 |
Главная |


Экспериментальные результаты.
|
из
5.00
|
Мы проводили эксперименты на генетических данных для определения эффективности наших алгоритмов. Программа была написана на C, основывалась на втором алгоритме (из 4-го раздела) и запускалась на оборудовании Sun Ultra 1 под управлением операционной системы Sun Solaris 2.5. Последовательности нуклеотидов общим объемом 24KB взяты из базы данных GenBank [11]. Мы получили 450 положительных последовательностей относящихся к сигнальным пептидам, и 450 отрицательных последовательностей 450 из других последовательностей, и предобработатывали данные, преобразовывая двадцать аминокислот в три символа 0,1,2 индексами из Kyte и Doolittle (1982). Для каждого m = 10 ~ 100 и каждого испытания мы случайно выбирали m положительных и m отрицательных последовательностей из исходной выборки S и вычисляли оптимальные образцы для полученной выборки.
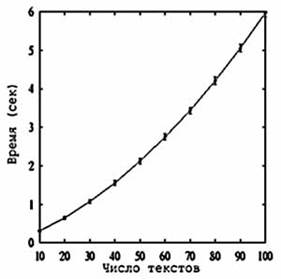
Время работы. На рисунке можно увидеть зависимость времени работы алгоритма от числа документов m, которое пропорционально размеру выборки n. Мы видим, что рост времени является более медленным, чем мы это ожидали из теоремы 2. Для большей выборки, размером 24KB (m = 450), алгоритм работает одну минуту и требует более 20MB памяти, при этом находит 37 оптимальных образцов, проверяя 676 часто повторяющихся из 577296729 возможных образцов. Примерами оптимальных образцов являются “12222”*”2” и “0”*”2222”, достигающие доверия 69% и 66% при поддержке 65%.
Случайная выборка. Рисунок показывает результат применения эвристики выборки (sampling).
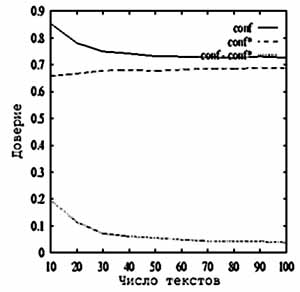
Для каждого испытания сначала вычисляются лучшие десять образцов выборки Sm, затем оценивается эмпирическое значение доверия conf для Sm и действительное значение доверия conf * для S. Мы отобразили среднее значение доверия для 100 испытаний для каждого m. Параметры были k = 5, s = 0.6. На рисунке можно видеть, что ошибка доверия – 5% для 10% выборки. Для значения поддержки мы имели подобный результат (12% ошибок).
Обрезание ( pruning ): На таблице показана эффективность применения эвристики обрезания.
| s | Размер выборки (байт) | Всего вариантов | Локально частых | Глобально частых |
| 90% | 2701 | 7,295,401 | 121 | 40 |
| 50% | 2754 | 7,584,516 | 1,444 | 64 |
| 30% | 2764 | 7,639,696 | 6,241 | 88 |
Выборка состояла из 50 положительных и 50 отрицательных последовательностей, общим размером 2.7KB. Первый и второй столбцы показывают минимальную поддержку и размер выборки; третий, четвертый и пятый – число образцов изначально, оставшихся после локального обрезания и после глобального. Мы можем видеть, что только небольшая часть образцов может быть разрешима для почти случайной последовательности.
Заключение
В этой статье мы рассмотрели задачу поиска правил зависимости для подстрок и дали эффективный алгоритм, который находит оптимальные правила (optimized confidence rules) из большого набора неструктурированных текстовых данных для класса образцов зависимых двух слов. Мы обсудили работу алгоритмов, эвристики и проведение экспериментов с генетическими данными.
Алгоритмы, данные в этой статье, эффективно используют структуру данных суффиксные массивы, которая представляет собой вариант суффиксного дерева, являющимся более эффективным и подходящим для осуществления функций продвинутого поиска в больших текстовых базах данных (Gonnet и Baeza-Yates [14]; Manber и Myers [22]). Таким образом, это - будущая задача разработки масштабируемых методов реализации суффиксных массивов, которая позволяет включить наши алгоритмы в существующие текстовые базы данных. Изучение применения алгоритма для вторичных устройств хранения и ускорение для параллельного выполнения – другие будущие задачи.
Мы разработали эффективный обучающийся алгоритм для класса структурированных шаблонов [4-6]. Было бы интересно расширить структуру образцов, введенных в этой статье.
Ссылки
1. S. Abiteboul, Querying semistructured data. In Proc. ICDT'97 (1997).
2. R. Agrawal, T. Imielinski, A. Swami, Mining association rules between sets of items
in large databases. In Proc. the 1993 ACM SIGMOD Conference on Management
of Data, 207--216 (1993).
3. A. Amir, M. Farach, Z. Galil, R. Giancarlo, K. Park, Dynamic Dictionary Match
ing. JCSS, 49 (1994), 208-222.
4. H. Arimura, R. Fujino, T. Shinohara, and S. Arikawa. Protein motif discovery
from positive examples by minimal multiple generalization over regular patterns
Proc. Genome Informatics Workshop 1994, 39-48, 1994.
5. H. Arimura, H. Ishizaka, T. Shinohara, Learning unions of tree patterns using
queries, Theoretical Computer Science, 185 (1997) 47-62.
6. H. Arimura, T. Shinohara, S. Otsuki. Finding minimal generalizations for unions
of pattern languages and its application to inductive inference from positive data.
In Proc. the 11th STACS, LNCS 775, (1994) 649-660.
7. L. Devroye, W. Szpankowski, B. Rais, A note on the height of the suffix trees.
SIAM J. Comput., 21, 48-53 (1992).
8. D. P. Dobkin and D. Gunopulos, Concept learning with geometric hypothesis. In
Proc. COLT95 (1995) 329-336.
9. R. Feldman and I. Dagan, Knowledge Discovery in Textual Databases (KDT). In
Proc. KDD95 (1995).
10. T. Fukuda, Y. Morimoto, S. Morishita, and T. Tokuyama, Data mining using
twodimensional optimized association rules. In Proc. the 1996 ACM SIGMOD
Conference on Management of Data, (1996) 13-23.
11. GenBank, GenBank Release Notes, IntelliGenetics Inc. (1991).
12. G. Gras and J. Nicolas, FOREST, a browser for huge DNA sequences. In Proc. the
7th Workshop on Genome Informatics (1996).
13. G. Gonnet, PAT 3.1: An efficient text searching system, User's manual. UW Center
for the New OED, University of Waterloo (1987).
14. G. Gonnet, R. BaezaYates, Handbook of Algorithms and Data Structures,
AddisonWesley (1991).
15. J. Han, Y. Cai, N. Cercone, Knowledge discovery in databases: An attribute
oriented approach. In Proc. the 18th VLDB Conference, 547-559 (1992).
16. D. Haussler, Decision theoretic generalization of the PAC model for neural net and
other learning applications. Information and Computation 100 (1992) 78-150.
17. M. J. Kearns, R. E. Shapire, L. M. Sellie, Toward efficient agnostic learning.
Machine Learning, 17(2--3), 115-141, 1994.
18. J. Kyte and R. F. Doolittle, In J. Mo. Biol., 157 (1982), 105-132.
19. D. D. Lewis, Challenges in machine learning for text classification. In Proc. 9th
Computational Learning Theory (1996), pp. 1.
20. W. Maass, Efficient agnostic PAClearning with simple hypothesis, In
Proc. COLT94 (1994), 67-75.
21. U. Manber and R. BaezaYates, An algorithm for string matching with a sequence
of don't cares. IPL 37, 133-136 (1991).
22. U. Manber and E. Myers, ``Suffix arrays'': a new method for online string searches.
In Proc. the 1st ACMSIAM Symposium on Discrete Algorithms (1990)319-327.
23. H. Mannila, H. Toivonen, Discovering generalized episodes using minimal occur
rences. In Proc. KDD'96 (1996) 146-151.
24. E. M. McCreight, A spaceechonomical suffix tree constructiooon algorithm. JACM
23 (1976), 262-272.
25. M. Nakanishi, M. Hashidume, M. Ito, A. Hashimoto, A lineartime algorithm for
computing characteristic strings. In Proc. the 5th International Symposium on
Algorithms and Computation (1994), 31523.
26. OPENTEXT Index.
http://index.opentext.net (1997).
27. F. P. Preparata, M. I. Shamos, Computational Geometry. SpringerVerlag (1985).
28. J. T.L. Wang, G.W. Chirn, T. G. Marr, B. Shapiro, D. Shasha, K. Zhang. Com
binatorial Pattern Discovery for Scientific Data: Some preliminary results. In
Proc. 1994 SIGMOD (1994) 115-125.
|
из
5.00
|
Обсуждение в статье: Экспериментальные результаты. |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы