 |
Главная |


экспериментальных данных
|
из
5.00
|
2.1. Задание 1. Определение ошибки воспроизводимости эксперимента.
Результаты измерений в каждой точке 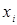 плана эксперимента диспергируют относительно группового среднего:
плана эксперимента диспергируют относительно группового среднего: 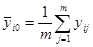 , где
, где 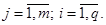 В данной работе экспериментальных точек
В данной работе экспериментальных точек 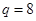 , а число повторных опытов в точках
, а число повторных опытов в точках 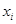 одинаковое
одинаковое 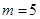 .
.
В каждой 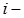 группе данных определяем средние значения
группе данных определяем средние значения 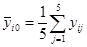 , а затем несмещенную оценку дисперсии воспроизводимости
, а затем несмещенную оценку дисперсии воспроизводимости 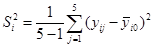 и оценку ошибки воспроизводимости
и оценку ошибки воспроизводимости 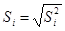 .Промежуточные результаты вычислений сведем в таблицу 1.
.Промежуточные результаты вычислений сведем в таблицу 1.
Таблица 1.
Результаты расчета внутригрупповых средних и дисперсий.
| Числовые характеристики групп | Обозначение i- уровней факториального признака Х | |||||||
| 
| 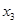
| 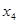
| 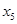
| 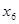
| 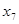
| 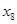
| |
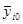
| 8,16 | 6,16 | 4,28 | 2,8 | 2,16 | 2,88 | 3,56 | |
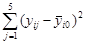
| 1,312 | 1,312 | 0,852 | 0,74 | 0,408 | 0,4 | 0,752 | 0,788 |
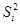
| 0,33 | 0,33 | 0,85 | 0,74 | 0,41 | 0,40 | 0,75 | 0,79 |
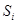
| 0,57 | 0,57 | 0,92 | 0,86 | 0,64 | 0,63 | 0,867 | 0,888 |
Ошибки воспроизводимости эксперимента (также и дисперсии) в каждой группе могут различатся. Поэтому, прежде чем вычислить усредненную внутригрупповую дисперсию нужно совокупность вычисленных оценок дисперсий проверить на однородность.
Для проверки нескольких ( 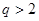 ) несмещенных оценок дисперсий на однородность, определяемых при одинаковых степенях свободы (
) несмещенных оценок дисперсий на однородность, определяемых при одинаковых степенях свободы ( 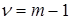 ) используют
) используют 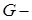 статистику Кокрена,
статистику Кокрена, 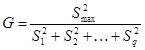 для выбранного критического значения
для выбранного критического значения 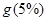 или
или 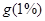 .
.
Выбрав 5%- уровень значимости, по соответствующей ему таблице для 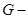 статистики, построенной по
статистики, построенной по 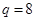 независимым оценкам дисперсии, каждая из которых обладает
независимым оценкам дисперсии, каждая из которых обладает 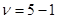 степенями свободы, определим критическое (табличное) значение
степенями свободы, определим критическое (табличное) значение 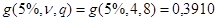 .
.
В нашей задаче эмпирическое значение G – статистики:
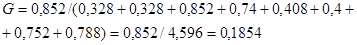 .
.
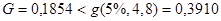 , а это значит, что вычисленные дисперсии в группах однородны (статистически неразличимы), следовательно, их можно усреднить
, а это значит, что вычисленные дисперсии в группах однородны (статистически неразличимы), следовательно, их можно усреднить 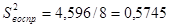 . Окончательный результат: несмещенная оценка ошибки воспроизводимости эксперимента
. Окончательный результат: несмещенная оценка ошибки воспроизводимости эксперимента 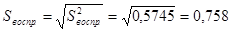 . («чистая» ошибка). При неудачном выборе выбора модели, а также, если не включены в модель значимые переменные ошибка воспроизводимости возрастает, так как в этих случаях растет доля случайных возмущений на результаты эксперимента.
. («чистая» ошибка). При неудачном выборе выбора модели, а также, если не включены в модель значимые переменные ошибка воспроизводимости возрастает, так как в этих случаях растет доля случайных возмущений на результаты эксперимента.
Примечание: Если для данного (5%) уровня значимости 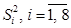 окажутся неоднородными, т.е. получится, что
окажутся неоднородными, т.е. получится, что 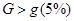 , то можно «ослабить» проверку, выполнив ее на 1%-уровне значимости, где табличное значение
, то можно «ослабить» проверку, выполнив ее на 1%-уровне значимости, где табличное значение 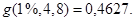 Если все же для 1%-уровня значимости дисперсии будут неоднородны, то следует проверить результаты эксперимента в точках и расчет
Если все же для 1%-уровня значимости дисперсии будут неоднородны, то следует проверить результаты эксперимента в точках и расчет 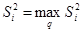 (возможно завышенный результат является «выбросом» неслучайным). В общем усреднять можно только однородные дисперсии.
(возможно завышенный результат является «выбросом» неслучайным). В общем усреднять можно только однородные дисперсии.
2.2. Задание 2 Дисперсионный анализ результатов эксперимента.
Цель: Определить степень детерминации объекта исследования.
Будем исходить из основного дисперсионного тождества: 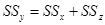 , т.е. сумма
, т.е. сумма 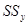 квадратов отклонений результатов эксперимента
квадратов отклонений результатов эксперимента 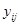 от общего среднего
от общего среднего 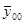 распадается на межгрупповую
распадается на межгрупповую 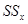 и внутригрупповую
и внутригрупповую 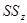 составляющие. Формулы расчета
составляющие. Формулы расчета 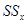 ,
, 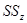 , и оценки получаемых дисперсий
, и оценки получаемых дисперсий 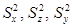 с учетом соответствующих для них степеней свободы
с учетом соответствующих для них степеней свободы 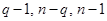 , где
, где 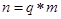 ,
, 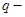 число групп,
число групп, 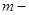 число данных в группе, сведены для удобства выполнения дисперсионного анализа в общую таблицу:
число данных в группе, сведены для удобства выполнения дисперсионного анализа в общую таблицу:
| Источник рассеяния | Число степеней свободы | Сумма квадратов отклонений | Оценка дисперсии |
| Между уровнями | 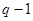
| 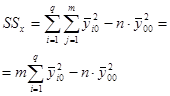
| 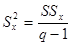
|
| Внутри уровней | 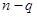
| 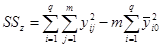
| 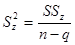
|
| Суммы | 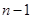
| 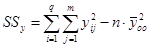
| 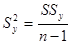
|
Общее среднее для всех значений 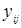 определим по исходным данным или по данным табл.1 (строка групповых средних ).
определим по исходным данным или по данным табл.1 (строка групповых средних ). 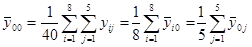
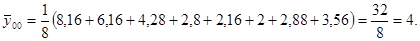
Для удобства и наглядности дальнейших вычислений составим табл.2, в которой представим квадраты исходных данных, а также квадраты средних значений в  -группах. Тогда удобно будет контролировать нужные суммы в строке, выделив для них последний столбец этой таблицы.
-группах. Тогда удобно будет контролировать нужные суммы в строке, выделив для них последний столбец этой таблицы.
Таблица 2.
Квадраты исходных значений и квадраты средних
| Квадраты значений | Значения уровней факториального признака Х | Суммы | ||||||||
| Квадраты откликов | 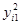
| 73,96 | 33,64 | 7,84 | 3,24 | 5,76 | 12,96 | 171,40 | ||
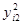
| 54,76 | 46,24 | 12,96 | 3,24 | 1,96 | 1,44 | 17,64 | 147,24 | ||
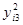
| 60,84 | 29,16 | 10,24 | 10,24 | 2,56 | 4,84 | 21,16 | 148,04 | ||
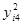
| 77,44 | 38,44 | 17,64 | 6,76 | 7,84 | 14,44 | 5,76 | 184,32 | ||
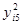
| 67,24 | 43,56 | 29,16 | 4,84 | 3,24 | 12,96 | 169,00 | |||
Суммы 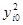
| 334,3 | 191,1 | 95,00 | 42,16 | 24,96 | 21,6 | 44,48 | 66,52 | 820,00 | |
Квадраты средних 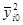
| 66,59 | 37,95 | 18,32 | 7,84 | 4,666 | 8,295 | 12,68 | 160,323 |
Сумму квадратов средних значений в 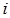 - группах определим по данным табл.2, просуммировав элементы последней строки:
- группах определим по данным табл.2, просуммировав элементы последней строки:
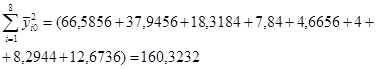
Сумму квадратов всех значений 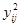 определим по данным табл.2 , просуммировав элементы последнего столбца (не включая собственно сумму, равную 820, и элемент последнего результата 160,3232).
определим по данным табл.2 , просуммировав элементы последнего столбца (не включая собственно сумму, равную 820, и элемент последнего результата 160,3232). 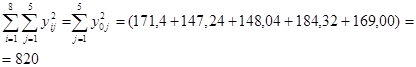 .
.
Примечание. Проверить правильность вычисления суммы 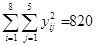 можно используя
можно используя 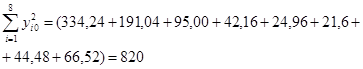
Теперь выполним основные расчеты для дисперсионного анализа: Определим суммы квадратов отклонений 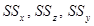 и соответствующие им оценки дисперсий .
и соответствующие им оценки дисперсий . 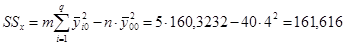 ;
; 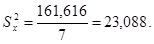
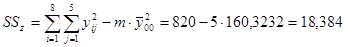 ;
; 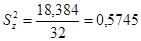
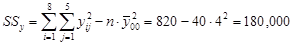 .
. 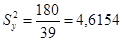 .
.
Указание Обязательно следует проверить выполнение основного дисперсионного тождества: 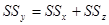 , т.е. 180=161,616+18,384, а также тождества для степеней свободы
, т.е. 180=161,616+18,384, а также тождества для степеней свободы 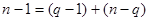 , т.е. 39=7+32.
, т.е. 39=7+32.
Степень детерминации объекта исследования определяется корреляционным отношением: 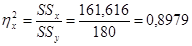 - это доля влияния факториального признака
- это доля влияния факториального признака 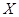 на результативный признак
на результативный признак 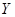 , т.е. 89,79 % Аналогично определяется доля воздействия на объект случайных возмущений (доля «чистой» ошибки):
, т.е. 89,79 % Аналогично определяется доля воздействия на объект случайных возмущений (доля «чистой» ошибки): 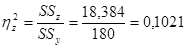 . При этом
. При этом 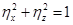
Достоверность полученного вывода проверяется по 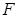 - критерию Фишера. Эмпирический
- критерию Фишера. Эмпирический 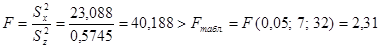 , т.е. на уровне значимости
, т.е. на уровне значимости 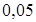 подтверждается гипотеза о значиом влиянии (89,79 %) факториального признака на результативный признак объекта исследования. На следующем этапе нужно подобрать модель
подтверждается гипотеза о значиом влиянии (89,79 %) факториального признака на результативный признак объекта исследования. На следующем этапе нужно подобрать модель 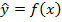 , которая наилучшим образом объясняла бы полученные в эксперименте данные и чтобы остаточная сумма квадратов, равная
, которая наилучшим образом объясняла бы полученные в эксперименте данные и чтобы остаточная сумма квадратов, равная 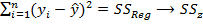 .
.
Поиск зависимости целесообразно начинать с линейной модели, используя корреляционные и регрессионные методы анализа.
2.3. Задание 3. Оценка линейной корреляции экспериментальных данных
Для выполнения этого и следующего задания удобно представить таблицу исходных данных в виде столбцов  , затем расширить ее новыми столбцами произведений вида
, затем расширить ее новыми столбцами произведений вида  , и в завершение линейного моделирования нужны будут столбцы предсказываемых результатов
, и в завершение линейного моделирования нужны будут столбцы предсказываемых результатов 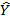 , остатков
, остатков 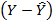 и их квадратов
и их квадратов 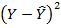 . Значения элементов для перечисленных выше столбцов приведены в табл. 3.
. Значения элементов для перечисленных выше столбцов приведены в табл. 3.
Корреляционный анализ позволят решить две основные задачи
1. Определить степень тесноты связи между столбцами значений изучаемых признаков
2. Установить параметры для простейшей (линейной) формы, связывающей изучаемые признаки.
Для решения первой задачи нужно вычислить оценку линейного коэффициента корреляции 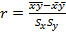 , где оценки стандартных ошибок
, где оценки стандартных ошибок
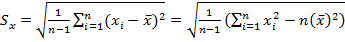
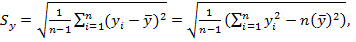 а затем проверить гипотезу Н0: М(r)
а затем проверить гипотезу Н0: М(r) 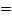 0, используя при n >30 t - статистику Стьюдента
0, используя при n >30 t - статистику Стьюдента 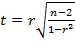 для числа степеней свободы
для числа степеней свободы 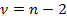 и выбранного уровня значимости
и выбранного уровня значимости 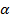 .
.
Используя итоговые данные табл. 3 (две последние строки) найдем оценки
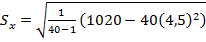 =
= 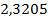 ,
,
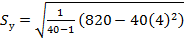 =
= 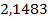 ,
, 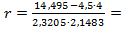 - 0,71. При условии
- 0,71. При условии 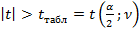 , где
, где 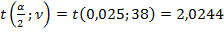 , в нашем случае Н0 гипотезу отвергаем, т.е. М(r)
, в нашем случае Н0 гипотезу отвергаем, т.е. М(r) 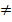 0, так как при
0, так как при 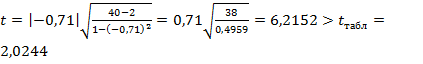 ,
,
Таблица 3.
Предварительная обработка данных
для линейной аппроксимации
| № | X | Y | Y*Y | X*Y | X*X | 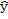
| Res | Res^2 |
| 8,6 | 73,96 | 8,6 | 6,3364 | 2,2636 | 5,12388496 | |||
| 7,4 | 54,76 | 7,4 | 6,3364 | 1,0636 | 1,13124496 | |||
| 7,8 | 60,84 | 7,8 | 6,3364 | 1,4636 | 2,14212496 | |||
| 8,8 | 77,44 | 8,8 | 6,3364 | 2,4636 | 6,06932496 | |||
| 8,2 | 67,24 | 8,2 | 6,3364 | 1,8636 | 3,47300496 | |||
| 5,8 | 33,64 | 11,6 | 5,6688 | 0,1312 | 0,01721344 | |||
| 6,8 | 46,24 | 13,6 | 5,6688 | 1,1312 | 1,27961344 | |||
| 5,4 | 29,16 | 10,8 | 5,6688 | -0,2688 | 0,07225344 | |||
| 6,2 | 38,44 | 12,4 | 5,6688 | 0,5312 | 0,28217344 | |||
| 6,6 | 43,56 | 13,2 | 5,6688 | 0,9312 | 0,86713344 | |||
| 5,0012 | -0,0012 | 0,00000144 | ||||||
| 3,6 | 12,96 | 10,8 | 5,0012 | -1,4012 | 1,96336144 | |||
| 3,2 | 10,24 | 9,6 | 5,0012 | -1,8012 | 3,24432144 | |||
| 4,2 | 17,64 | 12,6 | 5,0012 | -0,8012 | 0,64192144 | |||
| 5,4 | 29,16 | 16,2 | 5,0012 | 0,3988 | 0,15904144 | |||
| 2,8 | 7,84 | 11,2 | 4,3336 | -1,5336 | 2,35192896 |
Продолжение табл. 3
| № | X | Y | Y*Y | X*Y | X*X |
| Res | Res^2 |
| 1,8 | 3,24 | 7,2 | 4,3336 | -2,5336 | 6,41912896 | |||
| 3,2 | 10,24 | 12,8 | 4,3336 | -1,1336 | 1,28504896 | |||
| 4,3336 | -0,3336 | 0,11128896 | ||||||
| 2,2 | 4,84 | 8,8 | 4,3336 | -2,1336 | 4,55224896 | |||
| 1,8 | 3,24 | 3,666 | -1,866 | 3,481956 | ||||
| 1,4 | 1,96 | 3,666 | -2,266 | 5,134756 | ||||
| 3,666 | -0,666 | 0,443556 | ||||||
| 2,6 | 6,76 | 3,666 | -1,066 | 1,136356 | ||||
| 3,666 | -1,666 | 2,775556 | ||||||
| 2,4 | 5,76 | 14,4 | 2,9984 | -0,5984 | 0,35808256 | |||
| 1,2 | 1,44 | 7,2 | 2,9984 | -1,7984 | 3,23424256 | |||
| 1,6 | 2,56 | 9,6 | 2,9984 | -1,3984 | 1,95552256 | |||
| 2,8 | 7,84 | 16,8 | 2,9984 | -0,1984 | 0,03936256 | |||
| 2,9984 | -0,9984 | 0,99680256 | ||||||
| 3,6 | 12,96 | 25,2 | 2,3308 | 1,2692 | 1,61086864 | |||
| 2,3308 | 0,6692 | 0,44782864 | ||||||
| 2,2 | 4,84 | 15,4 | 2,3308 | -0,1308 | 0,01710864 |
Продолжение табл. 3
| № | X | Y | Y*Y | X*Y | X*X |
| Res | Res^2 |
| 3,8 | 14,44 | 26,6 | 2,3308 | 1,4692 | 2,15854864 | |||
| 1,8 | 3,24 | 12,6 | 2,3308 | -0,5308 | 0,28174864 | |||
| 1,6632 | 1,3368 | 1,78703424 | ||||||
| 4,2 | 17,64 | 33,6 | 1,6632 | 2,5368 | 6,43535424 | |||
| 4,6 | 21,16 | 36,8 | 1,6632 | 2,9368 | 8,62479424 | |||
| 2,4 | 5,76 | 19,2 | 1,6632 | 0,7368 | 0,54287424 | |||
| 3,6 | 12,96 | 28,8 | 1,6632 | 1,9368 | 3,75119424 | |||
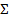
| 579,8 | 159,992 | 86,400 | |||||
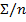
| 4,5 | 20,5 | 14,495 | 25,5 | 3,998 | 2,16 |
Для решения второй задачи выбирается модель вида 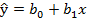 , параметры которой
, параметры которой 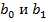 определяются методом наименьших квадратов (МНК):
определяются методом наименьших квадратов (МНК):
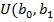 )=
)= 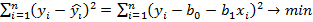 .
.
Откуда
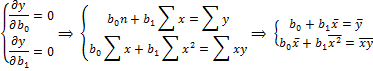
При условии, 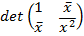 =
= 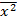 -
- 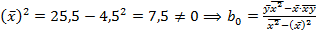 ;
; 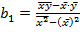 .
.
В нашем случае:
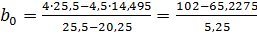 = 7,004 и
= 7,004 и 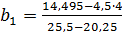 =
= 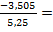 -0,66761.
-0,66761.
Общий вывод по заданию 3: разработана линейная модель вида 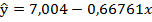 со степенью детерминации
со степенью детерминации
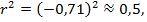 т.е. линейная модель за счет признака х объясняет ≈ 50% дисперсии результативного признака у.
т.е. линейная модель за счет признака х объясняет ≈ 50% дисперсии результативного признака у.
2.4. Задание 4. Выполнение регрессионного анализа линейной по параметрам модели.
Регрессионный анализ предполагает решение двух основных задач по качеству разработанной модели:
1. Определить ошибки вычисленных параметров модели;
2. Проверить модель на адекватность, т.е. оценить ошибку модели при интерполировании и прогнозировании результатов.
Решение первой задачи: оценки коэффициентов регрессии, вычисляемые на основе МНК, в матричной форме имеют вид 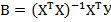 , где для модели вида
, где для модели вида
, вектор 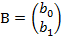 , X – входная матрица (условия эксперимента), имеет единичный столбец (для параметра
, X – входная матрица (условия эксперимента), имеет единичный столбец (для параметра 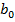 ) и столбец значений
) и столбец значений 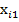 (для параметра
(для параметра 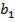 ), У - столбец результатов
), У - столбец результатов 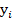 ,
, 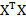 - матрица ковариации входных признаков. Тогда
- матрица ковариации входных признаков. Тогда 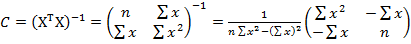 , где
, где 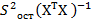 – матрица дисперсий-ковариаций коэффициентов регрессии,
– матрица дисперсий-ковариаций коэффициентов регрессии,
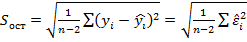 – оценка ошибки модели. Откуда дисперсии коэффициентов регрессии (элементы
– оценка ошибки модели. Откуда дисперсии коэффициентов регрессии (элементы 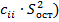 ,
, 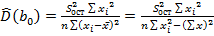 и
и 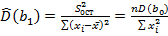 , т.е.
, т.е. 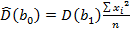 .
.
В нашем случае 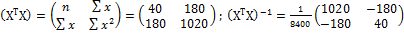 , где
, где 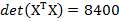 ,
,
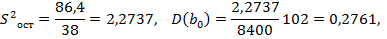
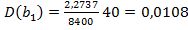
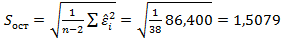 ,
, 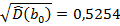 ,
, 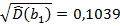
Значимость коэффициентов регрессии оценивается по t – статистике Стьюдента: 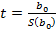 и
и 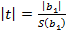 , где критическое (табличное) значение
, где критическое (табличное) значение 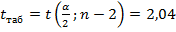 , n-2 – число степеней свободы, при котором определялась оценка ошибки
, n-2 – число степеней свободы, при котором определялась оценка ошибки 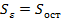 , – уровень значимости.
, – уровень значимости.
В нашем случае 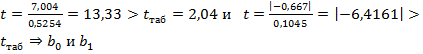 - статистически значимы при
- статистически значимы при 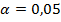 , для которого определено
, для которого определено 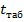 .
.
Построим доверительную оценку вычисленных коэффициентов регрессии:
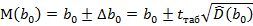 =7,004
=7,004 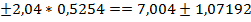 , аналогично,
, аналогично,
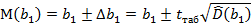 = - 0,66761
= - 0,66761 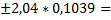 -0,66761
-0,66761 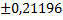 .
.
Примечание: в общем случае 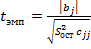 , где
, где 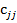 - элементы главной диагонали обратной матрицы
- элементы главной диагонали обратной матрицы 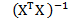 , j=0,1,… , где j- индекс определяемых коэффициентов регрессии;
, j=0,1,… , где j- индекс определяемых коэффициентов регрессии; 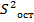 .- остаточная дисперсия.
.- остаточная дисперсия.
Решение второй задачи: исходя из дисперсионного тождества 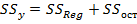 . В нашем случае
. В нашем случае
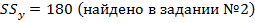
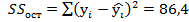 .
.
Откуда 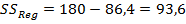 .
.
Адекватность модели проверяем по F – критерию Фишера 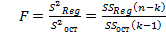 , где
, где 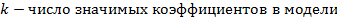
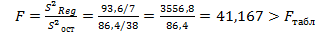 , где
, где
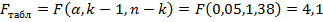 . Отсюда следует, что модель адекватна. Качество полученной линейной модели оценим по её степени детерминации:
. Отсюда следует, что модель адекватна. Качество полученной линейной модели оценим по её степени детерминации:
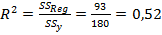 .
.
В завершение задания 4 построим график линейной модели в пространстве экспериментальных точек  .
.
Общий вывод по заданию 4. Построенная линейная модель адекватна, имеет статистически значимые коэффициенты регрессии. Очевидно также, что степень детерминации для линейной модели 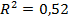 еще очень далека до степени детерминируемости данного объекта
еще очень далека до степени детерминируемости данного объекта 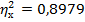 (около 90%) (см п.2.1)
(около 90%) (см п.2.1)
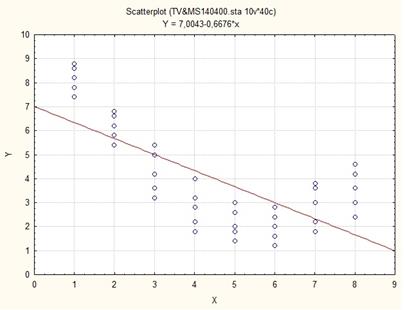
Рис.1 Линейная модель в пространстве нелинейного корреляционного поля экспериментальных точек.
2.5 Задание 5. Регрессионный анализ линейный по параметрам нелинейной модели.
В этом задании в качестве модели для аппроксимации эксперимента будем использовать квадратичную функцию вида: 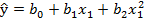 .
.
Для выполнения этого задания рекомендуется использовать какую – либо программу для ПК, которая содержит модуль «Множественная регрессия», например, EXCEL, STATISNICA, STADIA, SPSS, STATGRAPHICS и др. Модули (подпрограммы) типа «Multiple Regression» (множественная регрессия) работают в среде Windows имеют схожий интерфейс, включающий Стартовую панель и панель Выдачи результатов с большим числом опций для всестороннего анализа регрессионной модели.
В стартовой панели следует лишь задать входные переменные (матрица  Х), обозначенные как independent variables (независимые переменные), и одну выходную переменную (вектор У), обозначенный как dependent variable (зависимая переменная). После чего все расчеты выполняются автоматически и по желанию пользователя можно воспроизвести нужные таблицы и графики, отражающие в полной мере вычисленные результаты регрессионного анализа в соответствии с условием и назначенным режимом доступным для используемой программы.
Х), обозначенные как independent variables (независимые переменные), и одну выходную переменную (вектор У), обозначенный как dependent variable (зависимая переменная). После чего все расчеты выполняются автоматически и по желанию пользователя можно воспроизвести нужные таблицы и графики, отражающие в полной мере вычисленные результаты регрессионного анализа в соответствии с условием и назначенным режимом доступным для используемой программы.
Особо следует обратить внимание, что для построения и регрессионного анализа модели вида входными переменными являются 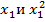 (матрица Х должна содержать два столбца
(матрица Х должна содержать два столбца 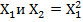 ), т.е. столбец
), т.е. столбец 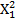 линейный по параметрам модели используется как новая независимая переменная (новый регрессор).
линейный по параметрам модели используется как новая независимая переменная (новый регрессор).
Отметим также, что единичный столбец 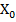 , предусмотренный алгоритмом для вычисления параметра , в матрицу данных Х не вносится, но учитывается в программах для линейной по параметрам регрессии автоматически.
, предусмотренный алгоритмом для вычисления параметра , в матрицу данных Х не вносится, но учитывается в программах для линейной по параметрам регрессии автоматически.
В отчет по заданию 5 необходимо включить следующие материалы:
1. Корреляционную матрицу признаков, используемых при разработке линейной по параметрам нелинейной регрессии.
2. Итоговую таблицу вычисленных параметров с оценкой их статистической значимости.
3. Таблицу результатов дисперсионного анализа нелинейной регрессионной модели.
4. График нелинейного уравнения регрессии в пространстве экспериментальных точек.
5. Гистограмму распределения остатков с оценкой качественных характеристик (асимметрия, эксцесс) отклонение распределения от нормального.
Примечание. Задание 5 можно также выполнить (по желанию студента) в «ручном» режиме, например, с использованием калькулятора. Для этого следует получить (исходя из МНК), соответствующую систему нормальных уравнений и решить её относительно искомых параметров 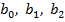 .
.
Согласно МНК: 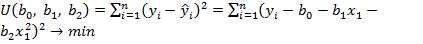
Приравнивая к нулю частные производные по искомым параметрам получим нормальную систему уравнений: 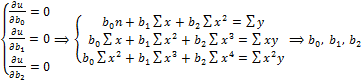
Для выполнения этого задания «вручную» следует дополнить исходную таблицу данных (см. табл. 3) новыми столбцами 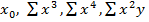 , и в завершении нелинейного моделирования вновь понадобятся столбцы предсказанных результатов
, и в завершении нелинейного моделирования вновь понадобятся столбцы предсказанных результатов 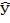 , новых остатков
, новых остатков 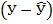 и их квадратов
и их квадратов 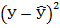 .
.
Все последующие расчеты выполняются по схеме подробно изложенной в заданиях 3 и 4 для линейной модели.
Формат представления отчета по нелинейной регрессии, включая комментарии и выводы по каждому пункту регрессионного анализа, следующий.
1. Корреляционная матрица использованных признаков при моделировании нелинейной регрессии.
Таблица 4.
Матрица корреляций.
| x | XX | Y | |
| x | 1,000000 | 0,976187 | -0,721111 |
| XX | 0,976187 | 1,000000 | -0,571609 |
| Y | -0,721111 | -0,571609 | 1,000000 |
Выводы:
1) Все наблюдаемые в таблице коэффициенты корреляции r – статистически значимы на уровне значимости 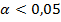 , так как
, так как 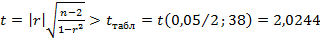 .
.
2) Связь отклика 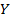 с признаками
с признаками 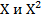 отрицательная.
отрицательная.
3) Связь входных переменных 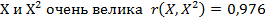 , т.е. намного сильнее, чем связь каждого регрессора с откликом (по модулю), что отражается на изменении алгебраического знака, как правило, менее сильного регрессора. (см. таблицу 4)
, т.е. намного сильнее, чем связь каждого регрессора с откликом (по модулю), что отражается на изменении алгебраического знака, как правило, менее сильного регрессора. (см. таблицу 4)
- Итоговая таблица вычисленных параметров с оценкой их статистической значимости.
Таблица 5.
Параметры нелинейной регрессии.
| Beta | Std.Err. | B | Std.Err. | t(37) | p-level | |
| Intercept | 11,24 | 0,45201 | 24,867 | 0,000000 | ||
| Х | -3,46617 | 0,248918 | -3,209 | 0,23045 | -13,92 | 0,000000 |
| XX | 2,81202 | 0,248918 | 0,282 | 0,025 | 11,297 | 0,000000 |
Общий вид модели:
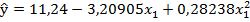
Вывод: линия регрессии в полной мере аппроксимирует зависимость «выхода» от «входов». Все параметры модели  статистически значимы:
статистически значимы:
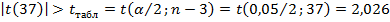 .
.
- Таблицу результатов дисперсионного анализа нелинейной регрессионной модели.
Таблица 6.
Дисперсионный анализ нелинейной дисперсии
| Sums of SS | df | Mean | F | p-level | |
| Regress. | 160,5810 | 80,29048 | 152,9811 | 0,000000 | |
| Residual | 19,4190 | 0,52484 | |||
| Total | 180,0000 |
Вывод: Коэффициент детерминации модели, вычисляемый как корреляционное отношение 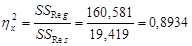 , т.е. эффекты линейный
, т.е. эффекты линейный 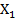 и квадратичный
и квадратичный 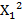 объясняют дисперсию результативного признака У на 89,34%, что очень близко к предельному значению 89,79% детерминируемости данного объекта исследования (см. п. 2.2).
объясняют дисперсию результативного признака У на 89,34%, что очень близко к предельному значению 89,79% детерминируемости данного объекта исследования (см. п. 2.2).
4. График нелинейного уравнения регрессии в пространстве экспериментальных точек.
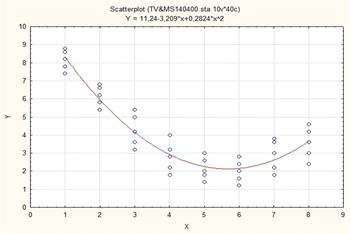
Рис. 2. График нелинейной регрессии в пространстве.
Вывод: График зависимости отражает алгебраические знаки поведения регрессора (линейный параметр отрицательный и положительный параметр квадратичного эффекта).
5. Гистограмма распределения остатков с оценкой качественных характеристик (асимметрия, эксцесс) отклонения распределения от нормального.
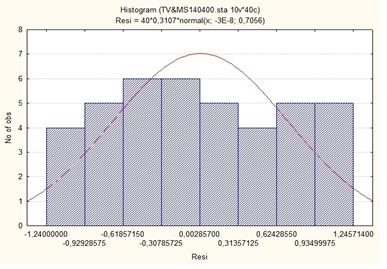
Рис.3.Гистограмма распределения остатков.
Числовые характеристики данных рис.3 приведены ниже:
| Параметры | Mean | Median | Mode | Minimum | Maximum | Variance | Skewness | Std.Err. | Kurtosis | Std.Err. |
| значения | -0,00 | -0,076667 | ,6485715 | -1,24000 | 1,245714 | 0,497924 | 0,069279 | 0,373783 | -1,12555 | 0,732600 |
Очевидно, что распределение остатков имеет некоторое отклонение от нормального закона в части эксцесса и в меньшей степени в части асимметрии (недостаточный объем выборки, малая плотность данных в центре распределения). На практике 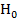 гипотезу об отсутствии As (асимметрия) и Ек (эксцесс) отвергают если
гипотезу об отсутствии As (асимметрия) и Ек (эксцесс) отвергают если 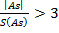 и
и 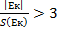 . В нашем случае соответственно
. В нашем случае соответственно 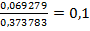 853<3 и
853<3 и 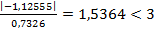 , т.е. достаточных оснований для отклонения
, т.е. достаточных оснований для отклонения  гипотезы нет.
гипотезы нет.
Обратим внимание, что качество аппроксимации нелинейного варианта по отношению к линейному оказалась значительно выше, так как коэффициент детерминации нелинейного варианта 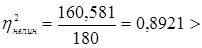
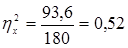 .
.
2.6. Задание 6. Определение числа наблюдений в подгруппах для их различимости с учетом ошибок  .
.
Данная задача возникает при утверждении, что средние результаты 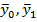 (оценки математических ожиданий
(оценки математических ожиданий 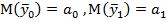 ) в обозначенных двух подгруппах статистически различимы. Это можно проверить при условии их однородности данных (см. п. 2.1.) и, если объемы этих подвыборок определены с учетом ошибки второго рода
) в обозначенных двух подгруппах статистически различимы. Это можно проверить при условии их однородности данных (см. п. 2.1.) и, если объемы этих подвыборок определены с учетом ошибки второго рода
