .
Пример 4.7. По результатам наблюдений была найдена оценка неизвестного математического ожидания M случайной величины
.
Пример 4.7. По результатам наблюдений была найдена оценка неизвестного математического ожидания M случайной величины  =4. Требуется оценить доверительный интервал для оценки математического ожидания по 36-ти наблюдениям с заданной надежностью ¡=0.99.
Решение. Из (4.1) следует, что
=4. Требуется оценить доверительный интервал для оценки математического ожидания по 36-ти наблюдениям с заданной надежностью ¡=0.99.
Решение. Из (4.1) следует, что  . Отсюда получаем, что
. Отсюда получаем, что  . Так как
. Так как  , то с вероятностью 0.99 доверительный интервал для оценки математического ожидания:
, то с вероятностью 0.99 доверительный интервал для оценки математического ожидания:  .
Со случаем, когда распределение результатов наблюдений нормально, но их дисперсия неизвестна, можно ознакомится в [3, 4, 6].
.
Со случаем, когда распределение результатов наблюдений нормально, но их дисперсия неизвестна, можно ознакомится в [3, 4, 6].
 ) и альтернативную (конкурирующую, противопоставленную основной,
) и альтернативную (конкурирующую, противопоставленную основной,  ). Например, если нулевая гипотеза
). Например, если нулевая гипотеза  Проверка статистических гипотез осуществляется с Помощью статистического критерия K — правила (функции от результатов наблюдений), определяющего меру расхождения результатов наблюдений с нулевой гипотезой. Вероятность
Проверка статистических гипотез осуществляется с Помощью статистического критерия K — правила (функции от результатов наблюдений), определяющего меру расхождения результатов наблюдений с нулевой гипотезой. Вероятность  называют Мощностью критерия.
Замечание. Ошибка первого рода состоит в том, что будет отвергнута правильная гипотеза. Ошибка второго рода состоит в том, что будет принята неправильная гипотеза.
Например, основная гипотеза состоит в том, что предприятие получает прибыль. Если это правильная гипотеза, то ошибка первого рода состоит в том, что данная гипотеза отвергается. Если принимается решение о том, что прибыль предприятие не получает, то это ошибка второго рода.
Иногда ошибку первого рода называют «альфа-риск» (a-риск) а ошибку второго рода «бета-риск» (b-риск).
Из двух критериев, характеризующихся одной и той же вероятностью
называют Мощностью критерия.
Замечание. Ошибка первого рода состоит в том, что будет отвергнута правильная гипотеза. Ошибка второго рода состоит в том, что будет принята неправильная гипотеза.
Например, основная гипотеза состоит в том, что предприятие получает прибыль. Если это правильная гипотеза, то ошибка первого рода состоит в том, что данная гипотеза отвергается. Если принимается решение о том, что прибыль предприятие не получает, то это ошибка второго рода.
Иногда ошибку первого рода называют «альфа-риск» (a-риск) а ошибку второго рода «бета-риск» (b-риск).
Из двух критериев, характеризующихся одной и той же вероятностью 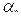 выбирают тот, которому соответствует меньшая ошибка 2-го рода, т. е. большая мощность. Уменьшить вероятности обеих ошибок
выбирают тот, которому соответствует меньшая ошибка 2-го рода, т. е. большая мощность. Уменьшить вероятности обеих ошибок  и
и  критерия K, рассчитанное по выборочным данным, попадает в критическую область, то гипотеза
критерия K, рассчитанное по выборочным данным, попадает в критическую область, то гипотеза  — область принятия этой гипотезы. Критической областью является множество
— область принятия этой гипотезы. Критической областью является множество  — правильных ответов меньше трех, в этом случае основная гипотеза отвергается в пользу альтернативной
— правильных ответов меньше трех, в этом случае основная гипотеза отвергается в пользу альтернативной 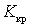 (вид критической области определить по виду альтернативной гипотезы
(вид критической области определить по виду альтернативной гипотезы  6) принять статистическое решение: если
6) принять статистическое решение: если