 |
Главная |


Автоинкрементная и автодекрементная адресации
|
из
5.00
|
Поскольку регистровая косвенная адресация требует предварительной загрузки регистра косвенным адресом из оперативной памяти, что связано с потерей времени, такой тип адресации особенно эффективен при обработке массива данных, если имеется механизм автоматического приращения или уменьшения содержимого регистра при каждом обращении к нему. Такой механизм называется соответственно автоинкрементной и автодекрементной адресацией. В этом случае достаточно один раз загрузить в регистр адрес первого обрабатываемого элемента массива, а затем при каждом обращении к регистру в нём будет формироваться адрес следующего элемента массива.
При автоинкрементной адресации сначала содержимое регистра используется как адрес операнда, а затем получает приращение, равное числу байт в элементе массива. При автодекрементной адресации сначала содержимое указанного в команде регистра уменьшается на число байт в элементе массива, а затем используется как адрес операнда.
Автоинкрементная и автодекрементная адресации могут рассматриваться как упрощенный вариант индексации — весьма важного механизма преобразования адресных частей команд и организации вычислительных циклов, поэтому их часто называют автоиндексацией.
Индексация
Для реализуемых на ЭВМ методов решения математических задач и обработки данных характерна цикличность вычислительных процессов, когда одни и те же процедуры выполняются над различными операндами, упорядоченно расположенными в памяти. Поскольку операнды, обрабатываемые при повторениях цикла, имеют разные адреса, без использования индексации требовалось бы для каждого повторения составлять свою последовательность команд, отличающихся адресными частями.
Программирование циклов существенно упрощается, если после каждого выполнения цикла обеспечено автоматическое изменение в соответствующих командах их адресных частей согласно расположению в памяти обрабатываемых операндов. Такой процесс называется модификацией команд, и основан на возможности выполнения над кодами команд арифметических и логических операций.
6 !Исправление ошибок. Диаграмма Венна. Код Хэмминга.
Память компьютера из-за всплесков напряжения и по другим причинам время от времени может ошибаться. Чтобы бороться с ошибками, используются специальные коды, умеющие обнаруживать и исправлять ошибки. В этом случае к каждому слову в памяти особым образом добавляются дополнительные биты. Когда слово считывается из памяти, эти дополнительные биты проверяются, что и позволяет обнаруживать ошибки.
Чтобы понять, как обращаться с ошибками, необходимо внимательно изучить, что представляют собой эти ошибки. Предположим, что слово состоит из т бит данных, к которым мы дополнительно прибавляем г бит (контрольных разрядов). Пусть общая длина слова составит п бит (то есть п= т + г). Единицу из п бит, содержащую т бит данных и г контрольных разрядов, часто называют кодовым словом.
Для любых двух кодовых слов, например 10001001 и 10110001, можно определить, сколько соответствующих битов в них различаются. В данном примере таких бита три. Чтобы определить количество различающихся битов, нужно над двумя кодовыми словами произвести логическую операцию ИСКЛЮЧАЮЩЕЕ ИЛИ и сосчитать количество битов со значением 1 в полученном результате. Число битовых позиций, по которым различаются два слова, называется интервалом Хэмминга [85]. Если интервал Хэмминга для двух слов равен d, значит, что достаточно dбитовых ошибок, чтобы превратить одно слово в другое. Например, интервал Хэмминга для кодовых слов 11110001 и 00110000 равен 3, поскольку для превращения первого слова во второе достаточно 3 битовые ошибки.
Память состоит из m-разрядных слов, следовательно, существуют 2твариантов сочетания битов. Кодовые слова состоят из п бит, но из-за способа подсчета контрольных разрядов допустимы только 2т из 2п кодовых слов. Если в памяти обнаруживается недопустимое кодовое слово, компьютер знает, что произошла ошибка. При наличии алгоритма подсчета контрольных разрядов можно составить полный список допустимых кодовых слов, и из этого списка найти два слова, для которых интервал Хэмминга будет минимальным. Это интервал Хэмминга для полного кода.
Возможности проверки и исправления ошибок определенного кода зависят от его интервала Хэмминга. Чтобы обнаружить d ошибок в битах, необходим код с интервалом d + 1, поскольку d ошибок не могут превратить одно допустимое кодовое слово в другое допустимое кодовое слово. Соответственно, чтобы исправить d ошибок в битах, необходим код с интервалом 2d + 1, поскольку в этом случае допустимые кодовые слова настолько сильно отличаются друг от друга, что, даже если произойдет dизменений, изначальное кодовое слово окажется ближе к ошибочному, чем любое другое кодовое слово, поэтому его без труда можно будет выявить.
В качестве простого примера кода с обнаружением ошибок рассмотрим код, в котором к данным присоединяется один бит четности. Бит четности выбирается таким образом, чтобы число битов со значением 1 в кодовом слове было четным (или нечетным). Интервал Хэмминга для этого кода равен 2, поскольку любая одиночная битовая ошибка приводит к кодовому слову с неправильной четностью. Другими словами, достаточно двух одиночных битовых ошибок для перехода от одного допустимого кодового слова к другому допустимому слову. Такой код может использоваться для обнаружения одиночных ошибок. Если из памяти считывается слово с неверной четностью, поступает сигнал об ошибке. Программа не сможет выполняться, но зато не выдаст неверных результатов.
В качестве простого примера кода исправления ошибок рассмотрим код с четырьмя допустимыми кодовыми словами: 0000000000, 0000011111, 1111100000 и 1111111111.
Интервал Хэмминга для этого кода равен 5. Это значит, что он может исправлять двойные ошибки. Если появляется кодовое слово 0000000111, компьютер знает, что изначально это слово выглядело как 0000011111 (если произошло не более двух ошибок). При появлении трех ошибок (например, слово 0000000000 меняется на 0000000111) этот метод не подходит.
Представим, что мы хотим разработать код, в котором т бит данных и г контрольных разрядов, позволяющий исправлять все одиночные битовые ошибки. Каждое из 2т допустимых слов имеет п недопустимых кодовых слов, которые отличаются от допустимого одним битом. Они образуются инвертированием каждого из п бит в и-разрядном кодовом слове. Следовательно, каждое из 2т допустимых слов требует п + 1 возможных сочетаний битов, приписываемых этому слову (п возможных ошибочных вариантов и один правильный). Поскольку общее число различных сочетаний битов равно 2W, то (п + 1) 2т < 2п. Так как п = т + г, то (т + г + 1) < 2Г. Эта формула дает нижний предел числа контрольных разрядов, необходимых для исправления одиночных ошибок. В табл. 2.2 показано необходимое количество контрольных разрядов для слов разного размера.
Таблица 2.2. Число контрольных разрядов для кода, способного исправлять одиночные ошибки
| Размер исходного слова | Количество контрольных разрядов | Общий размер слова | Процент увеличения слова |
Этого теоретического нижнего предела можно достичь, используя метод Ричарда Хэмминга. Но прежде, чем обратиться к указанному алгоритму, давайте рассмотрим простую графическую схему, которая четко иллюстрирует идею кода исправления ошибок для 4-разрядных слов. Диаграмма Венна на рис. 2.11 содержит 3 круга, Л, В и С, которые вместе образуют семь секторов. Давайте закодируем в качестве примера слово из 4 бит 1100 в сектора АВ, ABC, АС и ВС, по одному биту в каждом секторе (в алфавитном порядке). Подобное кодирование иллюстрирует рис. 2.11, а.

а б в
Рис. 2.11. Кодирование числа 1100 (а); добавляются биты четности (б); ошибка в секторе АС (е)
Далее мы добавим бит четности к каждому из трех пустых секторов, чтобы сумма битов в каждом из трех кругов, Д В, и С, получилась четной, как показано на рис. 2,11, б. В круге А находится 4 числа: 0, 0, 1 и 1, которые в сумме дают четное число 2. В круге В находятся числа 1, 1, 0 и 0, которые также при сложении дают четное число 2. Аналогичная ситуация и для круга С. В данном примере получилось так, что все суммы одинаковы, но вообще возможны случаи с суммами 0 и 4. Рисунок соответствует кодовому слову, состоящему из 4 бит данных и 3 бит четности.
Предположим, что бит в секторе АС изменился с 0 на 1, как показано на рис. 2.11, в. Компьютер обнаруживает, что круги А и С являются нечетными. Единственный способ исправить ошибку, изменив только один бит, — возвращение значения 0 биту в секторе АС. Таким способом компьютер может исправлять одиночные ошибки автоматически.
А теперь посмотрим, как может использоваться алгоритм Хэмминга при создании кодов исправления ошибок для слов любого размера. В коде Хэмминга к слову, состоящему из т бит, добавляются г бит четности, при этом образуется слово длиной т + г бит. Биты нумеруются с единицы (а не с нуля), причем первым считается крайний левый. Все биты, номера которых — степени двойки, являются битами четности; остальные используются для данных. Например, к 16-разрядному слову нужно добавить 5 бит четности. Биты с номерами 1, 2, 4, 8 и 16 — биты четности, все остальные — биты данных. Всего слово содержит 21 бит (16 бит данных и 5 бит четности). В рассматриваемом примере мы будем использовать проверку на четность (выбор произвольный).
Каждый бит четности позволяет проверять определенные битовые позиции. Общее число битов со значением 1 в проверяемых позициях должно быть четным. Ниже указаны позиции проверки для каждого бита четности:
♦ бит 1 проверяет биты 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21;
♦ бит 2 проверяет биты 2, 3, 6, 7, 10, И, 14, 15, 18, 19;
♦ бит 4 проверяет биты 4, 5, 6, 7, 12, 13, 14, 15, 20, 21;
♦ бит 8 проверяет биты 8, 9, 10, 11, 12, 13, 14, 15;
♦ бит 16 проверяет биты 16, 17, 18, 19, 20, 21.
В общем случае бит Ъ проверяется битами Ьь Ь2,fy, такими, что bt + b2 + ... + + bj = b. Например, бит 5 проверяется битами 1 и 4, поскольку 1+4 = 5. Бит 6 проверяется битами 2 и 4, поскольку 2 + 4 = 6 и т. д.
Рисунок 2.12 иллюстрирует построение кода Хэмминга для 16-разрядного слова 1111000010101110. Соответствующим 21-разрядным кодовым словом является 001011100000101101110. Чтобы понять, как происходит исправление ошибок, рассмотрим, что произойдет, если бит 5 изменит значение (например, из-за резкого скачка напряжения). В результате вместо кодового слова 001011100000101101110 получится 001001100000101101110. Будут проверены 5 бит четности. Вот результаты:
♦ неправильный бит четности 1 (биты 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21 содержат пять единиц);
♦ правильный бит четности 2 (биты 2, 3, 6, 7, 10, 11, 14, 15, 18, 19 содержат шесть единиц);
♦ неправильный бит четности 4 (биты 4, 5, 6, 7, 12, 13, 14, 15, 20, 21 содержат пять единиц);
♦ правильный бит четности 8 (биты 8, 9, 10, 11, 12, 13, 14, 15 содержат две единицы);
♦ правильный бит четности 16 (биты 16, 17, 18, 19, 20, 21 содержат четыре единицы).
Общее число единиц в битах 1, 3, 5, 7, 9, И, 13, 15, 17, 19 и 21 должно быть четным, поскольку в данном случае используется проверка на четность. Неправильным должен быть один из битов, проверяемых битом четности 1 (а именно 1, 3, 5, 7, 9, И, 13, 15, 17, 19 и 21). Бит четности 4 тоже неправильный. Это значит, что изменил значение один из следующих битов: 4, 5, 6, 7, 12, 13, 14, 15, 20, 21. Ошибка должна быть в бите, который содержится в обоих списках. В данном случае общими являются биты 5, 7, 13, 15 и 21. Поскольку бит четности 2 правильный, биты 7 и 15 исключаются. Правильность бита четности 8 исключает наличие ошибки в бите 13. Наконец, бит 21 также исключается, поскольку бит четности 16 правильный. В итоге остается бит 5, в котором и кроется ошибка. Поскольку этот бит имеет значение 1, он должен принять значение 0. Именно таким образом исправляются ошибки.
Слово 1111000010101110 в памяти
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21

Биты четности
Рис. 2.12. Построение кода Хэмминга для слова 1111000010101110 добавлением к битам
данных пяти контрольных разрядов
Чтобы найти неправильный бит, сначала нужно подсчитать все биты четности. Если они правильные, ошибки нет (или есть, но ошибка не однократная). Если обнаружились неправильные биты четности, нужно сложить их номера. Сумма, полученная в результате, даст номер позиции неправильного бита. Например, если биты четности 1 и 4 неправильные, а 2, 8 и 16 правильные, то ошибка произошла в бите 5(1 +4).
7 !Тракт данных — это…………(+схема…)
Тракт данных — это часть центрального процессора, состоящая из АЛУ (арифметико-логического устройства), его входов и выходов. Тракт данных нашей микроархитектуры показан на рис. 4.1. Хотя этот тракт данных и был оптимизирован для интерпретации ЦУМ-программ, он схож с трактами данных большинства компьютеров. Тракт содержит ряд 32-разрядных регистров, которым мы приписали символические названия (например, РС, 8Р, МЭИ). Хотя некоторые из этих названий нам знакомы, важно понимать, что эти регистры доступны только на уровне микроархитектуры (для микропрограммы). Им даны такие названия, поскольку они обычно содержат значения, соответствующие переменным с аналогичными названиями на уровне архитектуры команд. Содержание большинства регистров передается на шину В. Выходной сигнал АЛУ управляет схемой сдвига и далее шиной С. Значение с шины С может записываться в один или несколько регистров одновременно. Шину А мы введем позже, а пока представим, что ее нет.

8 !Описание и диаграмма полной микроархитектуры машины Mic-1.

До сих пор мы рассказывали об управлении трактом данных и не касались вопроса о том, какой именно сигнал управления и на каком цикле должен устанавливаться. Для этого существует контроллер последовательности, который отвечает за последовательность операций, необходимых для выполнения одной команды.
Контроллер последовательности в каждом цикле должен выдавать следующую информацию:
♦ состояние каждого сигнала управления в системе;
♦ адрес микрокоманды, которая будет выполняться следующей.
Рисунок 4.5 представляет собой подробную диаграмму полной микроархитектуры нашей машины, которую мы назвали Mic-1. Хотя на первый взгляд она может показаться внушительной, ее нужно подробно изучить. Если вы разберетесь во всех блоках и их связях, изображенных на этом рисунке, вам легче будет понять структуру уровня микроархитектуры. Диаграмма состоит из двух частей: тракта данных (слева), который мы уже подробно обсудили, и блока управления (справа), который мы рассмотрим сейчас.
Самой большой и самой важной частью блока управления является управляющая память. Удобно рассматривать ее как память, в которой хранится вся микропрограмма, хотя иногда микропрограмма реализуется в виде набора логических вентилей. Мы будем называть ее управляющей памятью, чтобы не путать с основной памятью, доступ к которой осуществляется через регистры MBR и MDR. Функционально управляющая память представляет собой память, в которой вместо обычных команд хранятся микрокоманды. В нашем примере она содержит 512 слов; каждое слово состоит из одной Зб-разрядной микрокоманды, формат которой показан на рис. 4.4. В действительности не все эти слова нужны, но по ряду причин нам требуются адреса для 512 отдельных слов.
Управляющая память отличается от основной памяти тем, что команды, хранящиеся в основной памяти, выполняются в соответствии с их адресами (за исключением ветвлений), а микрокоманды - нет. Увеличение счетчика команд в листинге 2.1 означает, что команда, которая будет выполняться после текущей, располагается вслед за ней в памяти. Микропрограммы должны обладать большей гибкостью, поскольку последовательности микрокоманд обычно короткие и этим свойством не обладают. Вместо этого каждая микрокоманда сама указывает на следующую микрокоманду.
Поскольку управляющая память функционально представляет собой ПЗУ, ей нужны собственные адресный регистр и регистр данных. Ей не требуются сигналы чтения и записи, поскольку процесс считывания происходит постоянно. Мы назовем адресный регистр управляющей памяти MPC (Microprogram Counter - счетчик микропрограмм). Название не очень подходящее, поскольку микропрограммы не упорядочены явным образом, и понятие счетчика тут неуместно, но мы не можем пойти против традиций. Регистр данных мы назовем MIR (Micro-Instruction Register - регистр микрокоманд). Он содержит текущую микрокоманду, биты которой запускают сигналы управления, влияющие на работу тракта данных.
Регистр MIR, изображенный на рис. 4.5, содержит те же шесть групп сигналов, которые показаны на рис. 4.4. Группы Addr и J (то же, что JAM) контролируют выбор следующей микрокоманды. Мы обсудим их чуть позже. Группа ALU содержит 8 бит, которые позволяют выбрать функцию АЛУ и запустить схему сдвига. Биты С загружают отдельные регистры с шины С. Сигналы M управляют работой памяти.
Наконец, последние 4 бита запускают декодер, который определяет, значение какого регистра будет передано на шину В. В данном случае мы выбрали декодер с 4 входами и 16 выходами, хотя имеется всего 9 разных регистров. В более проработанной модели мог бы использоваться декодер, имеющий 4 входа и 9 выходов. Мы задействуем стандартную схему, чтобы не разрабатывать собственную. Использовать стандартную схему гораздо проще, и, кроме того, вы сможете избежать ошибок. Ваша собственная микросхема займет меньше места, но на ее разработку потребуется довольно длительное время, к тому же вы можете построить ее неправильно.
Схема, изображенная на рис. 4.5, работает следующим образом. В начале каждого цикла (фронт синхронизирующего сигнала на рис. 4.2) в регистр MIR загружается слово из управляющей памяти, которая на рисунке отмечена буквами MPC. Загрузка регистра MIR занимает период Aw, то есть первый подцикл (см. рис. 4.2).
Когда микрокоманда попадает в MIR, в тракт данных поступают различные сигналы. Значение определенного регистра помещается на шину В, а АЛУ узнает, какую операцию нужно выполнять. Все это происходит во время второго под-цикла. После периода Aw + Ar входные сигналы АЛУ стабилизируются.
После периода Ау стабилизируются сигналы N и Z АЛУ, а также выходной сигнал схемы сдвига. Затем значения N и Z сохраняются в двух одноразрядных триггерах. Эти биты, как и биты всех регистров, которые загружаются с шины С и памяти, сохраняются на фронте синхронизирующего сигнала, ближе к концу цикла тракта данных. Выходной сигнал АЛУ не сохраняется, а просто передается в схему сдвига. Работа АЛУ и схемы сдвига происходит во время подцикла 3.
После следующего интервала, Az, выходной сигнал схемы сдвига, пройдя через шину С, достигает регистров. Регистры загружаются в конце цикла на фронте синхронизирующего сигнала (см. рис. 4.2). Во время подцикла 4 происходит загрузка регистров и триггеров N и Z. Подцикл завершается сразу после окончания фронта, когда все значения сохранены, результаты предыдущих операций памяти доступны, регистр MPC загружен. Этот процесс продолжается снова и снова, пока вы не выключите компьютер.
Микропрограмме приходится не только управлять трактом данных, но и определять, какая микрокоманда должна выполняться следующей, поскольку микропрограммы не упорядочены в управляющей памяти. Вычисление адреса следующей микрокоманды начинается после загрузки регистра MIR. Сначала в регистр MPC копируется 9-разрядное поле NEXT_ADDRESS (следующий адрес). Пока происходит копирование, проверяется поле JAM. Если оно содержит значение ООО, то ничего больше делать не нужно, и когда копирование поля NEXT_ ADDRESS завершится, регистр MPC укажет на следующую микрокоманду.
Если один или несколько битов в поле JAM равны 1, то требуются еще некоторые действия. Если бит JAMN равен 1, то триггер N соединяется через схему ИЛИ со старшим битом регистра MPC. Если бит JAMZ равен 1, то триггер Z соединяется через схему ИЛИ со старшим битом регистра MPC. Если оба бита равны 1, они оба соединяются через схему ИЛИ с тем же битом. А теперь объясним, зачем нужны триггеры N и Z. Дело в том, что после фронта сигнала (и вплоть до спада) шина В больше не запускается, поэтому выходные сигналы АЛУ уже не могут считаться правильными. Сохранение флагов состояния АЛУ в регистрах
N и Z делает правильные значения установившимися и доступными для вычисления регистра MPC, независимо от того, что происходит вокруг АЛУ.
На рис. 4.5 блок, который выполняет это вычисление, помечен как "Старший бит". Он вычисляет следующую булеву функцию:
F= (CJAMZ И Z) ИЛИ (JAMN И N)) ИЛИ NEXT_ADDRESS[8]
Отметим, что в любом случае регистр MPC может принять только одно из двух возможных значений:
1. Значение NEXT_ADDRESS.
2. Значение NEXT_ADDRESS со старшим битом, соединенным операцией ИЛИ с логической единицей.
Других значений не существует. Если старший бит значения NEXTADDRESS уже равен 1, нет смысла использовать J AMN или JAMZ.
Отметим, что если все биты JAM равны 0, то адрес следующей команды - это просто 9-разрядный номер в поле NEXTADDRESS. Если бит JAMN или JAMZ равен 1, то существует два потенциально возможных адреса следующей микрокоманды (символы Ох говорят о том, что следующее за ними число дается в ше-стнадцатеричной системе счисления): адрес NEXT_ADDRESS и адрес NEXT_ ADDRESS, соединенный операцией ИЛИ со значением 0x100 (предполагается, что NEXT_ADDRESS < OxFF). Это иллюстрирует рис. 4.6. Текущая микрокоманда с адресом 0x75 содержит поле NEXT_ADDRESS = 0x92, причем бит JAMZ установлен в 1. Следовательно, следующий адрес микрокоманды зависит от значения бита Z, сохраненного при предыдущей операции АЛУ. Если бит Z равен 0, то следующая микрокоманда имеет адрес 0x92. Если бит Z равен 1, то следующая микрокоманда имеет адрес 0x192.

Рис. 4.6. Микрокоманда с битом JAMZ, равным 1, указывает на две потенциальные последующие микрокоманды
Третий бит в поле JAM - JMPC. Если он установлен, то 8 бит регистра MBR поразрядно связываются операцией ИЛИ с 8 младшими битами поля NEXT_ ADDRESS текущей микрокоманды. Результат отправляется в регистр MPC. На рис. 4.5 меткой "О" обозначена схема, которая выполняет операцию ИЛИ над MBR и NEXT_ADDRESS, если бит JMPC равен 1, и просто отправляет NEXT_ADDRESS в регистр MPC, если бит JMPC равен 0. Если бит JMPC равен 1, то младшие 8 бит поля NEXT_ADDRESS равны 0. Старший бит может быть 0 или 1, поэтому значение поля NEXT_ADDRESS обычно 0x000 или 0x100. Почему иногда используется значение 0x000, а иногда - 0x100, мы обсудим позже.
Возможность выполнять операцию ИЛИ над MBR и NEXT_ADDRESS и сохранять результат в регистре MPC позволяет реализовывать межуровневые переходы. Отметим, что биты, находящиеся в регистре MBR, позволяют задать любой адрес из 256 возможных. Регистр MBR содержит код операции, поэтому использование бита JMPC приведет к единственно возможному выбору следующей микрокоманды. Этот метод позволяет осуществлять быстрый переход к функции, соответствующей вызванному коду операции.
Чтобы разобраться в следующем материале этой главы, очень важно понимать принципы синхронизации машины, поэтому повторим их еще раз. Синхронизирующий сигнал делится на подциклы, хотя внешние изменения этого сигнала происходят только на спаде, с которого начинается цикл, и на фронте, который загружает регистры и триггеры N и Z. Посмотрите еще раз на рис. 4.2.
Во время подцикла 1, который инициируется спадом сигнала, адрес, находящийся в регистре MPC, загружается в регистр MIR. Во время подцикла 2 регистр MIR устанавливает сигналы, и на шину В загружается выбранный регистр. Во время подцикла 3 работают АЛУ и схема сдвига. Во время подцикла 4 стабилизируются значения шины С, шин памяти и АЛУ. На фронте сигнала загружаются регистры из шины С, загружаются триггеры N и Z, а регистры MBR и MDR получают результаты из памяти, начавшей функционировать в конце предыдущего цикла (если эти результаты вообще имеются). Как только регистр MBR получает свое значение, загружается регистр MPC. Это происходит где-то в середине отрезка между фронтом и спадом, но уже после загрузки регистров MBR и MDR. Регистр MPC может загружаться либо уровнем (но не фронтом) сигнала, либо через фиксированный отрезок времени после фронта. Все это означает, что регистр MPC не получает своего значения до тех пор, пока не будут готовы регистры MBR, N и Z, от которых он зависит. На спаде сигнала, когда начинается новый цикл, регистр MPC может обращаться к памяти.
Отметим, что каждый цикл является самодостаточным. В каждом цикле определяется, значение какого регистра должно поступать на шину В, что должны делать АЛУ и схема сдвига, куда нужно сохранить значение шины С и, наконец, каким должно быть следующее значение регистра MPC.
Следует сделать еще одно замечание по поводу рис. 4.5. До сих пор мы считали MPC регистром, который состоит из девяти бит и загружается на высоком уровне сигнала. В действительности этот регистр вообще не нужен. Все его входные сигналы можно непосредственно связать с управляющей памятью. Поскольку эти сигналы присутствуют в управляющей памяти на спаде синхронизирующего сигнала, когда выбирается и считывается регистр MIR, этого достаточно. Их не нужно хранить в регистре MPC. По этой причине MPC может быть реализован в виде виртуального регистра, который представляет собой просто место объединения сигналов и похож скорее на коммутационное поле, чем на настоящий регистр. Если MPC сделать виртуальным регистром, то процедура синхронизации значительно упрощается: в этом случае события происходят только на фронте и спаде сигнала. Но если вам проще считать MPC реальным регистром, то такой подход тоже вполне допустим.
9 !Микроархитектура процессора 8051
Микроархитектура процессора 8051 (рис. 4.35) значительно проще двух предыдущих - Pentium и UltraSPARC. Дело в том, что размер этой микросхемы очень мал (она состоит из 60 ООО транзисторов), а разрабатывалась она задолго до того, как конвейерная технология стала популярной. Кроме того, перед разработчиками 8051 ставилась задача создать дешевую, а не быструю микросхему. Как известно, "дешевый" и "простой" - очень близкие понятия, в то время как дешевизна и быстродействие в нашем контексте редко сочетаются.

Рис. 4.35. Микроархитектура процессора 8051
Центральное положение в микроархитектуре 8051 занимает основная шина. С ней связаны немногочисленные регистры, причем для большинства из них операции чтения и записи выполняются программно. Регистр АСС представляет собой основной арифметический регистр, в котором сохраняется большая часть результатов вычислений. Через него проходят почти все арифметические команды. Регистр В применяется для умножения и деления; кроме того, при хранении результатов он выполняет роль временного регистра. Регистр SP является указателем стека, как и в большинстве других систем он указывает на вершину стека. В регистре команд IR содержатся команды, выполняемые в данный момент.
Регистры ТМР1 и ТМР2 - это защелки, обслуживающие АЛУ. Перед выполнением операций в АЛУ соответствующие операнды копируются в эти защелки. Результаты вычислений в АЛУ записываются в любой регистр записи, доступ к которому обеспечивает основная шина. Коды состояний, обозначающие нулевые, отрицательные и тому подобные результаты, записываются в регистр PSW (Program Status Word - слово состояния программы).
В 8051 предусмотрены независимые модули памяти для размещения данных и кода. Емкость ОЗУ для размещения данных составляет 128 (модель 8051) или 256 (модель 8052) байт; соответственно, 8-разрядного регистра RAM ADDR вполне достаточно для полной адресации этой памяти. В процессе адресации ОЗУ адрес целевого байта размещается в регистре RAM ADDR, после чего производится обращение к памяти. Емкость памяти кода может достигать 64 Кбайт (при условии размещения модуля памяти вне микросхемы), поэтому разрядность регистра ROM ADDR составляет 16 бит. Схема адресации к программному коду в ПЗУ с помощью регистра ROM ADDR аналогична вышеописанной схеме для памяти данных.
Регистр DPTR (Double PoinTeR - двойной указатель) - это 16-разрядный временный регистр, предназначенный для управления и сборки 16-разрядных адресов. Регистр PC представляет собой 16-разрядный счетчик команд; иными словами, он определяет адрес следующей команды, которую требуется вызвать и выполнить. Регистр PC incrementer - это специальный аппаратный модуль, выполняющий роль псевдорегистра. Когда в него копируется, а затем считыва-ется содержимое регистра PC, его значение автоматически увеличивается на единицу. Ни к PC, ни к PC incrementer нельзя обратиться через основную шину. Наконец, BUFFER - это еще один 16-разрядный временный регистр. На самом деле каждый 16-разрядный регистр процессора 8051 состоит из пары 8-разрядных регистров, с каждым из которых можно выполнять разные операции.
В дополнение ко всему, на микросхеме 8051 устанавливаются три 16-разрядных таймера, необходимых для выполнения приложений в реальном времени. Также предусмотрено четыре 8-разрядных порта ввода-вывода, через которые процессор 8051 может управлять 32 внешними кнопками, световыми индикаторами, датчиками, выключателями и т. д. Именно наличие таймеров и портов ввода-вывода делает возможным применение 8051 в качестве встроенного процессора без установки дополнительных микросхем.
Процессор 8051 относится к категории синхронных - большинство команд, которые он обрабатывает, завершаются за один цикл. Каждый цикл делится на шесть частей, называемых состояниями. В первом состоянии следующая команда вызывается из ПЗУ, и по основной шине отправляется в регистр IR. Во втором состоянии проводится декодирование этой команды, а значение в регистре PC увеличивается на единицу. В третьем состоянии подготавливаются операнды; в четвертом один из них передается основной шине, после чего, как правило, размещается в регистре ТМР1 и выполняет роль операнда АЛУ. В этом же состоянии возможно копирование содержимого АСС в регистр ТМР2, после чего оба АЛУ становятся готовы к дальнейшей обработке. В пятом состоянии происходит выполнение команд АЛУ. Наконец, в шестом состоянии результаты выполнения команд АЛУ передаются обратно основной шине. Одновременно в регистре ROM ADDR проводится подготовка к вызову следующей команды.
Об устройстве 8051 можно было бы рассказать подробнее, однако имеющегося описания и схемы, изображенной на рис. 4.35, вполне достаточно для того, чтобы получить общее представление. Резюмируя вышеизложенное, отметим, что 8051 состоит из одной основной шины (что позволяет уменьшить размер микросхемы), гетерогенного набора регистров, трех таймеров и четырех портов, подключенных к основной шине, а также нескольких дополнительных регистров, соединенных с локальной шиной. В течение каждого цикла тракта данных два АЛУ получают на входе по одному операнду, после чего, как и в более современных системах, результаты сохраняются в регистре.
10 !Классификация архитектур М. Flynn (SISD, MISD, SIMD, MIMD).
По-видимому, самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М.Флинном [1,2]. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD,MISD,SIMD,MIMD.

| SISD (single instruction stream / single data stream) - одиночный поток команд и одиночный поток данных. К этому классу относятся, прежде всего, классические последовательные машины, или иначе, машины фон-неймановского типа, например, PDP-11 или VAX 11/780. В таких машинах есть только один поток команд, все команды обрабатываются последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных. Не имеет значения тот факт, что для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка - как машина CDC 6600 со скалярными функциональными устройствами, так и CDC 7600 с конвейерными попадают в этот класс. |

| SIMD (single instruction stream / multiple data stream) - одиночный поток команд и множественный поток данных. В архитектурах подобного рода сохраняется один поток команд, включающий, в отличие от предыдущего класса, векторные команды. Это позволяет выполнять одну арифметическую операцию сразу над многими данными - элементами вектора. Способ выполнения векторных операций не оговаривается, поэтому обработка элементов вектора может производится либо процессорной матрицей, как в ILLIAC IV, либо с помощью конвейера, как, например, в машине CRAY-1. |
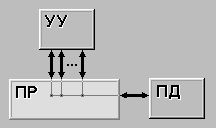
| MISD (multiple instruction stream / single data stream) - множественный поток команд и одиночный поток данных. Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных. Однако ни Флинн, ни другие специалисты в области архитектуры компьютеров до сих пор не смогли представить убедительный пример реально существующей вычислительной системы, построенной на данном принципе. Ряд исследователей [3,4,5] относят конвейерные машины к данному классу, однако это не нашло окончательного признания в научном сообществе. Будем считать, что пока данный класс пуст. |
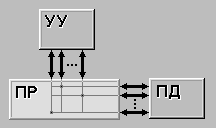
| MIMD (multiple instruction stream / multiple data stream) - множественный поток команд и множественный поток данных. Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных. |
Итак, что же собой представляет каждый класс? В SISD, как уже говорилось, входят однопроцессорные последовательные компьютеры типа VAX 11/780. Однако, многими критиками подмечено, что в этот класс можно включить и векторно-конвейерные машины, если рассматривать вектор как одно неделимое данное для соответствующей команды. В таком случае в этот класс попадут и такие системы, как CRAY-1, CYBER 205, машины семейства FACOM VP и многие другие.
Бесспорными представителями класса SIMD считаются матрицы процессоров: ILLIAC IV, ICL DAP, Goodyear Aerospace MPP, Connection Machine 1 и т.п. В таких системах единое управляющее устройство контролирует множество процессорных элементов. Каждый процессорный элемент получает от устройства управления в каждый фиксированный момент времени одинаковую команду и выполняет ее над своими локальными данными. Для классических процессорных матриц никаких вопросов не возникает, однако в этот же класс можно включить и векторно-конвейерные машины, например, CRAY-1. В этом случае каждый элемент вектора надо рассматривать как отдельный элемент потока данных.
Класс MIMD чрезвычайно широк, поскольку включает в себя всевозможные мультипроцессорные системы: Cm*, C.mmp, CRAY Y-MP, Denelcor HEP,BBN Butterfly, Intel Paragon, CRAY T3D и многие другие. Интересно то, что если конвейерную обработку рассматривать как выполнение множества команд (операций ступеней конвейера) не над одиночным векторным потоком данных, а над множественным скалярным потоком, то все рассмотренные выше векторно-конвейерные компьютеры можно расположить и в данном классе.
Предложенная схема классификации вплоть до настоящего времени является самой применяемой при начальной характеристике того или иного компьютера. Если говорится, что компьютер принадлежит классу SIMD или MIMD, то сразу становится понятным базовый принцип его работы, и в некоторых случаях этого бывает достаточно. Однако видны и явные недостатки. В частности, некоторые заслуживающие внимания архитектуры, например dataflow и векторно--конвейерные машины, четко не вписываются в данную классификацию. Другой недостаток - это чрезмерная заполненность класса MIMD. Необходимо средство, более избират
|
из
5.00
|
Обсуждение в статье: Автоинкрементная и автодекрементная адресации |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы