 |
Главная |


Регрессионные модели. Аппроксимация данных. Подбор формул со многими неизвестными
|
из
5.00
|
1. Построение регрессионной модели (определение функции «черного ящика»)
Задача. Известны данные динамики выпуска продукции предприятия за 10 лет (набор из n=10 экспериментальных точек):
| X | ||||||||||
| Y |
X – порядковый номер года с 2001 по 2010; Y – объем валовой продукции предприятия.
Экспериментальные точки отображены на графике:

Используя имеющиеся экспериментальные данные, необходимо построить регрессионную модель (т.е. определить функцию черного ящика), по которой вход преобразуется в выход.

Схема одномерной регрессионной модели
Занесите экспериментальные данные в таблицу Excel:
| Xi | Yi |
Результат ввода данных:

Предположим, что экспериментальные данные подчиняются линейному закону, т.е. выдвигаем гипотезу о линейной модели: Y = aX + b.
Построение модели выполним по методу наименьших квадратов, суть которого в том, что необходимо найти такие значения коэффициентов a и b, при которых сумма квадратов отклонений F экспериментальных данных от расчетных (теоретических) значений Y будет минимальной:

Здесь: Ei – ошибки между экспериментальными данными и расчетными значениями Y; F – суммарная ошибка (сумма квадратов отклонений).
Уравнения для Ei и F имеют вид:
Ei = (YiЭксп. – YiТеор.) = Yi – b – aXi, i = 1, …, n.

Для определения значений b и a, которые доставляют экстремум функции F, надо найти частные производные по переменным b и a и приравнять их к нулю (условие экстремума):


После раскрытия скобок получится система линейных уравнений:

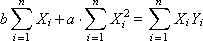
Для решения данной системы составьте в Excel таблицу промежуточных вычислений, используя соответствующие формулы и функцию СУММ:
| Xi | Yi | Xi2 | XiYi | |
| Сумма: |
Результат ввода

Полученная система линейных уравнений в матричной форме имеет вид:

Подстановка из таблицы соответствующих значений сумм при решении системы «вручную» дает:

Существуют следующие способы решения системы линейных уравнений (определения коэффициентов b и a):
- методом Крамера;
- методом Гаусса;
- методом обращения начальной матрицы.
При решении системы методом Крамера получаются следующие выражения для b и a:

Введите данное решение в таблицу Excel:
- для коэффициента b:
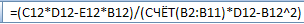
- для коэффициента a:

Здесь для вычисления общего числа точек n использована функция СЧЁТ.
Найдем значения b и a «ручным» способом:

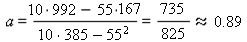
Удостоверьтесь, что полученные с помощью Excel и «вручную» значения b и a совпадают.
Существует также способ определения коэффициентов b и a с использованием расчетных формул, представленных в развернутом (скалярном) виде:
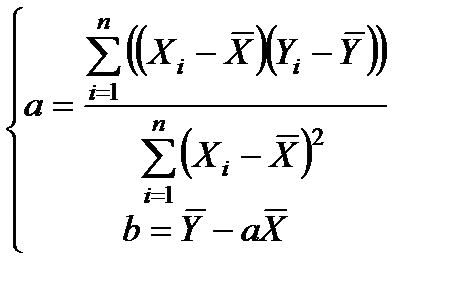
где  – средние значения Y и X (в Excel реализуется функцией СРЗНАЧ).
– средние значения Y и X (в Excel реализуется функцией СРЗНАЧ).
Решение задачи данным способом выполните на самостоятельной подготовке. Таблица Excel с расчетами этим способом имеет вид:

Итак, найденные значения b = 11.8 и a = 0.89 обеспечивают прохождение графика Y = aX + b как можно ближе одновременно ко всем экспериментальным точкам. Таким образом, получено линейное уравнение: Y = 0.89X + 11.8.
Произведите расчеты теоретических (эмпирических) значений Yiтеор. по данной линейной функции. Для расчетов используйте абсолютные ссылки (знак $) на ячейки с полученными значениями b и a.
Для ожидаемого значения Xож=11 (на 11-й год) определите прогнозное значение Y(Xож=11).

Теперь необходимо проверить правомерность принятой гипотезы о полученной линейной зависимости Y = 0.89X + 11.8.
Для этого необходимо рассчитать ошибку Ei между экспериментальными точками Y и точками полученной теоретической зависимости Yтеор., суммарную ошибку F, значение стандартного отклонения σ и вероятного отклонения S по формулам:
Ei = Yi – b – aXi, i = 1, …, n


Значение S связано с σ соотношением:
S = σ/sinβ = σ/sin(90°–arctga) = σ/cos(arctga).
Такая зависимость между S и σ получена из рисунка:

Рис. Связь σ и S
Для проверки правильности принятия гипотезы используется нормальный закон распределения случайных ошибок. На рисунке P – вероятность распределения ошибки.

Рис. Иллюстрация закона нормального распределения ошибок
Если в полосу, ограниченную линиями Yтеор-S = aX+b-S и Yтеор+S = aX+b+S попадет 68.26% или более из всех экспериментальных точек, то можно сделать вывод о том, что принятая гипотеза о линейной зависимости Y = aX + b верна.
Создайте таблицу для расчетов ошибок между точками экспериментальной и теоретической зависимости:

Примечание: формулы последнего столбца L реализованы с использованием функций ЕСЛИ и И.
Значение суммарной ошибки будет F = 10.62
Значение  .
.
Значение S = σ/cos(arctg(a)) = 1.38.
Таблица результатов создания регрессионной линейной модели:
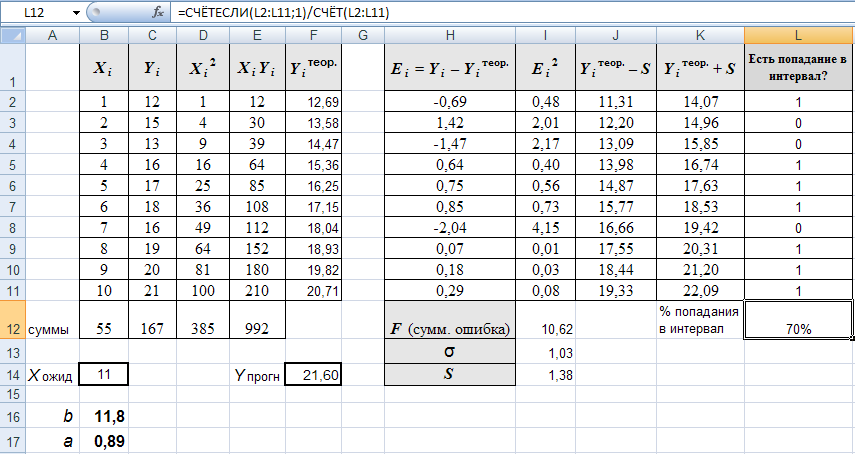
Расчеты показывают, что 7 точек из 10 (то есть 70%) попадают в полосу, ограниченную линиями Yнижняя = 0.89X + 11.8 – 1.38 и Yверхняя = 0.89X + 11.8 + 1.38, из чего заключаем: зависимость между входом и выходом модели линейная, то есть выдвинутая гипотеза о линейной зависимости верна.
Проиллюстрируем расчеты на графике:

Рис. Найденная линейная зависимость с обозначенным интервалом [–S; +S]
2. Прогнозирование с помощью линий тренда
Линии тренда графиков Excel используются для установления зависимости и исследования связи между двумя переменными.
Задача. Условия задачи остаются прежними (как в пункте 1).
Решение:
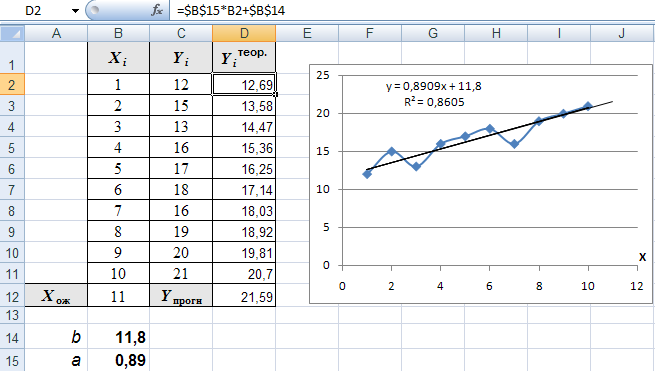
1. Введите значения X и Y по столбцам,скопировав лист с данными из п.1.
2. Постройте график зависимости Y(X), используя тип диаграммы «Точечная, с гладкими кривыми и маркерами».
3. Поставьте указатель мыши на линию графика функции, правая кнопка мыши – контекстное меню «Добавить линию тренда».
4. Установите параметры: тип тренда «линейная», «прогноз вперед на 1 период», «показывать уравнение на диаграмме», «поместить величину достоверности аппроксимации R^2».
5. Введите заголовок диаграммы «Прогноз объема производства на 11-й год».
6. Повторите пункты 2, 3, 4 для получения прогноза по следующим функциям: логарифмическая, полиномиальная второй степени, степенная, экспоненциальная.
7. Выберите лучшую модель по критерию R^2, которая лучше остальных описывает зависимость Y от X. Коэффициент детерминации R^2 равен доле исходных данных, которые подчиняются выбранной тенденции.
8. Произведите расчеты теоретических значений Yiтеор. и прогнозного значения Yпрогн для ожидаемого Xож = 11 по наилучшей модели.
9. Результаты расчетов изображены на рисунке.
3. Прогнозирование по методу наименьших квадратов с помощью матричных операций
Задача остается прежней: вычислить коэффициенты линейной модели b и a по методу наименьших квадратов, но только с помощью матричных операций.
Матричный способ решения построения модели имеет преимущества и недостатки.
Преимущества: компактность записи формул; исследование многофакторных моделей.
Недостатки: необходимость знания матричной алгебры; необходимость наличия программных средств выполнения матричных операций (Excel выполняет все матричные вычисления, кроме вычисления собственных значений и собственных векторов).
Перечень матричных операций в Excel:
- транспонирование – функция ТРАНПС категории «Ссылки и массивы»;
- вычисление обратной матрицы – функция МОБР категории «Математические»;
- умножение матриц – функция МУМНОЖ категории «Математические».
Особенности выполнения матричных операций в Excel:
1. после выбора функции установить нужные аргументы и выполнить расчеты для первой ячейки результирующего массива;
2. выделить первую ячейку с расчетами и все ячейки, на которые будет распространено действие функции;
3. нажать и отпустить клавишу F2;
4. последовательно нажать, не отпуская, клавиши Ctrl + Shift + Enter.
Решение задачи:
1. Введите данные Xi и Yi по столбцам. Для этого достаточно скопировать лист, в котором решалась задача в п.1, и удалить на новом листе всю лишнюю информацию, кроме таблицы с данными Xi и Yi.
2. Выполните расчет коэффициентов модели a и b в матричном виде по формуле:
A = (XТ X)-1 XТ Y,
где A – вектор-столбец коэффициентов модели;
X – матрица исходных данных, которая включает вектор-столбец переменной для свободного коэффициента b (его значения в нашем случае равны 1) и векторы-столбцы объясняемых факторов (в нашем случае – один столбец со значениями Xi);
XТ – транспонированная матрица;
(XТ X)-1 – обратная матрица от произведения двух матриц;
Y – вектор-столбец зависимой переменной.
3. Вычислите коэффициенты модели a и b в матричном виде в последовательности, как показано на рисунке.
4. Вычислите расчетные (теоретические) значения Yiтеор, прогнозное значение Yпрогн для Xожид=11.

Разобранный пример – учебный. Поэтому мы ограничились очень небольшим числом экспериментальных точек. В реальных условиях для обеспечения достоверности результатов исследования нужно брать гораздо большее число экспериментальных точек.
4. Построение многофакторных регрессионных моделей с помощью матричных операций
Для зависимостей со многими неизвестными подбор формул можно выполнить несколькими способами:
- с помощью функций из группы Статистические - ЛИНЕЙН и ЛГРФПРИБЛ.
- функции ТЕНДЕНЦИЯ и РОСТ – для вычисления значений аппроксимирующей функции в диапазоне наблюдения;
- инструмент для подбора формул со многими неизвестными Регрессия, входящий в Пакет анализа (Данные – Анализ данных…);
- матричными вычислениями по методу наименьших квадратов.
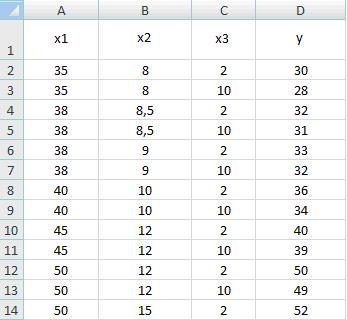
Задача. Необходимо оценить значения функции y по значениям трех переменных: х1, х2, х3, предполагая, что между ними и зависимой переменной y существует линейная зависимость вида y=a0+a1x1+a2x2+a3x3, т.е. надо вычислить ее коэффициенты a0, a1, a2, a3. Полученные в результате эксперимента данные занесены в таблицу:
| x1 | x2 | x3 | y |
| 8,5 | |||
| 8,5 | |||
Необходимо подобрать формулу для вычисления эмпирических (теоретических) значений y и вычислить прогнозное значение y с данными: х1 = 42, х2 = 11, х3 = 5.
Порядок решения задачи:
1. Заведите таблицу с данными в ячейки A1:D14. Результаты ввода:
2. Выполните расчет коэффициентов модели в матричном виде по формуле:
A = (XТ X)-1 XТ Y.
Здесь А – вектор-столбец неизвестных коэффициентов a0, a1, a2, a3.
Последовательность расчета показана на нижних рисунках.

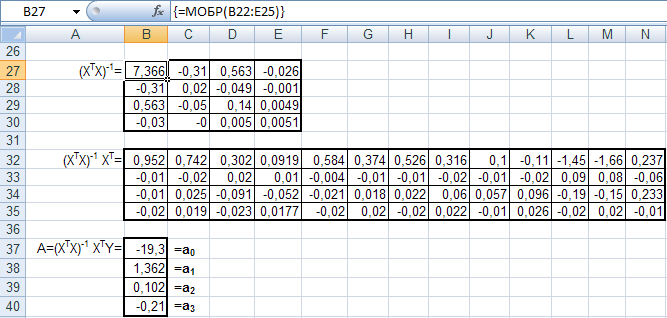
Таким образом, аппроксимирующая формула y=a0+a1x1+a2x2+a3x3 имеет вид:
Y = – 19,3 + 1,36*х1 + 0,1*х2 – 0,21*х3
3. С использованием полученной формулы вычислите теоретические значения yтеор и прогнозное значение функции yпрогн при х1=42, х2=11, х3=5, записав самостоятельно в любую ячейку формулу для расчета.Результат расчета: yпрогн=37,9.
5. Прогнозирование с использованием функций ЛИНЕЙН и ТЕНДЕНЦИЯ
Функции ЛИНЕЙН и ТЕНДЕНЦИЯ применяют для аппроксимации экспериментальных данных линейные зависимости вида y = a0+ a1x1 + a2x2 + … + anxn.
Функция ЛИНЕЙН возвращает массив с т.н. регрессионной статистикой, который содержит вычисленные значения параметров (a0, a1, a2, …, an), коэффициент детерминации R2 и другие характеристики аппроксимирующей функции.
Задача: Исходные данные те же, что и в п. 4. Необходимо также построить линейную регрессионную модель: y=a0+a1x1+a2x2+a3x3, но только с помощью функций ЛИНЕЙН и ТЕНДЕНЦИЯ, а также вычислить прогнозное значение y с данными: х1=37, х2=11, х3=3.
Порядок решения задачи:
|
из
5.00
|
Обсуждение в статье: Регрессионные модели. Аппроксимация данных. Подбор формул со многими неизвестными |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы