 |
Главная |


Встроенные методы отбора признаков на основе байесовского подхода
|
из
5.00
|
Наиболее часто используемым встроенным методом отбора признаков является регуляризация. Основная идея заключается во включении в целевую функцию слагаемого (регуляризатора), который «штрафует» коэффициенты модели, устремляя их к нулю.
При регуляризации вектор параметров w рассматривается как вектор случайных чисел с априорным распределением 𝑝(𝒘).
Апостериорная плотность распределения параметров ищется по формуле Байеса:
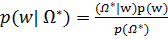

Так как 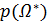 не зависит от w, следовательно:
не зависит от w, следовательно:
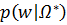 ∞
∞ 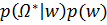
Используя принцип максимизации апостериорной плотности, получаем точечную оценку значений вектора параметров:
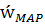 =
= 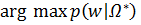 =
= 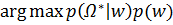 (4)
(4)
= 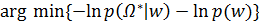 (5)
(5)
В формуле (5) второе слагаемое является вышеупомянутым регуляризатором или, так называемой, штрафной функцией. Обычно штрафная функция включается в модель с коэффициентом, с помощью которого можно контролировать количество отбираемых в модель признаков.
Перечислим самые распространенные методы регуляризации:
· Гребневая регрессия (ridge). В данном методе в качестве априорного распределения выбирается нормальное распределение. Штрафная функция будет выглядеть следующим образом:
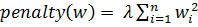 (6)
(6)
Метод сжимает коэффициенты. Количество признаков не меняется, но понижается эффективная размерность задачи.
· Метод Lasso. В данном методе в качестве априорного распределения выбирается закон Лапласа. Штрафная функция примет следующий вид:
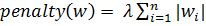 (7)
(7)
Данный метод производит отбор признаков, но при этом если признаки сильно коррелированны, то отберется только один из них, что является недостатком.
· Метод Elastic Net. Данный метод комбинирует два предыдущих:
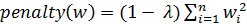 +
+ 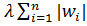 (8)
(8)
Основной целью его создания было желание преодолеть неспособность метода Lasso отбирать коррелируемые признаки в модель.
Разработка модели
При решении задачи бинарной классификации условное распределение зависимой переменной представляет собой распределение Бернулли:
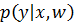 =
= 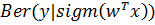 (9)
(9)
где 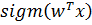 =
= 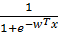 – логистическая функция (сигмоида),
– логистическая функция (сигмоида),
а 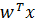 =
= 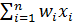 – линейная гиперплоскость.
– линейная гиперплоскость.
Тогда вероятности того, что заемщик принадлежит к классам «плохих» и «хороших» равны соответственно:
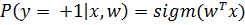 (10)
(10)
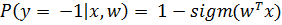 (11)
(11)
Можно записать это одним выражением:
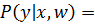
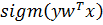 =
= 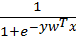 (12)
(12)
Мы предполагали, что наблюдения в обучающей выборке независимы, поэтому функция правдоподобия будет выглядеть следующим образом:
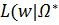 ) =
) = 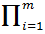 p(
p( 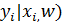 =
= 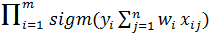 (13)
(13)
Используя принцип максимума правдоподобия, получаем оценку вектора параметров:
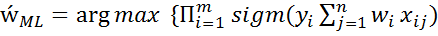 } (14)
} (14)
Прологарифмируем функцию правдоподобия (14) и будем решать задачу минимизации:
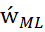 = arg min
= arg min 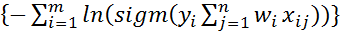 (15)
(15)
В соответствии с (15) оценивают коэффициенты в классической нерегуляризованной логистической регрессии. Предположим, что априорной плотностью распределения параметра является нормальное распределение с нулевым матожиданием и дисперсией r. В модели дисперсия будет являться случайной величиной.
Тогда совместное распределение вектора параметров будет иметь вид:
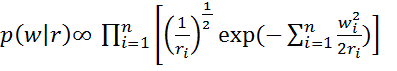 (16)
(16)
Параметры с малым значением 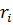 могут быть удалены из модели, а остальные параметры будут называться релевантными. Здесь – является гиперпараметром модели.
могут быть удалены из модели, а остальные параметры будут называться релевантными. Здесь – является гиперпараметром модели.
Попробуем величины, обратные дисперсиям, использовать в качестве штрафных функций. Тогда предполагаем, что априорная плотность распределения величин обратных дисперсиям является гамма-распределением:
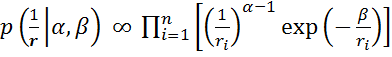 (17)
(17)
Из (17) видно, что обратная дисперсия зависит от двух параметров гаммараспределения 𝛼,𝛽. Для облегчения процесса подбора параметров предположим, что они являются функциями от одного и того же параметра 𝜇.
Для случайной величины, имеющей гамма-распределение, известно:
● E 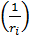 =
= 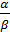 – математическое ожидание
– математическое ожидание
● 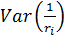 =
= 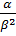 – дисперсия
– дисперсия
Рассмотрим отношение 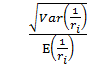 =
= 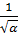 :
:
● Если 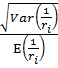 → 0, то значит все распределения дисперсий
→ 0, то значит все распределения дисперсий
сконцентрированы возле математического ожидания. Тогда можно сказать, что оцененные дисперсии практически фиксированы и равны единице при 𝛼 ≅ 𝛽.
● Если → 1, то априорные распределения становятся практически равномерными.
При → 0: ln → −∞ и критерию выгодно уменьшать все дисперсии. Но в этом случае невозможно выполнить ограничения, предписывающие достаточно хорошо приближать обучающую совокупность. Из-за этого противоречия критерий проявляет ярко выраженную склонность к чрезмерной селективности отбора признаков, подавляя большинство из них, в том числе и релевантные.
Получается, что необходимо выполнение следующих требований:
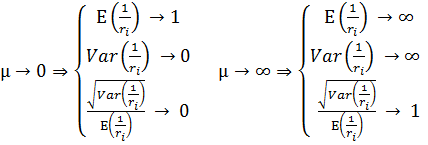 (18)
(18)
Одним из наборов функций, удовлетворяющих требованиям, является:
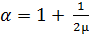 и
и 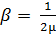 (19)
(19)
С учетом всех предположений об априорных распределениях вектора параметров и гиперпараметров получаем следующую оценку вектора параметров:
= 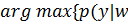 ,
, 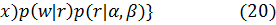
= 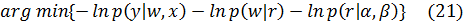
Тогда получаем следующий критерий обучения:
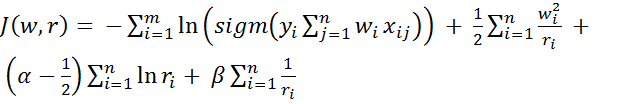 →
→ 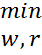 (22)
(22)
Подставим в критерий выбранные функции для 𝛼 и 𝛽:
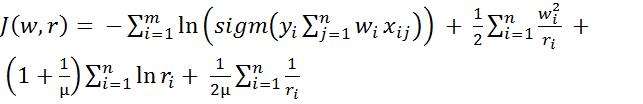 → (23)
→ (23)
Этот критерий будем называть моделью логистической регрессии с регулируемой селективностью.
|
из
5.00
|
Обсуждение в статье: Встроенные методы отбора признаков на основе байесовского подхода |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы