 |
Главная |


Руководство программиста
|
из
5.00
|
Назначение и условия применения программы.
Характеристики программы.
Обращение к программе.
Входные и выходные данные.
Сообщения.
Руководство оператора
Назначение программы.
Условия выполнения программы.
Выполнения программы.
Сообщения оператору.
Руководство по техническому обслуживанию
Введение
Общие указания
Требования к техническим средствам
Описание функций
Программа и методика испытаний
Объект испытаний.
Цель испытаний.
Требования к программе.
Требования к программной документации.
Средства и порядок испытаний.
Методы испытаний.
Текст программы
Описание программы
Общие сведения
Функциональное назначение
Описание логической структуры
Используемые технические средства
Вызов и загрузка
Исходные данные
Выходные данные
Содержание работ на стадии опытной (опытно-промышленной) эксплуатации
План мероприятий по подготовке объекта к вводу системы в эксплуатацию
Обучение персонала работе в условиях функционирования вводимой системы
Установка и тестирование технических средств
Проведение опытной эксплуатации
Ввод изменений в организационную структуру
Проверка эффективности реализованных решений и разработка мероприятий по их развитию
Подготовка и проведение приемочных испытаний
Содержание работ на стадии ввода в действие. Авторский надзор
Устранение замечаний по результатам проведения приемочных испытаний.
Гарантийное обслуживание
Модернизация системы по замечаниям заказчика
Лекция 2
Тема: Построение программных систем. Межпроцессное взаимодействие. Программные модули. Фильтры. Пакетная обработка, организация взаимодействия. Графические оболочки. Взаимодействие процессов, передача данных. Каналы, программная организация передачи данных.
Взаимодействие консольных программ.
Чтение и запись данных через перенаправление стандартных потоков ввода-вывода
Программа asdf1 – ввод из потока stdin:
enum { BUF_SIZE = 256 };
int main(int argc, char *argv[])
{
char name[BUF_SIZE];
puts("Input name:");
fgets(name, sizeof(name) / sizeof(name[0]), stdin);
printf("Hello, %s", name);
return 0;
}
Программа asdf2:
int main(int argc, char *argv[])
{
puts("Vasia Pupkin");
return 0;
}
Варианты использования:
asdf1
asdf2 >n.txt
asdf1 <n.txt
asdf2 | asdf1

Вызов внешней программы
#include <stdio.h>
#include <process.h>
int main(int argc, char *argv[])
{
…
int k,l;
// вызов программы AkelPad.exe без параметров (указан полный путь)
// без ожидания ее завершения
char *pt="C:\\TotalCommander\\AkelPad\\AkelPad.exe";
k=spawnl(P_NOWAIT , pt, pt, NULL);
// вызов программы MyProg.exe.exe с параметром "abc.txt"
// c ожиданиtv ее завершения
k=spawnl(P_WAIT, "D:\\ubuild\\Mirea\\MyProg.exe",
"D:\\ubuild\\Mirea\\MyProg.exe",
"abc.txt", NULL);
FILE *infile;
char buff[100];
infile = fopen(argv[2], "rt");
// чтение данных из "abc.txt"
return 0;
}
Прием параметров консольными программами
#include <stdio.h>
#include <process.h>
int main(int argc, char *argv[])
{
…
if (argc > 1)
{
FILE *outfile;
char buff[100];
outfile = fopen(argv[2], "wt");
// вывод данных в указанный файл
}
return 0;
}
Прием параметров программами Windows (c++ Builder)
…
int n;
AnsiString str;
TStringList *st=new TStringList();
if(ParamCount()>1)
{str= ParamStr(1);
st->LoadFromFile(str);
…
}
Взаимодействие процессов через каналы.
//-----------------------------------------------------------
#include <vcl.h>
#include <fcntl.h> // _pipe()
#include <io.h> // write()
#include <process.h> // spawnl() cwait()
#pragma hdrstop
#include "UMain.h"
//-----------------------------------------------------------
#pragma package(smart_init)
#pragma resource "*.dfm"
TForm1 *Form1;
static int handles[2]; // in- and outbound pipe handles
//-----------------------------------------------------------
__fastcall TForm1::TForm1(TComponent* Owner)
: TForm(Owner)
{
}
//-----------------------------------------------------------
void __fastcall TForm1::Button1Click(TObject *Sender)
{
// запрос дескрипторов
int k=_pipe(handles, 32768, O_TEXT);
if(k!=0) {ShowMessage("Кердык!"); return;}
else ShowMessage(AnsiString(handles[0])+"-read "+
AnsiString(handles[1])+"-write");
AnsiString handleStr, wrk;
// запрос номеров дескрипторов в строку
handleStr=AnsiString(handles[0])+" "+AnsiString(handles[1]);
// заполнение выходной «трубы»
wrk="Ехали медведи на велосипеде";
write(handles[1], (void *)(wrk.c_str()), wrk.Length());
wrk="А за ними раки на хромой собаке";
write(handles[1], (void *)(wrk.c_str()), wrk.Length());
}
//-----------------------------------------------------------
void __fastcall TForm1::Button2Click(TObject *Sender)
{
// чтение входной «трубы»
int len, k=lseek(handles[1], 0, SEEK_SET);
char buf[2000];
ShowMessage("Установка "+AnsiString(k)+" байт");
k=lseek(handles[0], 0, SEEK_SET);
len=read(handles[0], (void *) buf, 2000);
ShowMessage("Принято "+AnsiString(len)+" байт");
ShowMessage(AnsiString(buf));
}
//-----------------------------------------------------------
Реализация в среде windows вызова другой программы с передачей данных в обе стороны:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <io.h>
#include <fcntl.h>
#include <process.h>
enum { BUFSIZE = 256 };
int main(int argc, char *argv[])
{
// родительский процесс
// дескрипторы двух каналов
int rd[2], wd[2];
// открытие обоих
if (_pipe(rd, BUFSIZE, _O_TEXT) == 0 &&
_pipe(wd, BUFSIZE, _O_TEXT) == 0)
{
int oldout, oldin, handle;
// сохраняем стандартные дескрипторы
oldout = _dup(1);
oldin = _dup(0);
// перезаписываем их концами каналов
_dup2(wd[0], 0);
_dup2(rd[1], 1);
// закрываем соответствующие концы каналов
_close(wd[0]);
_close(rd[1]);
// запускаем процесс, наследующий дескрипторы
handle = _spawnlp(_P_NOWAIT, "cmd.exe", "cmd.exe", NULL);
// возвращаем на место стандартные дескрипторы
_dup2(oldout, 1);
_dup2(oldin, 0);
// закрываем копии
_close(oldout);
_close(oldin);
// обмен данными с созданным процессом
if (handle != -1)
{
char buf[BUFSIZE];
int sz;
strcpy(buf, "dir\nexit\n");
_write(wd[1], buf, strlen(buf) + 1);
for (;;)
{
sz = _read(rd[0], buf, sizeof(buf) / sizeof(buf[0]) - 1);
if (sz > 0)
{
buf[sz] = '\0';
fputs(buf, stdout);
}
else
break;
};
// после ожидания закрывается хэндл процесса
_cwait(NULL, handle, 0);
};
// закрываем свои концы каналов
_close(wd[1]);
_close(rd[0]);
};
return 0;
}
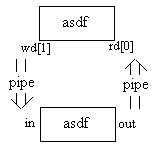
Содержимое таблицы дескрипторов:

Лекция 3
Тема: Кодирование информации при передаче. Машино-независимое представление данных. Сжатие данных без потерь. Построение дерева Хаффмана и кода Хаффмана для заданного текста. Алгоритмы сжатия типа LZW. Сжатие данных с потерями.
Кодирование Хаффмана
Один из первых алгоритмов эффективного кодирования информации был предложен Д. А. Хаффманом в 1952 году. Идея алгоритма состоит в следующем: зная вероятности символов в сообщении, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью ставятся в соответствие более короткие коды. Коды Хаффмана обладают свойством префиксности (т.е. ни одно кодовое слово не является префиксом другого), что позволяет однозначно их декодировать.
Классический алгоритм Хаффмана на входе получает таблицу частот встречаемости символов в сообщении. Далее на основании этой таблицы строится дерево кодирования Хаффмана (Н-дерево).
1. Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в сжимаемое сообщение.
2. Выбираются два свободных узла дерева с наименьшими весами.
3. Создается их родитель с весом, равным их суммарному весу.
4. Родитель добавляется в список свободных узлов, а два его потомка удаляются из этого списка.
5. Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0.
6. Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Допустим, у нас есть следующая таблица частот:
| 15 | 7 | 6 | 6 | 5 |
| А | Б | В | Г | Д |
Этот процесс можно представить как построение дерева, корень которого — символ с суммой вероятностей объединенных символов, получившийся при объединении символов из последнего шага, его n0 потомков — символы из предыдущего шага и т. д.
Чтобы определить код для каждого из символов, входящих в сообщение, мы должны пройти путь от корня до листа дерева, соответствующего текущему символу, накапливая биты при перемещении по ветвям дерева (первая ветвь в пути соответствует младшему биту). Полученная таким образом последовательность битов является кодом данного символа, записанным в обратном порядке.
Для данной таблицы символов коды Хаффмана будут выглядеть следующим образом.
| А | Б | В | Г | Д |
| 0 | 100 | 101 | 110 | 111 |
Поскольку ни один из полученных кодов не является префиксом другого, они могут быть однозначно декодированы при чтении их из потока. Кроме того, наиболее частый символ сообщения А закодирован наименьшим количеством бит, а наиболее редкий символ Д — наибольшим.
При этом общая длина сообщения, состоящего из приведённых в таблице символов, составит 87 бит (в среднем 2,2308 бита на символ). При использовании равномерного кодирования общая длина сообщения составила бы 117 бит (ровно 3 бита на символ). Заметим, что энтропия источника, независимым образом порождающего символы с указанными частотами, составляет ~2,1858 бита на символ, т.е. избыточность построенного для такого источника кода Хаффмана, понимаемая, как отличие среднего числа бит на символ от энтропии, составляет менее 0,05 бит на символ.
Классический алгоритм Хаффмана имеет ряд существенных недостатков. Во-первых, для восстановления содержимого сжатого сообщения декодер должен знать таблицу частот, которой пользовался кодер. Следовательно, длина сжатого сообщения увеличивается на длину таблицы частот, которая должна посылаться впереди данных, что может свести на нет все усилия по сжатию сообщения. Кроме того, необходимость наличия полной частотной статистики перед началом собственно кодирования требует двух проходов по сообщению: одного для построения модели сообщения (таблицы частот и Н-дерева), другого для собственно кодирования. Во-вторых, избыточность кодирования обращается в ноль лишь в тех случаях, когда вероятности кодируемых символов являются обратными степенями числа 2. В-третьих, для источника с энтропией, не превышающей 1 (например, для двоичного источника), непосредственное применение кода Хаффмана бессмысленно.
Сжатие по алгори́тмы Ле́мпеля — Зи́ва — Ве́лча (Lempel-Ziv-Welch, LZW)
Алгори́тм Ле́мпеля — Зи́ва — Ве́лча (Lempel-Ziv-Welch, LZW) — это универсальный алгоритм сжатия данных без потерь, созданный Абрахамом Лемпелем (англ. Abraham Lempel), Якобом Зивом (англ. Jacob Ziv) и Терри Велчем (англ. Terry Welch). Он был опубликован Велчем в 1984 году, в качестве улучшенной реализации алгоритма LZ78, опубликованного Лемпелем и Зивом в 1978 году. Алгоритм разработан так, чтобы его можно было быстро реализовать, но он не обязательно оптимален, поскольку он не проводит никакого анализа входных данных.
Акроним «LZW» указывает на фамилии изобретателей алгоритма: Лемпель, Зив и Велч, но многие утверждают, что, поскольку патент принадлежал Зиву, то метод должен называться алгоритмом Зива — Лемпеля — Велча.
Пример
Данный пример показывает алгоритм LZW в действии, показывая состояние выходных данных и словаря на каждой стадии, как при кодировании, так и при раскодировании сообщения. С тем чтобы сделать изложение проще, мы ограничимся простым алфавитом — только заглавные буквы, без знаков препинания и пробелов. Сообщение, которое нужно сжать, выглядит следующим образом:
TOBEORNOTTOBEORTOBEORNOT#
Маркер # используется для обозначения конца сообщения. Тем самым, в нашем алфавите 27 символов (26 заглавных букв от A до Z и #). Компьютер представляет это в виде групп бит, для представления каждого символа алфавита нам достаточно группы из 5 бит на символ. По мере роста словаря, размер групп должен расти, с тем чтобы учесть новые элементы. 5-битные группы дают 25 = 32 возможных комбинации бит, поэтому, когда в словаре появится 33-е слово, алгоритм должен перейти к 6-битным группам. Заметим, что, поскольку используется группа из всех нолей 00000, то 33-я группа имеет код 32. Начальный словарь будет содержать:
# = 00000
A = 00001
B = 00010
C = 00011
.
.
.
Z = 11010
Кодирование
Без использования алгоритма LZW, при передаче сообщения как оно есть — 25 символов по 5 бит на каждый — оно займёт 125 бит. Сравним это с тем, что получается при использовании LZW:
Символ: Битовый код: Новая запись словаря:
(на выходе)
T 20 = 10100
O 15 = 01111 27: TO
B 2 = 00010 28: OB
E 5 = 00101 29: BE
O 15 = 01111 30: EO
R 18 = 10010 31: OR <--- со следующего символа начинаем использовать 6-битные группы
N 14 = 001110 32: RN
O 15 = 001111 33: NO
T 20 = 010100 34: OT
TO 27 = 011011 35: TT
BE 29 = 011101 36: TOB
OR 31 = 011111 37: BEO
TOB 36 = 100100 38: ORT
EO 30 = 011110 39: TOBE
RN 32 = 100000 40: EOR
OT 34 = 100010 41: RNO
# 0 = 000000 42: OT#
Общая длина = 6*5 + 11*6 = 96 бит.
Таким образом, используя LZW мы сократили сообщение на 29 бит из 125 — это почти 22 %. Если сообщение будет длиннее, то элементы словаря будут представлять всё более и более длинные части текста, благодаря чему повторяющиеся слова будут представлены очень компактно.
Декодирование [
Теперь представим что мы получили закодированное сообщение, приведённое выше, и нам нужно его декодировать. Прежде всего, нам нужно знать начальный словарь, а последующие записи словаря мы можем реконструировать уже на ходу, поскольку они являются просто конкатенацией предыдущих записей.
Данные: На выходе: Новая запись:
Полная: Частичная:
10100 = 20 T 27: T?
01111 = 15 O 27: TO 28: O?
00010 = 2 B 28: OB 29: B?
00101 = 5 E 29: BE 30: E?
01111 = 15 O 30: EO 31: O?
10010 = 18 R 31: OR 32: R? <---- начинаем использовать 6-битные группы
001110 = 14 N 32: RN 33: N?
001111 = 15 O 33: NO 34: O?
010100 = 20 T 34: OT 35: T?
011011 = 27 TO 35: TT 36: TO? <---- для 37, добавляем только первый элемент
011101 = 29 BE 36: TOB 37: BE? следующего слова словаря
011111 = 31 OR 37: BEO 38: OR?
100100 = 36 TOB 38: ORT 39: TOB?
011110 = 30 EO 39: TOBE 40: EO?
100000 = 32 RN 40: EOR 41: RN?
100010 = 34 OT 41: RNO 42: OT?
000000 = 0 #
Единственная небольшая трудность может возникнуть, если новое слово словаря пересылается немедленно. В приведённом выше примере декодирования, когда декодер встречает первый символ, T, он знает, что слово 27 начинается с T, но чем оно заканчивается? Проиллюстрируем проблему следующим примером. Мы декодируем сообщение ABABA:
Данные: На выходе: Новая запись:
Полная: Частичная:
.
.
.
011101 = 29 AB 46: (word) 47: AB?
101111 = 47 AB? <--- что нам с этим делать?
На первый взгляд, для декодера это неразрешимая ситуация. Мы знаем наперёд, что словом 47 должно быть ABA, но как декодер узнает об этом? Заметим, что слово 47 состоит из слова 29 плюс символ идущий следующим. Таким образом, слово 47 заканчивается на «символ идущий следующим». Но, поскольку это слово посылается немедленно, то оно должно начинаться с «символа идущего следующим», и поэтому оно заканчивается тем же символом что и начинается, в данном случае — A. Этот трюк позволяет декодеру определить, что слово 47 это ABA.
В общем случае, такая ситуация появляется, когда кодируется последовательность вида cScSc, где c — это один символ, а S — строка, причём слово cS уже есть в словаре.
Лекция 4
Тема: Автоматное программирование. Синтаксический анализ. Конечный автомат, использование в программировании. Анализ строки. Прямая и обратная польская нотация, стековая и рекурсивная реализация. Синтаксический разбор, построение синтаксического дерева.
|
из
5.00
|
Обсуждение в статье: Руководство программиста |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы