 |
Главная |


Устройство центрального процессора
|
из
5.00
|

Внутреннее устройство тракта данных типичного фон-неймановского процессора показано на рис. 2.2. Тракт данных состоит из регистров (обычно от 1 до 32), АЛУ (арифметико-логического устройства) и нескольких соединяющих шин. Содержимое регистров поступает во входные регистры АЛУ, которые на рис. 2.2 обозначены буквами А и В. В них находятся входные данные АЛУ, пока АЛУ производит вычисления. Тракт данных — важная составная часть всех компьютеров, и мы обсудим его очень подробно.
АЛУ выполняет сложение, вычитание и другие простые операции над входными данными и помещает результат в выходной регистр. Этот выходной регистр может помещаться обратно в один из регистров. Он может быть сохранен в памяти, если это необходимо. На рис. 2.2 показана операция сложения. Отметим, что входные и выходные регистры есть не у всех компьютеров.
Большинство команд можно разделить на две группы: команды типа регистр память и типа регистр-регистр. Команды первого типа вызывают слова из памяти, помещают их в регистры, где они используются в качестве входных данных АЛУ.
(«Слова» — это такие элементы данных, которые перемещаются между памятью и регистрами.) Словом может быть целое число. Устройство памяти мы обсудим ниже в этой главе. Другие команды этого типа помещают регистры обратно в память.

Команды второго типа вызывают два операнда из регистров, помещают их во входные регистры АЛУ, выполняют над ними какую-нибудь арифметическую или логическую операцию и переносят результат обратно в один из регистров. Этот процесс называется циклом тракта данных. В какой-то степени он определяет, что может делать машина. Чем быстрее происходит цикл тракта данных, тем быстрее компьютер работает.
Выполнение команд
Центральный процессор выполняет каждую команду за несколько шагов:
1) вызывает следующую команду из памяти и переносит ее в регистр команд;
2) меняет положение счетчика команд, который теперь должен указывать наследующую команду;
3) определяет тип вызванной команды;
4) если команда использует слово из памяти, определяет, где находится это слово;
5) переносит слово, если это необходимо, в регистр центрального процессора;
6) выполняет команду;
7) переходит к шагу 1, чтобы начать выполнение следующей команды.
Такая последовательность шагов (выборка—декодирование—исполнение) является основой работы всех компьютеров.
Описание работы центрального процессора можно представить в виде программы на английском языке. В листинге 2.1 приведена такая программа-интерпретатор на языке Java. В описываемом компьютере есть два регистра: счетчик команд, который содержит путь к адресу следующей команды, и аккумулятор, в котором хранятся результаты арифметических операций. Кроме того, имеются внутренние регистры, в которых хранится текущая команда (instr), тип текущей команды (instr_type), адрес операнда команды (datajloc) и сам операнд (data). Каждая команда содержит один адрес ячейки памяти. В ячейке памяти находится операнд, например кусок данных, который нужно добавить в аккумулятор.
Сама возможность написать программу, имитирующей работу центрального процессора, показывает, что программа не обязательно должна выполняться реальным процессором, относящимся к аппаратному обеспечению. Напротив, вызывать из памяти, определять тип команд и выполнять эти команды может другая программа. Такая программа называется интерпретатором. Об интерпретаторах мы говорили в главе 1.
Написание программ-интерпретаторов, которые имитируют работу процессора, широко используется при разработке компьютерных систем. После того как разработчики выбрали машинный язык (Я) для нового компьютера, они должны решить, строить ли им процессор, который будет выполнять программы на языке Я, или написать специальную программу для интерпретации программ на языке Я. Если они решают написать интерпретатор, они должны создать аппаратное обеспечение для выполнения этого интерпретатора. Возможны также гибридные конструкции, когда часть команд выполняется аппаратным обеспечением, а часть интерпретируется.
Интерпретатор разбивает команды на маленькие шаги. Таким образом, машина с интерпретатором может быть гораздо проще по строению и дешевле, чем процессор, выполняющий программы без интерпретации. Такая экономия особенно важна, если компьютер содержит большое количество сложных команд с различными опциями. В сущности, экономия проистекает из самой замены аппаратного обеспечения программным обеспечением (интерпретатором).
Первые компьютеры содержали небольшое количество команд, и эти команды были простыми. Но поиски более мощных компьютеров привели, кроме всего прочего, к появлению более сложных команд. Вскоре разработчики поняли, что при наличии сложных команд программы выполняются быстрее, хотя выполнение отдельных команд занимает больше времени. В качестве примеров сложных команд можно назвать выполнение операций с плавающей точкой, обеспечение прямого доступа к элементам массива и т. п. Если обнаруживалось, что две определенные команды часто выполнялись последовательно одна за другой, то вводилась новая команда, заменяющая работу этих двух.
Сложные команды были лучше, потому что некоторые операции иногда перекрывались. Какие-то операции могли выполняться параллельно, для этого использовались разные части аппаратного обеспечения. Для дорогих компьютеров с высокой производительностью стоимость этого дополнительного аппаратного обеспечения была вполне оправданна. Таким образом, у дорогих компьютеров было гораздо больше команд, чем у дешевых. Однако развитие программного обеспечения и требования совместимости команд привели к тому, что сложные команды стали использоваться и в дешевых компьютерах, хотя там во главу угла ставилась стоимость, а не скорость работы.
К концу 50-х годов компания IBM, которая лидировала тогда на компьютерном рынке, решила, что производство семейства компьютеров, каждый из которых выполняет одни и те же команды, имеет много преимуществ и для самой компании, и для покупателей. Чтобы описать этот уровень совместимости, компания IBM ввела термин архитектура. Новое семейство компьютеров должно было иметь одну общую архитектуру и много разных разработок, различающихся по цене и скорости, которые могли выполнять одну и ту же программу. Но как построить дешевый компьютер, который будет выполнять все сложные команды, предназначенные для высокоэффективных дорогостоящих машин?
Решением этой проблемы стала интерпретация. Эта технология, впервые предложенная Уилксом в 1951 году, позволяла разрабатывать простые дешевые компьютеры, которые, тем не менее, могли выполнять большое количество команд. В результате IBM создала архитектуру System/360, семейство совместимых компьютеров, различных по цене и производительности. Аппаратное обеспечение без интерпретации использовалось только в самых дорогих моделях.
Простые компьютеры с интерпретированными командами имели некоторые другие преимущества. Наиболее важными среди них были:
1) возможность фиксировать неправильно выполненные команды или даже восполнять недостатки аппаратного обеспечения;
2) возможность добавлять новые команды при минимальных затратах, даже после покупки компьютера;
3) структурированная организация, которая позволяла разрабатывать, проверять и документировать сложные команды.
В 70-е годы компьютерный рынок быстро разрастался, новые компьютеры могли выполнять все больше и больше функций. Спрос на дешевые компьютеры провоцировал создание компьютеров с использованием интерпретаторов. Возможность разрабатывать аппаратное обеспечение и интерпретатор для определенного набора команд вылилась в создание дешевых процессоров. Полупроводниковые технологии быстро развивались, преимущества низкой стоимости преобладали над возможностями более высокой производительности, и использование интерпретаторов при разработке компьютеров стало широко применимо. Интерпретация использовалась практически во всех компьютерах, выпущенных в 70-е годы, от миникомпьютеров до самых больших машин.
К концу 70-х годов интерпретаторы стали применяться практически во всех моделях, кроме самых дорогостоящих машин с очень высокой производительностью (например, Сгау-1 и компьютеров серии Control Data Cyber). Использование интерпретаторов исключало высокую стоимость сложных команд, и разработчики могли вводить все более и более сложные команды, в особенности различные способы определения используемых операндов.
Эта тенденция достигла пика своего развития в разработке компьютера VAX (производитель Digital Equipment Corporation), у которого было несколько сотен команд и более 200 способов определения операндов в каждой команде. К несчастью, архитектура VAX с самого начала разрабатывалась с использованием интерпретатора, а производительности уделялось мало внимания. Это привело к появлению большого количества команд второстепенного значения, которые трудно было выполнять сразу без интерпретации. Данное упущение стало фатальным как для VAX, так и для его производителя (компании DEC). Compaq купил DEC в 1998 году.
Хотя самые первые 8-битные микропроцессоры были очень простыми и содержали небольшой набор команд, к концу 70-х годов даже они стали разрабатываться с использованием интерпретаторов. В этот период основной проблемой для разработчиков стала возрастающая сложность микропроцессоров. Главное преимущество интерпретации заключалось в том, что можно было разработать простой процессор, а вся сложность сводилась к созданию интерпретатора. Таким образом, разработка сложного аппаратного обеспечения замещалась разработкой сложного программного обеспечения.
Успех Motorola 68000 с большим набором интерпретируемых команд и одновременный провал Zilog Z8000, у которого был столь же обширный набор команд, но не было интерпретатора, продемонстрировали все преимущества использования интерпретаторов при разработке новых машин. Успех Motorola 68000 был несколько неожиданным, учитывая, что Z80 (предшественник Zilog Z8000) пользовался большей популярностью, чем Motorola 6800 (предшественник Motorola 68000). Конечно, важную роль здесь играли и другие факторы, например то, что Motorola много лет занималась производством микросхем, a Exxon (владелец Zilog) долгое время был нефтяной компанией.
Еще один фактор в пользу интерпретации — существование быстрых постоянных запоминающих устройств (так называемых командных ПЗУ) для хранения интерпретаторов. Предположим, что для выполнения обычной интерпретируемой команды Motorola 68000 интерпретатору нужно выполнить 10 команд, которые называются микрокомандами, по 100 не каждая, и произвести 2 обращения к оперативной памяти по 500 не каждое. Общее время выполнения команды составит, следовательно, 2000 не, всего лишь в два раза больше, чем в лучшем случае могло бы занять непосредственное выполнение этой команды без интерпретации. А если бы не было специального быстродействующего постоянного запоминающего устройства, выполнение этой команды заняло бы целых 6000 не. Таким образом, важность наличия командных ПЗУ очевидна.
4 !Многоступенчатый конвейер.
Выполнение команды можно разделить на два этапа: выборка из основной памяти и собственно выполнение. Известно, что этап выборки занимает сравнительно длительное время. Для его сокращения в 1959 г. При разработке IBM Stretch был предложен принцип выборки с упреждением, согласно которому команды выбираются из памяти заранее и помещаются в буферный регистр. Это происходит, когда процессор не занимает внешнюю шину, связывающую его с основной памятью. При выполнении программы по мере необходимости команды вызываются из буфера, благодаря чему сокращается время их выполнения. Позднее идея конвейеризации получила дальнейшее развитие. При конвейерной технологии выполнение команды разделяется на несколько стадий, или этапов, которые реализуются одновременно соответствующими аппаратными средствами.
Если время выполнения одной команды T секунд, то при отсутствии простоев и ожиданий конвейерный принцип обеспечивает выполнение n/T команд в секунду, где n – число стадий (ступеней) конвейера.
Пример
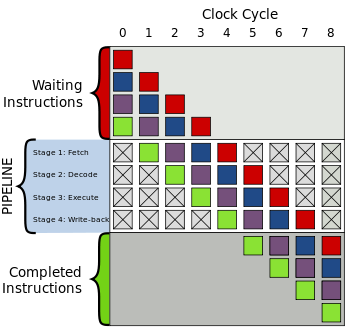
Общий четырёхуровневых конвейер; цветные квадраты символизируют независимые друг от друга инструкции
1. Получение (англ. Fetch)
2. Раскодирование (англ. Decode)
3. Выполнение (англ. Execute)
4. Запись результата (англ. Write-back)
Верхняя серая область — список инструкций, которые предстоит выполнить. Нижняя серая область — список инструкций, которые уже были выполнены. И средняя белая область является самим конвейером.
Выполнение происходит следующим образом:
| Цикл | Действия |
| · Четыре инструкции ожидают исполнения | |
| · Зелёная инструкция забирается из памяти | |
| · Зелёная инструкция раскодируется · Фиолетовая инструкция забирается из памяти | |
| · Зелёная инструкция выполняется (то есть исполняется то действие, которое она кодировала) · Фиолетовая инструкция раскодируется · Синяя инструкция забирается из памяти | |
| · Итоги исполнения зелёной инструкции записываются в регистры или в память · Фиолетовая инструкция выполняется · Синяя инструкция раскодируется · Красная инструкция забирается из памяти | |
| · Зелёная инструкция завершилась · Итоги исполнения фиолетовой инструкции записываются в регистры или в память · Синяя инструкция выполняется · Красная инструкция раскодируется | |
| · Фиолетовая инструкция завершилась · Результаты исполнения синей инструкция записываются в регистры или в память · Красная инструкция выполняется | |
| · Синяя инструкция завершилась · Итоги исполнения красной инструкции записываются в регистры или в память | |
| · Красная инструкция завершилась | |
| · Все инструкции были выполнены |
5 !Организация (адресация) памяти.
Адресация — осуществление ссылки (обращение) к устройству или элементу данных по его адресу; установление соответствия между множеством однотипных объектов и множеством их адресов; метод идентификации местоположения объекта.
Методы адресации
Адресное пространство
- Простая (англ. flat addressing) — указание объекта с помощью идентификатора или числа, не имеющего внутренней структуры.
- Расширенная (англ. extended addressing) — доступ к запоминающему устройству с адресным пространством, бо́льшим диапазона адресов, предусмотренного форматом команды.
- Виртуальная (англ. virtual addressing) — принцип, при котором каждая программа рассматривается как ограниченное непрерывное поле логической памяти, а адреса этого поля — как виртуальные адреса.
- Ассоциативная (англ. associative addressing) — точное местоположение данных не указывается, а задаётся значение определённого поля данных, идентифицирующее эти данные (см.: Ассоциативная память).
Исполнение программ
- Статическая (англ. static addressing) — соответствие между виртуальными и физическими адресами устанавливается до начала и не меняется в ходе выполнения программы.
- Динамическая (англ. dynamic addressing) — преобразование виртуальных адресов в физические осуществляется в процессе выполнения программы. Программа при этом не зависит от места размещения в физической памяти и может перемещаться в ней в процессе выполнения.
Кодирование адресов
- Явная (англ. explicit addressing) — адресация путём явного задания адресов в программе.
- Неявная (англ. implied addressing) — один или несколько операндов или адресов операндов находятся в фиксированных для данной команды регистрах или ячейках памяти и не требуют явного указания в команде.
- Абсолютная (англ. absolute addressing) — адресная часть команды содержит абсолютный адрес.
- Символическая (англ. symbolic addressing) — адресная часть команды содержит символический адрес.
Вычисление адресов
- Непосредственная, прямая (англ. immediate (direct) addressing) — адресная часть команды содержит непосредственный (прямой) адрес; адресация путём указания прямых адресов.
- Косвенная (англ. indirect addressing) — адресная часть команды содержит косвенный адрес; адресация посредством косвенных адресов.
- Регистровая (англ. register addressing) — задание адресов операндов в регистрах.
- Базисная (англ. basic addressing) — вычисление адресов в машинных командах относительно содержимого регистра, указанного в качестве базового.
- Базовая (англ. base-displacement addressing) — схема вычисления исполнительного адреса, при которой этот адрес является суммой базового адреса исмещения.
- Относительная (англ. relative addressing) — адресная часть команды содержит относительный адрес.
- Индексная (англ. indexed addressing) — формирование исполнительного адреса осуществляется путём добавления к базовому адресу содержимого индексного регистра.
- Автодекрементная, автоинкрементная (англ. autodecremental, autoincremental addressing) — содержимое регистра индекса изменяется (уменьшается или увеличивается) на некоторое число.
- Постдекрементная, предекрементная, постинкрементная, преинкрементная — автодекрементные и автоинкрементные адресации, при которых уменьшение/увеличение происходит после/до выборки операнда.
- Стековая (англ. stack addressing) — адресация посредством регистра — указателя стека.
- Самоопределяющаяся (англ. self-relative addressing) — адресная часть команды содержит самоопределяющийся адрес.
- Адресация относительно счётчика команд (англ. program counter relative addressing) — адреса в команде указываются в виде разности исполнительных адресов и адреса исполняемой команды. Такой способ адресации не требует настройки (см. также: Позиционно-независимый код).
Способы адресации
|
из
5.00
|
Обсуждение в статье: Устройство центрального процессора |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы