 |
Главная |


Удаление вершины из КЧД
|
из
5.00
|
Удаление вершины немного сложнее добавления. Мы будем считать, что (NIL).color == BLACK, и будем считать операцию взятия цвета у указателя, равного NIL, допустимой операцией. Также мы будем считать допустимым присваивание (NIL).nodeParent, и будем считать данное присваивание имеющим результат. То есть при взятии значения (NIL).nodeParent мы получим ранее записанное значение. Функция RBTDelete подобна TreeDelete, но, удалив вершину, она вызывает процедуру RTBDeleteFixUp для восстановления свойств КЧД.
| RBTDelete(Tree,node) Begin If (node.left == NIL) or (node.right == NIL) Then nodeParent = node; Else nodeParent = TreeNext(node); If (nodeParent.left != NIL) Then nodeTemp = nodeParent.left; Else nodeTemp = nodeParent.right; nodeTemp.nodeParent = nodeParent.nodeParent; If (nodeTemp.nodeParent == NIL) Then Tree.root = nodeTemp; Else Begin If (nodeParent.nodeParent.left == nodeParent) Then nodeParent.nodeParent.left = nodeTemp; Else nodeParent.nodeParent.right = nodeTemp; End If (nodeParent != node) Then Begin node.key = nodeParent.key; node.color = nodeParent.color; { копирование дополнительных данных } End If (nodeParent.color == BLACK) Then RBTDeleteFixUp(Tree,nodeTemp); Return nodeParent; End |
Рассмотрим, как процедура RBTDeleteFixUp восстанавливает свойства КЧД. Очевидно, что если удалили красную вершину, то, поскольку оба ее потомка чёрные, красная вершина не станет родителем красного потомка. Если же удалили чёрную вершину, то как минимум на одном из путей от корня к листьям количество чёрных вершин уменьшилось. К тому же красная вершина могла стать потомком красного родителя.
| 1 RTBDeleteFixUp(Tree,node) 2 Begin 3 While (node != Tree.root) and (node.color == BLACK) Do 4 Begin 5 If (node == node.nodeParent.left) 6 Begin 7 nodeTemp = node.nodeParent.right; 8 If (nodeTemp.color == RED) Then 9 Begin 10 nodeTemp.color = BLACK; 11 nodeTemp.nodeParent.color = RED; 12 RBTLeftRotate(Tree,node.nodeParent); 13 nodeTemp = node.nodeParent.right; 14 End 15 If (nodeTemp.left.color == BLACK) and (nodeTemp.right.color == BLACK) Then 16 Begin 17 nodeTemp.color = RED; 18 nodeTemp = nodeTemp.nodeParent; 19 End 20 Else 21 Begin 22 If (nodeTemp.right.color == BLACK) Then 23 Begin 24 nodeTemp.left.color = BLACK; 25 nodeTemp.color = RED; 26 RBTRightRotate(Tree,nodeTemp) 27 nodeTemp = node.nodeParent.right; 28 End 29 nodeTemp.color = node.nodeParent.color; 30 node.color.nodeParent = BLACK; 31 nodeTemp.right.color = BLACK; 32 RBTLeftRotate(Tree,node.nodeParent); 33 node = Tree.root; 34 End 35 End 36 Else 37 Begin 38 nodeTemp = node.nodeParent.left; 39 If (nodeTemp.color == RED) Then 40 Begin 41 nodeTemp.color = BLACK; 42 nodeTemp.nodeParent.color = RED; 43 RBTRightRotate(Tree,node.nodeParent); 44 nodeTemp = node.nodeParent.left; 45 End 46 If (nodeTemp.right.color == BLACK) and (nodeTemp.left.color == BLACK) Then 47 Begin 48 nodeTemp.color = RED; 49 nodeTemp = nodeTemp.nodeParent; 50 End 51 Else 52 Begin 53 If (nodeTemp.left.color == BLACK) Then 54 Begin 55 nodeTemp.right.color = BLACK; 56 nodeTemp.color = RED; 57 RBTLeftRotate(Tree,nodeTemp) 58 nodeTemp = node.nodeParent.left; 59 End 60 nodeTemp.color = node.nodeParent.color; 61 node.color.nodeParent = BLACK; 62 nodeTemp.left.color = BLACK; 63 RBTRightRotate(Tree,node.nodeParent); 64 node = Tree.root; 65 End 66 End 67 End 68 node.color = BLACK; 69 End |
Процедура RBTDeleteFixUp применяется к дереву, которое обладает свойствами КЧД, если учесть дополнительную единицу черноты в вершине node (она теперь дважды чёрная, это чисто логическое понятие, и оно нигде фактически не сохраняется и логического типа для хранения цвета вам всегда будет достаточно) и превращает его в настоящее КЧД.
Что такое дважды чёрная вершина? Это определение может запутать. Формально вершина называется дважды чёрной, дабы отразить тот факт, что при подсчёте чёрных вершин на пути от корня до листа эта вершина считается за две черных. Если чёрная вершина была удалена, её черноту так просто выкидывать нельзя. Она на счету. Поэтому временно черноту удалённой вершины передали вершине node. В задачу процедуры RBTDeleteFixUp входит распределение этой лишней черноты. Они или будет передана красной вершине (и та станет чёрной) или после перестановок других чёрных вершин (дабы изменить их количество на пути от корня к листьям) будет просто выкинута.
В цикле (строки 3-67) дерево изменяется, и значение переменной node тоже изменяется, но сформулированное свойство остаётся верным. Цикл завершается, если:
node указывает на красную вершину, тогда мы красим её в чёрный цвет (строка 68).
node указывает на корень дерева, тогда лишняя чернота может быть просто удалена.
Могло оказаться, что внутри тела цикла удается выполнить несколько вращений и перекрасить несколько вершин, так что дважды чёрная вершина исчезает. В этом случае присваивание node = Tree.root (строки 33 и 64) позволяет выйти из цикла.
Внутри цикла node указывает на дважды чёрную вершину, а nodeTemp – на её брата (другую вершину с тем же родителем). Поскольку вершина node дважды чёрная, nodeTemp не может быть NIL, поскольку в этом случае вдоль одного пути от node.nodeParent было бы больше чёрных вершин, чем вдоль другого. Четыре возможных случая показаны на рисунке ниже. Зелёным и синим, помечены вершины, цвет которых не играет роли, то есть может быть как черным, так и красным, но сохраняется в процессе преобразований.
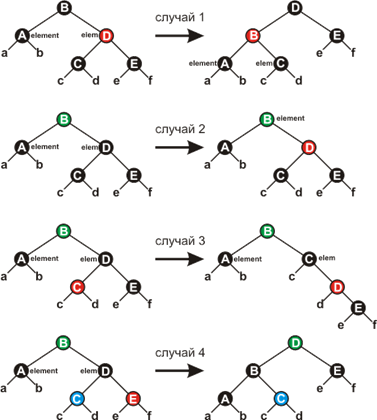
Рисунок 8
Убедитесь, что преобразования не нарушают свойство 4 КЧД (помните, что вершина node считается за две чёрные, и что в поддеревьях a - f изначально не равное количество чёрных вершин).
Случай 1 (строки 9-14 и 40-45) имеет место, когда вершина nodeTemp красная (в этом случае node.nodeParent чёрная). Так как оба потомка вершины nodeTemp чёрные мы можем поменять цвета nodeTemp и node.nodeParent и произвести левое вращение вокруг node.nodeParent не нарушая свойств КЧД. Вершина node остается дважды чёрной, а её новый брат – чёрным, так что мы свели дело к одному из случаев 2-4.
Случай 2 (строки 16-19 и 47-50). Вершина nodeTemp – чёрная, и оба её потомка тоже чёрные. В этом случае мы можем снять лишнюю чёрноту с node (теперь она единожды чёрная), перекрасить nodeTemp, сделав ёё красной (оба её потомка чёрные, так что это допустимо) и добавить черноту родителю node. Заметим, что если мы попали в случай 2 из случая 1, то вершина node.nodeParent – красная. Сделав её чёрной (добавление чёрного к красной вершине делает её чёрной), мы завершим цикл.
Случай 3 (строки 23 – 28 и 53 - 59) Вершина nodeTemp чёрная, её левый потомок красный, а правый чёрный. Мы можем поменять цвета nodeTemp и её левого потомка и потом применить правое вращение так, что свойства КЧД будут сохранены. Новым братом node будет теперь чёрная вершина с красным правым потомком, и случай 3 сводится к случаю четыре.
Случай 4 (строки 29 – 33 и 60 - 64) Вершина nodeTemp чёрная, правый потомок красный. Меняя некоторые цвета (не все из них нам известны, но это нам не мешает) и, производя левое вращение вокруг node.nodeParent, мы можем удалить лишнюю черноту у node, не нарушая свойств КЧД. присваивание node = Tree.root выводит нас из цикла.
Сравнительные характеристики скорости работы различных структур данных
Чтобы всё сказанное до этого не казалось пустой болтовнёй, я в качестве заключения приведу сравнительные характеристики скорости работы различных структур данных (деревьев и массивов). Для измерения времени была использована функция WinAPI QueryPerfomanceCounter. Время пересчитано в микросекунды. В скобках приведена конечная глубина дерева. Тестирование проводилось на процессоре Intel Celeron Tualatin 1000MHz с 384Мб оперативной памяти. В качестве ключа использовалось число типа int (32-х битное целое со знаком), а в качестве данных число типа float (4-х байтное вещественное).
| Количество элементов | ДДП | КЧД | Постоянно сортированный массив | Несортированный массив | Массив с постсортировкой |
| 1000 | 4943 (1000) | 535 (17) | 193 | 32 | 73 |
| 2000 | 20571 (2000) | 1127 (19) | 402 | 89 | 152 |
| 3000 | 65819 (3000) | 1856 (20) | 621 | 98 | 305 |
| 4000 | 82321 (4000) | 2601 (21) | 862 | 189 | 327 |
| 5000 | 126941 (5000) | 3328 (22) | 1153 | 192 | 461 |
| 6000 | 183554 (6000) | 4184 (22) | 1391 | 363 | 652 |
| 7000 | 255561 (7000) | 4880 (23) | 1641 | 452 | 789 |
| 8000 | 501360 (8000) | 5479 (23) | 1905 | 567 | 874 |
| 9000 | 1113230 (9000) | 6253 (24) | 2154 | 590 | 1059 |
| 10000 | 1871090 (10000) | 7174 (24) | 2419 | 662 | 1180 |
Таблица 1. Добавление элемента (возрастающие ключи)
| Количество элементов | ДДП | КЧД | Постоянно сортированный массив | Несортированный массив | Массив с постсортировкой |
| 1000 | 4243 | 108 | 136 | 1354 | 134 |
| 2000 | 19295 | 250 | 289 | 5401 | 286 |
| 3000 | 71271 | 391 | 448 | 25373 | 441 |
| 4000 | 79819 | 560 | 615 | 23861 | 607 |
| 5000 | 124468 | 759 | 787 | 38862 | 776 |
| 6000 | 180029 | 956 | 954 | 55303 | 941 |
| 7000 | 246745 | 1199 | 1165 | 75570 | 1111 |
| 8000 | 487187 | 1412 | 1307 | 98729 | 1330 |
| 9000 | 1062128 | 1906 | 1494 | 134470 | 1474 |
| 10000 | 1807235 | 2068 | 1719 | 154774 | 1688 |
Таблица 2. Поиск элемента (возрастающие ключи).
| Количество элементов | ДДП | КЧД | Постоянно сортированный массив | Несортированный массив | Массив с постсортировкой |
| 1000 | 308 | 419 | 2077 | 2047 | 2080 |
| 2000 | 639 | 876 | 13422 | 8046 | 8179 |
| 3000 | 1001 | 1372 | 25092 | 30902 | 18407 |
| 4000 | 1380 | 1831 | 32572 | 32473 | 32651 |
| 5000 | 1680 | 2286 | 50846 | 51001 | 50962 |
| 6000 | 2105 | 2891 | 73321 | 73114 | 73202 |
| 7000 | 2569 | 3514 | 99578 | 100059 | 99801 |
| 8000 | 3025 | 4384 | 129833 | 129897 | 130054 |
| 9000 | 3484 | 5033 | 164846 | 194361 | 164264 |
| 10000 | 4050 | 5690 | 203207 | 202979 | 202738 |
Таблица 3. Удаление элемента по ключу (возрастающие ключи).
| Количество элементов | ДДП | КЧД | Постоянно сортированный массив | Несортированный массив | Массив с постсортировкой |
| 1000 | 547 (25) | 548 (13) | 1800 | 34 | 362 |
| 2000 | 1133 (25) | 1171 (14) | 5534 | 70 | 734 |
| 3000 | 1723 (28) | 1905 (14) | 12065 | 150 | 1174 |
| 4000 | 2891 (28) | 2985 (15) | 20867 | 223 | 1626 |
| 5000 | 3604 (28) | 4024 (15) | 32927 | 248 | 1962 |
| 6000 | 4336 (29) | 4970 (15) | 44720 | 373 | 2537 |
| 7000 | 5196 (29) | 5794 (16) | 60723 | 443 | 2977 |
| 8000 | 6051 (30) | 6972 (16) | 77482 | 511 | 3485 |
| 9000 | 6994 (30) | 7519 (16) | 104219 | 590 | 3821 |
| 10000 | 9544 (31) | 10303 (16) | 118760 | 584 | 4408 |
Таблица 4. Добавление элемента (случайные ключи)
| Количество элементов | ДДП | КЧД | Постоянно сортированный массив | Несортированный массив | Массив с постсортировкой |
| 1000 | 181 | 136 | 159 | 1354 | 155 |
| 2000 | 406 | 307 | 347 | 5412 | 339 |
| 3000 | 653 | 494 | 551 | 12927 | 538 |
| 4000 | 925 | 702 | 765 | 23936 | 747 |
| 5000 | 1223 | 949 | 1024 | 37861 | 962 |
| 6000 | 1532 | 1142 | 1216 | 55124 | 1185 |
| 7000 | 1893 | 1494 | 1453 | 75628 | 1403 |
| 8000 | 2477 | 1833 | 1679 | 98802 | 1631 |
| 9000 | 2943 | 2390 | 1994 | 125570 | 1858 |
| 10000 | 3395 | 2937 | 2228 | 154791 | 2108 |
Таблица 5. Поиск элемента (случайные ключи)
| Количество элементов | ДДП | КЧД | Постоянно сортированный массив | Несортированный массив | Массив с постсортировкой |
| 1000 | 469 | 517 | 1149 | 2014 | 1195 |
| 2000 | 995 | 1079 | 4381 | 8054 | 4387 |
| 3000 | 1557 | 1756 | 9673 | 18191 | 9639 |
| 4000 | 2272 | 2424 | 17071 | 32451 | 17105 |
| 5000 | 3070 | 3019 | 27380 | 50665 | 26954 |
| 6000 | 3528 | 3618 | 39294 | 72996 | 39227 |
| 7000 | 4322 | 4542 | 53255 | 99402 | 53309 |
| 8000 | 5299 | 5531 | 71406 | 129964 | 70766 |
| 9000 | 6180 | 6553 | 89583 | 164943 | 89935 |
| 10000 | 7527 | 7797 | 112190 | 202993 | 111439 |
Таблица 6. Удаление элемента по ключу (случайные ключи)
Постоянно сортированный массив – это массив, в который элементы вставляются так, что бы он сохранял свойство упорядоченности. Массив с постсортировкой – это массив, в который сначала вставляются все элементы, а потом он сортируется алгоритмом быстрой сортировки. Данные таблицы, безусловно, не являются истиной в последней инстанции, но позволят вам прикинуть, какая из структур данных будет наиболее производительна в вашей программе, учитывая предполагаемую вероятность операций вставки, удаления и поиска. Так, например, массив с постсортировкой является весьма привлекательным по производительности, но совершенно не подходит для комплексных работ, так как предполагает фиксированный порядок действий – сначала только добавление элементов, а после использование полученной информации. Другие структуры данных лишены этого недостатка. Для большого числа (порядка 10 000) случайных элементов время поиска в ДДП и КЧД становится практически одинаковым. Как следствие, можно реализовать более простые алгоритмы, исходя из некоторых свойств входных данных. С другой стороны, в крайнем случае (возрастающие элементы) ДДП отстают от КЧД на несколько порядков. Постоянно сортированный массив является абсолютным победителем по скорости, но не имеет естественной поддержки отношений родитель-ребёнок. Если они вам нужны, придётся реализовывать их поддержку самостоятельно. Также надо всегда помнить, что при количестве элементов порядка тысячи, асимптотические показатели скорости ещё не вполне вступили в силу и теоретически более быстрые структуры данных на практике могут оказаться более медленными. Так, например, скорость поиска в КЧД и массиве с пресортировкой до 5000-7000 практически одинакова. Так же надо заметить, что тестирование производилось на объектах относительно малого размера (8 байт), сравнимого с размером указателя (4 байта). Все виды массивов сортированных подразумевают весьма интенсивное копирование элементов, в то время как деревья работают с указателями. При размере элемента, на порядки превышающем размеры указателя, акценты сместятся весьма значительно. Например, ниже приведены результаты испытания с ключом типа int (32-x битное целое) и битовыми данными размером в 256 байт.
| Количество элементов | ДДП | КЧД | Постоянно сортированный массив | Не сортированный массив | Массив с постсортировкой |
| 1000 | 5868 (1000) | 1663 (17) | 1430 | 1154 | 1035 |
| 2000 | 140888 (2000) | 3694 (19) | 3476 | 2460 | 2808 |
| 3000 | 368748 (3000) | 5815 (20) | 5372 | 3848 | 4382 |
| 4000 | 721328 (4000) | 7271 (21) | 7274 | 5175 | 6035 |
| 5000 | 1208373 (5000) | 9349 (22) | 9247 | 6670 | 7619 |
| 6000 | 1752135 (6000) | 11395 (22) | 11046 | 7778 | 9168 |
| 7000 | 2501167 (7000) | 13503 (23) | 13327 | 9378 | 10764 |
| 8000 | 3334948 (8000) | 15753 (23) | 18222 | 12560 | 15267 |
| 9000 | 4266560 (9000) | 21600 (24) | 20564 | 15391 | 17430 |
| 10000 | 5421499 (10000) | 24105 (24) | 24064 | 17152 | 19341 |
Таблица 7. Добавление элемента (возрастающие ключи)
| Количество элементов | ДДП | КЧД | Постоянно сортированный массив | Не сортированный массив | Массив с постсортировкой |
| 1000 | 4289 | 132 | 242 | 1621 | 230 |
| 2000 | 134074 | 303 | 605 | 6903 | 530 |
| 3000 | 359985 | 457 | 961 | 24268 | 806 |
| 4000 | 706129 | 787 | 1336 | 27610 | 1121 |
| 5000 | 1183405 | 959 | 1736 | 44660 | 1516 |
| 6000 | 1730699 | 1116 | 2138 | 69068 | 1841 |
| 7000 | 2462759 | 1344 | 2494 | 103158 | 2251 |
| 8000 | 3293519 | 1565 | 2871 | 159274 | 2617 |
| 9000 | 4215750 | 1840 | 3284 | 278697 | 2923 |
| 10000 | 5361524 | 2060 | 3698 | 513268 | 3303 |
Таблица 8. Поиск элемента (возрастающие ключи)
| Количество элементов | ДДП | КЧД | Постоянно сортированный массив | Не сортированный массив | Массив с постсортировкой |
| 1000 | 502 | 583 | 115640 | 131837 | 186703 |
| 2000 | 1181 | 1152 | 1604342 | 1574484 | 1592896 |
| 3000 | 1602 | 1580 | 4616940 | 4653355 | 4604626 |
| 4000 | 2075 | 2537 | 8966113 | 8999484 | 8978279 |
| 5000 | 2689 | 3007 | 14848795 | 14851393 | 14822206 |
| 6000 | 3574 | 3836 | 21572736 | 21473162 | 21676597 |
| 7000 | 4129 | 4432 | 30384061 | 29938188 | 30409709 |
| 8000 | 4898 | 5424 | 39013182 | 39342862 | 39341616 |
| 9000 | 5086 | 6368 | 50197296 | 49946077 | 50320092 |
| 10000 | 6279 | 6372 | 63020912 | 62049584 | 62564125 |
Таблица 9. Удаление элемента по ключу (возрастающие ключи)
| Количество элементов | ДДП | КЧД | Постоянно сортированный массив | Не сортированный массив | Массив с постсортировкой |
| 1000 | 1903 (24) | 2072 (12) | 57991 | 1418 | 5448 |
| 2000 | 4532 (25) | 4739 (14) | 479463 | 3107 | 13907 |
| 3000 | 7747 (26) | 7819 (15) | 1727433 | 4992 | 22440 |
| 4000 | 10348 (29) | 10664 (15) | 3616654 | 6733 | 33905 |
| 5000 | 13064 (29) | 13652 (16) | 6141684 | 8314 | 43768 |
| 6000 | 16530 (31) | 16713 (16) | 9214638 | 10191 | 53619 |
| 7000 | 19305 (31) | 19642 (16) | 12981887 | 11904 | 61301 |
| 8000 | 23140 (32) | 23329 (16) | 17388765 | 13785 | 75968 |
| 9000 | 26051 (32) | 26378 (16) | 21935279 | 15335 | 92007 |
| 10000 | 29450 (32) | 29448 (16) | 27053495 | 17075 | 90155 |
Таблица 10. Добавление элемента (случайные ключи)
| Количество элементов | ДДП | КЧД | Постоянно сортированный массив | Не сортированный массив | Массив с постсортировкой |
| 1000 | 185 | 150 | 266 | 1613 | 274 |
| 2000 | 695 | 359 | 719 | 6974 | 724 |
| 3000 | 1044 | 586 | 1193 | 15561 | 1245 |
| 4000 | 2186 | 823 | 1694 | 27675 | 1703 |
| 5000 | 2701 | 1106 | 2234 | 44905 | 2314 |
| 6000 | 3898 | 1496 | 2874 | 71549 | 2871 |
| 7000 | 4883 | 1889 | 3464 | 109554 | 3371 |
| 8000 | 4186 | 2183 | 4060 | 165605 | 4077 |
| 9000 | 6760 | 2771 | 4696 | 281860 | 4622 |
| 10000 | 7291 | 3201 | 5372 | 514893 | 5384 |
Таблица 11. Поиск элемента (случайные ключи)
| Количество элементов | ДДП | КЧД | Постоянно сортированный массив | Не сортированный массив | Массив с постсортировкой |
| 1000 | 1235 | 1115 | 54929 | 111088 | 62794 |
| 2000 | 3042 | 2978 | 557875 | 1596298 | 558580 |
| 3000 | 4641 | 4703 | 1837401 | 4730623 | 1841029 |
| 4000 | 7531 | 6494 | 3830510 | 9008129 | 3833983 |
| 5000 | 9497 | 8788 | 6675616 | 14599142 | 6626964 |
| 6000 | 12018 | 10922 | 10270460 | 21832592 | 10315160 |
| 7000 | 14605 | 14376 | 14808484 | 29779691 | 14618091 |
| 8000 | 15876 | 16070 | 19927348 | 39932636 | 19946118 |
| 9000 | 20043 | 19079 | 25347571 | 49928153 | 25384886 |
| 10000 | 22117 | 21860 | 32049086 | 61766884 | 32072537 |
Таблица 12. Удаление элемента по ключу (случайные ключи)
Хорошо видно, что при увеличенном размере элемента деревья догоняют, а то и значительно обгоняют массивы. Таким образом, очевидно, что выбор структуры данных сильно зависит от предполагаемого количества элементов и их размера. Напоследок хотелось бы сказать, что правильный выбор структуры данных является одним из основных моментов, определяющих производительность программы. Поэтому подходить к выбору надо осторожно, продумав все возможные - как наиболее вероятные, так и наихудшие случаи.
|
из
5.00
|
Обсуждение в статье: Удаление вершины из КЧД |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы