 |
Главная |


Принцип работы, структура ПЛИС, скоростные характеристики, в каких корпусах выпускается, примеры устройств, фирмы реализации, рынок (объем выпуска), тенденции.
|
из
5.00
|
В настоящее время выпускаются следующие серии ПЛИС FPGA:
· Серия Virtex
· Серия Spartan
· Серия ХС4000
· Серия ХС5200
· Серия ХС3000
ПЛИС типа FPGA фирмы Xilinx выполненны по SRAM кМОП технологии. Характеризуются высокой гибкостью структуры и изобилием на кристалле триггеров. При этом логика реализуется посредством так называемых LUT – таблиц (Look Up Table) Xilinx, а внутренние межсоединения – посредством разветвлённой иерархии металлических линий, коммутируемых специальными быстродействующими транзисторами.
Отличительными системными особенностями являются:
· внутренние буфера с возможностью переключения в высокоомное состояние и тем самым позволяющие организовать системные двунаправленные шины
· индивидуальный контроль высокоомного состояния и времени нарастания фронта выходного сигнала по каждому внешнему выводу
· наличие общего сброса/установки всех триггеров ПЛИС
· множество глобальных линий с низкими задержками распространения сигнала
· наличие внутреннего распределённого ОЗУ Xilinx, реализующегося посредством тех же LUT – таблиц (серии Spartan, Virtex, XC4000).
· наличие внутреннего блочного ОЗУ, один блок имеет ёмкость 4 кбит (семейства Virtex, Virtex-E, Spartan-II, Spartan-IIE) или 18 кбит (семейства Virtex-II и Virtex-IIPro), всего блоков до 556 на кристалл
· наличие встроенных блоков умножителей 18х18 (семейства Virtex-II и Virtex-IIPro), всего блоков до 556 на кристалл
· наличие встроенных блоков процессоров PowerPC-405 (семейство Virtex-IIPro), до 4 процессоров на кристалл
· наличие высокоскоростных трансиверов(семейство Virtex-IIPro), до 24 со скоростью передачи данных 3.125 ГБит/с каждый
Процесс конфигурации
Конфигурационная последовательность (bitstream) может быть загружена в прибор непосредственно в системе и перегружена неограниченное число раз. Инициализация ПЛИС производится автоматически (из загрузочного ПЗУ Xilinx) при подаче напряжения питания или принудительно по специальному сигналу. В зависимости от ёмкости ПЛИС процесс инициализации занимает от 20 до 900 мс, в течение которых выводы ПЛИС находятся в высокоомном состоянии (подтянуты к логической единице).
Потребление энергии
Статическое потребление энергии достаточно мало и для некоторых серий составляет единицы микроватт. Динамическое же потребление пропорционально возрастает с частотой функционирования проекта и зависит от степени заполнения кристалла, характера логической структуры проекта на кристалле, параметров режима внешних выводов ПЛИС и т. д.
Корпуса
Для каждого отдельно взятого семейства ПЛИС Xilinx существует преемственность кристаллов по типу корпуса и, соответственно, цоколёвке, то есть в одни и те же корпуса упаковываются ПЛИС различного логического объёма. Например, в корпусе PQ/HQ240 имеются ПЛИС с ёмкостью от 13тыс. (XC4013XLA) до 85 тыс. вентилей (XC4085XLA), что позволяет разработчику, задавшись на этапе проектирования печатной платы определённым типом корпуса, в дальнейшем устанавливать ПЛИС наиболее подходящего размера.
ПЛИС Actel – основа при реализации «SoC» бортовой аппаратуры
Сегодня в России, как и во всем мире, подходы к созданию электронных устройств и систем, работающих в тяжелых условиях эксплуатации, существенно меняются. Основная тенденция – переориентация на специализированные изделия с сокращенным циклом проектирования и производства, что позволяет достигать максимальной эффективности при выполнении конкретных задач управления, контроля и сбора информации.
На передний план выходит концепция построения «системы на кристалле» (System on Chip – SoC). Наиболее серьёзное препятствие для ее реализации – это, безусловно, высокая стоимость изготовления СБИС такого типа. Их разработка, отладка и освоение производства требуют значительных затрат, поэтому ощутимый экономический эффект можно получить только при выпуске больших партий этих изделий – как правило в сотни тысяч устройств. Однако сегодня для построения «системы на кристалле» появилась экономически эффективная альтернатива СБИС – программируемые логические интегральные схемы (ПЛИС). Новые поколения этих микросхем способны конкурировать со СБИС как по числу вентилей, быстродействию и надежности, так и по функциональности. Более того, сейчас на рынок выпущены матрицы, не требующие внешних средств для хранения и загрузки конфигурации и готовые к работе с момента подачи питания, что до сих пор считалось исключительным преимуществом СБИС.
Внедрение концепции «системы на кристалле» признано одним из приоритетных направлений развития отечественной электроники, определяющим, по сути, технологию построения будущих поколений бортовой аппаратуры. «Система на кристалле» имеет три принципиальные особенности: o в одной микросхеме технологической платформы (как правило, СБИС или ПЛИС сверхвысокой степени интеграции) реализован функционально законченный набор модулей управления и обработки данных;
- встроенный микропроцессор ориентирован преимущественно на выполнение задач управления, а не обработки данных;
- поток данных в системе организован непосредственно между контроллерами, а не через микропроцессорную шину.
Среди основных достоинств правильно спроектированной «системы на кристалле» следует выделить максимальную эффективность в решении прикладных задач. Это обусловлено глубокой оптимизацией внутренней структуры и отсутствием избыточности, характерной для систем, построенных на основе универсальных компонентов. А высокая оптимизация определяет высокую экономическую эффективность подобных решений как за счет прямой экономии (снижение числа компонент на плате, уменьшение площади печатной платы и пр.), так и за счет косвенной экономии (меньшего энергопотребления, повышения надежности, производительности, уменьшения объема аппаратной отладки и пр.).
Реализованная на базе высоконадежной и высокоскоростной ПЛИС «система на кристалле» помимо всех достоинств, присущих решениям на основе СБИС, имеет важные дополнительные преимущества:
- значительное сокращение расходов на изготовление микросхем и экономический эффект при реализации проектов малой и средней серийности (до десятков тысяч штук);
- существенное сокращение сроков выпуска новых изделий на рынок (time to market);
- гибкая конфигурируемость системы в соответствии с текущими нуждами конкретного проекта и задачами упрощения модификации; – повышенная надежность изделия благодаря 100%-ному тестированию производителем регулярной структуры платформы;
- возможность высокоэффективной внутрикристальной отладки;
- возможность прототипирования изделий для особых условий эксплуатации на основе функционально идентичных, но более дешевых коммерческих исполнений платформы.
Один из самых успешных разработчиков и производителей в области новых технологий ПЛИС высокой надежности, используемых в тяжелых условиях эксплуатации, – Actel Corp. (www.actel.ru), специализирующаяся с 1985 года на производстве ПЛИС как для военных и авиационно-космических приложений, так и для нужд промышленности и потребительского рынка. Компания прочно занимает место в первой тройке мировых производителей ПЛИС общего назначения и уже много лет лидирует на рынке радиационно стойких ПЛИС, выпуская до 80% мирового объема этих изделий для бортового оборудования космических аппаратов. Actel непрерывно вкладывает значительные средства в совершенствование своих технологий. Наивысшие приоритеты развития сегодня – это надежность, которая всегда отличала продукцию корпорации, и обеспечение комплексной интеграции цифровой электроники на одном кристалле ПЛИС.
Сегодня Actel предлагает три основные группы изделий:
- многократно программируемые ПЛИС на основе Flash-технологии;
- однократно программируемые ПЛИС на основе технологии прожигаемых перемычек (Antifuse);
- радиационно стойкие ПЛИС с уникальными характеристиками на основе технологии Antifuse.
Как однократно, так и многократно программируемые ПЛИС компании Actel последних поколений благодаря своей уникальной архитектуре и функциональности, приближенной к СБИС, а также высоким показателям надежности идеально подходят для построения «систем на кристалле».
Основное отличие ПЛИС компании от традиционных матриц на основе ячеек СОЗУ – это способ хранения конфигурации. Элементы памяти (перемычки в семействах Antifuse и флэш-ключи в семействах Flash) ПЛИС Actel распределены по всей площади кристалла и являются одновременно ключами, задающими конфигурацию. Такое технологическое решение позволяет избавиться от потенциально ненадежной коммутационной матрицы (ГКМ) на основе ячеек СОЗУ, не защищенных от высокоэнергетических частиц, воздействующих на электронные устройства даже на уровне моря, а также отказаться от всех элементов, участвующих в процессе загрузки конфигурации. На сегодняшний день аналогов этой технологии нет.
Рассмотрим современные семейства ПЛИС, предлагаемые компанией Actel. Новые семейства однократно программируемых ПЛИС, выполненных по технологии Antifuse, характеризуются следующими особенностями:
- рекордной надежностью – FIT, или число отказов/сбоев на 109 ч наработки не более 10;
- чрезвычайно низким энергопотреблением;
- большой логической емкостью – до 4 млн. системных вентилей;
- рекордной системной производительностью – свыше 500 МГц;
- отсутствием процесса загрузки конфигурации и готовностью к работе с момента подачи питания;
- защищенностью от воздействия высокоэнергетических частиц (даже у коммерческих изделий) – свыше 60 МэВ/см2 и высокой радиационной стойкостью – накопленная доза (TID) более 300 крад;
- отсутствием возможности несанкционированного считывания конфигурации – конфигурация защищена технологией FuseLock, при запуске нет конфигурационной последовательности (bit-stream);
- доступом специализированного логического анализатора к любому элементу работающей схемы без затрат трассировочных ресурсов самой ПЛИС;
- широким выбором поддерживаемых стандартов ввода-вывода -LVDS, HSTL1, SSTL2/3, GTL+, LVTTL, LVCMOS, LVPECL;
- полной совместимостью по корпусам изделий различной емкости и в различном исполнении: от коммерческих до выполненных в соответствии со стандартом MIL-STO-883B и радиационно стойких;
- высокой экономической эффективностью.
ПЛИС, выполненные по технологии Antifuse, объединяют в себе достоинства традиционной программируемой логики и базовых матричных кристаллов (БМК) и позволяют потребителю производить БМК непосредственно «у себя на столе». Но неопытных разработчиков иногда отпугивают трудности применения однократно программируемых матриц, которые невозможно проектировать по популярному циклическому маршруту «написал-прошил-посмотрел». Для подобного стиля работы Actel предлагает многократно программируемые матрицы. При этом следует отметить, что все изделия Actel изначально ориентированы на применение классического маршрута проектирования СБИС на языках описания оборудования высокого уровня (HDL).
Выпускаемые компанией Actel многократно программируемые матрицы на основе Flash-технологии имеют следующие достоинства:
- возможность перепрограммирования непосредственно в системе (ISP);
- логическая емкость до 1 млн. системных вентилей;
- малое энергопотребление;
- высокая системная производительность – до 350 МГц;
- готовность к работе с момента подачи питания – отсутствует процесс загрузки конфигурации;
- высокая радиационная стойкость – накопленная доза до 100 крад и устойчивость к воздействию высокоэнертегических частиц свыше 60 МэВ/см2 (для микросхем в исполнении MIL-STD-883B);
- отсутствие возможности несанкционированного считывания конфигурации – конфигурация защищается технологией FlashLock, конфигурационная последовательность при запуске отсутствует;
- богатый выбор поддерживаемых стандартов ввода-вывода;
- полная совместимость по корпусам изделий различной емкости и в различном исполнении.
К выпуску готовится новое поколение многократно программируемых ПЛИС емкостью до 3 млн. системных вентилей с улучшенной архитектурой ячейки, расширенным набором интерфейсов ввода-вывода и с блоками флэш-памяти для хранения программ или данных микропроцессоров, встроенных в «систему на кристалле».
Современный маршрут проектирования интегральных систем состоит из трех основных этапов: ввода (описания) проекта, его синтеза в выбранном базисе и, наконец, трассировки и размещения на кристалле. Неотъемлемая часть маршрута проектирования – комплексная верификация дизайна с помощью средств симуляции после каждого из основных его этапов: до синтеза, после синтеза и после размещения на кристалле. Если спецификация проекта (включая построение testbench) разработана с должным качеством и последовательно реализована в RTL, можно практически полностью выявить и устранить ошибки дизайна еще до программирования кристалла. Такой подход, конечно, выдвигает высокие требования к организации проектной группы и самодисциплины всех ее инженеров и менеджеров. Однако результаты работы, выраженные в качестве конечного изделия, безусловно, окупают организационные затраты. Поскольку проекты разработки «систем на кристалле» по своей сложности значительно превосходят «обычные» проекты создания связующих логических схем на ПЛИС, роль средств управления группой разработчиков становится не менее важной, чем роль комплексов программных средств разработки ПЛИС и СБИС (EDA), например FPGA Advantage фирмы Mentor Graphics.
Коротко рассмотрим основные требования к организации проектного менеджмента при создании систем на кристалле. Современная система управления разработкой, построенная в соответствии с требованиями международных стандартов качества ISO, должна пердусматривать проведение проектных форумов для обсуждения технических деталей проекта в режиме реального времени. Кроме того, в нее должны входить подсистемы отладки проектов (issue tracking), хранения исходных данных проекта (knowledge base), контроля версий (version control) и планирования для прогноза сроков выполнения этапов проекта и оперативной корректировки планов. При этом значительно возрастают требования к руководителю проекта, который должен оперативно управлять работой группы в реальном времени.
Одна из компаний, успешно разрабатывающих системные решения на основе новых поколений ПЛИС высокой интеграции фирмы Actel, – петербургское СКБ Интегральных Систем (www.asicdesign.ru), имеющее статус официального технического центра Actel в России.
На платформе ПЛИС ProASICplus в СКВ ИС создан комплекс программно-аппаратных решений СнК186 для построения бортовых регистраторов высокоскоростных данных.
Структура устройства, представляющего собой бортовой управляющий вычислительный комплекс (БУВК) автономного робота с подсистемой сбора и хранения потоковых данных (160 Мбит/с), реализована на одной печатной плате с «системой на кристалле» на основе ПЛИС APA750-PQ208I емкостью 750 тыс. системных вентилей. В состав системы входят: процессорное ядро Турбо186, контроллер USB 2.0 с производительностью 480 Мбит/с, контроллер IDE ATA5 для внешнего накопителя, контроллер телеметрической информации и аппаратный компрессор данных «без потерь». Плата с потреблением около 1 Вт и габаритами 100×200 мм позволила заменить громоздкий бортовой промышленный компьютер, существенно улучшив эксплуатационные характеристики и параметр FIT системы в целом. Очевидно, что подобные решения находят применение в большом числе бортовых приложений в самых различных областях, где важны габариты и энергопотребление устройства, а к надежности системы предъявляются повышенные требования. Благодаря широкому применению технологии «система на кристалле» на основе оптимальной платформы ПЛИС такие решения позволят выйти на новый технологический уровень и будут способствовать модернизации промышленности.
КЛАССИФИКАЦИЯ ПЛИС
Микросхемы, программируемые пользователями, открыли новую страницу в истории современной микроэлектроники и вычислительной техники. Они сделали БИС/СБИС, предназначенные для решения специализированных задач, стандартной продукцией электронной промышленности со всеми вытекающими из этого положительными следствиями: массовое производство, снижение стоимости микросхем, сроков разработки и выхода на рынок продукции на их основе. ПЛИС можно классифицировать по многим признакам, в первую очередь:
- по уровню интеграции и связанной с ним логической сложности;
- по архитектуре (типу функциональных блоков, характеру системы межсоединений);
- по числу допустимых циклов программирования;
- по типу памяти конфигурации («теневой»памяти);
- по степени зависимости задержек сигналов от путей их распространения;
- по системным свойствам;
- по схемотехнологии (КМОП, ТТЛШ и др.);
- по однородности или гибридности (по признаку наличия или отсутствия в микросхеме областей с различными по методам проектирования схемами, такими как ПЛИС, БМК, схемы на стандартных ячейках).
Все перечисленные признаки имеют значение и отображают ту или иную сторону возможных классификаций. Выделяя основные признаки и укрупняя их, рассмотрим классификацию по трем, в том числе двум комплексным, признакам:
- по архитектуре;
- по уровню интеграции и однородности/гибридности;
- по числу допустимых циклов программирования и связанному с этим типу памяти конфигурации.
В классификации по первому признаку (рис. 2, а) ПЛИС разделены на 4 класса.
Первый из классов — SPLD, Simple Programmable Logic Devices, т. е. простые программируемые логические устройства. По архитектуре эти ПЛИС делятся на подклассы программируемых логических матриц ПЛМ (PLA, Programmable Logic Arrays) и программируемой матричной логики ПМЛ (PAL, Programmable Arrays Logic, или GAL, Generic Array Logic).
Оба эти подкласса микросхем реализуют дизъюнктивные нормальные формы (ДНФ) переключательных функций, а их основными блоками являются две матрицы: матрица элементов И и матрица элементов ИЛИ, включенные последовательно. Такова структурная модель ПЛМ и ПМЛ. Технически они могут быть выполнены и как последовательность двух матриц элементов ИЛИ-НЕ, но варианты с последовательностью матриц И-ИЛИ и с последовательностью матриц ИЛИ-НЕ — ИЛИ-НЕ функционально эквивалентны, т. к. второй вариант согласно правилу де Моргана тоже реализует ДНФ, но для инверсных значений переменных.
На входы первой матрицы поступают n входных переменных в виде как прямых, так и инверсных значений, так что матрица имеет 2n входных линий. Таким образом, отпадает необходимость специально инвертировать входные переменные и на промежуточных шинах можно реализовать любую конъюнкцию входных переменных и их инверсий, а также переменных обратных связей. На выходах матрицы И формируются конъюнктивные термы, ранг которых не выше n. В дальнейшем для краткости конъюнктивные термы называются просто термами.

Рис.2. Классификация ПЛИС (а – по архитектуре, б – по уровню интеграции)
Выработанные термы поступают на вход матрицы ИЛИ. Эти матрицы для ПЛМ и ПМЛ различны. В ПЛМ матрица ИЛИ программируется, а в ПМЛ она фиксирована.
Программируемая матрица ИЛИ микросхем ПЛМ составлена из дизъюнкторов, имеющих по q входов. На входы каждого дизъюнктора при программировании можно подать любую комбинацию имеющихся термов, причем термы можно использовать многократно (т. е. один и тот же терм может быть использован для подачи на входы нескольких дизъюнкторов).
Число дизъюнкторов в матрице ИЛИ определяет число выходов ПЛМ. Из изложенного видно, что ПЛМ позволяет реализовать систему из m переключательных функций, зависящих не более чем от n переменных и содержащих не более чем q термов.
В ПМЛ выработанные матрицей И термы поступают на фиксированную (непрограммируемую) матрицу элементов ИЛИ. Это означает жесткое заранее заданное распределение имеющихся термов между отдельными дизъюнкторами.
ПЛМ обладают большей функциональной гибкостью, все воспроизводимые ими функции могут быть комбинациями любого числа термов, формируемых матрицей И. Это полезно при реализации систем переключательных функций, имеющих большие взаимные пересечения по термам. Такие системы свойственны, например, задачам формирования сигналов управления машинными циклами процессоров. Для широко распространенных в практике задач построения «произвольной логики» большое пересечение функций по термам не типично. Для них программируемость матрицы ИЛИ используется мало и становится излишней роскошью, неоправданно усложняющей микросхему. Поэтому микросхемы ПМЛ распространены больше, чем ПЛМ, и к их числу относится большинство SPLD. Обобщённая структура «классической» ПМЛ представлена на рис.3.

Рис.3. Обобщённая структура «классической» ПМЛ
«Классические» ПМЛ также позволяют программировать высокоимпедансное (третье) состояние выходного буфера, что делает возможным двунаправленный вывод использовать как вход. Кроме того, индивидуальное управление с помощью отдельного терма третьим состоянием выходного буфера позволяет двунаправленный вывод в один момент времени использовать как выход, а в другой момент – как вход или отключать от внешней шины, например, для уменьшения нагрузки.
Возможность ПМЛ передачи значения выходного сигнала по цепи обратной связи на вход матрицы И позволяет в одном устройстве строить многоуровневые каскадные схемы. Однако следует избегать случаев, когда значение некоторой функции является аргументом этой же функции, так как в подобной ситуации схема перестаёт быть комбинационной и переходит в класс последовательностных схем, а отсутствие в циклах элементов задержки приводит к непредсказуемости поведения схемы.
Обобщенная структура универсальных ПМЛ (рис.4.) включает n входов, программируемую матрицу И, m выходных макроячеек (MC) с одной обратной связью и m2 макроячеек (MCF) с двумя обратными связями. Архитектура макроячейки с двумя обратными связями показана на рис. 5.
В макроячейках с одной обратной связью отсутствует цепь от входа выходного буфера к входу матрицы И. С каждой макроячейкой универсальных ПМЛ связано различное число промежуточных шин, что позволяет более рационально их использовать: простые функции назначать для реализации на выходы, связанные с небольшим числом промежуточных шин, а сложные – назначать на выходы, связанные с большим числом промежуточных шин. Кроме того, каждая макроячейка допускает программирование логического уровня выходного сигнала благодаря наличию в архитектуре макроячейки вентиля Исключающее ИЛИ с программируемой связью одного входа с «землёй».
Поэтому из двух функций yi или ¯yi для реализации можно выбрать наиболее подходящую (например, которая требует для реализации меньше промежуточных шин), а необходимый вид функции на выходе ПМЛ образуется путём программирования логического уровня выходного сигнала.
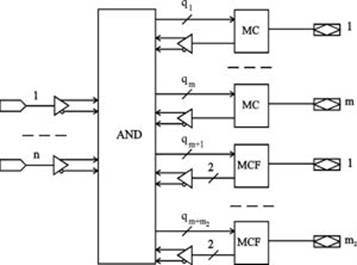
Рис. 4. Обобщённая структура универсальных ПМЛ
Макроячейки с двумя обратными связями допускают одновременное использование в двух целях: для реализации промежуточных функций и для приёма входных переменных.

Рис. 5. Обобщённая структура выходной макроячейки универсальных ПМЛ с двумя обратными связями
Cложные программируемые логические схемы CPLD (Complex Programmable Logic Devices) (сложные программируемые логические устройства) содержат относительно крупные программируемые логические блоки — макроячейки соединённые с внешними выводами и внутренними шинами. Функциональность CPLD кодируется в энергонезависимой памяти, поэтому нет необходимости их перепрограммировать при включении.
Несколько блоков, подобных ПМЛ, объединяются средствами программируемой коммутационной матрицы (рис.6.). В CPLD могут входить сотни блоков и десятки и сотни тысяч эквивалентных вентилей. Архитектуры CPLD разрабатываются фирмами Altera, Atmel, Lattice Semiconductor, Cypress Semiconductor, Xilinx и др. Воздействуя на программируемые соединения коммутационной матрицы и ПМЛ, входящих в состав CPLD, можно реализовать требуемую схему.
Архитектура функциональных блоков здесь во многом подобна архитектуре универсальных ПМЛ. Отличия заключаются в том, что все выходные макроячейки имеют две обратные связи, а промежуточные шины макроячейкам назначаются с помощью распределителя (allocator). Некоторые макроячейки CPLD не имеют связи с внешним выводом. Такие макроячейки называются скрытыми. Скрытые макроячейки имеют только одну обратную связь.
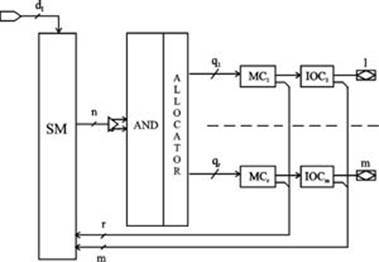
Рис. 6. Обобщённая структура функционального блока CPLD и его взаимодействие с матрицей переключений
Каждый функциональный блок CPLD будем характеризовать числом входов n; выходных макроячеек m; общим числом макроячеек r, из которых r-m являются скрытыми; суммарным числом промежуточных шин функционального блока q и максимальным числом промежуточных шин qmax, которые могут быть подсоединены к одной макроячейке. Кроме того, общая структура CPLD характеризуется числом E функциональных блоков и числом dI «чистых» входов.
Отметим некоторые особенности синтеза комбинационных схем на CPLD, обусловленные их архитектурными свойствами:
· число подсоединяемых к макроячейке промежуточных шин не фиксировано, как для ПМЛ, а определяется для каждой макроячейки индивидуально;
· в некоторых CPLD промежуточные шины между макроячейками распределяются кластерами и для реализации любой функции (даже очень простой) необходимо не менее qCL промежуточных шин, где qCL – число промежуточных шин в одном кластере;
· для реализации промежуточных функций могут использоваться ресурсы скрытых макроячеек, а также выходных макроячеек, выводы которых используются в качестве входов;
· каждый функциональный блок имеет фиксированное число входов n, по которым могут поступать значения аргументов (в ПМЛ число входов может изменяться за счёт использования двунаправленных выводов в качестве входов);
· общее число аргументов СБФ, реализуемой на CPLD, может быть достаточно большим (dI + m·E – N), в то время как число аргументов СБФ, реализуемой одним функциональным блоком, ограничено параметром n, имеющим значение от 16 до 36;
· все значения аргументов и промежуточных функций поступают на входы функциональных блоков только через матрицу переключений, поэтому при частом дублировании входных переменных различных функциональных блоков возникает опасность быстрого истощения ресурсов матрицы переключений.
В качестве примера можно рассмотреть архитектуру микросхем семейства MAX 7000 фирмы Altera [5].
Архитектура MAX 7000 включает следующие элементы:
· логические блоки (LAB, Logic array blocks)
· макроячейки (МЯ, Macrocells)
· логические расширители, разделяемый и параллельный (Expander product terms)
· программируемая матрица соединений (PIA, Programmable interconnect array)
· блоки управления вводом/выводом (БВВ, I/O control blocks)
В структуру ПЛИС MAX 7000 входят четыре специализированных входа. Эти входы могут быть использованы как входы общего назначения для обработки “быстрых” сигналов. Через эти входы на каждую МЯ могут быть поданы глобальные управляющие сигналы (синхронизация, сброс, переход в третье состояние). На рис.7 представлена функциональная схема ПЛИС.
Архитектура ПЛИС MAX 7000 основана на логических блоках, состоящих из 16 макроячеек. Логические блоки соединяются вместе при помощи программируемой матрицы соединений (PIA).

Рис.7 Функциональная схема ПЛИС MAX 7000
К каждому логическому блоку подводятся следующие сигналы:
· 36 сигналов от PIA, используемых в качестве логических входов;
· глобальные управляющие сигналы;
· непосредственные цепи от входных буферов к регистрам, обеспечивающие высокое быстродействие.
Макроячейка содержит три функциональных блока:
· локальная программируемая матрица (Logic Array);
· матрица распределения термов (Product Term Select Matrix);
· программируемый регистр (Programmable register).
На рис.8 приведена структурная схема МЯ. Комбинационная логика реализуется на локальной программируемой матрице, которая передает пять основных термов в матрицу распределения термов. Матрица распределения термов позволяет реализовать комбинационную функцию путем выполнения операций “исключающее или”, “ИЛИ” над логическими произведениями. Кроме этого, матрица распределения может передать термы на регистры.
Для расширения функциональных возможностей доступны две логические схемы:
· разделяемый логический расширитель. Инвертирует терм и передает назад на локальную программируемую матрицу;
· параллельный логический расширитель. Передает термы из предыдущих МЯ в последующие.

Рис.8 Структурная схема макроячейки.
Комбинационная логика реализуется на локальной программируемой матрице, которая передает пять основных термов в матрицу распределения термов. Матрица распределения термов позволяет реализовать комбинационную функцию путем выполнения операций “исключающее или”, “ИЛИ” над логическими произведениями. Кроме этого, матрица распределения может передать термы на регистры.
САПР фирмы Altera способны автоматически оптимизировать процесс распределения термов в соответствии с требованиями проекта.
Для каждого регистра может быть выбран один из трех способов тактирования:
· тактирование глобальным синхросигналом. Это самый быстрый вариант;
· тактирование глобальным сигналом с применением локального сигнала разрешения тактирования;
· тактирование сигналом от локальной программируемой матрицы.
В MAX7000доступны два глобальных тактовых сигнала выводы GCLK1 или GCLK2.
Для каждого регистра имеется возможность асинхронного сброса и установки. Матрица распределения термов обеспечивает управление этими операциями. Возможно индивидуальное управление сбросом каждого регистра при помощи глобального тактирующего сигнала GCLRn.
Хотя большинство логических функций могут быть реализованы пятью термами, доступными в каждой МЯ. Возможна ситуация, при которой пяти переменных будет недостаточно. Для решения подобной проблемы предназначен специальный механизм – логические расширители. Этот механизм позволяет использовать термы любых МЯ, находящихся в данном логическом блоке. Логические расширители помогают добиться максимального быстродействия при минимальных затратах.
Каждый логический блок содержит 16 разделяемых расширителей, которые могут быть рассмотрены как емкость неподключенных термов (один от каждой макроячейки). Терм инвертируется и возвращается обратно в локальную программируемую матрицу. Инвертированный терм может использоваться любой МЯ данного логического блока. Временная задержка, вызванная использованием расширителя обозначается TSEXP.
Схема расширителя изображена на рис.9:
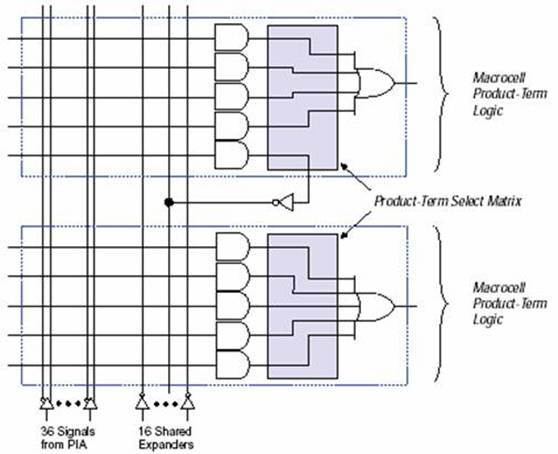
Рис.9 Разделяемый расширитель
Расширитель реализует логические функции, состоящие из термов соседних МЯ. Таким образом, МЯ связываются в цепочку. Расширитель позволяет использовать до 20 термов. Пять термов берутся непосредственно из данной МЯ, остальные 15 из соседних МЯ данного логического блока. Дополнительная временная задержка, вносимая расширителем, обозначается tPEXP. Последовательно в цепочку можно соединить до 8 МЯ. Схема параллельного логического расширителя представлена на рис.10.

Рис.10 Параллельный расширитель
Программируемая матрица соединений (PIA) реализует все внутренние связи. С этой шиной соединены все источники и приемники сигналов. Все специальные сигналы, выводы ввода/вывода, сигналы МЯ. На рис.11 показано как сигналы PIA подводятся к логическим блокам (LAB).

Рис.11 Схема передачи сигналов из программируемой матрицы соединений в логические блоки.
Блок управления вводом/выводом позволяет индивидуально конфигурировать каждый вывод ПЛИС. Вывод ПЛИС может быть настроен на ввод, вывод, двунаправленную передачу данных. Все выводы ПЛИС могут быть выводами буфера с третьим состоянием, который может управляться глобальным сигналом. Кроме того, возможен режим работы с открытым коллектором. На рис.6 показана схема блока управления.

Рис.12 Блок управления вводом/выводом
ПЛИС семейства MAX 7000 соответствуют промышленному стандарту 4-pin Joint Test Action Group (JTAG) IEEE Std. 1149.1-1990). Программирование в системе. (In-System Programmability ISP) быстро и эффективно позволяет изменять конфигурацию ПЛИС как в стадии тестирования проекта, как и в течение эксплуатации. Перепрограммирование может быть выполнено непосредственно в системе, для этого необходим только один уровень напряжения 5В. Пока идет программирование, выводы микросхемы переводятся в третье состояние, для избежания конфликта с системой. Сопротивление внутренних “подтягивающих” резисторов 50 кОм.
Для программирования используется специальный загрузочный кабель Altera MasterBlaster, ByteBlaster или ByteBlasterMV. Программирование ПЛИС в системе позволяет снизить вероятность повреждения при эксплуатации устройства. Кроме того, модернизация устройства может быть выполнена в полевых условиях, например, с помощью модема.
Для программирования ПЛИС во встраиваемых приложениях может быть использован Jam Standard Test and Programming Language (STAPL).
ПЛИС MAX 7000 могут работать в режиме энергосбережения. Этот режим позволяет сократить энергозатраты на 50% и более. Большинство логических функций не используют значительную часть вентилей – этот факт используется для реализации данного режима.
Разработчик может для каждой МЯ выбрать режим высокого быстродействия или энергосбережения (устанавливается или снимается TurboBit). МЯ, работающие в режиме экономии электроэнергии, характеризуются дополнительной временной задержкой tLPA, задержка добавляется к параметрам tLAD, tLAC, tIC, tEN, tSEXP, tACL, tCPPW.
Большинство ПЛИС семейства MAX 7000 поддерживают интерфейс MultiVolt I/O, который обеспечивает работу микросхемы в устройствах с разным уровнем питания. На выводы VCCINT всегда должно быть подано напряжение 5В. При уровне напряжения на выводе VCCINT 5В порог входного напряжения соответствует уровню 5В, однако совместим и с логикой 3,3 В.
На выводы VCCIO может быть подано напряжение питания 3,3В или 5В, в зависимости от требований к выходному каскаду. Когда на выводы VCCIO подано напряжение 5В, уровень выходного каскада соответствует системам 5В. Если подано 3,3В, выходной сигнал соответствует логике 3,3 В, однако совместим и с 5В.
Выводы ПЛИС MAX 7000 могут быть настроены как выводы с открытым коллектором.
Для выходных буферов ПЛИС существует возможность регулирования уровня шумов. Низкий уровень шумов может быть достигнут за счет снижения быстродействия. И наоборот, повышение быстродействия приводит к росту уровня шума. Это достигается посредством настроек Slew Rate Control.
Все микросхемы серии MAX 7000 содержат программируемый бит секретности, который контролирует доступ к “зашитым” в микросхему данным. Если этот бит установлен, прошивка не может быть считана. Такой способ обеспечивает высокую степень защищенности проекта, т.к. информация, находящаяся в ячейках EEPROM, не видима. Бит защиты может быть сброшен только при перепрограммировании ПЛИС.
Микросхемы программируемых пользователями вентильных матриц FPGA (Field Programmable Gate Arrays)
Содержат блоки умножения – суммирования (DSP), которые широко применяются при обработке сигналов, а также логические элементы (как правило на базе таблиц перекодировки (таблиц истинности)) и их блоки коммутации. F
|
из
5.00
|
Обсуждение в статье: Принцип работы, структура ПЛИС, скоростные характеристики, в каких корпусах выпускается, примеры устройств, фирмы реализации, рынок (объем выпуска), тенденции. |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы