1. а).Задано множество пар значений {(xt,yt)}, t= (n=41), представляющих собой результаты измерений функции. Дан прибор, который генерирует функцию y(x)=ax+b. На вход поступает сигнал x1,x2,..,xn; на выходе: y1,y2,…,yn.
Числа не соответствуют внутренним числам, так как прибор имеет шумы
yt=axt+b +εt, t= ,
где a,b – неизвестные коэффициенты, а εt – независимые в совокупности случайные величины с нормальным законом распределения: εt~N(0,σ2), где σ2 неизвестная дисперсия; 0 – математическое ожидание шума εt. М εt=0, D εt= σ2.
Требуется найти методом наименьших квадратов неизвестные параметры кривой регрессии.
y(x)=ax+b – кривая регрессии – условное матожидание случайной величины Y при аргументе x, М(y/x).
б). Построить график линии регрессии ỹ(x).
2. Найти точечную оценку для неизвестного параметра неизвестной дисперсии σ2 , которая входит в нормальный закон распределения.
3. Построить интервальные оценки для неизвестных коэффициентов a,b и дисперсии σ2 на уровне доверия j1=0,9; j2=0,95.
4. С помощью критерия Снедекера-Фишера проверить гипотезу Ho: a=0 и гипотезу Ho: b=0 на уровне доверия j1=0,9 и j2=0,95.
Теоретическая часть
Выборка.
Математическая статистика – наука о математических методах, позволяющих по статистическим данным, например по реализациям случайной величины (СВ), построить теоретико-вероятностную модель исследуемого явления. Задачи математической статистики являются, в некотором смысле, обратными к задачам теории вероятностей. Центральным понятием математической статистики является выборка.
Определение 1. Однородной выборкой (выборкой) объема n при n 1 называется случайный вектор Zn=col(X1,…,Xn), компоненты которого Xi, i= , называемые элементами выборки, являются независимыми СВ с одной и той же функцией распределения F(x). Будем говорить, что выборка Zn соответствует функции распределения F(x).
Числа, данные, полученные после опыта – апостериорная выборка.
Определение 2. Реализацией выборки называется неслучайный вектор zn=col(x1,…,xn), компонентами которого являются реализации соответствующих элементов выборки Xi, i= .
Из этих определений вытекает, что реализацию выборки zn можно также рассматривать как последовательность x1,…,xn из n реализаций одной и той же СВ X, полученных в серии из n независимых одинаковых опытов, проводимых в одинаковых условиях. Поэтому можно говорить, что выборка Zn порождена наблюдаемой СВ X, имеющей распределение Fx(x)=F(x).
Определение 3. Если компоненты вектора Zn независимы, но их распределения F1(x1),…,Fn(xn) различны, то такую выборку называют неоднородной.
Определение 4. Множество S всех реализаций выборки Zn называется выборочным пространством.
Выборочное пространство может быть всем n-мерным евклидовым пространством Irn или его частью, если СВ X непрерывна, а также может состоять из конечног или счетного числа точек из Irn, если СВ X дискретна.
На практике при исследовании конкретного эксперимента распределения F1(x1),…,Fn(xn) СВ X1,…,Xn редко бывают известны полностью. Часто априори (до опыта) можно лишь утверждать, что распределение FZn(zn)=F1(x1),…Fn(xn) случайного вектора Zn принадлежит некоторому классу (семейству) F.
Определение 5. Пара (S,F) называется статистической моделью описания серии опытов, порождающих выборку Zn.
Определение 6. Если распределение FZn(zn,Ө) из класса F определены с точностью до некоторого векторного параметра Ө Θ IRs, то такая статистическая модель называется параметрической и обозначается (SӨ, FZn( zn, Ө)), Ө Θ IRs.
В некоторых случаях выборочное пространство может не зависеть от неизвестного параметра Ө распределения FZn(zn,Ө).
В зависимости от вида статистической модели в математической статистике формулируются соответствующие задачи по обработке информации, содержащейся в выборке.
Определение 7. СВ Z=φ(Zn), где φ(Zn) – произвольная функция, определенная на выборочном пространстве S и не зависящая от распределения FZn(zn,Ө), называется статистикой.
Точечные оценки.
Определение 2.1. Параметром распределения Ө Θ IR1 СВ X называется любая числовая характеристика этой СВ ( математическое ожидание, дисперсия и т.п.) или любая константа, явно входящая в выражение для функции распределения.
В общем случае будем предполагать, что параметр распределения Ө может быть векторным, т.е. Ө Θ IRs.
В случае параметрической статистической модели (SӨ, FZn( zn,Ө)) таким параметром распределения может служить неизвестный вектор Ө Θ IRs, характеризующий распределение FZn( zn,Ө).
Пусть имеется выборка Zn=col(X1,…Xn) с реализацией zn=(x1,…xn).
Определение 2.2. Точечной (выборочной) оценкой неизвестного параметра распределения Ө Θ IRs называется произвольная статистика (Zn), построенная по выборке Zn и принимающая значения в множестве Θ.
Замечание 2.1. Реализацию (zn) оценки (Zn), принимают, как правило, за приближенное значение неизвестного параметра Ө.
Ясно, что существует много разных способов построения точечной оценки которые учитывают тип статистической модели. Для параметрической и не параметрической моделей эти способы могут быть различны. Рассмотрим некоторые свойства, которые характеризуют качество введенной оценки.
Определение 2.3. Оценка (Zn) параметра Ө называется несмещенной, если ее МО равно Ө , т.е. M[ (Zn)]= Ө для любого Ө Θ.
Определение 2.4. Оценка (Zn) параметра Ө называется состоятельной, если она сходится по вероятности к Ө, т.е. (Zn) Ө при n → ∞ для любого Ө Θ.
Определение 2.5. Оценка (Zn) параметра Ө называется сильно состоятельной, если она сходится почти наверное к Ө, т.е. (Zn) Ө при n → ∞ для любого Ө Θ.
Определение 2.6. Несмещенная оценка *(Zn) скалярного параметра Ө называется эффективной, если D[ *(Zn)]≤ D[ (Zn)] для всех несмещенных оценок (Zn) параметра Ө, т.е. ее дисперсия минимальна по сравнению с дисперсиями других несмещенных оценок при одном и том же объеме n выборки Zn.
Вообще говоря, дисперсии несмещенных оценок могут зависеть о параметра Ө. В этом случае под эффективной оценкой понимается такая, для которой вышеприведенное неравенство является строгим хотя бы для одного значения параметра Ө.
Интервальные оценки.
Пусть имеется параметрическая статистическая модель (SӨ, FZn( zn,Ө)), Ө Θ IR1, и по выборке Zn=col(X1,…Xn), соответствующей распределению F( x,Ө), наблюдаемой СВ X, требуется оценить неизвестный параметр Ө. Вместо точечных оценок, рассмотренных ранее, рассмотрим другой тип оценок неизвестного параметра Ө Θ IR1.
Определение 3.1. Интервал [θ1(Zn),θ2(Zn)] со случайными концами, «накрывающий» с вероятностью 1-α, 0<α<1, неизвестный параметр θ, т.е.
P{ θ1(Zn)≤ θ ≤ θ2(Zn)}= 1-α,
называется доверительным интервалом (или интервальной оценкой) уровня надежности 1-α параметра θ.
Аналогично определяется доверительный интервал для произвольной функции от параметра θ.
Определение 3.2. Число δ=1-α называется доверительной вероятностью или уровнем доверия (надежности).
Определение 3.3. Доверительный интервал [θ1(Zn),θ2(Zn)] называется центральным, если выполняются следующие условия:
P{ θ≥ θ2(Zn)}= , P{ θ1(Zn) ≥ θ}= .
Часто вместо двусторонних доверительных интервалов рассматривают односторонние доверительные интервалы, полагая θ1(Zn)= -∞ или θ2(Zn)= +∞.
Определение 3.4. Интервал, границы которого удовлетворяют условию:
P{ θ≥ θ2(Zn)}= α (или P{ θ1(Zn) ≥ θ}= α.),
называется соответственно правосторонним (или левосторонним) доверительным интервалом.
Проверка статистических гипотез.
Определение 4.1. Статистической гипотезой H или просто гипотезой называется любое предположение относительно параметров ли законов распределения СВ X, проверяемое по выборке Zn.
Определение 4.2. Проверяемая гипотеза называется основной (или нулевой) и обозначается Ho. Гипотеза, конкурирующая с Ho, называется альтернативной и обозначается H1,
Определение 4.3. Статистическая гипотеза Ho называется простой, если она однозначно определяет параметр или распределение СВ X. В противном случае гипотеза Ho называется сложной.
Определение 4.4.Статистическим критерием (критерием согласия, критерием значимости или решающим правилом) проверки гипотезы Ho называется правило, в соответствии с которым по реализации z=φ(zn) статистики Z гипотеза Ho принимается или отвергается.
Определение 4.5.Критической областью статистического критерия называют область реализации z статистики Z, при которых гипотеза Ho отвергается.
Определение 4.6. Доверительной областью G статистического критерия называется область значений z статистики Z, при которых гипотеза Ho принимается.
Например, в качестве статистического критерия можно использовать правило:
1. Если значение z= φ(zn) статистики Z= φ(zn) лежит в критической области , то гипотеза Ho отвергается и принимается альтернативная гипотеза H1;
2. Если реализация z= φ(zn) статистики Z= φ(zn) лежит в доверительной области G, то гипотеза Ho принимается.
При реализации этого правила возникают ошибки двух видов.
Определение 4.7. Ошибкой 1-го рода называется событие, состоящее в том, что гипотеза Ho отвергается, когда она верна.
Определение 4.8. Ошибкой 2-го рода называется событие, состоящее в том, что принимается гипотеза Ho, когда верна гипотеза H1.
Определение 4.9. Уровнем значимости статистического критерия называется вероятность ошибки 1-го рода α=P{Z |Ho}, Вероятность ошибки 1-го рода α может быть вычислено, если известно распределение F(z|Ho) статистики Z.
Вероятность ошибки 2-го рода равна β=P{Z G|Ho} и может быть вычислена, если известно условное распределение F(z|H1) статистики Z при справедливости гипотезы H1.
Ясно. Что с уменьшением вероятности α ошибки 1-го рода возрастает вероятность β ошибки 2-го рода, и наоборот, т.е. при выборе критической и доверительной областей должен достигаться определенный компромисс. Поэтому часто при фиксированной вероятности ошибки 1-го рода критическая область выбирается таким образом, чобы вероятность ошибки второго рода была минимальна.
Определение 4.10. Мощность статистического критерия – это вероятность того, что нулевая гипотеза будет отвергнута, если верна конкурирующая гипотеза.
Проверка статистической гипотезы может быть подразделена на следующие этапы:
1. сформулировать проверяемую гипотезу Ho и альтернативную к ней гипотезу H1;
2. выбрать уровень значимости α;
3. выбрать статистику Z для проверки гипотезы Ho;
4. найти распределение F(z|Ho) статистики Z при условии, что гипотеза Ho верна;
5. построить, в зависимости от формулировки гипотезы H1 и уровня значимости α, критическую область ;
6. получить выборку наблюдений x1,..,xn и вычислить выборочное значение z= φ(x1,..,xn) статистики Z критерия;
7. принять статистическое решение на уровне доверия 1-α: если Z , то отклонить гипотезу Ho как не согласующуюся с результатами наблюдений, а если Z G, то принять гипотезу Ho как не противоречащую результатам наблюдений.



 (n=41), представляющих собой результаты измерений функции. Дан прибор, который генерирует функцию y(x)=ax+b. На вход поступает сигнал x1,x2,..,xn; на выходе: y1,y2,…,yn.
(n=41), представляющих собой результаты измерений функции. Дан прибор, который генерирует функцию y(x)=ax+b. На вход поступает сигнал x1,x2,..,xn; на выходе: y1,y2,…,yn. неизвестной дисперсии σ2 , которая входит в нормальный закон распределения.
неизвестной дисперсии σ2 , которая входит в нормальный закон распределения.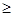 1 называется случайный вектор Zn=col(X1,…,Xn), компоненты которого Xi, i=
1 называется случайный вектор Zn=col(X1,…,Xn), компоненты которого Xi, i=  , называемые элементами выборки, являются независимыми СВ с одной и той же функцией распределения F(x). Будем говорить, что выборка Zn соответствует функции распределения F(x).
, называемые элементами выборки, являются независимыми СВ с одной и той же функцией распределения F(x). Будем говорить, что выборка Zn соответствует функции распределения F(x). .
.  Θ
Θ  IRs, то такая статистическая модель называется параметрической и обозначается (S Ө, FZn( zn, Ө)), Ө
IRs, то такая статистическая модель называется параметрической и обозначается (S Ө, FZn( zn, Ө)), Ө  Θ
Θ  IRs, характеризующий распределение FZn( zn,Ө).
IRs, характеризующий распределение FZn( zn,Ө). Θ
Θ 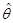 (Zn), построенная по выборке Zn и принимающая значения в множестве Θ.
(Zn), построенная по выборке Zn и принимающая значения в множестве Θ.  Ө при n → ∞ для любого Ө
Ө при n → ∞ для любого Ө  Ө при n → ∞ для любого Ө
Ө при n → ∞ для любого Ө 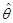 (Zn) параметра Ө, т.е. ее дисперсия минимальна по сравнению с дисперсиями других несмещенных оценок при одном и том же объеме n выборки Zn.
(Zn) параметра Ө, т.е. ее дисперсия минимальна по сравнению с дисперсиями других несмещенных оценок при одном и том же объеме n выборки Zn.  IR1, и по выборке Zn=col(X1,…Xn), соответствующей распределению F( x,Ө), наблюдаемой СВ X, требуется оценить неизвестный параметр Ө. Вместо точечных оценок, рассмотренных ранее, рассмотрим другой тип оценок неизвестного параметра Ө
IR1, и по выборке Zn=col(X1,…Xn), соответствующей распределению F( x,Ө), наблюдаемой СВ X, требуется оценить неизвестный параметр Ө. Вместо точечных оценок, рассмотренных ранее, рассмотрим другой тип оценок неизвестного параметра Ө  , P{ θ1(Zn) ≥ θ}=
, P{ θ1(Zn) ≥ θ}=  статистического критерия называют область реализации z статистики Z, при которых гипотеза Ho отвергается.
статистического критерия называют область реализации z статистики Z, при которых гипотеза Ho отвергается. , то гипотеза Ho отвергается и принимается альтернативная гипотеза H1;
, то гипотеза Ho отвергается и принимается альтернативная гипотеза H1;

 , то отклонить гипотезу Ho как не согласующуюся с результатами наблюдений, а если Z
, то отклонить гипотезу Ho как не согласующуюся с результатами наблюдений, а если Z 