 |
Главная |


Структурная схема устройства выделения признаков речевых сигналов
|
из
5.00
|
Ниже будет предложена следующая структурная схема устройства выделения признаков речевых сигналов (рисунок 1.1).
Она состоит из следующих блоков:
1 - микрофон;
2 – блок выделения огибающей;
3 – блок определения начала и конца слова;
4 – блок выделения конечной разности;
5 – блок выделения количества звуков;
6 – линия задержки;
7 – блок выделения интервалов;
8 – блок анализа;
9 – блок данных;
10 – печатающее устройство.
 Рисунок 1.1 - Структурная схема устройства выделения признаков речевых сигналов
Рисунок 1.1 - Структурная схема устройства выделения признаков речевых сигналов
|
Задача распознавания речи может быть сведена к задаче распознавания отдельных звуков с последующим использованием алгоритмов, учитывающих особенности произношения, словопостроения и словосочетания фраз отдельных индивидуумов.
В этом случае задача выделения звуков речи может рассматриваться как задача распознавания образов, количество которых ограничено, хотя и достигает нескольких десятков. При этом сама задача классификации предъявляемых образцов звуков может быть сведена к задаче многоальтернативной проверки гипотез. При этом система распознавания звуков речи может строиться с использованием принципов "обучения с учителем", т.е. предварительного набора информационной базы классифицированных данных, с которыми производится сравнение поступающих на анализ сигналов. Процедура распознавания звуков речи должна учитывать особенности их реализации. Во-первых, эти реализации у каждого звука имеют свой вид. Во-вторых, имеют ограниченную протяженность во времени.
Методы анализа речевых сигналов можно рассматривать с помощью модели, в которой речевой сигнал является откликом системы с медленно изменяющимися параметрами на периодическое или шумовое возбуждающее колебание (рисунок 1.2).
Выходной сигнал голосового тракта определяется сверткой функции возбуждения и импульсного отклика линейного, изменяющегося во времени фильтра, моделирующего голосовой тракт. Таким образом, речевой сигнал s(t) выражается следующим образом:
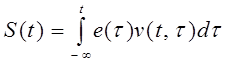 ,
,
где e(t) - функция возбуждения, v(t,t) - отклик голосового тракта в момент t на дельта-функцию, подаваемую на вход в момент t.

|
| Рисунок 1.2 - Схема функциональной модели формирования речи |
Речевой сигнал можно промоделировать откликом линейной системы с переменными параметрами (голосового тракта) на соответствующий возбуждающий сигнал. При неизменной форме голосового тракта выходной сигнал равен свертке возбуждающего сигнала и импульсного отклика голосового тракта. Однако все разнообразие звуков получается путем изменения формы голосового тракта. Если форма голосового тракта изменяется медленно, то на коротких интервалах времени выходной сигнал логично по-прежнему аппроксимировать сверткой возбуждающего сигнала и импульсного отклика голосового тракта. Поскольку при создании различных звуков форма голосового тракта изменяется, огибающая спектра речевого сигнала будет, конечно, тоже изменяться с течением времени. Аналогично при изменении периода сигнала, возбуждающего звонкие звуки, частотный разнос между гармониками спектра будет изменяться. Следовательно, необходимо знать вид речевого сигнала на коротких отрезках времени и характер его изменения во времени.
В системах анализа речевых сигналов обычно пытаются разделить возбуждающую функцию и характеристики голосового тракта. Далее в зависимости от конкретного способа анализа получают параметры, описывающие каждую компоненту.
В частотной области спектр коротких отрезков речевого сигнала можно представить в виде произведения огибающей, характеризующей состояние голосового тракта, и функции, описывающей тонкую структуру, которая характеризует возбуждающий сигнал. Поскольку основным параметром сигнала, возбуждающего звонкий звук, является разнос гармоник основного тона, а характеристики голосового тракта с достаточной полнотой определяются частотами формант, то при анализе весьма удобно исходить из представления речи в частотной области. При создании различных звуков форма голосового тракта и возбуждающий сигнал изменяются, при этом изменяется и спектр речевого сигнала. Следовательно, спектральное представление речи должно основываться на кратковременном спектре, получаемом из преобразования Фурье.
Рассмотрим дискретизированный речевой сигнал, представленный последовательностью s(n). Его кратковременное преобразование Фурье S(w,n) определяется как
 (1.1)
(1.1)
Данное выражение описывает преобразование Фурье взвешенного отрезка речевого колебания, причем весовая функция h(n) сдвигается во времени.
Линейное предсказание является одним из наиболее эффективных методов анализа речевых сигналов. Этот метод становится доминирующим при оценке основных параметров речевых сигналов, таких как период основного тона, форманты, спектр, а также при сокращенном представлении речи с целью ее низкоскоростной передачи и экономного хранения. Важность метода обусловлена высокой точностью получаемых оценок и относительной простотой вычисления.
Основной принцип метода линейного предсказания состоит в том, что текущий отсчет речевого сигнала можно аппроксимировать линейной комбинацией предшествующих отсчетов. Коэффициент предсказания при этом определяется однозначно минимизацией среднего квадрата разности между отсчетами речевого сигнала и их предсказанными значениями (на конечном интервале). Коэффициенты предсказания - это весовые коэффициенты, используемые в линейной комбинации. Метод линейного предсказания можно применять для сокращения объема цифрового речевого сигнала.
Основной целью обработки речевых сигналов является получение наиболее удобного и компактного представления содержащейся в них информации. Точность представления определяется той информацией, которую необходимо сохранить или выделить. Например, цифровая обработка может применяться для выяснения, является ли данное колебание речевым сигналом. Сходная, но несколько более сложная задача состоит в том, чтобы классифицировать колебания на вокализованную речь, невокализованную речь и паузу (шум).
В основе большинства методов обработки речи лежит представление о том, что свойства речевого сигнала с течением времени медленно изменяются. Это предположение приводит к методам кратковременного анализа, в которых сегменты речевого сигнала выделяются и обрабатываются так, как если бы они были короткими участками отдельных звуков с отличающимися свойствами.
Одним из наиболее известных методов анализа речи во временной области можно назвать метод, предложенный Л.Рабинером и Р.Шафером в /3/. Он основан на измерении кратковременного среднего значения сигнала и кратковременной функции среднего числа переходов через нуль. Как отмечалось выше, амплитуда речевого сигнала существенно изменяется во времени. Подобные изменения амплитуды хорошо описываются с помощью функции кратковременной энергии сигнала. В общем случае определить функцию энергии можно как

Это выражение может быть переписано в виде
 , (1.2)
, (1.2)
где 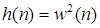
Выбор импульсной характеристики h(n) или окна составляет основу описания сигнала с помощью функции энергии.
Чтобы понять, как влияет выбор временного окна на функцию кратковременной энергии сигнала, предположим, что h(n) в (1.2) является достаточно длительной и имеет постоянную амплитуду; значение En будет при этом изменяться во времени незначительно. Такое окно эквивалентно фильтру нижних частот с узкой полосой пропускания. Полоса фильтра нижних частот не должна быть столь узкой, чтобы выходной сигнал оказался постоянным. Для описания быстрых изменений амплитуды желательно иметь узкое окно (короткую импульсную характеристику), однако слишком малая ширина окна может привести к недостаточному усреднению и, следовательно, к недостаточному сглаживанию функции энергии. Влияние ширины временного окна на точность измерения кратковременного среднего значения (средней энергии):
если N (ширина окна в отсчетах) мало (порядка периода основного тона и менее), то En будет изменяться очень быстро, в соответствии с тонкой структурой речевого колебания,
если N велико (порядка нескольких периодов основного тона), то En будет изменяться медленно и не будет адекватно описывать изменяющиеся особенности речевого сигнала.
Это означает, что не существует единственного значения N, которое в полной мере удовлетворяло бы перечисленным требованиям, так как период основного тона изменяется от 10 отсчетов (при частоте дискретизации 10 кГц) для высоких детских и женских голосов и до 250 отсчетов для очень низких мужских. N выберем равным 100, 200, 300 отсчетов при частоте дискретизации 8 кГц.
Основное назначение En состоит в том, что эта величина позволяет отличить вокализованные речевые сегменты от невокализованных. Значение функции кратковременного среднего значения сигнала для невокализованных сегментов значительно меньше, чем для вокализованных.
Характерной особенностью метода анализа речевых сигналов является бинарное квантование входного речевого сигнала. Возможность выделения параметров сигналов, подвергшихся бинарному квантованию, показана в /4/. Используемая математическая модель речевого сигнала имеет вид:
 , (1.3)
, (1.3)
где A(t) - закон изменения амплитуды речевого сигнала, Y(t) - полная фазовая функция речевого сигнала.
Закон изменения амплитуды сигнала не является достаточно информативным параметром для оценки речевого сообщения, так как он не является постоянным для одного и того же слова или фразы, произнесенных с различной интонацией и громкостью. В качестве информативной характеристики речевого сигнала в предлагаемом методе полагается полная фазовая функция речевого сигнала. Полная фазовая функция речевого сигнала представляется в виде разложения в ряд Тейлора:
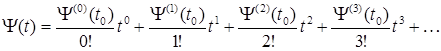 . (1.4)
. (1.4)
Выражение (1.4) можно переписать следующим образом
 . (1.5)
. (1.5)
В разложении берутся первые три коэффициента разложения. При этом первый коэффициент m0, являющийся начальной фазой речевого сигнала, принимается равным нулю, вследствие неинформативности. Тогда полная фазовая функция будет:
 , (1.6)
, (1.6)
где, m1 - коэффициент разложения, являющийся средней частотой речевого сигнала, m2 - коэффициент разложения, являющийся изменением (девиацией) частоты речевого сигнала.
После дискретизации полная фазовая функция имеет следующий вид:
 , (1.7)
, (1.7)
где i - номер текущего отсчета в дискретизированной последовательности, Dt - шаг дискретизации.
Параметры m1 и m2 являются характеристиками, которые используются для описания речевого сообщения. В режиме обработки "скользящее окно" вычисляется первая конечная разность полной фазовой функции речевого сигнала, которая является кратковременной функцией среднего числа переходов через нуль речевого сигнала и является грубой оценкой частоты речевого сигнала m1 с некоторой погрешностью, зависящей от изменения частоты m2. Для определения m2 следует вычислить вторую конечную разность полной фазовой функции речевого сигнала, которая также является скоростью изменения функции среднего числа переходов через нуль речевого сигнала. Первая и вторая конечные разности полной фазовой функции имеют следующий вид /4/:
 ,
,
 , (1.8)
, (1.8)
где L - ширина временного "скользящего" окна выраженная в количестве отсчетов.
Тогда из (1.8) частоту речевого сигнала m1 и изменение частоты m2, получим в виде:
 ,
,
 ,
,
где T=L×Dt - ширина временного "скользящего" окна.
|
из
5.00
|
Обсуждение в статье: Структурная схема устройства выделения признаков речевых сигналов |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы