 |
Главная |


Алгоритм работы с польской нотацией
|
из
5.00
|
/* Компиляция:
* gcc -o rpn rpn.c
*
* Использование:
* ./rpn <выражение>
*
* Пример:
* ./rpn 3 5 +
*
* Замечание: знак умножения `*' заменен на `x', т.к. символ `*' используется
* командной оболочкой.
**/
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#define STKDPTH 32 /* Глубина стека */
/* Значения, возвращаемые функцией parse */
#define VAL 0 /* В стек занесено новое значение */
#define ADD 1 /* Сложение */
#define SUB 2 /* Вычитание */
#define MUL 3 /* Умножение */
#define DIV 4 /* Деление */
#define SOF -1 /* Переполнение стека */
#define SUF -2 /* В стеке недостаточно операндов */
#define UNK -3 /* Неопознанное значение */
/* Глобальные переменные */
int scount;
double stack[STKDPTH];
/* Функция распознавания аргументов */
int parse(char *);
/* Точка входа */
int main(int argc, char **argv)
{
/* Организуем цикл для перебора аргументов командной строки */
while (*++argv) {
/* Пытаемся распознать текущий аргумент как число или
* символ арифметической операции */
switch (parse(*argv)) {
case VAL: continue;
/* Вычисляем */
case ADD:
stack[scount - 1] += stack[scount];
break;
case SUB:
stack[scount - 1] -= stack[scount];
break;
case MUL:
stack[scount - 1] *= stack[scount];
break;
case DIV:
if (stack[scount] != 0) {
stack[scount - 1] /= stack[scount];
break;
} else {
fprintf(stderr, "Деление на ноль!\n");
return(1);
}
/* Обработка ошибок */
case SUF:
fprintf(stderr, "Недостаточно операндов!\n");
return(1);
case SOF:
fprintf(stderr, "Переполнение стека!\n");
return(1);
case UNK:
fprintf(stderr, "Неопознанный аргумент!\n");
return(1);
}
}
/* Вывести результат */
auto int i;
for (i = 0; i < scount; i++) printf("%0.3f\n", stack[i]);
return(0);
}
int parse(char *s)
{
double tval = 0;
char * endptr;
/* Распознаем знаки арифметических операций */
switch (*s) {
case '-':
/* Если минус является первым и не последним символом аргумента,
* значит пользователь ввел отрицательное число и опознавать его
* как операцию вычитания не нужно */
if (*(s+1) != '\0') break;
if (scount >= 2) {
scount -= 1;
return(SUB);
}
else return(SUF);
case '+':
if (scount >= 2) {
scount -= 1;
return(ADD);
}
else return(SUF);
case 'x':
if (scount >= 2) {
scount -= 1;
return(MUL);
}
else return(SUF);
case '/':
if (scount >= 2) {
scount -= 1;
return(DIV);
}
else return(SUF);
}
errno = 0;
/* Пытаемся сконвертировать строковый аргумент в число */
tval = strtod(s, &endptr);
/* Вернуть ошибку `неопознанный аргумент' в случае неудачи */
if (errno != 0 || *endptr != '\0') return(UNK);
/* Проверяем, есть ли свободное место в стеке
* и сохраняем в нем операнд, иначе возвращаем ошибку переполнения */
if (scount < STKDPTH) stack[scount++] = tval;
else return(SOF);
return(VAL);
}
Лекция 5
Тема: Многопоточное программирование. Параллельное программирования. Распределения задач по отдельным потокам. Распараллеливание циклов. Использование объектов типа Threads. Синхронизация вычислений, защита данных в разных потоках.
Распараллеливание вычислений.
Большинство операционных систем, даже на однопроцессорных машинах позволяет одновременное выполнение нескольких программ (на однопроцессорных за счет выделения каждой программе кванта времени, если ей нужны ресурсы процессора, с последующим переключением на другую). Учитывая, что программы, ожидающие действий пользователя или периферийных устройств, занимают незначительную часть времени процессора, то такое переключение дает значительный эффект. При наличии нескольких процессоров ускорение может дать еще более значительный эффект.
Для распараллеливания вычислений годятся не всякие алгоритмы. Если следующий шаг алгоритма использует результаты предыдущего, то распараллеливание невозможно. Тем не менее, существует множество алгоритмов, отдельные части которых могут исполняться независимо.
Исполнение такого алгоритма можно представить в виде графа.

Рассмотрим реализацию многопоточного алгоритма с использованием объекта типа TThread.
//--- Главная программа
#include <vcl.h>
#pragma hdrstop
#include "UMain.h"
#include "UTH.h"
//---------------------------------------------------------------------------
#pragma package(smart_init)
#pragma resource "*.dfm"
TFMain *FMain;
TMyThread *ms;
//---------------------------------------------------------------------------
__fastcall TMyThread::TMyThread(bool CreateSuspended)
: TThread(CreateSuspended)
{
}
//---------------------------------------------------------------------------
void __fastcall TMyThread::Execute()
{
//---- Place thread code here ----
double s=0,t;
for(int i=1;i<1000000000;++i)
{t=i;
s=s+1/t;
}
arr[0]=s;
ReturnValue=32;
}
//---------------------------------------------------------------------------
//---------------------------------------------------------------------------
__fastcall TFMain::TFMain(TComponent* Owner)
: TForm(Owner)
{
}
//---------------------------------------------------------------------------
void __fastcall TFMain::Button1Click(TObject *Sender)
{AnsiString s;
ms=new TMyThread(true);
ms->Resume();
Memo1->Lines->Clear();
for(int i=0;i<20;++i){Memo1->Lines->Add("HHHH"+AnsiString(i));}
}
//---------------------------------------------------------------------------
void __fastcall TFMain::Button2Click(TObject *Sender)
{int res=-1;
res=ms->WaitFor();
Memo1->Lines->Add(AnsiString(res));
Memo1->Lines->Add(AnsiString(ms->arr[0]));
}
//---------------------------------------------------------------------------
//--- Заголовок главной программы
#ifndef UMainH
#define UMainH
//---------------------------------------------------------------------------
#include <Classes.hpp>
#include <Controls.hpp>
#include <StdCtrls.hpp>
#include <Forms.hpp>
//---------------------------------------------------------------------------
class TMyThread : public TThread
{
private:
protected:
void __fastcall Execute();
public:
__fastcall TMyThread(bool CreateSuspended);
double arr[100];
};
//---------------------------------------------------------------------------
class TFMain : public TForm
{
__published: // IDE-managed Components
TButton *Button1;
TMemo *Memo1;
TButton *Button2;
void __fastcall Button1Click(TObject *Sender);
void __fastcall Button2Click(TObject *Sender);
private: // User declarations
public: // User declarations
__fastcall TFMain(TComponent* Owner);
};
//---------------------------------------------------------------------------
extern PACKAGE TFMain *FMain;
//---------------------------------------------------------------------------
#endif
//--- Программа UTH
#include <vcl.h>
#pragma hdrstop
#include "UTH.h"
//---------------------------------------------------------------------------
#pragma package(smart_init)
#pragma resource "*.dfm"
TFTH *FTH;
//---------------------------------------------------------------------------
// Important: Methods and properties of objects in VCL can only be
// used in a method called using Synchronize, for example:
//
// Synchronize(UpdateCaption);
//
// where UpdateCaption could look like:
//
// void __fastcall Unit1::UpdateCaption()
// {
// Form1->Caption = "Updated in a thread";
// }
//---------------------------------------------------------------------------
__fastcall TMyThread1::TMyThread1(bool CreateSuspended)
: TThread(CreateSuspended)
{
}
//---------------------------------------------------------------------------
void __fastcall TMyThread1::Execute()
{
//---- Place thread code here ----
double s=0,t;
for(int i=1;i<1000000000;++i)
{t=i;
s=s+1/t;
}
arr[0]=s;
ReturnValue=32;
}
//---------------------------------------------------------------------------
//---------------------------------------------------------------------------
__fastcall TFTH::TFTH(TComponent* Owner)
: TForm(Owner)
{
}
//---------------------------------------------------------------------------
//--- Заголовок программы UTH
#ifndef UTHH
#define UTHH
//---------------------------------------------------------------------------
#include <Classes.hpp>
#include <Controls.hpp>
#include <StdCtrls.hpp>
#include <Forms.hpp>
//---------------------------------------------------------------------------
class TMyThread1 : public TThread
{
private:
protected:
void __fastcall Execute();
public:
__fastcall TMyThread1(bool CreateSuspended);
double arr[100];
};
//---------------------------------------------------------------------------
class TFTH : public TForm
{
__published: // IDE-managed Components
private: // User declarations
public: // User declarations
__fastcall TFTH(TComponent* Owner);
};
//---------------------------------------------------------------------------
extern PACKAGE TFTH *FTH;
//---------------------------------------------------------------------------
#endif
Данный пример иллюстрирует возможность запуска процесса, параллельного основному.
Примером алгоритмов, допускающих простое распараллеливание, могут служить алгоритмы метода ветвей и границ.
В данном случае алгоритм имеет вид, описанный ниже.
1. Прием входных параметров.
2. Решение основной задачи оценки.
3. Если оценка не лучше рекорда, завершить процесс.
4. Найти допустимое решение.
5. Если решение лучше рекорда, выдать запрос на обновление рекорда и ждать подтверждение принятия запроса.
6. Если оценка не лучше рекорда, завершить процесс.
7. Определить ветви влево и вправо.
8. Запустить процесс влево.
9. Запустить процесс вправо.
10. Освободить память.
11. Ждать завершения процесса влево.
12. Ждать завершения процесса вправо.
13. Завершить процесс.
Такое распараллеливание допускает запуск программ на разных компьютерах и не требует жесткой синхронизации. Однако далеко не всякие алгоритмы имеют блоки, допускающие независимое выполнение.
Другим способом распараллеливания является разбиение циклов.
В качестве примера рассмотрим вычислительный цикл c матрицей a и вектором b.
for(int i=0; i<n; ++i) exec_prog(a[i], b, res);
Вместо него можно породить m параллельных процессов, получающих в качестве параметров фрагмент матрицы a и вектор b. Предполагается, что в процессе вычислений матрица и вектор не меняются.
for(int j=0; j<m; ++j) {
// запуск процесса с параметрами &(a[j*n/m]), int((j+1)*n/m)- int(j*n/m), b
…
}
// Ожидание окончания запущенных процессов
Рассмотрим выполнение распараллеленного алгоритма.
Схематически его можно представить в следующем виде:
A→(B1, B2… Bn)↓S1, C→ (D1, D2… Dm)↓S2, E→(F1, F2… Fk) )↓ S3…
Этап алгоритма A выполняется последовательно и запускает n параллельных процессов Bi.
Этап S1 ожидает окончание процессов Bi.
Этап алгоритма C выполняется последовательно и запускает m параллельных процессов Di.
Этап S2 ожидает окончание процессов Di.
Этап алгоритма C выполняется последовательно и запускает k параллельных процессов Fi.
Этап S3 ожидает окончание процессов Fi.
…
Сравним времена работы последовательного и параллельного алгоритмов.
В последовательном случае имеем

В параллельном случае имеем

Отсюда следует, что даже, если n=m=k=N, то  из -за того, что лишь часть алгоритма выполняется действительно параллельно. Кроме того при ожидании окончания параллельного блока приходится ориентироваться на время окончания последнего из параллельных алгоритмов. Таким образом КПД параллельной программы в оптимистичном случае вряд ли превысит 50-60%. Однако, учитывая ограничение на производительность отдельного процессора и отсутствия видимых ограничений на количество процессоров, применение параллельных процессов представляется весьма эффективным.
из -за того, что лишь часть алгоритма выполняется действительно параллельно. Кроме того при ожидании окончания параллельного блока приходится ориентироваться на время окончания последнего из параллельных алгоритмов. Таким образом КПД параллельной программы в оптимистичном случае вряд ли превысит 50-60%. Однако, учитывая ограничение на производительность отдельного процессора и отсутствия видимых ограничений на количество процессоров, применение параллельных процессов представляется весьма эффективным.
Лекция 6
Тема: Сложные структуры данных. Хранение данных переменной структуры. Механизм тегов. Методы упорядочения данных. Сортировки. Деревья. Красно-черные и сбалансированые деревья. Хеш-таблицы Мониторинг сложных систем. Сети Петри, состав и правила выполнения. Мониторинг и обработка состояний систем с большим количеством условий.
Сети Петри
Сети Петри — аппарат для моделирования динамических дискретных систем (преимущественно асинхронных параллельных процессов). Сеть Петри определяется как четверка  , где
, где 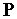 и
и  — конечные множества позиций и переходов,
— конечные множества позиций и переходов,  и
и 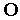 — множества входных и выходных функций. Другими словами, сеть Петри представляет собой двудольный ориентированный граф, в котором позициям соответствуют вершины, изображаемые кружками, а переходам — вершины, изображаемые утолщенными черточками; функциям соответствуют дуги, направленные от позиций к переходам, а функциям — от переходов к позициям.
— множества входных и выходных функций. Другими словами, сеть Петри представляет собой двудольный ориентированный граф, в котором позициям соответствуют вершины, изображаемые кружками, а переходам — вершины, изображаемые утолщенными черточками; функциям соответствуют дуги, направленные от позиций к переходам, а функциям — от переходов к позициям.
Как и в системах массового обслуживания, в сетях Петри вводятся объекты двух типов: динамические — изображаются метками (маркерами) внутри позиций и статические — им соответствуют вершины сети Петри.
Распределение маркеров по позициям называют маркировкой. Маркеры могут перемещаться в сети. Каждое изменение маркировки называют событием, причем каждое событие связано с определенным переходом. Считается, что события происходят мгновенно и разновременно при выполнении некоторых условий.
Каждому условию в сети Петри соответствует определенная позиция. Совершению события соответствует срабатывание (возбуждение или запуск) перехода, при котором маркеры из входных позиций этого перехода перемещаются в выходные позиции. Последовательность событий образует моделируемый процесс.
Правила срабатывания переходов (рис. 1), конкретизируют следующим образом: переход срабатывает, если для каждой из его входных позиций выполняется условие  , где
, где  — число маркеров в
— число маркеров в  -й входной позиции,
-й входной позиции, 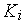 — число дуг, идущих от -й позиции к переходу; при срабатывании перехода число маркеров в -й входной позиции уменьшается на , а в
— число дуг, идущих от -й позиции к переходу; при срабатывании перехода число маркеров в -й входной позиции уменьшается на , а в 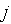 -й выходной позиции увеличивается на
-й выходной позиции увеличивается на 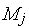 , где — число дуг, связывающих переход с -й позицией.
, где — число дуг, связывающих переход с -й позицией.
На рис. 1 показан пример распределения маркеров по позициям перед срабатыванием, эту маркировку записывают в виде (2,2,3,1). После срабатывания перехода маркировка становится иной: (1,0,1,4).
Можно вводить ряд дополнительных правил и условий в алгоритмы моделирования, получая ту или иную разновидность сетей Петри. Так, прежде всего полезно ввести модельное время, чтобы моделировать не только последовательность событий, но и их привязку ко времени. Это осуществляется приданием переходам веса — продолжительности (задержки) срабатывания, которую можно определять, используя задаваемый при этом алгоритм. Полученную модель называют временной сетью Петри.

|
Рис. 1. Фрагмент сети Петри
Если задержки являются случайными величинами, то сеть называют стохастической сетью Петри. В стохастических сетях возможно введение вероятностей срабатывания возбужденных переходов. Так, на рис. 2 представлен фрагмент сети Петри, иллюстрирующий конфликтную ситуацию — маркер в позиции 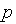 может запустить либо переход
может запустить либо переход 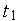 , либо переход
, либо переход  . В стохастической сети предусматривается вероятностный выбор срабатывающего перехода в таких ситуациях.
. В стохастической сети предусматривается вероятностный выбор срабатывающего перехода в таких ситуациях.

|
Рис. 2. Конфликтная ситуация
Если задержки определяются как функции некоторых аргументов, которыми могут быть количества маркеров в каких-либо позициях, состояния некоторых переходов и т.п., то имеем функциональную сеть Петри.
Во многих задачах динамические объекты могут быть нескольких типов, и для каждого типа нужно вводить свои алгоритмы поведения в сети. В этом случае каждый маркер должен иметь хотя бы один параметр, обозначающий тип маркера. Такой параметр обычно называют цветом; цвет можно использовать как аргумент в функциональных сетях. Сеть при этом называют цветной сетью Петри.
Среди других разновидностей сетей Петри следует упомянуть ингибиторные сети Петри, характеризующиеся тем, что в них возможны запрещающие (ингибиторные) дуги. Наличие маркера во входной позиции, связанной с переходом ингибиторной дугой, означает запрещение срабатывания перехода.
Введенные понятия поясним на следующих примерах.
Пример 1
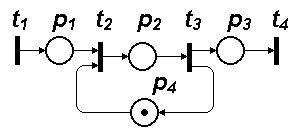
Требуется описать с помощью сети Петри работу группы пользователей на единственной рабочей станции WS при заданных характеристиках потока запросов на пользование WS и характеристиках поступающих задач. Сеть Петри представлена на рис. 3.
Здесь переходы связаны со следующими событиями: 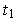 — поступление запроса на использование WS,
— поступление запроса на использование WS, 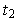 — занятие станции,
— занятие станции, 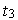 — освобождение станции,
— освобождение станции,  — выход обслуженной заявки; позиция
— выход обслуженной заявки; позиция  используется для отображения состояния WS: если в имеется метка, то WS свободна и пришедшая заявка вызывает срабатывание перехода ; пока эта заявка не будет обслужена, метки в не будет, следовательно, пришедшие в позицию
используется для отображения состояния WS: если в имеется метка, то WS свободна и пришедшая заявка вызывает срабатывание перехода ; пока эта заявка не будет обслужена, метки в не будет, следовательно, пришедшие в позицию  запросы вынуждены ожидать срабатывания перехода .
запросы вынуждены ожидать срабатывания перехода .
|
Рис. 3. Сеть Петри для примера 1
Пример 2
На рис. 4 представлена сеть Петри, соответствующая организации параллельных вычислений на основе асинхронного message passing interface (MPI) [1].

|
Рис. 4. Сеть Петри для примера 2
Пример 3
Требуется описать с помощью сети Петри процессы возникновения и устранения неисправностей в некоторой технической системе, состоящей из множества однотипных блоков; в запасе имеется один исправный блок; известны статистические данные об интенсивностях возникновения отказов и длительностях таких операций, как поиск неисправностей, замена и ремонт отказавшего блока. Поиск и замену отказавшего блока производит одна бригада, а ремонт замененного блока — другая бригада. Сеть Петри показана на рис. 5. Отметим, что при числе меток в позиции, равном  , можно в ней не ставить точек, а записать в позиции значение .
, можно в ней не ставить точек, а записать в позиции значение .
В нашем примере значение в позиции  соответствует числу имеющихся в системе блоков. Переходы отображают следующие события: — отказ блока, — поиск неисправного блока, — его замена, — окончание ремонта.
соответствует числу имеющихся в системе блоков. Переходы отображают следующие события: — отказ блока, — поиск неисправного блока, — его замена, — окончание ремонта.
Очевидно, что при непустой позиции переход срабатывает, но с задержкой, равной вычисленному случайному значению моделируемого отрезка времени между отказами. После выхода маркера из он попадает через в , если имеется метка в позиции  , это означает, что обслуживающая систему бригада специалистов свободна и может приступить к поиску возникшей неисправности. В переходе метка задерживается на время, равное случайному значению длительности поиска неисправности. Далее маркер оказывается в
, это означает, что обслуживающая систему бригада специалистов свободна и может приступить к поиску возникшей неисправности. В переходе метка задерживается на время, равное случайному значению длительности поиска неисправности. Далее маркер оказывается в  и, если имеется запасной блок (маркер в ), то запускается переход , из которого маркеры выйдут в ,
и, если имеется запасной блок (маркер в ), то запускается переход , из которого маркеры выйдут в ,  и в через отрезок времени, требуемый для замены блока. После этого в имитируется восстановление неисправного блока.
и в через отрезок времени, требуемый для замены блока. После этого в имитируется восстановление неисправного блока.
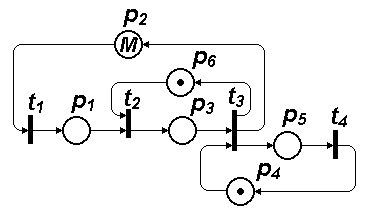
|
Рис. 5. Сеть Петри для примера 3
Рассматриваемая модель описывает функционирование системы в условиях, когда отказы могут возникать и в рабочем, и в неисправном состояниях системы. Поэтому не исключены ситуации, при которых более чем один маркер окажется в позиции .
Лекция 7
Тема: Сетевое взаимодействие. Взаимодействие процессов в рамках вычислительной сети. Типы взаимодействия. Интерфейс sockets.
Сокеты (sockets) представляют собой высокоуровневый унифицированный интерфейс взаимодействия с телекоммуникационными протоколами.
Программирование сокетов несложно само по себе, но довольно поверхностно описано в доступной литературе, а Windows Sockets SDK содержит многоженство ошибок как в технической документации, так и в прилагаемых к ней демонстрационных примерах. К тому же имеются значительные отличия реализаций сокетов в UNIX и в Windows, что создает очевидные проблемы.
Основное подспорье в изучении сокетов - Windows Sockets 2 SDK. SDK - это документация, набор заголовочных файлов и инструментарий разработчика. Документация не то, чтобы очень хороша - но все же написана достаточна грамотно и позволяет, пускай, не без труда, освоить сокеты даже без помощи какой-либо другой литературы. Причем, большинство книг, имеющиеся на рынке, явно уступают Microsoft в полноте и продуманности описания. Единственный недостаток SDK - он полностью на английском (для некоторых это очень существенно).
Из инструментария, входящего в SDK, в первую очередь хотелось бы выделить утилиту sockeye.exe - это настоящий "тестовый стенд" разработчика. Она позволяет в интерактивном режиме вызывать различные сокет-функции и манипулировать ими по своему усмотрению.
Демонстрационные программы, к сожалению, не лишены ошибок, причем порой довольно грубых и наводящих на мысли - а тестировались ли эти примеры вообще? (Например, в исходном тексте программы simples.c в вызове функций send и sendto вместо strlen стоит sizeof) В то же время, все примеры содержат множество подробных комментариев и раскрывают довольно любопытные приемы нетрадиционного программирования, поэтому ознакомится с ними все-таки стоит.
Из WEB-ресуросов, посвященных программированию сокетов, и всему, что с ними связано, в первую очередь хотелось бы отметить следующие три: sockaddr.com; www.winsock.com и www.sockets.com.
Обзор сокетов
Библиотека Winsock поддерживает два вида сокетов - синхронные (блокируемые) и асинхронные (неблокируемые). Синхронные сокеты задерживают управление на время выполнения операции, а асинхронные возвращают его немедленно, продолжая выполнение в фоновом режиме, и, закончив работу, уведомляют об этом вызывающий код.
ОС Windows 3.x поддерживает только асинхронные сокеты, поскольку, в среде с корпоративной многозадачностью захват управления одной задачей "подвешивает" все остальные, включая и саму систему. ОС Windows 9x\NT поддерживают оба вида сокетов, однако, в силу того, что синхронные сокеты программируются более просто, чем асинхронные, последние не получили большого распространения. Эта статья посвящена исключительно синхронным сокетам (асинхронные - тема отдельного разговора).
Сокеты позволяют работать со множеством протоколов и являются удобным средством межпроцессорного взаимодействия, но в данной статье речь будет идти только о сокетах семейства протоколов TCP/IP, использующихся для обмена данными между узлами сети Интернет. Все остальные протоколы, такие как IPX/SPX, NetBIOS по причине ограниченности объема журнальной статьи рассматриваться не будут.
Независимо от вида, сокеты делятся на два типа - потоковые и дейтаграммные. Потоковые сокеты работают с установкой соединения, обеспечивая надежную идентификацию обоих сторон и гарантируют целостность и успешность доставки данных. Дейтаграмные сокеты работают без установки соединения и не обеспечивают ни идентификации отправителя, ни контроля успешности доставки данных, зато они заметно быстрее потоковых.
Выбор того или иного типа сокетов определяется транспортным протоколом на котором работает сервер, - клиент не может по своему желанию установить с дейтаграммным сервером потоковое соединение.
Замечание: дейтаграммные сокеты опираются на протокол UDP, а потоковые на TCP.
|
из
5.00
|
Обсуждение в статье: Алгоритм работы с польской нотацией |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы