 |
Главная |


Применение скрытых Марковских моделей для распознавания речи.
|
из
5.00
|
· Введение в скрытые Марковские модели (СММ). Решение задачи распознавания.
Скрытой Марковской моделью (СММ) называется модель состоящая из N состояний, в каждом из которых некоторая система может принимать одно из M значений какого-либо параметра. Вероятности переходов между состояниями задается матрицей вероятностей A={aij}, где aij – вероятность перехода из i-го в j-е состояние. Вероятности выпадения каждого из M значений параметра в каждом из N состояний задается вектором B={bj(k)}, где bj(k) – вероятность выпадения k-го значения параметра в j-м состоянии. Вероятность наступления начального состояния задается вектором π={πi}, где πi – вероятность того, что в начальный момент система окажется в i-м состоянии.
Таким образом, скрытой Марковской моделью называется тройка λ={A,B,π}. Использование скрытых Марковских моделей для распознавания речи основано на двух приближениях:
1) Речь может быть разбита на фрагменты, соответствующие состояниям в СММ, параметры речи в пределах каждого фрагмента считаются постоянными.
2) Вероятность каждого фрагмента зависит только от текущего состояния системы и не зависит от предыдущих состояний.
Модель называется «скрытой», так как нас, как правило, не интересует конкретная последовательность состояний, в которой пребывает система. Мы либо подаем на вход системы последовательности типа O={o1,o2,…oi} - где каждое oi – значение параметра (одно из M), принимаемое в i-й момент времени, а на выходе ожидаем модель λ={A,B,π}с максимальной вероятностью генерирующую такую последовательность, - либо наоборот подаем на вход параметры модели и генерируем порождаемую ей последовательность. И в том и другом случае система выступает как “черный ящик”, в котором скрыты действительные состояния системы, а связанная с ней модель заслуживает названия скрытой.
Для осуществления распознавания на основе скрытых моделей Маркова необходимо построить кодовую книгу, содержащую множество эталонных наборов для характерных признаков речи (например, коэффициентов линейного предсказания, распределения энергии по частотам и т.д.). Для этого записываются эталонные речевые фрагменты, разбиваются на элементарные составляющие (отрезки речи, в течении которых можно считать параметры речевого сигнала постоянными) и для каждого из них вычисляются значения характерных признаков. Одной элементарной составляющей будет соответствовать один набор признаков из множества наборов признаков словаря.
Фрагмент речи разбивается на отрезки, в течении которых параметры речи можно считать постоянными. Для каждого отрезка вычисляются характерные признаки и подбирается запись кодовой книги с наиболее подходящими характеристиками. Номера этих записей и образуют последовательность наблюдений O={o1,o2,…oi} для модели Маркова. Каждому слову словаря соответствует одна такая последовательность. Далее A – матрица вероятностей переходов из одного минимального отрезка речи (номера записи кодовой книги) в другой минимальный отрезок речи (номер записи кодовой книги). В – вероятности выпадения в каждом состоянии конкретного номера кодовой книги рис. 2.2

Рис. 2.2 кодовая книга
На этапе настройки моделей Маркова мы применяем алгоритм Баума- Уэлча для имеющегося словаря и сопоставления каждому из его слов матрицы A и B.
При распознавании мы разбиваем речь на отрезки, для каждого вычисляем набор номеров кодовой страницы и применяем алгоритм прямого или обратного хода для вычисления вероятности соответствия данного звукового фрагмента определенному слову словаря. Если вероятность превышает некоторое пороговое значение – слово считается распознанным.
· Алгоритм Баума-Уэлча.
Необходимо подобрать параметры скрытой модели Маркова так, чтобы максимизировать вероятность данной последовательности наблюдений.
Вводятся переменные
ξt(i,j) = P(qt=Si,qt+1=Sj|O,λ)
которые показывают вероятность того, что при заданной последовательности наблюдений O система в моменты времени t и t+1 будет находиться соответственно в состояниях Si и Sj. Используя прямую и обратную переменные запишем:

Введем переменные вероятности того, что при заданной последовательности наблюдений O система в момент времени t будет находиться в состоянии Si:

При этом мы можем вычислить ожидаемое число переходов из состояния Si: равно

а ожидаемое число переходов из состояния Si в состояние Sj

Исходя из этого можно получить формулы для переоценки параметров модели Маркова:
π*i=  (i)
(i)
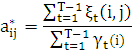
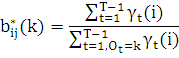
Выражение

в формуле для b*ij (k) означает что суммируются только те γt(j) , для которых значение состояния равно k, то есть Ot = k.
После переоценки параметры модели либо выясняется, что она уже была оптимальной до переоценки либо обязательно улучшаются ее параметры (то есть правдоподобность модели после переоценки выше, чем до переоценки во всех случаях, когда модель можно оптимизировать).
|
из
5.00
|
Обсуждение в статье: Применение скрытых Марковских моделей для распознавания речи. |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы