 |
Главная |


Лингвистическое обеспечение КИС
|
из
5.00
|
Лингвистическое и правовое обеспечение КИС.
Лингвистическое обеспечение (ЛО) представляет собой совокупность научно–технических терминов и других языковых средств, используемых в информационных системах, а также правил формализации естественного языка, включающих в себя методы сжатия и раскрытия текстовой информации для повышения эффективности автоматизированной обработки информации.
Основным средством описания информационной базы и информационной потребности служат информационно–поисковые языки, относящиеся к классу искусственных языков. Помимо таких строго формализованных с точки зрения семантики и синтаксиса средств, в качестве дополнительных широко применяются терминологические структурыразличного назначения, имеющие как линейную, так и нелинейную (иерархическую, сетевую) организацию. Состав лингвистического обеспечения (ЛО) информационных систем может быть представлен следующей схемой (рис. 1):
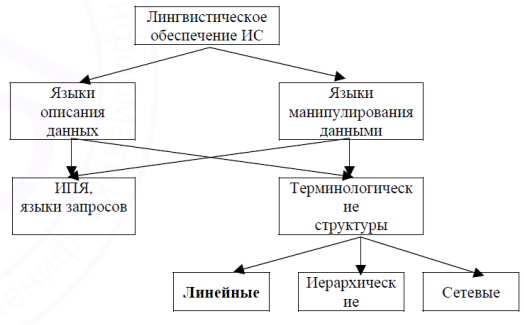
Рис. 1. Состав лингвистического обеспечения информационных систем
В предложенной схеме информационно–поисковые языки служат как средства выражения смыслового содержания документов и информационной потребности пользователя, языки манипулирования как попытки обобщения средств управления данными, терминологические структуры как моделей данных, с одной стороны, и понятийных систем, выражаемых средствами искусственного языка с естественной лексикой – с другой. Далее приведем характеристики выделенных компонентов ЛО ИС.
Для изучения принципов и методов построения и использования компонентов ЛО предварительно определим базовые понятия.
Язык– это знаковая система любой физической природы, выполняющая познавательную и коммуникативную функцию в процессе человеческой деятельности.
Искусственный язык(в отличие от естественного, представляющего собой средство общения и выражения мысли и неоднозначного по своей природе) – это специализированный язык, основное назначение которого состоит в устранении многозначности слов естественного языка и всего того, что характеризует эмоции и отношение к различным предметам. В искусственном языке должны выражаться лишь объективные характеристики предметов, их связей и соотношений.
Многозначность слов естественного языка и служащая в некотором роде показателем развитости языка, становится препятствием в случае использования в системе хранения и обработки информации. В связи с этим в ИС применяются искусственные языки, специально сконструированные для формулировки основного смыслового содержания информационной базы и информационной потребности с целью последующего их сопоставления. К таким языкам в первую очередь относятся информационно–поисковые языки (ИПЯ),обеспечивающие компактную, строго алгоритмизированную запись содержания документов и запросов в информационно–поисковой системе. ИПЯ можно определить как специализированную семантическую систему, состоящую из алфавита, правил образования (грамматики) и правил интерпретации (семантики).
Алфавит– это любая конечная совокупность знаков (букв, цифр и т.п.), используемых в ИПЯ.
Выделяют морфологические и синтаксические правила образования (построения) терминов– слов языка. Морфологические правила определяют процедуру построения терминов ИПЯ из его морфем, а синтаксические – процедуру построения предложений (фраз) из этих терминов. Синтаксические правила – обязательный элемент любого ИПЯ. В некоторых ИПЯ для соединения терминов в предложения (фразы) применяются специальные лексические средства.
Последний элемент ИПЯ, если его рассматривать как специализированный абстрактный язык это правила интерпретации, т.е. правила перевода терминов и предложений (фраз) ИПЯ на соответствующий естественный язык. Эти правила задаются, например, в в виде двуязычных словарей, в которых каждому термину (лексической единице) ставится в соответствие определенное слово или выражение естественного языка, и наоборот. В такой словарь включаются также все символы, применяемые в данном ИПЯ для соединения терминов в предложения (фразы). Кроме того, правила интерпретации для ИПЯ, как и правил построения, формулируются на естественном языке в специальных инструкциях, методиках и т. д.
Рассмотрим типологию ИПЯ по способности к выражению смыслового содержания документов, как структурных единиц информационной базы. Опираясь на лексику, грамматику и синтаксис, выделим два основных типа ИПЯ:
– языки классификационного типа (классификация);
– языки дескрипторного типа (индексирование).
Классификация, как средство описания содержания документа, представляет собой процесс соотнесения содержания документов с понятиями, зафиксированными в заранее составленных систематических схемах. Основная цель классификации – приписать каждый документ классу, или, иначе – приписать каждому документу имя класса, формируя тем самым множества сообщений для обработки и поиска.
Языки дескрипторного типа поддерживают процесс индексирования, который заключается в формировании описания документа как совокупности дескрипторов (синонимов, обозначающих одно понятие), выбираемых из заранее созданных словарей понятий, либо из текстов документов.
Следующий компонент ЛО ИС: языки описания данных, предназначены для описания данных на разных уровнях абстракции: внешнем, логическом и внутреннем. Считается, что языки описания данных на логическом (концептуальном) и внутреннем уровнях независимые и разные. Однако в большинстве промышленных СУБД языки не делится на два отдельных языка описания логической и физической организации данных, а существует единый язык, которая еще называется языком описания схем. В известных и широко используемых на практике СУБД семьи dBASE применяется единый язык описания данных. Он предназначен для представления данных на логическом и физическом уровнях. Этот язык имеет свой синтаксис: например, имя файла не должно превышать восьми символов, а имя поля - десяти; при этом каждое имя может начинаться с буквы, поля календарной даты обозначаются символом D (DATA), символьные поля — С (CHARACTER), числовые — N (NUMERIC), логические — L (LOGICAL), примечаний — М (MEMO).
Описание всех имен, типов и размеров полей сохраняется в памяти вместе с данными; эти структуры в случае необходимости можно просмотреть и исправить. Если логический и физический уровни отделены, то в состав СУБД может входить язык описания сохранения данных. В некоторых СУБД используется еще язык описания подсхем, который нужен для описания части БД, которая отражает информационные потребности отдельного пользователя или прикладной программы. В составе СУБД типа dBASE такой язык не используется.
Язык описания данных на внешнем уровне используется для описания требований пользователей и прикладных программ и создания инфологической модели БД. Этот язык не имеет ничего общего с языками программирования. Так, языковым средством, которое используются для моделирования, является обычный естественный язык или его подмножество, а также язык графов и матриц.
Языки манипулирования данными используются для обработки данных, их преобразований и написания программ. DML может быть базовым или автономным.
Базовый язык DML — это один из традиционных языков программирования (BASIC, C, FORTRAN и др.). Системы, которые используют базовый язык, называют открытыми. Использование базовых языков как языков описания данных сужает круг лиц, которые могут непосредственно обращаться к БД, поскольку для этого нужно знать язык программирования. В таких случаях для упрощения общения конечных пользователей с БД предполагается язык ведения диалога, который значительно проще для овладения, чем язык программирования.
Автономный язык DML — это собственный язык СУБД, который дает возможность выполнять различные операции с данными. Системы с собственным языком называют закрытыми.
Теперь рассмотрим еще один компонен ЛО ИС: терминологические структуры. В большинстве информационных систем помимо ИПЯ на этапах индексирования и поиска документов применяются различные средства, имеющие лингвистическую природу, например, тематические рубрикаторы, тезаурусы, словари как информативных, так и неинформативных лексических единиц, словари синонимов, словари словосочетаний и т.п. Организационная типология терминологических структур, приведенная на рис. 2, тесно связана с типологией по семантическому признаку. С точки зрения семантики словоупотребления терминологические структуры могут быть разделены на семантически упорядоченные и семантически неупорядоченные. При этом семантически неупорядоченные терминологические структуры всегда имеют линейную организацию, а семантически упорядоченные – иерархическую или сетевую организацию.
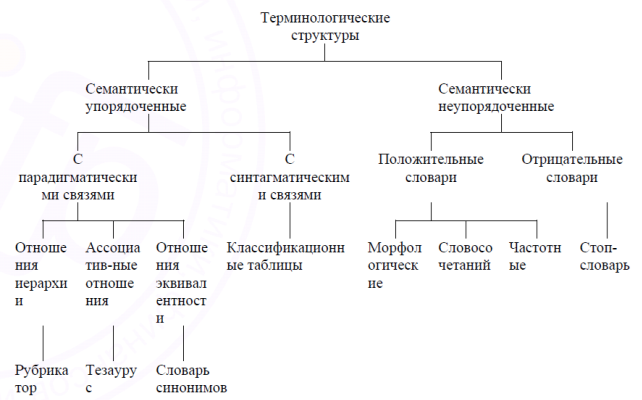
Рис. 2. Типология терминологических структур по семантическому признаку
Семантически упорядоченные терминологические структуры отражают оба типа связей, которые могут существовать между отдельными терминами – парадигматические и синтагматические. Парадигматические связи характеризуют различные виды отношений – отношения иерархии, ассоциативные отношения и отношения эквивалентности. Синтагматические связи показывают логические отношения между понятиями (рис. 2).
Основными представителями сетевых терминологических структур являются тезаурусы. Все понятия естественного языка, служащие для описания окружающего мира, входят во всеобщий тезаурус мира, отражающий весь универсум знаний. Такой тезаурус представляет собой список понятий, выраженных на естественном языке, с обозначением отношения между ними.
Всеобщий тезаурус можно подразделить на частные тезаурусы путем выделения совокупности однородных понятий по их иерархическому уровню или путем выделения понятий, которыми можно описать какую–либо специфическую часть мира. Таким образом, на основе всеобщего тезауруса можно составить бесконечное множество тезаурусов по различным областям знаний, по отдельным проблемам и задачам.
Тезаурус может быть представлен как семантическая сеть, в которой понятия связаны регулярными и устойчивыми семантическими отношениями – иерархическими (например, род–вид, целое–часть), ассоциативными, а также отношениями эквивалентности. При этом отдельное понятие определенной области знаний в тезаурусе представлено словом или словосочетанием, соотносящимся с другими словами и словосочетаниями и образующим вместе с ними замкнутую систему. Иерархические отношения в тезаурусе представляют собой классификацию, основанную на словах естественного языка, а не на абстрактных категориях, поэтому нарушается правильная структура дерева – один и тот же термин может иметь несколько «родителей» – вышестоящих терминов на предыдущем уровне. Например, в Тезаурусе по информатике словосочетание Автоматизированная обработка информации имеет два вышестоящих родителя: Автоматизированная обработка и Обработка информации, а слово Буквы – целых три родителя: алфавиты, символы, буквенно–цифровая информация. Тезаурус, отображая возможные семантические связи терминов, представленных в базах данных, является идеальным лексическим инструментом информационно–поисковых систем, с помощью которого можно найти необходимую лексику для составления запросов или их модификации с целью достижения наилучших показателей эффективности поиска.
Иерархические классификационные структуры.К таким структурам относятся различные рубрикаторы и классификаторы, фиксирующие подчинение терминов в определенной предметной области.
На рисунке 3 приведен фрагмент Рубрикатора ВИНИТИ для заглавной рубрики «201 Информатика». Рубрикатор ВИНИТИ является локальным (отраслевым) по отношению к Государственному рубрикатору и отличается большей детализацией рубрик.

Рис. 3. Фрагмент Рубрикатора ВИНИТИ
Словарь синонимов. Словарь синонимов, который для каждого входа словаря определяет одну или больше синонимичных категорий, также с точки зрения своей структуры может быть отнесен к иерархической организации терминов. Такие словари широко используются при индексировании, а также позволяют искать не только по запрошенному слову, но и по его синонимам. Ниже приведен фрагмент словаря синонимов для области «Информатика»:
…
ЭФФЕКТИВНОСТЬ ПОИСКА
информационная эффективность
техническая эффективность
эффективность информационного
ЮРИДИЧЕСКАЯ ДЕЯТЕЛЬНОСТЬ
юридическая практика
ЮРИСПРУДЕНЦИЯ
право
правоведение
юридические аспекты
К линейным терминологическим структурам относятся линейные словари различного назначения, обычно упорядоченные по лексикографическому принципу. С точки зрения своего участия в процессах индексирования документов и запросов такие словари делятся на положительные и отрицательные. Положительные словари объединяют лексику, которую можно использовать в процессе индексирования. Отрицательные словари содержат лексику, запрещенную для использования при индексировании.
Морфологические словари содержат основы слов, аффиксы, суффиксы и окончания. Такие словари могут быть использованы, с одной стороны, для нормализации поисковых образов документов, а с другой – для нормализации лексики поисковых запросов. Грамматический строй естественных языков нередко расходится со структурой логической мышления, и поэтому при поиске информации необходимо полностью или частично исключить влияние аффиксов и окончаний слов естественных языков. Для этого можно предусмотреть наращивание документов всеми потенциально возможными словоформами, которые можно составлять, например, на базе основ слов, первоначально содержащихся в документах. Наличие в паре «документ – запрос» словоформ, совпадающих с точностью до общности их корней, в результате такого наращивания может привести к появлению в документе словоформы, полностью совпадающей со словоформой, имеющейся в запросе. Такое наращивание снимало бы различие употреблений словоформ в документах и запросах. Другой технологический вариант, позволяющий снимать различие употреблений словоформ, состоит в использовании кодирования слов. Сущность метода автоматического кодирования слов с помощью наперед заданных словарей аффиксов и окончаний заключается в автоматической проверке на наличие в словах естественных языков элементов, вошедших в наперед заданные (составленные экспертами– лингвистами) словари аффиксов и окончаний, и отсечении их, если они имеются. От качества составления словарей аффиксов и окончаний в значительной мере зависит качество автоматического кодирования слов естественных языков, а, следовательно, и функциональная эффективность ИПС в целом. Ошибки могут быть следствием такого алгоритма, когда после включения очередной морфемы в словарь, она отсекается из всех слов естественно–языкового употребления в базе данных, не зависимо от того, является ли для конкретно рассматриваемого словаря морфемой или частью корня.
Словарь словосочетаний. Такой словарь используется для определения наиболее часто встречающихся устойчивых комбинаций слов. Словарь словосочетаний повышает эффективность анализа содержания, выделяя для идентификации содержания однозначные словосочетания вместо множества в общем случае однозначных (например, пара отдельных терминов «программа» и «язык» является менее определенной, чем словосочетание «язык программирования»).
Лингвистической особенностью словаря является то, что термины – одиночные слова зачастую не выражают никакого смысла, являясь только составной частью словосочетания.
Основываясь на том, что наиболее информативными терминами являются термины–словосочетания, наиболее правомерно использовать именно их для составления поискового запроса.
Частотный словарь.Частотный словарь – перечень дескрипторов и ключевых слов. Термины располагаются в алфавитном порядке, либо в порядке убывания (возрастания) частоты использования их в информационном массиве. Частотная характеристика термина показывает количество документов информационного массива, в которых термин встретился хотя бы один раз. Частота встречаемости ориентирует пользователя в лексике информационного массива с точки зрения включения какого–либо термина в поисковый запрос. Рассмотрим, например, фрагмент частотного словаря ретроспективной реферативной базы данных «Инфрматик» (1986–2002 г):
51 ИНФОРМАЦИОННАЯ ГРАМОТНОСТЬ
1 ИНФОРМАЦИОННАЯ ГРАНИЦА ВСЕЛЕННОЙ
1 ИНФОРМАЦИОННАЯ ДЕМОКРАТИЯ
Стоп–словарь (словарь отрицаний).Словарь отрицаний («стоп–слов») содержит термины, которые признаны не информативными для данной предметной области. Использование их запрещается для индексирования содержания документов. Например, термины «исследование», «вопросы», «требования», «проблемы» и др. являются политематическими и удаляются из поисковых образов документов и запросов. Словарь стоп–слов может использоваться как при построении частотных словарей, так и при разборе выражения информационной потребности на ИПЯ. Запрещенные термины не заносятся в словарь. Таким образом, неинформативные термины автоматически исключаются из поискового процесса.
|
из
5.00
|
Обсуждение в статье: Лингвистическое обеспечение КИС |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы