 |
Главная |


Инвертированные текстовые файлы.
|
из
5.00
|
Получаются из цепочечных файлов, когда в справочник включаются адресные ссылки на все тексты, имеющие соответствующий ключ в качестве индексационного термина.
Недостаток: переменное число адресов в справочнике.
Достоинство: быстрый поиск релевантных документов, так как их адреса находятся сразу в справочнике, обработку которого можно организовать в оперативной памяти.
Рассредоточенные текстовые файлы.
Весь массив документов разбивается на группы файлов, ключевые термины которых связаны некоторым математическим соотношением. Тогда поиск в справочнике заменяется вычислительной процедурой, которая называется хешированием, рандомизацией или перемешиванием.
Здесь нет справочника, а существует вычислительная процедура, т.е. блок, называемый блоком рандомизации, который по ключу (поисковому термину) на основании вычислительной процедуры определяет адрес, по которому находится текст.
Ключ адрес этот участок
{ключ} памяти
называется
бакетом
В этой области памяти находится несколько текстов, каждый из которых характеризуется по своему в векторе документов. Т.е. адрес получается по вычислительной процедуре.
Преимущества:
Быстрый вычисляемый доступ;
Из-за отсутствия справочника экономится память.
Недостатки:
Сложность при выборе метода хеширования;
Применяется для коротких векторов запросов, когда в поиске участвует немного слов;
Изменения векторов документов порождает сложность в ведении файлов.
 Вопрос 27(окончание).
Вопрос 27(окончание).
4. Коррекция кластеров сверху вниз.
В начале строятся один или несколько очень больших кластеров, которые затем разбиваются на более мелкие.
Способы выбора исходных классов:
В качестве центров классов используются случайные документы;
Классом с именем i можно считать множество документов, в векторах которых находится термин i;
В качестве исходных классов принимаются все документы, признанные релевантными некоторому запросу по результатам предыдущих поисковых операций.
Процесс коррекции кластеров:
Вычисляется КП между каждым документом и каждым центроидом кластера;
Кластеры переопределяются путём отнесения документов к тем из них, по отношению к которым, они имеют наибольшее подобие;
Формируются центроиды новых кластеров.
Эти 3 шага выполняются до тех пор, пока:
Будет необходимость в изменениях;
Чтобы процесс не был бесконечным, он выполняется в заданное число итераций.
5.Однократная кластеризация.
Документы рассматриваются в произвольном порядке и каждый документ либо относится к существующему классу, если КП достаточен, либо образует новый кластер.
“+”: каждый документ обрабатывается только 1 раз, => требует мало времени.
“-”: состав и структура классов существенно зависит от порядка рассмотрения документов.
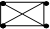
Нахождение КЛИК.
Клика – такой вид кластера, в котором каждый документ подобен любому другому документу. Клика формируется тогда, когда возникает полный граф, т.е. полное соотношение подобия между всеми элементами.
А В
С Д
Исходными данными для метода является матрица подобия документа массива, которая заполняется коэффициентами подобия всех пар документов.
Матрица: S(Di , Dj) – диагональная квадратная и симметричная.
i = 1,N ; j = 1,N.
Пусть задано множество пар:
VDi = {(ti , wi)}
VDj = {(tj , wj)}
Коэффициент подобия документов определяется:
S(Di , Dj) = сумм(k =1,N)rk/N
r – отношение; N – мощность множества документов.
0, wi = 0 или wj = 0
rk = wi / wj в противном случае
Чтобы задача решалась адекватно, вектора (*) должны быть упорядочены по терминам, т.е. одни и те же термины должны быть записаны в одних и тех же позициях этих векторов. Исходная матрица, которая получена в результате расчётов, преобразуется в бинарную следующим образом: вводится некоторое пороговое значение T коэффициента подобия, и те коэффициенты, которые меньше его заменяются на 0, в противном случае на 1:
S(Di , Dj) < T , => 0
S(Di , Dj) > T , => 1
Алгоритм:
1.В класс или кластер включаются подгруппы порядка 2, т.е. те элементы, которые в отношении подобия установлены на паре.
2.Из подгруппы порядка 2 получают подгруппу порядка 3 по следующему правилу: если есть подгруппы (Di , Dj) , (Di , Dp) , (Dj , Dp), то получаем: (Di , Dj , Dp) и подгруппы из исходного списка исключаются.
3.Из подгруппы порядка p формируют подгруппу порядка (p+1),т.е. (Di , Dj , … , Dp) => (Di , Dj , … ,
Вопрос 33(продолжение).
Последовательность.
Это свойство гарантирует, что пользователь, освоивший работу в одной части системы не запутается, работая в другой её части.
Выражается в 3-х явлениях:
Последовательность в построении фраз. Т.е. вводимые коды или команды в системе всегда трактуются одинаково;
Последовательность в использовании форматов данных - аналогичные поля всегда представляются в одном формате (противоречит требованию гибкости);
Последовательность в размещении данных на экране.
Рекомендуется следующий шаблон для оформления экрана:
Вверху в 2-х, 3-х строках помещается заголовок и данные о состоянии системы;
Далее, под заголовком размещается область для вывода справочных сообщений;
Основная область – для рисования или для ввода данных;
Ниже – область для вывода сообщений об ошибках;
Описание функциональных клавиш.
Краткость.
Требует от пользователя ввода минимума информации. Это, с одной стороны, убыстряет работу системы, а, с другой, приводит к появлению ошибок.
Рекомендации:
Не следует запрашивать информацию, которую следует сформировать автоматически;
Информация не должна выводится сразу же, только потому, что она стала доступна системе. Она должна выводится только в том объёме, который требуется пользователю и в нужном для него формате.
Поддержка пользователя – мера помощи, которую система оказывает пользователю при работе с ней.
Эта поддержка выражается в 3-х видах:
Инструкции пользователя. Выводятся в виде подсказок или справочной информации. При этом справочная информация должна быть контекстной, своевременной и доступной в любой точке диалога. Помимо внутрисистемной существует внешняя справочная информация, которая сопровождает текст в виде бумажного носителя. Там указывается 5 моментов:
Общий обзор, в котором описывается назначение системы, основные понятия предметной области, необходимые для оценки системы, связанные с этими понятиями принципы работы системы;
Как начать работу с системой;
Сведения о поведении пользователя при выходе системы или отдельных частей из строя;
Пример работы с системой;
Ограничения на систему.
Сообщения об ошибках. Хорошее сообщение об ошибке должно отвечать следующим требованиям:
Должно быть изложено в терминах, понятных пользователю;
Нужно точно определить причину ошибки;
Должно пояснять, как исправить ошибку;
Должно быть своевременным, пока не проделаны вещи, которые необратимы.
Подтверждения каких-либо действий системы.
Гибкость - мера того, насколько хорошо диалог соответствует различным уровням подготовки и производительности труда пользователя. Гибкость называют свойством адаптивности системы.
Существует 3 системы, которые характеризуют её гибкость:
 37.Типы диалогов.
37.Типы диалогов.
4 типа диалога:
вопрос – ответ;
меню;
командный язык;
экранные формы.
Вопрос – ответ. Самая старая форма ведения диалога. Используется в экспертных системах, в информационно – поисковых системах к фактографическим или документальным базам данных.
3 вида диалога в режиме “вопрос – ответ”:
Диалог с ограничениями на предметную область. Форма запроса – произвольна (ограничений нет), а лексика запроса строится на базе 2-х словарей. 1-й содержит функциональные слова, которые либо означают характер задачи, которую нужно решить, либо носят вспомогательный характер, т.е. те запросы с которыми пользователь обращается к БД. Эти функциональные слова являются ключевыми, смысл их жёстко регламентирован.
2-й словарь содержит специфические термины, которые характеризуют данную предметную область и, как правило, являются именами полей с записями базы данных. 1-е ограничение: если существуют надёжные окончания, то каждое слово из запроса нужно спроецировать на слова из словаря (где максимальное пересечение, то и брать). 2-е ограничение в рамках диалога – ограничение на язык.
Требования:
Запрос или задание формируется с помощью фраз естественного языка, каждая из которых описывает элемент, операцию, которую надо выполнить.
Каждое предложение должно начинаться с функционального слова, определяющего нужное действие.
При формулировке условий поиска каждое значение поля БД должно предваряться названием этого поля.
3-я форма – естественно языковая без ограничений.
Этот диалог применяется тогда, когда диапазон либо слишком велик, либо вообще не определён.
Последующий запрос зависит от предыдущего, т.е. этот диалог нельзя заранее описать некоторым сценарием.
Меню – ориентированный диалог.
Здесь у пользователя есть список вариантов ответа и он выбирает нужный номер.
Виды меню:
1.
2. С использованием мнемонических обозначений опций (Norton Commander);
3. Блоковое;
4. Строчное меню;
5. Меню в виде пиктограмм.
Требования к меню:
Каждое меню должно содержать 5-6 опций;
При большом числе различных вариантов их надо группировать (подменю);
Пункты меню должны следовать в естественном порядке или по алфавиту.
Применение меню:
Диапазон возможных ответов невелик и они все известны заранее и могут быть представлены явно;
Когда пользователю необходимо видеть сразу все опции для выбора оптимальной, чтобы оценить все возможные варианты;
Когда пользователь неопытен.
 40.Метод нисходящего синтаксического анализа(СА).
40.Метод нисходящего синтаксического анализа(СА).
Нисходящий СА (развёртка) – дерево разбора строится от корней к листьям.
СА методом развёртки. Здесь делается предположение, что исходное предложение уже принадлежит языку, а следовательно к ней применяется 1-я продукция грамматики, в которой левая часть является начальным символом грамматики. Этот шаг является 1-м шагом алгоритма развёртки. Введём здесь понятие элемента развёртки, роль которого на 1-м шаге правая часть продукции.
2-й шаг: из элемента развёртки выбирается крайний слева нетерминальный символ. Нетерминальный символ заменяется правой частью продукции с соответствующей левой частью того же списка продукции. Управление передаётся началу 2-го шага этого алгоритма. Если цепочка не содержит нетерминальных символов, она сравнивается с исходной анализируемой цепочкой. Если они совпадают, то конец алгоритма, иначе переход к шагу 3.
Шаг 3: разбор выполняется заново и при альтернативных вариантах продукции выбираются те, которые ранее не использовались. Т.е. выполняется разбор предложения фактически, по несколько другой схеме.
Если в грамматических правилах преобладают правила с одинаковыми левыми частями, оптимальнее выбирать восходящий разбор предложения и наоборот, если превалируют правила с альтернативными правыми частями нужно выбирать нисходящий разбор.
|
из
5.00
|
Обсуждение в статье: Инвертированные текстовые файлы. |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы