 |
Главная |


Лабораторная работа 6 Анализ финансово-экономических ситуаций с помощью методов теории вероятности и статистики
|
из
5.00
|
Цель работы: Освоить навыки работы со статистическими функциями Excel.
Порядок работы:
1. Запустите программу MS Excel 2010.
2. В открывшемся окне нажмите кнопку Новая книга для создания новой рабочей области. Щелкните по кнопке Создать.
3. В поле Имя файла (файл сохранить как) задайте имя вашей рабочей книги lab6_FIO (где FIO - ваши инициалы) и выберите диск D/папка студент/папка FIO и номер группы (созданная на первом занятии).
4. При этом откроется окно вашей рабочей книги.
Анализ финансово-экономических ситуаций сопровождается выполнением большого объёма разнообразных вычислений: модального значения и медианы, средних величин, дисперсии, ранга и персентили, квартили, квантили и др. Кроме того, в ходе анализа выполняются различные виды оценок, группировок, сравнений и сортировок эмпирических данных; нахождение минимального, максимального, среднего значения и ряд других операций. Корректное применение этих методов позволяет выявить функциональные закономерности в различных массовых социальных процессах, строить математические модели и др.
Табличные процессоры позволяют осуществить всё это многообразие видов аналитической работы с помощью встроенных функций (категория Статистические рис.34) и надстройки «Пакет анализа».
Рис.34. Мастер функций, категория Статистические
Применение статистических функций облегчает пользователю статистический анализ данных. Для того чтобы иметь возможность использовать все статистические функции, следует загрузить надстройку «Пакет анализа».
Ниже приведено описание некоторых наиболее распространенных статистических функций (по алфавиту), применяемых при анализе финансовых и экономических данных.
| Название | Описание |
| БИНОМ.ОБР | Возвращает наименьшее значение, для которого интегральное биномиальное распределение меньше или равно заданному. |
| БИНОМ.РАСП | Возвращает отдельное значение биномиального распределения. |
| ДИСП.В | Оценивает дисперсию по выборке. |
| ДИСП.Г | Вычисляет дисперсию для генеральной совокупности. |
| ДИСПА | Оценивает дисперсию по выборке, включая числа, текст и логические значения. |
| ДИСПРА | Вычисляет дисперсию для генеральной совокупности, включая числа, текст и логические значения. |
| КВАРТИЛЬ.ВКЛ | Возвращает квартиль множества данных. |
| КВАРТИЛЬ.ИСКЛ | Возвращает квартиль набора данных на основе значений процентиля от 0 до 1, исключая эти числа. |
| МАКС | Возвращает наибольшее значение в списке аргументов. |
| МЕДИАНА | Возвращает медиану заданных чисел. |
| МИН | Возвращает наименьшее значение в списке аргументов. |
| МОДА.НСК | Возвращает вертикальный массив из наиболее часто |
| встречающихся (повторяющихся) значений в массиве или диапазоне данных. | |
| МОДА.ОДН | Возвращает значение моды множества данных. |
| НОРМ.ОБР | Возвращает обратное нормальное распределение. |
| НОРМ.РАСП | Возвращает нормальную функцию распределения. |
| ПЕРЕСТ | Возвращает количество перестановок для заданного числа объектов. |
| ПРОЦЕНТИЛЬ.ВКЛ | Возвращает k-ую персентиль для значений диапазона. |
| ПРОЦЕНТРАНГ.ВКЛ | Возвращает процентную норму значения в множестве данных. |
| РАНГ.РВ | Возвращает ранг числа в списке чисел. |
| СРЗНАЧ | Возвращает среднее арифметическое аргументов. |
| СТАНДОТКЛОН.В | Оценивает стандартное отклонение по выборке. |
| СТАНДОТКЛОН.Г | Вычисляет стандартное отклонение по генеральной совокупности. |
| СЧЁТ | Подсчитывает количество чисел в списке аргументов. |
| СЧЁТЕСЛИ, | Подсчитывает количество ячеек в диапазоне, удовлетворяющих заданному условию. |
| СЧЁТЕСЛИМН | Подсчитывает количество ячеек внутри диапазона, удовлетворяющих нескольким условиям. |
| СЧИТАТЬПУСТОТЫ | Подсчитывает количество пустых ячеек в диапазоне |
| ТЕНДЕНЦИЯ | Возвращает значения в соответствии с линейным трендом. |
| ЧАСТОТА | Возвращает распределение частот в виде вертикального массива. |
Разберем несколько примеров, в которых применяются приведенные функции.
Пример 19.В супермаркете есть три точки для размещения товаров. На каждой точке размещаются товары одного вида. Сколько способов существует для размещения товаров пяти видов?
Алгоритм решения.
В вашей рабочей книге lab6_FIO, откройте Лист 1.
Размещениями называются конечные упорядоченные множества из элементов данного множества. Для вычисления числа размещений в библиотеке функций табличного процессора есть специальная функция ПЕРЕСТ (число; число_выбранных), относящаяся к категории статистических функций (Рис. 35). Аргумент «число» в данной задаче представляет «Количество видов товаров», аргумент «число выбранных» – «Количество точек для размещения товаров».
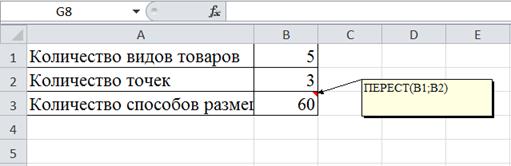
Рис. 35. Функция ПЕРЕСТ
Пример 20.Дан набор случайных значений дискретной случайной величины 10, 14, 5, 6, 18, 6, 13. Требуется вычислить математическое ожидание, дисперсию, стандартное отклонение, медиану, моду, верхнюю квартиль и квантиль со значением 0,1.
Алгоритм решения.
В вашей рабочей книге lab6_FIO, откройте Лист 2.
Речь идет о выборочной совокупности, т.е. случайно выбранной из генеральной совокупности некоторой ее части. Исходя из этого, будем применять функции, относящиеся именно к выборочной совокупности (рис.36).
Математическое ожидание –среднее значение, одна из важнейших характеристик распределения вероятностей случайной величины. Определяется по функции СРЗНАЧ(число1; число2 …).
Дисперсия(от лат. dispersio – рассеяние), в математической статистике и теории вероятностей, наиболее употребительная мера рассеивания, т. е. отклонения от среднего. Для выборочной совокупности дисперсия определяется по функции ДИСП.В(число1; число2 …).
Стандартное отклонение –понятие теории вероятностей и математической статистики. Мера разброса случайной величины вокруг ее среднего значения. Для выборочной совокупности стандартное отклонение определяется по функции СТАНОТКЛОН.В(число1; число2 …).
Медиана– это серединное значение признака X. Медиана разбивает выборку на две равные части. Половина значений переменной лежит ниже медианы, половина –выше. Медиана дает общее представление о том, где сосредоточены значения переменной, иными словами, где находится ее центр. Медиана определяется по функции МЕДИАНА(число1; число2 …).
Мода– представляет собой максимально часто встречающееся значение переменной. Определяется по функции МОДА.ОДН(число1; число2 …). Если набор данных не содержит повторяющихся точек данных, функция МОДА.ОДН возвращает значение ошибки #Н/Д.
Квартили– представляют собой значения, которые делят две половины выборки (разбитые медианой) еще раз пополам (от слова кварта – четверть).
Различают верхнюю квартиль, которая больше медианы и делит пополам верхнюю часть выборки (значения переменной больше медианы), и нижнюю квартиль, которая меньше медианы и делит пополам нижнюю часть выборки.
Нижнюю квартиль часто обозначают символом 25%, это означает, что 25% значений переменной меньше, чем нижняя квартиль.
Верхнюю квартиль часто обозначают символом 75%, это означает, что 75% значений переменной меньше, чем верхняя квартиль.
Таким образом, три точки – нижняя квартиль, медиана и верхняя квартиль – делят выборку на 4 равные части.
Квартиль определяется по функции КВАРТИЛЬ.ВКЛ(массив; часть). Аргумент часть может принимать только пять следующих значений: 0 – наименьшая величина, 1 – величина 25-го персентиля, 2 – медиана (величина 50 персентиля), 3 – величина 75-го персентиля, 4 – наибольшая величина.
Персентиль(перцентиль, процентиль) – это сотая доля объема измеренной совокупности, выраженная в процентах, которой соответствует определенное значение признака.
Вместо функции КВАРТИЛЬ.ВКЛ (массив; часть) для получения наименьшего и наибольшего значений можно использовать функцию МИН(число1; число2 …) и МАКС(число1; число2 …) соответственно, а для получения медианы – функцию МЕДИАНА(число1; число2 …). Эти функции вычисляются быстрее, чем функция КВАРТИЛЬ.ВКЛ (массив; часть), особенно в случае больших массивов данных.
Квантиль– это точка на числовой оси измеренного признака, которая делит всю совокупность упорядоченных измерений на две группы с известным соотношением их численности. К квантилям относятся медиана (квантиль со значением 0,5), квартили (например, верхняя квартиль – это квантиль со значением 75% или 0,75), персентили.
Вычисляется квантиль по функции ПРОЦЕНТИЛЬ.ВКЛ (массив; k), где массив – это совокупность значений, k – значение процентиля в интервале от 0 до 1 включительно.
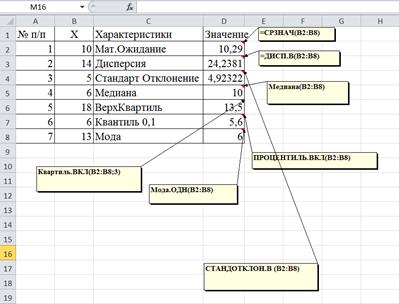
Рис. 36. Решение примера 20
MS Excel в своем составе содержит компоненты предоставляющие доступ к дополнительным функциям и командам. Эти компоненты получили название «надстройки». "Пакет анализа" является одной из наиболее популярных надстроек, которая реализует функции расширенного анализа данных. Чтобы использовать надстройки, их необходимо установить и активировать. Для этого выполняются действия Вкладка Файл/кнопка Параметры/категория Надстройки/кнопка Перейти. В появившемся диалоговом окне Надстройки (Рис.37) установить флажок Пакет анализа и нажать кнопку ОК.
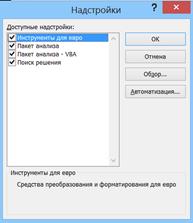
Рис. 37. Диалоговое окно Надстройки
На вкладке Данныебудет добавлена группа Анализ,которая содержит кнопку для надстройки Анализ данных(Рис. 38).Нажав кнопку Анализ данных появится диалоговое окно Анализ данных (Рис. 39) для выбора инструментов анализа.

Рис. 38. Вкладка Данные/группа Анализ/Анализ данных
Рис. 39. Окно Анализ данных
Пример 21.
Даны выборки зарплат основных групп работников банка: администрации (менеджеров), персонала по работе с клиентами, технических служб. Полученные данные приведены в таблице на рис. 40. Требуется вычислить основные статистические характеристики в группах данных.
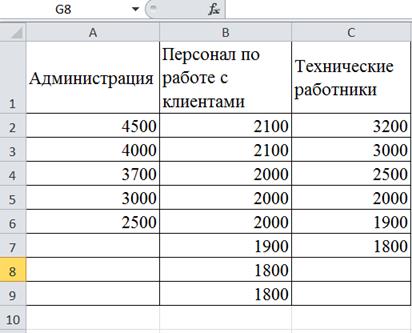
Рис. 40. Выборка зарплат работников банка
Алгоритм решения.
В вашей рабочей книге lab6_FIO, откройте Лист 3.
Для решения задачи воспользуемся надстройкой «Описательная статистика» из анализа данных. В состав описательной статистики входят такие характеристики как среднее, стандартная ошибка, медиана, мода, стандартное отклонение, дисперсия выборки, эксцесс, асимметричность, интервал, минимум, максимум, сумма, количество. Цель описательной статистики – обобщить первичные результаты, полученные в результате наблюдений и экспериментов.
Стандартная ошибка– характеризует колебания средней. При этом необходимо отметить, что чем больше объем выборки, тем меньше разброс средних величин.
Эксцесс –есть степень крутости эмпирического распределения по отношению к нормальному. Обычно, если эксцесс положителен, то пик заострен, если отрицательный, то пик закруглен. Эксцесс нормального распределения равен 0.
Асимметричность– коэффициент асимметрии в теории вероятности – величина, характеризующая асимметрию распределения данной случайной величины. Принято считать, что асимметрия выше 0,5 (независимо от знака) считается значительной. Если асимметрия меньше 0,25, она считается незначительной.
Выбираем инструмент Описательная статистика: Вкладка Данные/группа Анализ/Анализ данных (Рис.41).
Рис. 41. Анализ данных (описательная статистика)
Заполняем диалоговое окно Описательная статистика (Рис. 42). Входной интервал – таблица «Выборка зарплат» вместе с шапкой; Группирование «по столбцам»; первую строку таблицы берем в качестве меток первой строки; задаем параметры вывода – верхнюю левую точку выходного интервала; итоговую статистику для создания подробной выходной таблицы; уровень надежности равный 95%. Результат можно разместить на существующем листе или новом рабочем листе, или новой рабочей книге.
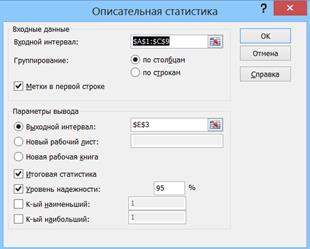
Рис. 42. Диалоговое окно «Описательная статистика»
В результате получаем таблицу следующего вида (Рис. 43)
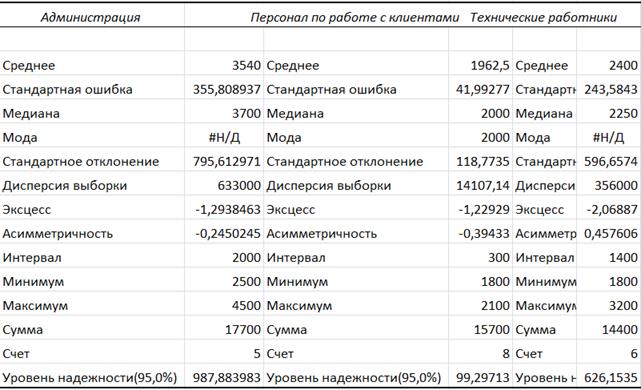
Рис. 43. Основные статистические характеристики
Пример 22.
Магазин продает мужские костюмы. Распределение спроса по размерам является нормальным с математическим ожиданием М=48 и сигма=2. Вычислить процент спроса на 52 размер.
Алгоритм решения.
В вашей рабочей книге lab6_FIO, откройте Лист 4.
Для решения воспользуемся функцией НОРМ.РАСП(x,среднее, стандартное_откл, интегральная), которая возвращает нормальную функцию распределения для указанного среднего и стандартного отклонения. Эта функция очень широко применяется в статистике, в том числе при проверке гипотез.
Аргументы функции НОРМ.РАСП:
xЗначение, для которого строится распределение. В нашем примере размер x = 52.
СреднееСреднее арифметическое распределения. В нашем примере М=48 Стандартное_отклСтандартное отклонение распределения. В нашем примере сигма=2.
ИнтегральнаяЛогическое значение, определяющее форму функции. Если аргумент «интегральная» имеет значение ИСТИНА, функция НОРМ.РАСП возвращает интегральную функцию распределения; если этот аргумент имеет значение ЛОЖЬ, возвращается весовая функция распределения. В нашем примере ЛОЖЬ, т.к. речь идет о весовой функции распределения, т.к. мы ищем результат для определенной точки Х.
Создадим модель и заполним данными задачи (Рис. 44)
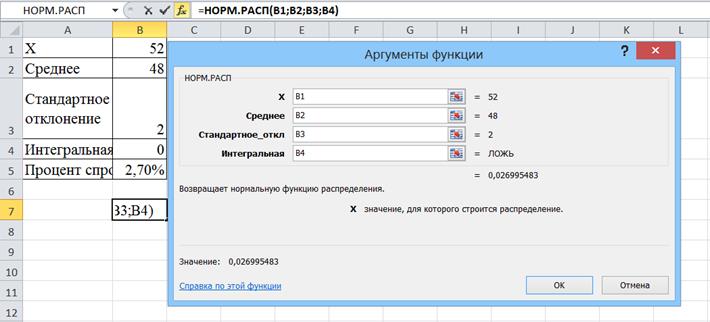
Рис.44. Функция НОРМ.РАСП
|
из
5.00
|
Обсуждение в статье: Лабораторная работа 6 Анализ финансово-экономических ситуаций с помощью методов теории вероятности и статистики |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы