 |
Главная |


Построение вариационного ряда
|
из
5.00
|
Работа № 2. Выборки и их представление
Основные понятия
Напомним, что такое выборка, вариационный ряд, эмпирическое распределение, группирование, гистограмма, выборочные характеристики и др.
Выборкой х1, ..., х n объема n из совокупности, распределенной по F(х), называется n независимых наблюдений над случайной величиной x с функцией распределения F(x).
Вариационным рядом х(1) £ х(2) £ ... £ х( n) называется выборка, записанная в порядке возрастания ее элементов.
Каждому наблюдению из выборки присвоим вероятность, равную 1/n; получим распределение, которое называют эмпирическим; ему соответствует функция эмпирического распределения
 º
º  =
= 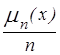 ,
,
где m n(х) - число членов выборки, меньших х. Значение этой функции для статистики определяется тем, что при n ® ¥
® F(x)
(теорема Гливенко).
Выборки больших объемов труднообозримы; разобъем диапазон значений выборки на равные интервалы и подсчитаем для каждого интервала частоту- количество наблюдений, попавших в него; частоты, отнесенные к общему числу наблюдений n, называют относительными частотами; графическое представление распределения частот по интервалам - гистограммой; накопленной частотой для данного интервала называют сумму частот данного интервала и всех тех, что левее его.
Числовые характеристики эмпирического распределения называются выборочными характеристиками: выборочные среднее (математическое ожидание), дисперсия:

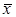 =
= 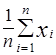 , s2=
, s2= 
выборочный момент порядка к:
m k =  ;
;
выборочные квантили zp порядка р - корни уравнения
F( z p)=p,
которыми являются члены вариационного ряда
z( p)= x([ np]+1),
где [nр] означает целую часть nр; частным случаем (p = 0.5) является выборочная медиана - центральныйчлен вариационного ряда. Значение выборочных характеристик состоит в том, что при n ® ¥ они стремятся к истинным значениям распределения F(х).
Приведем с помощью пакетов примеры. Исходные данные находятся в табл.1 ( E(a) в таблице означает показательное (экспоненциальное) распределение с математическим ожиданием, равным a).
таблица1
| ¹ | Закон | n | a | ¹ | Закон | n | a |
| 1 | R [0, 2] | 50 | 0.03 | 14 | N (1,4) | 60 | 0.01 |
| 2 | N(2, 0.25) | 60 | 0.02 | 15 | E (5) | 70 | 0.03 |
| 3 | E (3) | 70 | 0.01 | 16 | R [0.3] | 80 | 0.1 |
| 4 | R [1, 3] | 80 | 0.02 | 17 | N (1,4) | 50 | 0.3 |
| 5 | N (1, 1) | 50 | 0.01 | 18 | E (1) | 60 | 0.2 |
| 6 | E (2) | 60 | 0.03 | 19 | R [1,3] | 70 | 0.03 |
| 7 | R [2, 3] | 70 | 0.01 | 20 | N (1,1) | 80 | 0.02 |
| 8 | N (0, 4) | 80 | 0.03 | 21 | E (2) | 50 | 0.01 |
| 9 | E (3) | 50 | 0.02 | 22 | R [2,3] | 60 | 0.02 |
| 10 | R [0, 2] | 60 | 0.03 | 23 | N (2,1) | 70 | 0.01 |
| 11 | N [2, 1] | 70 | 0.02 | 24 | E (3) | 80 | 0.03 |
| 12 | E (4) | 80 | 0.01 | 25 | R [1,2] | 50 | 0.01 |
| 13 | R [1, 2] | 50 | 0.02 |
Выполнение в пакете STATGRAPHICS
Генерация выборки
Работа начинается с главного меню пакета (панель STATGRAPHICS Statistical Graphics System) :
|STATGRAPHICS Statistical Graphics System|
DATA MANAGEMENT AND SYSTEM UTILITIES TIME SERIES PROCEDURES
A. Data Management L. Forecasting
B. System Environment M. Quality Control
C. Report Writer and Graphics Replay N. Smoothing
D. Graphics Attributes O. Time Series Analysis
PLOTTING AND DESCRIPTIVE STATISTICS ADVANCED PROCEDURES
E. Plotting Functions P. Categorical Data Analysis
F. Descriptive Methods Q. Multivariate Methods
G. Estimation and Testing R. Nonparametric Methods
H. Distribution Functions S. Sampling
I. Exploratory Data Analysis T. Experimental Design
ANOVA AND REGRESSION ANALYSIS MATHEMATICAL AND USER
PROCEDURES
J. Analysis of Variance U. Mathematical Functions
K. Regression Analysis V. Supplementary Operations
р ис. 1. Главное меню
Выполнение:
H.Distribution functions (законы распределения) — 5. Random Number Generation (генерация случайных чисел) - из списка Distributions available (возможные распределения) выбираем нужное и его номер вводим в окно Distribution number - F6 (исполнение) — вводим параметры распределения и объем выборки Number of samples; исходное состояние датчика случайных чисел (окно seed) оставим без изменения (однако, оно не должно превышать 2147483646) - F6 — вводим имя файла, в котором будем хранить все данные этой работы (в виде различных переменных): File: WORK (например), вводим имя переменной, в которой будет находиться наша выборка: Variable (переменная): x - F6.
Выборка сгенерирована. Посмотрим полученную выборку:
Ctrl + Break (быстрый возврат в главное меню вместо многократного Esc или F10) — A.Data Management (управление данными) — 1. Display Data Directory — выбираем нашу переменную WORK. x - F6.
Наблюдаем выборку. Выпишем значения выборки или выведем на печать (клавиша F4) или сохраним (F3; повторный вызов: Report Writer & Graphics Replay (составление отчетов и вызов графиков) - Replay Texts & Graphic Files (вызов текстов и графических файлов ) ).
Посмотрим выборку графически. После возврата в главное меню ( Ctrl + Break):
E.Plotting Function (графические функции) — 1 .X-Y Line and Scatterplots (x-y графики) — вводим данные для графика: по оси x должны быть целые числа от 1 до n: в строку x записываем оператор (для n = 50, например):
COUNT 50
этот оператор создает массив целых чисел от 1 до 50; в строку y записываем x; в окне Points: Yes (точки нужны), в окне Lines: Yes (клавишей «пробел», линии нужны) - F6.
График выведем на печать (F4) или сохраним (F3).
Построение вариационного ряда
Й способ
A.2.File Operations — вводим в окно file name: WORK (можно так: Ctrl+F7 (список файлов) — выделить нужный - ENTER) - Desired operation: C (Edit - редактирование) - F6 — выделяем переменную x - ENTER - F6-(наблюдаем выборку) - F5 (опции) - Sort in ascending order (сортировка в порядке возрастания ) - F6 - Save and exit (запоминание и выход). Если бы требовалось не менять содержимое переменной x, следовало бы сначала скопировать ее в другую переменную (операцией U pdate).
Й способ
Сначала загрузим оператор сортировки SORTUP, который относится к разряду загружаемых:
V.Supplementary Operations (дополнительные операции) — 1. Load Operation and Function (загрузка операторов и функций) — Mathematical function - Read (после использования загружаемых операторов их желательно выгрузить опцией Erase, чтобы не занимать память).
Ctrl+F5 (быстрый выход в исполнительное окно) — SORTUP x - ENTER (наблюдаем вариационный ряд, при этом содержащие переменной x не изменилось).
Построение графика функции эмпирического распределения
F.3.Frequency Histogram — Data: x - F6 — поправляем некоторые параметры графика: No of classes (число классов): 200 (или еще больше: — 500, чтобы на каждый интервал попало не больше одного наблюдения), Cumulative: Yes, (накопленные частоты, т.е. функция распределения), Relative: Yes, (относительные частоты) - F6.
Наблюдаем функцию эмпирического распределения. Выводим ее на печать или сохраняем.
Группирование данных
F.2.Frequency Tabulation — Data: x - F6 — поправляем, если нужно параметры группирования: нижний (Lower limit) и верхний (Upper Limit) пределы (минимальное и максимальное значения выборки приведены ниже на экране), число интервалов группирования No of classes: 10 - F6 — Display Table - ENTER.
Наблюдаем таблицу группированных данных. Выводим ее на печать или сохраняем.
|
из
5.00
|
Обсуждение в статье: Построение вариационного ряда |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы